참고: 이 추천 노트는 Couchbase 분석 R&D를 이끌고 있는 Till Westmann 및 Mike Carey와 공동으로 작성되었습니다.
[이 글의 2부는 Even Pease의 글에서 확인할 수 있습니다: https://www.couchbase.com/blog/part-2-n1ql-to-query-or-to-analyze/]
Couchbase의 쿼리 및 분석 서비스는 모두 N1QL(JSON용 SQL)을 지원합니다. 일반적인 질문은 "어떤 서비스가 내 쿼리를 실행해야 하나요?"입니다. 빠른 대답은 "사용자에 따라 다릅니다. 워크로드". 이 블로그에서 이 답변에 대해 설명합니다.
거래는 식료품점에서 커피와 케이크를 구매하는 것을 말합니다. 분석은 식료품점에서 모든 판매 데이터를 살펴보고 어떤 요일, 어떤 달에 커피나 케이크가 더 많이 팔리는지 확인하여 재고, 판매, 가격을 계획할 수 있도록 하는 것입니다.
모든 비즈니스는 이 세 가지를 주기적으로 또는 나선형으로 수행합니다[목표].
- 고객에게 제품이나 서비스를 제공하기 위한 비즈니스 프로세스를 실행합니다.
- 비즈니스를 분석하여 변경할 사항과 변경할 대상을 결정하세요.
- 변화를 실현하세요.
현대 비즈니스에서는 각 단계를 수행하기 위해 애플리케이션이 필요합니다.
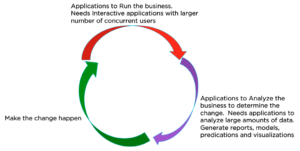
쿼리 서비스는 비즈니스 운영에 필요한 애플리케이션에서 사용되며, 각각 소량의 작업을 수행하는 많은 수의 동시 쿼리를 위해 설계되었습니다. RDBMS 세계에서는 이 워크로드를 OLTP 워크로드라고 합니다.
분석에 사용되는 애플리케이션이나 도구는 워크로드 특성이 다릅니다. 일반적으로 많은 수의 문서를 분석하는 적은 수의 동시 쿼리를 위해 설계된 분석 서비스를 사용합니다. RDBMS 세계에서는 이러한 워크로드를 OLAP 워크로드라고 합니다.
이 두 서비스에 대해 자세히 살펴보겠습니다.
| 쿼리 서비스 | 분석 서비스 |
| 튜토리얼 | |
| https://query-tutorial.couchbase.com/tutorial/#1 | https://sqlplusplus-tutorial.couchbase.com/tutorial/#1 |
| 상위 수준 비교 | |
| 애플리케이션 로직 내 데이터 조작에 사용 | 보고서, 분석(기록, 대화형), 대시보드에 사용 |
| 짧은 쿼리
- 비교적 간단한 SQL - 일반적으로 소량의 데이터와 관련된 경우 |
더 긴 작업 시간
- 분석이 포함된 복잡한 SQL - 일반적으로 대량의 데이터가 포함되는 경우 |
| 운영 애플리케이션을 위한 SELECT, INSERT, UPDATE, DELETE, MERGE 실행 | 분석을 위해 SELECT 실행 |
| 무작위 업데이트
- 쿼리당 몇 개의 문서 업데이트 |
업데이트 없음
- 데이터 서비스에서 수집된 변경 사항 |
| 밀리초에서 1초의 지연 시간,
높은 처리량(10-1000 QPS), 성능 목표는 쿼리/초입니다. |
초에서 분 단위의 응답 시간,
<초당 1~10개 미만의 쿼리, 성능 목표는 초/쿼리입니다. |
| 많은 수의 인덱스 | 인덱스 수 감소 |
| 개발자 작성 쿼리; 생성된 쿼리는 잘 알려져 있습니다. | 애드혹 쿼리; 복잡한 보고서, 대시보드, BI 워크로드 |
| 쿼리는 분산 인덱스 및 데이터 인프라를 사용하여 단일 쿼리 노드에서 실행됩니다. | 쿼리는 분산 컴퓨팅, 인덱스 및 데이터 인프라를 사용하여 모든 분석 노드에서 실행됩니다. |
| 기술 비교: 아키텍처 | |
| 쿼리는 SMP 모드에서 실행되며, 새 쿼리 노드를 추가하여 처리량을 확장할 수 있습니다. | MPP 모드에서 실행되는 쿼리는 새로운 분석 노드를 추가하여 더 큰 데이터를 처리하거나 쿼리 실행 시간을 단축할 수 있습니다. |
| 기술 비교: 옵티마이저 | |
| 기본적으로 중첩 루프 조인
쿼리 힌트를 통한 해시 조인 |
기본적으로 병렬 해시 조인이 사용됩니다,
(인덱스) 중첩 루프 조인 또는 쿼리 힌트를 통한 브로드캐스트 조인 |
| 기술 비교: 색인 | |
| 글로벌 보조 인덱스 | 로컬 보조 인덱스(데이터 파티션과 함께 위치) |
| 메모리 최적화 인덱스, 표준 보조 인덱스(플라즈마) 사용 | 로그 구조 병합 트리(LSM) 기반 보조 인덱스 |
| 보장 및 비보장 인덱스 스캔 모두 지원 | 커버되지 않는 인덱스 스캔 |
| 쿼리에 전체 텍스트 색인 사용 가능(6.5) | |
| 기술 비교: 실행 | |
| 대부분의 쿼리는 한 번 준비되고 여러 번 실행됩니다. | 임시 및 탐색 쿼리 |
| SDK는 임시 플래그를 기반으로 준비-실행 모델을 사용합니다. | SDK는 애드혹 및 매개변수화된 쿼리를 제공합니다. |
| 대부분의 작업은 메모리에서 수행되며, 인덱스 스캔이 대용량 데이터를 반환할 때만 디스크 백필에 기록됩니다. | 대용량 데이터(클러스터 메모리보다 큰)에 대한 제한 메모리 작업, 필요에 따라 부드럽게 스필링 가능 |
| 단일 노드 쿼리 병렬 처리 | 다중 노드 파티션 병렬 조인, 정렬, 집계 및 그룹화된 집계 연산자 |
| 단일(레이드 가능) 스토리지 장치 예상 | 여러 저장 장치의 RAID 없는 사용 |
| 인덱스 서비스 노드에서 스캔, 그룹화 및 집계 작업을 지원하는 인덱스 커버링을 통한 성능 격리 | 분석 서비스 노드에서 데이터 섀도잉을 통한 모든 쿼리의 성능 격리 |
| 기술 문서 | |
| https://docs.couchbase.com/server/6.0/n1ql/n1ql-language-reference/index.html | https://docs.couchbase.com/server/6.0/analytics/introduction.html |
| 기술 정보 | |
| https://www.couchbase.com/products/n1ql | https://www.couchbase.com/sqlplusplus |
| 기술 서적 | |
| https://www.couchbase.com/blog/a-guide-to-n1ql-features-in-couchbase-5-5-special-edition/ | https://resources.couchbase.com/sql_tutorial
https://www.amazon.com/SQL-Users-Tutorial-Don-Chamberlin/dp/0692184503/ |
- [목표]: 목표: 지속적인 개선의 과정. https://www.amazon.com/Goal-Process-Ongoing-Improvement/dp/0884271951/ref=sr_1_1?keywords=the+goal&qid=1547969233&sr=8-1
- 고객 업무에 대한 참여 시스템: https://marketing.cioreview.com/cxoinsight/systems-of-engagement-for-customer-jobs-nid-24677-cid-51.html
- 이 글의 2부는 Even Pease의 글입니다: https://www.couchbase.com/blog/part-2-n1ql-to-query-or-to-analyze/