"검색이 없는 앱은 검색창이 없는 구글 홈페이지와 같습니다."

좋은 검색 기능 없이는 앱을 설계하기 어렵습니다. 요즘에는 검색 기능이 내장되지 않은 데이터베이스를 찾기도 어렵습니다. MySQL에서 NoSQL, Sybase에서 Couchbase에 이르기까지, 모든 데이터베이스는 Couchbase처럼 기본 제공되거나 Elastic과의 통합을 통해 텍스트 검색을 지원합니다(Cassandra의 경우처럼). SQL과 달리 텍스트 검색 기능은 표준화되어 있지 않습니다. 모든 애플리케이션에는 동급 최강의 검색 기능이 필요하지만 모든 데이터베이스가 동일한 텍스트 검색 기능을 제공하는 것은 아닙니다. 각 텍스트 검색 구현의 사용 가능한 기능, 성능을 이해하고 애플리케이션의 필요에 맞는 것을 선택하는 것이 중요합니다. 텍스트 검색의 동기를 부여한 후, 효과적인 텍스트 검색을 위해 필요한 텍스트 검색 기능에 대해 알아보고, 예제를 통해 MongoDB와 Couchbase의 이러한 기능을 비교 및 대조해 보겠습니다.
애플리케이션 수준 검색 요구 사항을 살펴보겠습니다.
-
정확히 검색: (WHERE item_id = "ABC482")
-
범위 검색: (WHERE item_type = "신발", 사이즈 = 6, 가격 49.99~99.99)
-
문자열 검색:
-
(여기서 lower(name) LIKE "%joe%")
-
(WHERE lower(name) LIKE "%joe%" AND state = "CA")
-
-
문서 검색:
-
JSON 문서 내의 모든 필드에서 joe 찾기
-
전화번호(408-956-2444)와 일치하는 문서 찾기(+1 (408) 956-2444, +1 510.956.2444, (408) 956 2444)
-
-
복합 검색: (WHERE 하위(제목)이 "%dictator%", 하위(배우)가 "%chaplin", 연도 < 1950년인 경우)
(1)과 (2)의 경우의 범위 검색은 일반적인 B-Tree 인덱스로 효율적으로 처리할 수 있습니다. 데이터는 검색하려는 전체 데이터에 따라 잘 정리되어 있습니다. 'joe'라는 단어 조각을 찾거나 더 큰 문서에서 다양한 패턴의 전화번호를 일치시키기 시작하면 B-Tree 기반 인덱스는 어려움을 겪게 됩니다. Simple 토큰화 B-Tree 기반 인덱스를 사용하면 간단한 경우에 도움이 될 수 있습니다. 실제 검색 사례에 대한 새로운 접근 방식이 필요합니다.
이 블로그의 부록 섹션에서 역 트리 인덱스가 구성되는 방식과 엔터프라이즈 검색에 사용되는 이유에 대한 자세한 내용을 확인할 수 있습니다. Lucene 그리고 Bleve. Bleve는 Couchbse의 전체 텍스트 검색을 지원합니다. MongoDB는 텍스트 검색에도 B-Tree 기반 인덱스를 사용합니다.
이제 MongoDB와 Couchbase의 텍스트 검색 지원에 대해 집중해 보겠습니다.
제가 사용한 데이터 세트는 다음에서 가져온 것입니다. https://github.com/jdorfman/awesome-json-datasets#movies
MongoDB: https://docs.mongodb.com/manual/text-search/
카우치베이스: https://docs.couchbase.com/server/6.0/fts/full-text-intro.html
MongoDB 텍스트 검색 개요: 몽고DB 문서 문자열에 텍스트 검색 인덱스를 생성하고 쿼리합니다. 이 인덱스는 기본 제공 분석기를 위한 추가 레이어가 있는 단순한 B-트리 인덱스인 것 같습니다. 여기에는 많은 크기 조정 및 성능 문제가 수반되는데, 이에 대해서는 나중에 자세히 설명하겠습니다. 텍스트 검색 인덱스는 MongoDB 데이터베이스 인프라와 쿼리 API에 긴밀하게 통합되어 있습니다.
MongoDB는 문자열에 대한 텍스트 검색 쿼리만 지원하는 텍스트 인덱스를 제공합니다. 텍스트 인덱스에는 값이 문자열 또는 문자열 요소의 배열인 필드만 포함할 수 있습니다. 컬렉션에는 텍스트 검색 인덱스가 하나만 있을 수 있지만, 그 인덱스는 여러 필드를 포함할 수 있습니다.
카우치베이스 FTS(전체 텍스트 검색) 개요: 전체 텍스트 검색은 자연어 쿼리를 위한 광범위한 기능을 제공합니다. 반전 인덱스로 구현된 Bleve는 Couchbase 전체 텍스트 인덱스를 구동합니다. 이 인덱스는 서비스 중 하나로 배포되며 클러스터의 모든 노드에 배포할 수 있습니다.
MongoDB |
카우치베이스 |
|||
이름 |
텍스트 검색 - 4.x |
전체 텍스트 검색(FTS) - 6.x. |
||
기능 |
간단한 텍스트 검색을 통해 문자열 필드를 색인하고 하나 이상의 문자열 필드에서만 문자열을 검색합니다. 사용 B-Tree 인덱스 를 텍스트 검색 색인으로 사용합니다.전체 복합 문자열에서 검색하며 특정 필드를 분리할 수 없습니다. |
데이터에서 무엇이든 찾을 수 있는 전체 텍스트 검색. 모든 JSON 데이터 유형(문자열, 숫자, 부울, 날짜/시간)을 지원하며, 쿼리는 모든 유형의 필드에서 복잡한 부울 표현식, 퍼지 표현식을 지원합니다. 쿼리는 반전 인덱스 를 텍스트 검색 색인으로 사용합니다. |
||
설치 |
텍스트 검색: MongoDB 설치 시 사용 가능. 별도의 설치 옵션이 없습니다. |
Couchbase 설치와 함께 사용할 수 있습니다. 다른 서비스(데이터, 쿼리, 인덱스 등)와 함께 설치하거나 별도의 검색 노드에 별도로 설치할 수 있습니다. |
||
단일 필드에서 인덱스 생성 |
db.films.createIndex({ title: "text" }); |
curl -u 관리자:비밀번호 -XPUT https://localhost:8094/api/index/films_title -H '캐시 제어: 캐시 없음' -H '콘텐츠 유형: 애플리케이션/json' -d '{ "name": "films_title", "type": "전체 텍스트 인덱스", "매개변수": { "mapping": { "default_field": "title" } }, "sourceType": "카우치베이스", "소스 이름": "films" }' |
||
여러 필드에서 인덱스 생성 |
db.films.createIndex({ title: "text", genres: "text"});이 인덱스를 만들려면 먼저 이전 인덱스를 삭제해야 합니다. 컬렉션에는 텍스트 인덱스가 하나만 있을 수 있습니다.. 인덱스의 이름은 db.films.getIndexes()로 가져오거나 인덱스를 만들 때 직접 지정할 수 있습니다.db.films.dropIndex("title_text"); |
버킷(또는 키 스페이스)에 여러 개의 인덱스를 제한 없이 만들 수 있습니다.curl -u 관리자:비밀번호 -XPUT https://localhost:8094/api/index/films_title_genres -H '캐시 제어: 캐시 없음' -H '콘텐츠 유형: 애플리케이션/json' -d '{ "이름": "films_title_genres", "type": "fulltext-index", "params": { "매핑": { "types": { "장르": { "enabled": true, "dynamic": false }, "title": { "enabled": true, "dynamic": false }}}}, "sourceType": "카우치베이스", "소스 이름": "films" }' |
||
가중치 사용 |
db.films.createIndex({ title: "text", genres: "text"}, {weights:{title: 25}, name : "txt_title_genres"}); |
모피디어를 사용하여 부스팅을 통해 동적으로 수행됩니다.curl -XPOST -H "Content-Type: application/json" \ https://172.23.120.38:8094/api/index/films_title_genres/query \ -d '{ "explain": true, "fields": [ "*" ], "highlight": {}, "query": { "query": "title:찰리^40 장르:코미디^5" } }' |
||
언어 옵션 |
기본 언어는 영어입니다. 매개변수를 전달하여 변경할 수 있습니다.db.films.createIndex({ title: "text"}, { default_language: "프랑스어" }); |
분석기는 24개 언어로 제공됩니다. 인덱스를 생성하는 동안 다음 매개변수를 변경하여 is를 변경할 수 있습니다."기본_분석기": "fr", |
||
대소문자를 구분하지 않는 텍스트 색인 |
기본적으로 대소문자를 구분하지 않습니다. 새로운 언어로 확장되었습니다. |
기본적으로 대소문자를 구분하지 않습니다. |
||
분음 부호 불감증 |
버전 3에서는 텍스트 인덱스가 발음 부호를 구분하지 않습니다. |
예. 해당 분석기(예: 프랑스어)에서 자동으로 활성화됩니다. |
||
구분 기호 |
대시, 하이픈, 패턴 구문, 따옴표, 터미널 구두점 및 공백 |
각 작업은 언어 및 분석기 사양에 따라 분석됩니다. |
||
언어 |
15개 언어:덴마크어, 네덜란드어, 영어, 핀란드어, 프랑스어, 독일어, 헝가리어, 이탈리아어, 노르웨이어, 포르투갈어, 루마니아어, 러시아어, 스페인어, 스웨덴어, 터키어 |
토큰 필터는 다음 언어에 대해 지원됩니다.
아랍어, 카탈로니아어, 중국어, 일본어 , 한국어, 쿠르드어, 덴마크어, 독일어, 그리스어, 영어, 스페인어(카스티야어), 바스크어, 페르시아어, 핀란드어, 프랑스어, 게일어, 스페인어(갈리시아어), 힌디어, 헝가리어, 아르메니아어, 인도네시아어, 이탈리아어, 네덜란드어, 노르웨이어, 포르투갈어, 루마니아어, 러시아어, 스웨덴어, 터키어, 터키어 |
||
인덱스 유형 |
각 문서의 각 어간 단어에 대한 항목을 포함하는 간단한 B-Tree 색인입니다.텍스트 인덱스는 클 수 있습니다. 색인에는 삽입된 각 문서의 각 색인 필드에 있는 고유한 어간 끝 단어마다 하나의 색인 항목이 포함됩니다. |
반전된 색인. 전체 인덱스의 어간 단어당 하나의 항목(인덱스 파티션당). 따라서 인덱스 크기가 훨씬 작은 인덱스입니다. 데이터 세트가 더 방대할수록 Couchbase FTS 인덱스는 MongoDB 텍스트 인덱스에 비해 훨씬 더 효율적입니다. |
||
삽입에 대한 인덱스 생성 효과. |
삽입 속도에 부정적인 영향을 미칩니다. |
삽입/업서트 요금은 영향을 받지 않습니다. |
||
인덱스 유지 관리 |
동기식 유지 관리. |
비동기적으로 유지됩니다. 쿼리는 일관성 매개변수를 사용하여 유효기간을 지정할 수 있습니다. |
||
구문 쿼리 |
지원되지만 속도가 느립니다.구문 검색은 텍스트 색인에 문서에서 단어의 근접성에 대한 필수 메타데이터가 포함되어 있지 않기 때문에 느립니다. 따라서 전체 컬렉션이 RAM에 들어갈 때 구문 쿼리가 훨씬 더 효과적으로 실행됩니다. |
빠르게 지원됩니다.
인덱스 생성 시 벡터라는 용어를 포함하세요. |
||
텍스트 검색 |
db.films.find({$text: {$search: "찰리 채플린"}})찰리 또는 채플린이 포함된 모든 문서를 찾습니다. 찰리와 채플린이 모두 있으면 더 높은 점수를 받습니다. 컬렉션당 텍스트 인덱스는 하나만 있을 수 있으므로 이 쿼리는 인덱싱하는 필드에 관계없이 해당 인덱스를 사용합니다. 따라서 어떤 필드가 인덱스에 포함될지 결정하는 것이 중요합니다. |
|
||
정확한 구문 검색 |
db.films.find({$text: {$search: "\"찰리 채플린\""}}) |
|
||
| 정확한 제외 | db.films.find({$text: {$search: "charlie -chaplin"}});
"찰리"가 있지만 "채플린"이 없는 모든 영화. |
|
||
| 결과 순서. |
기본적으로 주문되지 않습니다.필요할 때 점수별로 투사하고 정렬하세요.db.films.find({$text: {$search: "찰리 채플린"}}, {score: {$meta: "searchscore"}}).sort({$meta: "searchscore"}) |
기본적으로 점수(내림차순)로 정렬됩니다. 모든 필드 또는 메타 데이터를 기준으로 정렬할 수 있습니다. 제목과 점수(내림차순)를 기준으로 정렬합니다.
|
||
| 특정 언어 검색 |
db.articles.find({ $text: { $search: "leche", $language: "es" } }) |
언어 분석기는 색인 및 쿼리의 특성을 결정합니다. | ||
| 대소문자를 구분하지 않는 검색 |
db.film.find( { $text: { $search: "Lawrence", $caseSensitive: true } } )
|
분석가가 결정합니다. 모든 검색이 대소문자를 구분하지 않도록 to_lower 토큰 필터를 사용합니다. 자세한 내용은 https://docs.couchbase.com/server/6.0/fts/fts-using-analyzers.html 참조 | ||
| 반환 결과 집합을 제한합니다. |
db.films.find({$text: {$search: "찰리 채플린"}},{score: {$meta: "searchscore"}}).sort({$meta: "searchscore"}).limit(10) |
각각 "size" 및 "from" 매개변수를 사용하여 SQL에서 LIMIT 및 SKIP와 동등한 기능을 지원합니다.
|
||
| 복잡한 정렬 |
db.films.find({$text: {$search: "찰리 채플린"}},{score: {$meta: "searchscore"}}).sort({year : 1, $meta: "searchscore"}).limit(10) |
기본적으로 점수(내림차순)로 정렬됩니다. 모든 필드 또는 메타 데이터를 기준으로 정렬할 수 있습니다. 제목(오름차순), 연도(내림차순) 및 점수(내림차순)를 기준으로 정렬합니다.
|
||
| 복잡한 쿼리 |
집계 프레임워크를 사용합니다. $텍스트 검색은 몇 가지 제한 사항이 있는 집계 프레임워크에서 사용할 수 있습니다.db.articles.aggregate(
|
지금까지 살펴본 것처럼 FTS 쿼리 자체는 매우 정교합니다. 또한 FTS는 간단한 그룹화 및 카운팅을 위한 패싯을 지원합니다. https://docs.couchbase.com/server/6.0/fts/fts-response-object-schema.html
곧 출시될 릴리스에서는 N1QL(JSON용 SQL)이 검색 술어에 FTS 인덱스를 사용할 예정입니다.
|
||
| 전체 문서 색인 | 전체 문서 인덱싱을 지원하지 않습니다. 모든 문자열 필드는 createIndex 호출에서 지정해야 합니다.
db.films.createIndex({ title: "text", generes: "text", cast: "text", year: "text"});
|
기본적으로 전체 문서 색인화를 지원하며, 필드의 유형을 자동으로 인식하고 그에 따라 색인을 생성합니다. | ||
| 쿼리 유형 |
기본 검색은 반드시 있어야 하고, 없어서는 안 됩니다. |
일치, 일치 구문, 문서 ID 및 접두사 쿼리연결, 연결 해제 및 부울 필드 쿼리숫자 범위 및 날짜 범위 쿼리지리공간 쿼리쿼리 문자열 쿼리는 각 쿼리의 세부 사항을 표현하기 위해 특수 구문을 사용합니다(자세한 내용은 쿼리 문자열 쿼리 참조). |
||
| 사용 가능한 분석기 | 기본 제공 분석기만 해당됩니다. | 기본 제공 및 사용자 지정 가능한 분석기. 자세히 보기: https://docs.couchbase.com/server/6.0/fts/fts-using-analyzers.html#character-filters/token-filters |
||
UI를 통한 생성 및 검색 |
기본 제품에는 포함되어 있지 않습니다. |
콘솔에 내장 |
||
| REST API |
사용할 수 없습니다. |
사용 가능.
https://docs.couchbase.com/server/6.0/fts/fts-searching-with-the-rest-api.html https://docs.couchbase.com/server/6.0/rest-api/rest-fts.html |
||
SDK |
텍스트 검색은 대부분의 몽고 SDK에 내장되어 있습니다. 예: https://mongodb.github.io/mongo-java-driver/ |
https://docs.couchbase.com/java-sdk/2.7/full-text-searching-with-sdk.html |
||
| 지원되는 데이터 유형 | 문자열만 지원됩니다. 다른 데이터 유형은 지원되지 않습니다. | 모든 JSON 데이터 유형 및 날짜-시간.
문자열, 숫자, 부울, 날짜/시간, 개체 및 배열을 지원합니다. 가장 가까운 이웃 쿼리를 위한 지오포인트. 를 참조하세요: https://docs.couchbase.com/server/6.0/fts/fts-geospatial-queries.html |
||
| 용어 벡터. | 지원되지 않습니다. | 사용 가능합니다. 용어 벡터는 구문 검색에 매우 유용합니다. | ||
| 페이싱 | 지원되지 않음 |
용어 패싯숫자 범위 패싯날짜 범위 패싯https://docs.couchbase.com/server/6.0/fts/fts-response-object-schema.html |
||
| 고급 AND 쿼리(접속사) | 지원되지 않습니다. |
curl -u 관리자:비밀번호 -XPOST -H "콘텐츠 유형: 애플리케이션/json" https://172.23.120.38:8094/api/index/filmsearch/query -d '{}'"설명": true,"필드": [“*”],"하이라이트": {},"query": {"conjuncts":[ {"field":"title", "match":"kid"}, {"field":"cast", "match":"chaplin"}]}}’ |
||
| 고급 OR 쿼리(분리) | 지원되지 않습니다. |
curl -u 관리자:비밀번호 -XPOST -H "콘텐츠 유형: 애플리케이션/json" https://172.23.120.38:8094/api/index/filmsearch/query -d '{}'"설명": true,"필드": [“*”],"하이라이트": {},"query": {"disjuncts":[ {"field":"title", "match":"kid"}, {"field":"cast", "match":"chaplin"}]}}’ |
||
| 날짜 범위 쿼리 | 지원되지 않습니다.
성능에 영향을 줄 수 있는 사후 처리가 필요합니다. |
FTS에서 지원됩니다.
{
|
||
| 숫자 범위 쿼리 | 지원되지 않습니다. | curl -u 관리자:비밀번호 -XPOST -H "콘텐츠 유형: 애플리케이션/json" https://172.23.120.38:8094/api/index/filmsearch/query -d '{}' "설명": true, "필드": [ “*” ], "하이라이트": {}, "query": { "field":"year","min":1999,"max":1999,"inclusive_min":true,"inclusive_max":true } }’ |
성능:
정교한 성능 비교는 아직 보류 중이지만 위키피디아의 100만 개 문서와 간단한 비교를 해보았습니다. 결과는 다음과 같습니다:
인덱스 크기.
| 카우치베이스(6.0) | MongoDB(4.x) | |
| 인덱싱 크기 | 1GB(스코치) | 1.6GB |
| 인덱싱 시간 | 46초 | 7.5분 |
검색 쿼리 처리량(초당 쿼리 수):
카우치베이스 Mongodb
고빈도 용어 395 79
Med 빈도 조건 6396 201
낮음 빈도 조건 24600 643
높음 또는 높음 용어 145 82
높음 또는 중간 용어 258 78
구문 검색 107 50
요약:
MongoDB는 문자열 검색을 위한 간단한 문자열 검색 인덱스와 API를 제공합니다. 문자열 검색을 위해 생성하는 B-트리 인덱스도 상당히 방대합니다. 텍스트 검색은 그렇지 않습니다.
카우치베이스 텍스트 인덱스는 반전 인덱스를 기반으로 하며 훨씬 더 많은 기능과 더 나은 성능을 갖춘 전체 텍스트 인덱스입니다.
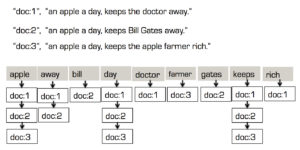
검색 인덱스에 반전 인덱스가 필요한 이유는 무엇인가요?
간단한 정확도 및 범위 검색은 다음을 통해 지원됩니다. B-Tree 인덱스처럼 효율적인 검색을 위해 사용합니다. 하지만 텍스트 검색은 어간, 어절, 분석기 등 더 광범위한 요구 사항이 있습니다. 이를 위해서는 다른 색인 접근 방식뿐만 아니라 사전 색인 필터링, 사용자 정의 분석 도구, 언어별 어간 및 대소문자 구분도 필요합니다.
검색 인덱스는 기존의 B-TREE를 사용해 만들 수 있습니다. 하지만 스칼라 값에 대한 B-TREE 색인과 달리 텍스트 색인에는 각 문서에 대해 여러 개의 색인 항목이 있습니다. 이 문서의 텍스트 인덱스에만 최대 12개의 항목이 있을 수 있습니다: 출연자 이름에 8개, 장르에 1개, 마침표(in)와 연도를 제거한 후 제목에 2개. 문서와 문서 수가 많을수록 텍스트 색인의 크기는 기하급수적으로 증가합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "cast": [ "Whoopi Goldberg", "Ted Danson", "Will Smith", "Nia Long" ], "genres": [ "Comedy" ], "title": "Made in America", "year": 1993 } } |
솔루션: 반전 트리입니다. 반전 트리는 데이터(검색어)가 맨 위(루트)에 있고 해당 용어가 있는 다양한 문서 키가 맨 아래에 있어 마치 거꾸로 된 트리처럼 보이는 구조입니다. 인기 있는 텍스트 색인 Lucene, Bleve 는 모두 반전된 인덱스로 구현됩니다.