행사에 나가서 NoSQL 사용자 및 옹호자들과 이야기를 나누다 보면, 사람들이 왜 MongoDB를 사용하다가 Couchbase를 사용하기로 결정했는지에 대한 이야기를 자주 듣게 됩니다. 예를 들어 뉘앙스의 톰 코츠와 진행한 인터뷰. Nuance가 MongoDB를 중단하기로 결정한 가장 큰 이유는 단순화된 방식으로 확장할 수 없기 때문입니다. 이 이야기를 처음 들은 것은 아닙니다.
MongoDB로 NoSQL 클러스터를 확장하는 데 관련된 사항을 살펴본 다음 카우치베이스.
몽고DB의 경우 샤딩은 널리 사용되는 방법 중 하나입니다.cale. 다른 데이터베이스는 NoSQL 클러스터링 프로세스에 다르게 접근합니다. 모든 경우에 데이터 복제를 포함하는 다중 노드 클러스터를 만드는 데 관심이 있습니다.
다중 노드 MongoDB 클러스터 만들기
MongoDB는 마스터-슬레이브 아키텍처를 가진 NoSQL 문서 데이터베이스입니다. 클러스터를 생성하고 확장할 때, 클러스터를 생성하고 관리하려면 샤드 클러스터 및 복제 세트는 복제 클러스터의 다른 이름입니다. 이는 잠재적으로 큰 퍼즐의 조각이며, 이 퍼즐이 어떻게 쉽게 복잡해질 수 있는지 알게 될 것입니다.
모든 것을 로컬에서 처리할 계획이기 때문에 Docker는 이 작업에 적합한 솔루션입니다. 여러 개의 MongoDB Docker 컨테이너를 배포하고 클러스터의 일부로 확장할 것입니다.
가장 먼저 해야 할 일은 클러스터에 필요한 모든 노드를 배포하는 것입니다. Docker CLI를 사용하여 다음 명령을 실행합니다:
|
1 2 3 |
도커 실행 -d -p 27017-27019:27017-27019 -p 28017:28017 --name mongocfg1 mongo mongod --configsvr --replSet rs0 도커 실행 -d -p 37017-37019:27017-27019 -p 38017:28017 --이름 몽고시드1 몽고 몽고드 --shardsvr --replSet rs1 도커 실행 -d -p 47017-47019:27017-27019 -p 48017:28017 --이름 몽고시드2 몽고 몽고 --shardsvr --replSet rs1 |
위의 명령은 다음을 사용하는 구성 노드를 생성합니다. rs0 복제본 세트와 두 개의 샤드 노드를 사용하는 rs1 복제본 세트. 이제 막 MongoDB 인스턴스를 시작했는데 이미 두 가지 다른 노드 유형과 복제본 세트에 대해 걱정해야 합니다.
이제 이 모든 것을 함께 연결하여 복제 및 샤딩이 작동하는 상태로 만들어야 합니다.
먼저 두 개의 샤드 노드에서 복제를 초기화해 보겠습니다. rs1 복제본 세트. 이 작업을 수행하려면 해당 컨테이너 IP 주소를 확인해야 합니다. Docker CLI에서 다음을 실행합니다:
|
1 2 |
도커 검사 몽고시드1 도커 검사 몽고시드2 |
IP 주소를 얻은 후 다음 명령을 통해 샤드 노드 중 하나에 연결합니다:
|
1 |
도커 실행 -잇 몽고시드1 배쉬 |
이를 통해 대화형 셸로 컨테이너를 제어할 수 있습니다. 이러한 노드에서 복제를 초기화하려면 연결된 컨테이너에서 Mongo 셸을 실행해야 합니다:
|
1 |
몽고 --포트 27018 |
몽고 셸을 통해 연결되면 다음을 실행합니다:
|
1 2 3 4 5 6 7 |
rs.initiate({ _ID : "RS1", 멤버: [ { _id : 1, host : "172.17.0.3:27018" }, { _id : 2, host : "172.17.0.4:27018" } ] }); |
위의 명령에서 컨테이너 IP 주소를 실제로 사용하려는 샤드 노드로 교체하는 것을 잊지 마세요.
실행이 완료되면 다음을 통해 노드의 상태를 확인할 수 있습니다. rs.status() 명령을 사용합니다.
이제 구성 노드를 준비해야 합니다. 먼저 앞서 설명한 대로 컨테이너 IP를 결정하고 다음을 통해 연결합니다:
|
1 |
도커 실행 -it mongocfg1 bash |
대화형 셸로 연결되면, 이번에는 구성 노드이므로 다른 포트를 통해 Mongo 셸을 사용하여 MongoDB에 연결해야 합니다:
|
1 |
몽고 --포트 27019 |
몽고 셸을 통해 구성 노드에 연결되면 다음 명령을 실행하여 복제본 세트를 초기화합니다:
|
1 2 3 4 5 6 |
rs.initiate({ _ID : "RS0", 멤버: [ { _id : 0, host : "172.17.0.2:27019" }, ] }); |
이제 샤드 노드 구성을 시작할 수 있습니다. 이전에는 샤드 노드에서 복제본만 구성했음을 기억하세요. 구성 노드에서 Mongo 셸을 종료하되 대화형 셸을 그대로 두지 마세요. 다음과 같은 새 명령을 실행해야 합니다. 몽고를 실행하여 더 많은 구성을 수행할 수 있습니다. 다음을 실행합니다:
|
1 |
몽고스 --configdb rs0/172.17.0.2:27019 |
이렇게 하면 몽고 셸을 통해 샤드를 추가할 수 있습니다. 백그라운드에서 몽고를 실행하도록 선택하지 않은 경우, 몽고 셸을 사용하려면 새 터미널을 열어야 합니다.
다음에 연결 mongocfg1 을 실행한 다음 몽고 셸을 사용하여 연결합니다. 이번에는 포트 27019 포트 27017.
연결되면 다음 명령을 실행하여 샤드를 추가합니다:
|
1 2 |
sh.addShard("rs1/172.17.0.3:27018"); sh.addShard("rs1/172.17.0.4:27018"); |
위에서는 샤드 노드의 IP 주소와 샤드 노드 포트를 사용하고 있다는 점을 기억하세요.
MongoDB의 샤딩 기능이 구성되었으므로 이제 특정 데이터베이스에 대해 샤딩 기능을 활성화할 수 있습니다. 원하는 모든 MongoDB 데이터베이스가 될 수 있습니다. 샤딩을 활성화하는 방법은 다음과 같습니다:
|
1 |
sh.enableSharding("example"); |
하지만 아직 끝나지 않았습니다. 몽고DB에서 샤딩 옵션은 다음과 같은 범위에 존재합니다. 원거리 샤딩 그리고 해시드 샤딩. 다음 사항에 유의하면서 데이터 수집을 어떻게 샤딩할 것인지에 대한 접근 방식을 결정합니다. 데이터베이스의 데이터가 이 NoSQL 클러스터에 최대한 균등하게 분산되도록 하는 것이 목표입니다.
다음 명령을 예로 들어 보겠습니다:
|
1 |
sh.shardCollection("example.people", { "_id": "hashed" }); |
위의 명령은 다음 위치에 샤드 키를 생성합니다. _id 에 대한 사람들 컬렉션을 사용합니다. 가장 좋은 방법일 수도 있고 아닐 수도 있지만, MongoDB에서 데이터를 어떻게 샤딩할지는 사용자가 결정할 문제입니다.
샤드 배포를 확인하려면 실행할 수 있습니다:
|
1 |
db.people.getShardDistribution(); |
저희가 진행한 모든 단계를 보면 알 수 있듯이, MongoDB 노드 클러스터에서 복제 및 샤딩을 작동시키는 것은 결코 쉬운 일이 아니었습니다. 클러스터를 확장하거나 축소해야 하는 경우, 이 작업은 더욱 번거로워지며 이는 기업들을 좌절하게 만드는 요소입니다.
이것이 바로 Couchbase의 역할입니다!
다중 노드 카우치베이스 클러스터 만들기
Couchbase는 MongoDB와 같은 문서 데이터베이스이지만 아키텍처가 조금 다릅니다. Couchbase는 마스터-슬레이브 설계를 없애는 P2P(피어투피어) 설계를 사용합니다. 또한 클러스터의 모든 노드는 동일한 설계로 데이터, 인덱싱, 쿼리 서비스를 사용할 수 있습니다. 따라서 특수 복제 또는 샤드 클러스터를 만들 필요가 없습니다.
이제 다중 노드 Couchbase 클러스터를 만드는 방법을 살펴보겠습니다. 모든 작업을 로컬에서 수행할 것이므로 이 작업에는 Docker를 사용하는 것이 좋습니다.
Docker CLI에서 다음 명령을 실행합니다:
|
1 2 3 |
도커 실행 -d -p 7091-7093:8091-8093 --이름 카우치베이스1 카우치베이스 도커 실행 -d -p 8091-8093:8091-8093 --이름 카우치베이스2 카우치베이스 도커 실행 -d -p 9091-9093:8091-8093 --이름 카우치베이스3 카우치베이스 |
위의 명령은 컨테이너 포트를 다른 호스트 포트 집합에 매핑하는 세 개의 Couchbase Server 컨테이너를 생성합니다.
이것은 Docker이므로 각 컨테이너는 Couchbase를 새로 설치하게 됩니다. 이 가이드의 목표는 Couchbase를 시작하고 실행하는 것이 아니므로 5가지 구성 단계 각각을 진행하는 방법은 검토하지 않겠습니다.
Couchbase에서 클러스터를 설정하는 방법에는 여러 가지가 있으므로 몇 가지를 살펴보겠습니다. 세 개의 컨테이너 중 두 개의 컨테이너를 새 클러스터로 구성합니다.
구성되지 않은 노드, 예를 들어 couchbase1 가 클러스터에 가장 먼저 추가됩니다. 클러스터와 동일한 클러스터에 추가할 것입니다. couchbase2 노드로 이동합니다. 브라우저에서 다음 위치로 이동합니다. http://localhost:7091 를 클릭하고 클러스터에 참여하도록 선택합니다.
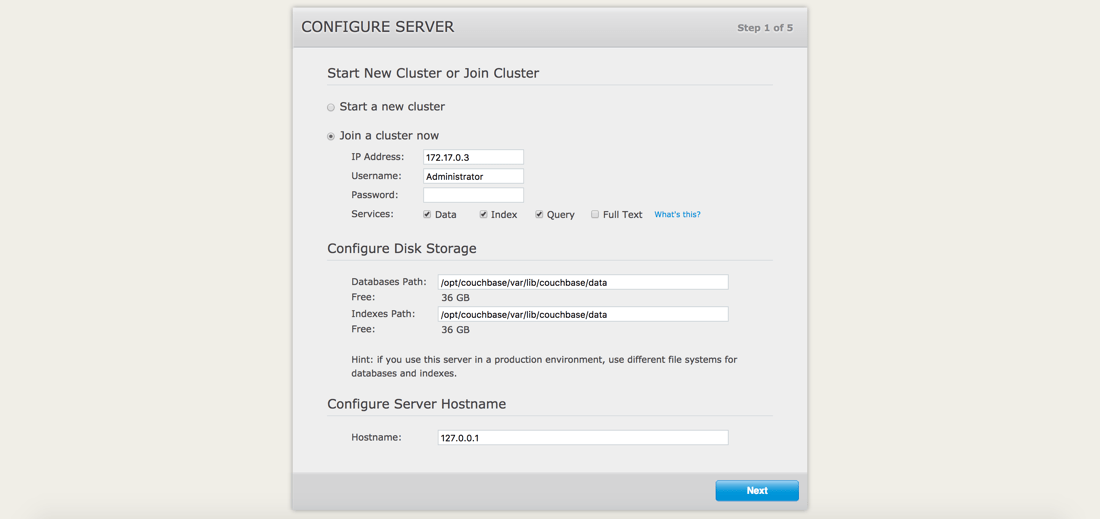
여기서 중요한 것은 다른 노드의 IP 주소, 관리 사용자 아이디 및 비밀번호, 사용하려는 서비스입니다.
Docker를 사용하므로 올바른 IP 주소를 사용하는 것이 중요합니다. couchbase2 노드입니다. 이 IP 주소를 찾으려면 다음 명령을 실행합니다:
|
1 |
도커 인스펙트 카우치베이스2 |
결과에서 IP 주소를 찾습니다. 로컬 호스트는 실제 컨테이너 주소가 아니라 바인딩된 주소일 뿐이므로 사용하지 않는 것이 매우 중요합니다.
이후 couchbase1 노드가 couchbase2 클러스터의 밸런스를 재조정해야 합니다.
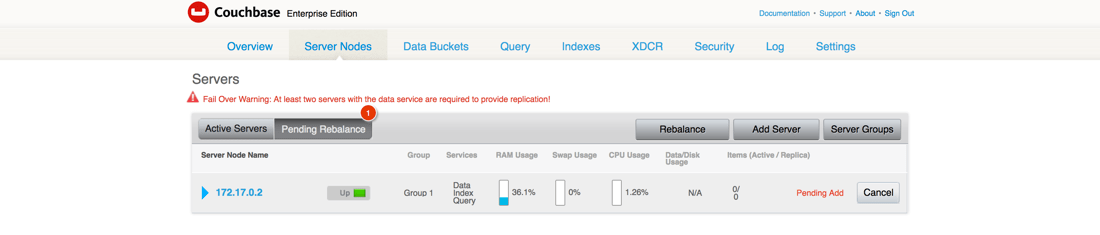
클러스터를 재조정하면 버킷 데이터가 클러스터 전체에 고르게 분산됩니다. 클러스터에서 노드를 추가하거나 제거할 때마다 리밸런싱을 수행해야 합니다.
이제 데이터 복제 및 자동 샤딩 기능을 갖춘 두 개의 노드 클러스터가 생겼습니다. 이제 이미 구성된 세 번째 노드를 클러스터에 추가해 보겠습니다.
Couchbase는 피어 투 피어이므로 다음 중 하나에 연결합니다. couchbase1 또는 couchbase2 를 클릭하고 클러스터에 새 서버를 추가하도록 선택합니다.
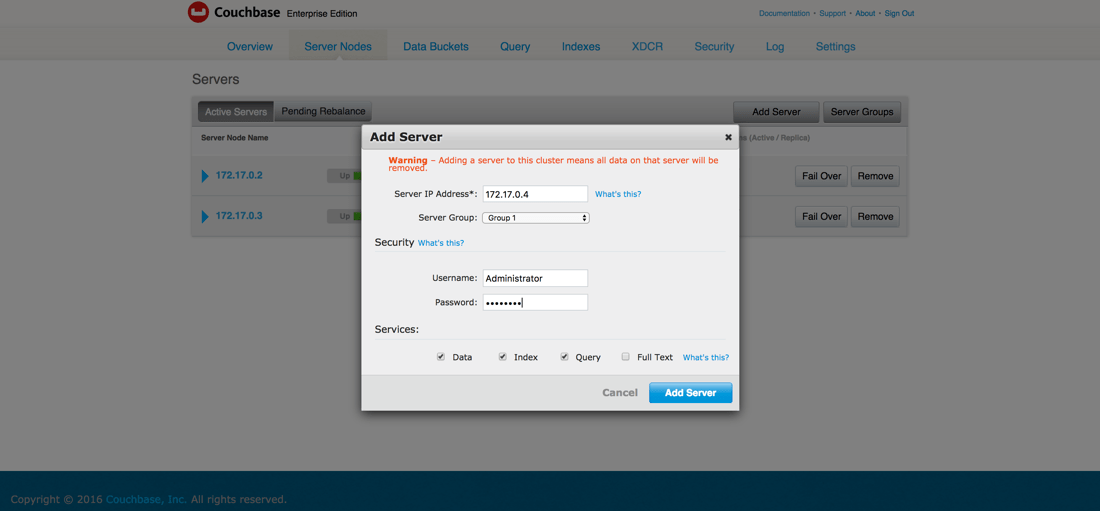
다음에 대한 노드 정보를 입력해야 합니다. couchbase3를 사용하여 이전에 했던 방식과 유사하게 설정합니다. 적절한 컨테이너 IP 주소를 사용해야 한다는 점을 잊지 마세요.
방금 클러스터에 세 번째 노드를 추가했습니다. 프로세스를 완료하려면 리밸런싱하는 것을 잊지 마세요.
클러스터에 노드를 추가하거나 클러스터에 가입하는 CLI 방법이 있지만, 이미 살펴본 내용보다 더 어렵지 않으므로 여기서는 다루지 않겠습니다. Couchbase 확장은 노드가 3개이든 50개이든 상관없이 2단계로 진행됩니다.
Docker에 관심이 있으신 분들을 위해 이 프로세스를 자동화하는 방법에 대한 가이드를 작성했습니다. 이전 기사 주제에 대해 설명합니다.
결론
방금 Couchbase Server 클러스터를 만들고 확장하는 것이 MongoDB를 사용할 때보다 얼마나 쉬운지 보셨을 것입니다. NoSQL 데이터베이스의 추가적인 복잡성은 운영 또는 개발자 중심적인 사람이라면 누구도 감당하고 싶지 않은 부담입니다.
Couchbase와 MongoDB를 더 자세히 비교하고 싶으시다면 이 주제에 대한 다른 개발자 중심의 글 몇 개를 작성해 두었습니다. 예를 들어, MongoDB에서 Couchbase로 데이터를 전송하려는 경우 다음과 같이 할 수 있습니다. 제가 작성한 골랑 튜토리얼을 확인하세요.를 사용하거나 Node.js RESTful API 변환하기에서 해당 주제에 대한 자료를 찾을 수도 있습니다.
카우치베이스 사용에 대한 자세한 내용은 다음을 참조하세요. 카우치베이스 개발자 포털.