이 블로그 게시물 시리즈에서는 관계형 배경이 있는 경우 문서 데이터베이스로 이동할 때 고려해야 할 사항을 정리해 보려고 합니다. 특히 Microsoft SQL Server와 카우치베이스 서버.
세 부분으로 나눠서 설명해 드리겠습니다:
- 데이터 모델링(이 블로그 게시물)
- 데이터 자체
- 데이터를 사용하는 애플리케이션
목표는 애플리케이션 계획 및 디자인에 적용할 수 있는 몇 가지 일반적인 가이드라인을 제시하는 것입니다.
따라 해보고 싶으신 분들을 위해 Couchbase와 SQL Server를 나란히 시연하는 애플리케이션을 만들었습니다. GitHub에서 소스 코드 받기를 클릭하고 다음 사항을 확인하세요. 카우치베이스 서버의 개발자 미리 보기 다운로드.
내가 왜 이렇게 해야 하나요?
시작하기 전에 동기 부여에 대해 잠시 말씀드리고 싶습니다. 관계형 데이터베이스 대신(또는 관계형 데이터베이스와 함께) 문서 데이터 저장소를 사용하려는 이유는 크게 세 가지입니다. 동기는 이 세 가지 중 하나 또는 모두에 해당할 수 있습니다:
- 속도: 카우치베이스 서버는 메모리 우선 아키텍처 관계형 데이터베이스에 비해 속도가 크게 향상될 수 있습니다.
- 확장성: 카우치베이스 서버는 분산 데이터베이스를 사용하면 상용 하드웨어를 추가하는 것만으로 용량을 확장(또는 축소)할 수 있습니다. 자동 샤딩, 복제, 로드 밸런싱과 같은 기본 제공 Couchbase 기능을 사용하면 관계형 데이터베이스보다 훨씬 원활하고 쉽게 확장할 수 있습니다.
- 유연성: 일부 데이터는 관계형 모델에 잘 맞지만 일부 데이터는 JSON 사용의 유연성. SQL Server와 달리 스키마 유지 관리가 더 이상 문제가 되지 않습니다. JSON을 사용하면 필요에 따라 스키마를 변경할 수 있습니다.
이러한 이유와 다른 이유 때문입니다, Gannett, SQL Server에서 Couchbase Server로 전환. 이를 고려하고 있다면 반드시 가넷의 프레젠테이션 전문을 확인하세요..
[유튜브 https://www.youtube.com/watch?v=mor2p0UqZ14&w=560&h=315]
문서 데이터베이스와 관계형 데이터베이스는 서로 보완적인 역할을 할 수 있다는 점에 유의하세요. 애플리케이션에 따라 둘 중 하나, 둘 중 하나 또는 둘을 조합하여 사용하는 것이 가장 적합할 수 있습니다. 대부분의 경우 설계에서 관계형 데이터베이스를 완전히 제거할 수는 없지만 Couchbase Server와 같은 문서 데이터베이스는 여전히 소프트웨어에 위의 이점을 제공할 수 있습니다. 이 블로그 시리즈의 나머지 부분에서는 SQL Server에 대한 배경 지식이 있고 Couchbase를 사용하여 기존 프로젝트를 대체, 보완 또는 새로운 그린필드 프로젝트를 시작한다고 가정합니다.
기존 애플리케이션을 전환하는 작업의 용이성 또는 난이도는 여러 가지 요인에 따라 크게 달라집니다. 어떤 경우에는 매우 쉬울 수도 있고, 어떤 경우에는 시간이 많이 걸리고 어려울 수도 있으며, 어떤 경우에는 전환하는 것이 좋은 생각조차 되지 않을 수도 있습니다.
차이점 이해
첫 번째 단계는 문서 데이터베이스에서 데이터가 어떻게 모델링되는지 이해하는 것입니다. 관계형 데이터베이스에서 데이터는 일반적으로 테이블에 평평하게 저장되며 기본 키와 외래 키가 있는 구조가 주어집니다. 간단한 예로 쇼핑 카트와 소셜 미디어 기능이 있는 웹사이트의 관계형 데이터베이스를 생각해 보겠습니다. (이 예에서는 단순성을 유지하기 위해 이러한 기능은 서로 관련이 없습니다).
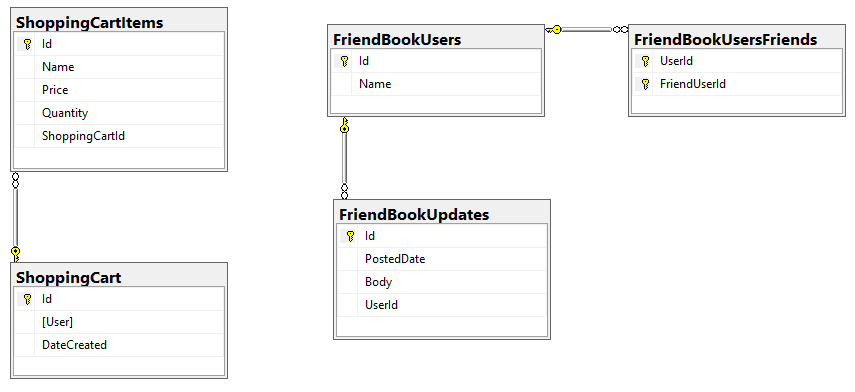
문서 데이터베이스에서 데이터는 키와 값으로 저장됩니다. 카우치베이스 버킷에는 문서가 포함되며, 각 문서에는 고유한 키와 JSON 값이 있습니다. 외래 키는 없습니다(더 정확하게는 외래 키 제약 조건이 없습니다).
다음은 Couchbase와 비교한 SQL Server 기능/명칭의 개괄적인 비교입니다:
| SQL Server | 카우치베이스 서버 |
|---|---|
|
서버 |
클러스터 |
|
데이터베이스 |
버킷 |
|
테이블의 행 |
문서 |
|
칼럼 |
JSON 키/값 |
|
기본 키 |
문서 키 |
이러한 비교는 은유적인 출발점입니다. 이 표를 보면 단순한 접근 방식을 취하고 싶을 수도 있습니다. "테이블이 5개이므로 행당 하나의 문서로 5개의 서로 다른 유형의 문서를 만들면 됩니다." 이는 문자 그대로 언어를 번역하는 것과 같습니다. 이 접근 방식은 때때로 효과가 있을 수 있지만 JSON을 사용하는 문서 데이터베이스의 모든 기능을 고려하지 않습니다. 문어를 문자 그대로 번역할 때 문화적 맥락, 관용구, 역사적 맥락을 고려하지 않는 것처럼 말입니다.
JSON의 유연성 덕분에 문서 데이터베이스의 데이터는 애플리케이션에서 도메인 객체처럼 구조화할 수 있습니다. 따라서 엔티티 프레임워크나 NHibernate와 같은 OR/M 도구에서 자주 발생하는 임피던스 불일치 문제가 발생하지 않습니다.
Couchbase에서 데이터를 모델링할 때 사용할 수 있는 두 가지 주요 접근 방식이 있으며, 이에 대해 자세히 살펴볼 것입니다:
- 비정규화 - 외래 키를 사용하여 테이블 간에 데이터를 분할하는 대신 개념을 하나의 문서로 그룹화하세요.
- 참조 - 개념에는 자체 문서가 제공되지만 문서 키를 사용하여 다른 문서를 참조합니다.
비정규화 예제
'쇼핑 카트' 엔티티를 살펴보겠습니다.
이를 관계형 데이터베이스로 표현하려면 ShoppingCart 테이블과 ShoppingCart의 행에 대한 외래 키가 있는 ShoppingCartItem 테이블이라는 두 개의 테이블이 필요할 수 있습니다.
문서 데이터베이스에 대한 모델을 만들 때 이를 두 개의 개별 엔티티(예: 쇼핑 카트 문서와 해당 쇼핑 카트 항목 문서)로 계속 모델링할지 아니면 쇼핑 카트를 나타내기 위해 쇼핑 카트의 행과 쇼핑 카트 항목의 행을 '비정규화'하여 단일 문서로 결합할지 여부를 결정해야 합니다.
카우치베이스에서는 비정규화 전략을 사용하면 장바구니와 그 안에 있는 항목이 하나의 문서로 표현됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "user": "mgroves", "dateCreated": "2017-02-02T15:28:11.0208157-05:00", "items": [ { "name": "BB-8 Sphero", "price": 80.18, "quantity": 1 }, { "name": "Shopkins Season 5", "price": 59.99, "quantity": 2 } ], "type": "ShoppingCart" } |
이제 항목과 장바구니 간의 관계가 동일한 문서에 포함되어 있음을 암시합니다. 더 이상 관계를 나타내기 위해 항목에 ID가 필요하지 않습니다.
C#에서는 다음과 같이 정의할 수 있습니다. 쇼핑 카트 그리고 항목 클래스를 사용하여 이 데이터를 모델링합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public class ShoppingCart { public Guid Id { get; set; } public string User { get; set; } public DateTime DateCreated { get; set; } public List Items { get; set; } } public class Item { public Guid Id { get; set; } // necessary for SQL Server, not for Couchbase public string Name { get; set; } public decimal Price { get; set; } public int Quantity { get; set; } } |
이러한 클래스는 Couchbase에서도 여전히 의미가 있으므로 재사용하거나 이러한 방식으로 설계할 수 있습니다. 하지만 관계형 데이터베이스에서는 이러한 설계가 직접적인 방식으로 일치하지 않습니다.
따라서 엔히버네이트나 엔티티 프레임워크와 같은 OR/M이 필요합니다. 위의 모델을 관계형 데이터베이스에 매핑하는 방식은 다음과 같이 엔티티 프레임워크*에서 표현됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
public class ShoppingCartMap : EntityTypeConfiguration { public ShoppingCartMap() { this.HasKey(m => m.Id); this.ToTable("ShoppingCart"); this.Property(m => m.User); this.Property(m => m.DateCreated); this.HasMany(m => m.Items) .WithOptional() .HasForeignKey(m => m.ShoppingCartId); } } public class ShoppingCartItemMap : EntityTypeConfiguration { public ShoppingCartItemMap() { this.HasKey(m => m.Id); this.ToTable("ShoppingCartItems"); this.Property(m => m.Name); this.Property(m => m.Price); this.Property(m => m.Quantity); } } |
*다른 OR/M도 유사한 매핑을 갖습니다.
이러한 매핑과 사용 사례 분석을 바탕으로 Couchbase에서 단일 문서로 모델링하기로 결정할 수 있었습니다. 쇼핑 카트 항목 맵 는 오직 OR/M이 어떻게 항목 속성의 쇼핑 카트. 또한 애플리케이션이 다음을 수행하지 않고 장바구니를 읽지 않을 가능성이 높습니다. 또한 항목을 읽어야 합니다.
이후 포스트에서 OR/M에 대해 더 자세히 설명할 예정이지만, 현재로서는 쇼핑 카트 맵 그리고 쇼핑 카트 항목 맵 클래스는 필요하지 않으며, 카우치베이스를 사용할 때는 Id 필드에서 항목 가 필요하지 않습니다. 실제로 Couchbase .NET SDK를 사용하면 쇼핑 카트 객체를 한 줄의 코드에서 OR/M 없이 사용할 수 있습니다:
|
1 2 3 4 |
public ShoppingCart GetCartById(Guid id) { return _bucket.Get(id.ToString()).Value; } |
그렇다고 해서 카우치베이스를 사용하면 항상 더 짧고 읽기 쉬운 코드를 만들 수 있다는 것은 아닙니다. 하지만 특정 사용 사례에서는 확실히 영향을 미칠 수 있습니다.
참조 예제
다음과 같은 관계를 정상화하는 것이 항상 가능하거나 최적의 방법은 아닙니다. 쇼핑 카트 예시. 대부분의 경우 한 문서가 다른 문서를 참조해야 하는 경우가 있습니다. 애플리케이션에서 읽기 및 쓰기를 수행하는 방식에 따라 참조를 사용하여 모델을 별도의 문서에 보관하는 것이 좋을 수 있습니다.
참조가 가장 좋은 접근 방식일 수 있는 예를 살펴보겠습니다. 애플리케이션에 소셜 미디어 요소가 있다고 가정해 보겠습니다. 사용자는 친구를 가질 수 있고 사용자는 텍스트 업데이트를 게시할 수 있습니다.
이를 모델링하는 한 가지 방법입니다:
- 개별 문서로서의 사용자
- 사용자를 참조하는 개별 문서로 업데이트
- 사용자 문서 내의 키 배열로서의 친구
사용자 두 명, 업데이트 두 개를 사용하면 Couchbase에 다음과 같은 4개의 문서가 생깁니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
[ // Key: "7fc5503f-2092-4bac-8c33-65ef5b388f4b" { "friends": [ "c5f05561-9fbf-4ab0-b68f-e392267c0703" ], "name": "Matt Groves", "type": "User" }, // Key: "c5f05561-9fbf-4ab0-b68f-e392267c0703" { "friends": [ ], "name": "Nic Raboy", "type": "User" }, // Key: "5262cf62-eb10-4fdd-87ca-716321405663" { "body": "Nostrum eligendi aspernatur enim repellat culpa.", "postedDate": "2017-02-02T16:19:45.2792288-05:00", "type": "Update", "user": "7fc5503f-2092-4bac-8c33-65ef5b388f4b" }, // Key: "8d710b83-a830-4267-991e-4654671eb14f" { "body": "Autem occaecati quam vel. In aspernatur dolorum.", "postedDate": "2017-02-02T16:19:48.7812386-05:00", "type": "Update", "user": "c5f05561-9fbf-4ab0-b68f-e392267c0703" } ] |
이 예제에서는 '친구'를 트위터와 같은 일방적인 관계로 모델링하기로 했기 때문에 Matt Groves는 닉 라보이를 친구로 두고 있지만 그 반대의 경우는 없습니다. (너무 확대해석하지 마세요, Nic :).
C#에서 이를 모델링하는 방법은 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
public class FriendbookUser { public Guid Id { get; set; } public string Name { get; set; } public virtual List Friends { get; set; } } public class Update { public Guid Id { get; set; } public DateTime PostedDate { get; set; } public string Body { get; set; } public virtual FriendbookUser User { get; set; } public Guid UserId { get; set; } } |
그리고 업데이트 에 친구북 사용자 관계는 다음 중 하나로 모델링할 수 있습니다. Guid 또는 다른 친구북 사용자 객체입니다. 이것은 구현 세부 사항입니다. 애플리케이션 요구 사항 및/또는 OR/M 작동 방식에 따라 둘 중 하나, 다른 하나 또는 둘 다를 선호할 수 있습니다. 두 경우 모두 기본 모델은 동일합니다.
다음은 엔티티 프레임워크에서 이러한 클래스에 사용한 매핑입니다. EF 또는 다른 OR/M 도구를 사용하는 방식에 따라 마일리지가 달라질 수 있습니다. OR/M 매핑 도구의 세부 사항이 아닌 기본 모델에 집중하세요.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
public class UpdateMap : EntityTypeConfiguration { public UpdateMap() { this.HasKey(m => m.Id); this.ToTable("FriendBookUpdates"); this.Property(m => m.Body); this.Property(m => m.PostedDate); this.HasRequired(m => m.User) .WithMany() .HasForeignKey(m => m.UserId); } } public class FriendbookUserMap : EntityTypeConfiguration { public FriendbookUserMap() { this.HasKey(m => m.Id); this.ToTable("FriendBookUsers"); this.Property(m => m.Name); this.HasMany(t => t.Friends) .WithMany() .Map(m => { m.MapLeftKey("UserId"); m.MapRightKey("FriendUserId"); m.ToTable("FriendBookUsersFriends"); }); } } |
이러한 엔티티를 별도의 문서로 저장하는 대신 쇼핑 카트 예시와 동일한 비정규화를 적용하여 사용자와 업데이트를 하나의 문서에 저장하려고 하면 몇 가지 문제가 발생할 수 있습니다.
- 친구 복제각 사용자는 친구를 위해 세부 정보를 저장합니다. 이제 사용자의 정보가 단일 소스가 아닌 여러 곳에 저장되기 때문에 이 방식은 지속 가능하지 않습니다(쇼핑 카트와 달리 같은 항목을 두 개 이상의 장바구니에 넣는 것은 도메인에 의미가 없을 수 있습니다). Couchbase를 캐시로 사용할 때는 괜찮을 수 있지만 기본 데이터 저장소로는 사용할 수 없습니다.
- 업데이트 크기: 정기적으로 사용하는 기간 동안 개별 사용자가 수백, 수천 개의 업데이트를 게시할 수 있습니다. 이로 인해 매우 큰 문서가 생성되어 I/O 작업 속도가 느려질 수 있습니다. 이 문제는 Couchbase의 하위 문서 API하지만 Couchbase는 문서당 용량이 20MB로 제한되어 있다는 점에 유의하세요.
참고: 여기에도 N+1 문제(친구의 친구 등)가 있지만 여기서는 이 문제를 해결하는 데 시간을 할애하지 않겠습니다. 두 데이터베이스에만 국한된 문제가 아니기 때문입니다.
또한 애플리케이션이 사용자를 읽거나 쓸 때 친구 및 업데이트를 읽거나 써야 하는 경우가 없을 수도 있습니다. 그리고 업데이트를 작성할 때 애플리케이션이 사용자를 업데이트해야 할 필요는 없습니다. 이러한 엔티티는 종종 자체적으로 읽거나 쓸 수 있으므로 별도의 문서로 모델링해야 합니다.
의 배열에 주목하십시오. 친구 필드에 있는 값과 사용자 문서의 사용자 필드를 입력합니다. 이 값은 관련 문서를 검색하는 데 사용할 수 있습니다. 이 글의 뒷부분에서는 키/값 연산을 사용하는 방법과 N1QL을 사용하는 방법에 대해 설명하겠습니다.
요약하자면, 문서 데이터베이스에서 데이터를 모델링하는 방법에는 두 가지가 있습니다. 사용된 쇼핑 카트 예제 중첩된 개체소셜 미디어 예제에서는 별도의 문서. 이러한 예에서는 비교적 간단하게 선택할 수 있었습니다. 직접 모델링 결정을 내릴 때 유용한 치트 시트가 있습니다:
| 만약 ... | 그렇다면 다음을 고려하세요... |
|---|---|
|
관계는 일대일 또는 일대다입니다. |
중첩된 개체 |
|
관계는 다대일 또는 다대다입니다. |
문서 분리 |
|
데이터 읽기는 대부분 상위 필드입니다. |
별도의 문서 |
|
데이터 읽기는 대부분 상위 + 하위 필드입니다. |
중첩된 개체 |
|
데이터 읽기는 대부분 상위 또는 자식(둘 다 아님) |
문서 분리 |
|
데이터 쓰기는 대부분 상위 그리고 자식(둘 다) |
중첩된 개체 |
키/값 연산
Couchbase에서 문서를 가져오려면 가장 간단하고 빠른 방법은 키로 요청하는 것입니다. 일단 친구북 사용자 문서가 있으면 다른 작업을 실행하여 관련 문서를 가져올 수 있습니다. 예를 들어, Couchbase에 키 2, 3, 1031에 대한 문서를 제공하도록 요청할 수 있습니다(일괄 작업으로). 그러면 각 친구에 대한 문서가 제공됩니다. 그런 다음 다음과 같은 작업을 반복할 수 있습니다. 업데이트등입니다.
키/값 연산이 매우 빠르며 RAM에서 직접 값을 가져올 가능성이 높기 때문에 속도 면에서 이점이 있습니다.
단점은 최소 두 가지 작업이 필요하다는 것입니다(친구북 사용자 문서를 가져온 다음 업데이트를 가져옵니다). 따라서 약간의 추가 코딩이 필요할 수 있습니다. 또한 문서 키를 구성하는 방법에 대해 더 신중하게 생각해야 할 수도 있습니다(나중에 자세히 설명합니다).
N1QL
Couchbase에서는 JSON용 SQL인 N1QL을 사용하여 쿼리를 작성할 수 있습니다. 여기에는 JOIN 키워드를 추가할 수 있습니다. 예를 들어 최신 업데이트 10건과 그에 해당하는 사용자를 가져오는 쿼리를 작성할 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public List GetTenLatestUpdates() { var n1ql = @"SELECT up.body, up.postedDate, { 'id': META(u).id, u.name} AS `user` FROM `sqltocb` up JOIN `sqltocb` u ON KEYS up.`user` WHERE up.type = 'Update' ORDER BY STR_TO_MILLIS(up.postedDate) DESC LIMIT 10;"; var query = QueryRequest.Create(n1ql); query.ScanConsistency(ScanConsistency.RequestPlus); var result = _bucket.Query(query); return result.Rows; } |
이 쿼리의 결과는 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[ { "body": "Autem occaecati quam vel. In aspernatur dolorum.", "postedDate": "2017-02-02T16:19:48.7812386-05:00", "user": { "id": "c5f05561-9fbf-4ab0-b68f-e392267c0703", "name": "Bob Johnson" } }, { "body": "Nostrum eligendi aspernatur enim repellat culpa eligendi maiores et.", "postedDate": "2017-02-02T16:19:45.2792288-05:00", "user": { "id": "7fc5503f-2092-4bac-8c33-65ef5b388f4b", "name": "Steve Oberbrunner" } }, // ... etc ... ] |
N1QL을 사용하면 데이터를 매우 유연하게 검색할 수 있습니다. 키만 사용해야 한다는 제약이 없습니다. 또한 SQL Server 사용자가 빠르게 익힐 수 있는 SQL의 상위 집합이기 때문에 쉽게 익힐 수 있습니다. 하지만 여기서는 인덱싱이 중요하다는 단점이 있습니다. SQL Server 인덱싱보다 훨씬 더 중요합니다. 쿼리를 작성한다고 가정해 보겠습니다. 이름 필드에 다음과 같은 인덱스가 있어야 합니다:
|
1 |
CREATE INDEX IX_Name ON `SocialMedia` (Name) USING GSI; |
그렇지 않으면 쿼리가 실행되지 않거나(인덱싱이 없는 경우) 성능이 저하됩니다(기본 인덱스만 생성한 경우).
참조를 사용할지 여부를 결정하는 데는 장단점이 있습니다.. 의 값은 친구 그리고 사용자 는 다른 문서를 참조한다는 점에서 외래 키와 유사합니다. 그러나 카우치베이스에서 값을 강제 적용하지는 않습니다. 이러한 키의 관리는 애플리케이션에서 적절하게 처리해야 합니다. 또한 Couchbase는 단일 문서 작업을 위한 ACID 트랜잭션을 제공하지만, 다중 문서 ACID 트랜잭션은 제공하지 않습니다.
애플리케이션 계층에서 이러한 주의 사항을 처리하는 방법은 이 시리즈의 이후 블로그 게시물에서 자세히 설명할 예정이니 계속 지켜봐 주세요!
주요 디자인 및 문서 차별화
관계형 데이터베이스에서 데이터 행은 (항상 그런 것은 아니지만 일반적으로) 기본 키에 해당하며, 이 키는 정수나 Guid인 경우가 많고 때로는 복합 키인 경우도 있습니다. 이러한 키는 반드시 의미가 있는 것은 아니며 테이블 내에서 행을 식별하는 데만 사용됩니다. 예를 들어, 서로 다른 두 테이블에 있는 두 행의 데이터가 동일한 키(예: 정수 값 123)를 가질 수 있지만, 그렇다고 해서 데이터가 반드시 연관되어 있다는 의미는 아닙니다. 관계형 데이터베이스에 적용되는 스키마는 그 자체로 의미를 전달하는 경우가 많기 때문입니다(예: 테이블 이름).
Couchbase와 같은 문서 데이터베이스에는 테이블 자체에 해당하는 것이 없습니다. 버킷의 각 문서에는 고유한 키가 있어야 합니다. 하지만 버킷에는 다양한 문서가 들어 있을 수 있습니다. 따라서 버킷 내에서 문서를 구분하는 방법을 생각해내는 것이 현명할 때가 많습니다.
의미 있는 키
예를 들어, 전적으로 가능한 일입니다. 친구북 사용자 키가 있는 문서에 123및 업데이트 키가 있는 문서에 456. 그러나 키에 시맨틱 정보를 더 추가하는 것이 좋습니다. 대신 123키를 사용하여 친구북 사용자::123. 키에 시맨틱 정보를 넣으면 다음과 같은 이점이 있습니다:
- 가독성: 문서의 용도를 한눈에 파악할 수 있습니다.
- 참조 가능성: 다음과 같은 경우
친구북 사용자::123문서에 키가 있는 다른 문서를 만들 수 있습니다.친구북 사용자::123::업데이트암묵적인 연관성이 있는 단어입니다.
N1QL을 사용할 계획이라면 이렇게 의미적으로 의미 있는 키가 필요하지 않을 수도 있습니다. 성능 측면에서 키가 짧을수록 RAM에 더 많은 키를 저장할 수 있습니다. 따라서 이 패턴은 N1QL 쿼리 대신 키/값 연산을 많이 사용할 계획인 경우에만 사용하세요.
판별자 필드
N1QL을 사용할 때 의미 있는 키와 함께 또는 대신 사용할 수 있는 또 다른 전략은 문서를 구분하는 데 사용되는 필드를 문서에 추가하는 것입니다. 이는 종종 유형 필드에 입력합니다.
|
1 2 3 4 5 6 |
{ "address" : "1800 Brown Rd", "city" : "Groveport", "state" : "OH", "type" : "address" } |
마법 같은 것은 없습니다. 유형 필드를 사용할 수 있습니다. 이 필드는 문서 내에서 예약어가 아니며 Couchbase Server에서 특별히 취급하지 않습니다. 다음과 같이 쉽게 이름을 지정할 수 있습니다. 문서 유형, theType등입니다. 하지만 애플리케이션 내에서 특정 종류의 문서를 쿼리하기 위해 N1QL을 사용할 때 유용할 수 있습니다.
|
1 2 3 |
SELECT d.* FROM `default` d WHERE d.type = 'address' |
한 단계 더 나아가 문서에 임베드된 객체를 추가하여 일종의 가짜 '메타 데이터' 역할을 할 수도 있습니다:
|
1 2 3 4 5 6 7 8 9 10 |
{ "address" : "1800 Brown Rd", "city" : "Groveport", "state" : "OH", "documentInfo" : { "type" : "address", "lastUpdated" : "1/29/2017 1:31:10 PM", "lastUpdatedBy" : "mgroves" } } |
일부 애플리케이션에서는 과할 수도 있습니다. 이는 관계형 데이터베이스 내에서 상속을 시뮬레이션하기 위한 '루트' 테이블이나 모든 테이블에 동일한 필드를 붙이는 등 관계형 데이터베이스에서 보았던 패턴과 유사합니다.
1부 결론
이 블로그 게시물에서는 비정규화를 사용한 데이터 모델링, 참조를 사용한 데이터 모델링, 키 디자인, 필드 식별에 대해 다뤘습니다. 문서 데이터베이스에서 데이터를 모델링하는 것은 기계적인 프로세스가 아니라 사고 과정이며 일종의 예술입니다. 문서 데이터베이스에서 데이터를 모델링하는 방법에 대한 정답은 없으며, 애플리케이션이 데이터와 상호 작용하는 방식에 따라 크게 달라집니다.
다음과 같이 전체 블로그 시리즈에 대한 소스 코드를 지금 깃허브에서 확인하세요.의 일부가 이 블로그 게시물에 소개되었습니다. 해당 코드의 다양한 부분에 대해 궁금한 점이 있으면 아래에 댓글을 남기거나 GitHub에서 이슈를 개설하세요.
다음 블로그에서는 데이터와 데이터 마이그레이션에 대해 다룰 예정이니 기대해 주세요.
[...] 데이터 모델링 [...]
[...] 데이터 모델링에 대한 첫 번째 블로그 게시물로 돌아가서, 관계형 [...]에 비해 다중 문서 트랜잭션의 필요성이 줄어들거나 제거되는 경우가 많습니다.
[...] SQL Server에서 Couchbase로 - 1부(데이터 모델링), 2부(데이터 마이그레이션), 3부 [...]
[...] JSON 데이터 모델링으로의 전환은 "SQL Server에서 Couchbase로 이동하기" 시리즈의 첫 번째 글에서 다룬 내용입니다. 그 블로그 게시물 이후, 최근 [...] Hackolade에서 몇 가지 새로운 도구가 제 관심을 끌었습니다.