이 게시물에서는 활동을 기록하는 기본 클라이언트를 구축하는 방법을 설명합니다. 스텔라 탈중앙화 블록체인. 스텔라는 점점 더 많은 새롭고 다양한 암호화폐 알트코인 및 토큰 목록을 호스팅하고 있습니다. 이 게시물의 코드를 사용하면 저장 및 쿼리를 위해 Couchbase를 사용하여 스텔라 계정에 보유한 자산에 대한 기본 쿼리 도구를 만들 수 있습니다.
준비물
카우치베이스
따라 하려면 7.0.2 이상의 최신 버전의 Couchbase를 설치하세요. 이전 버전에서도 대부분의 작업을 수행할 수 있지만 향후 게시물에서는 기본 제공되는 차트, 범위 또는 컬렉션에 액세스할 수 없습니다. 카우치베이스 카펠라 서비스형 데이터베이스도 간단한 무료 평가판을 통해 사용할 수 있으며, 온프레미스 또는 카우치베이스의 도커 버전.
기본 제공 Couchbase 관리자 UI 사용 - 다음을 선택합니다. 버킷 메뉴와 사이드바의 버킷 추가 버튼(오른쪽 상단)을 클릭합니다. 라는 버킷을 만듭니다. 스텔라로 이동합니다. 최소한의 메모리가 할당되어야 하며, 기본값은 300MB이므로 이 정도면 충분합니다.
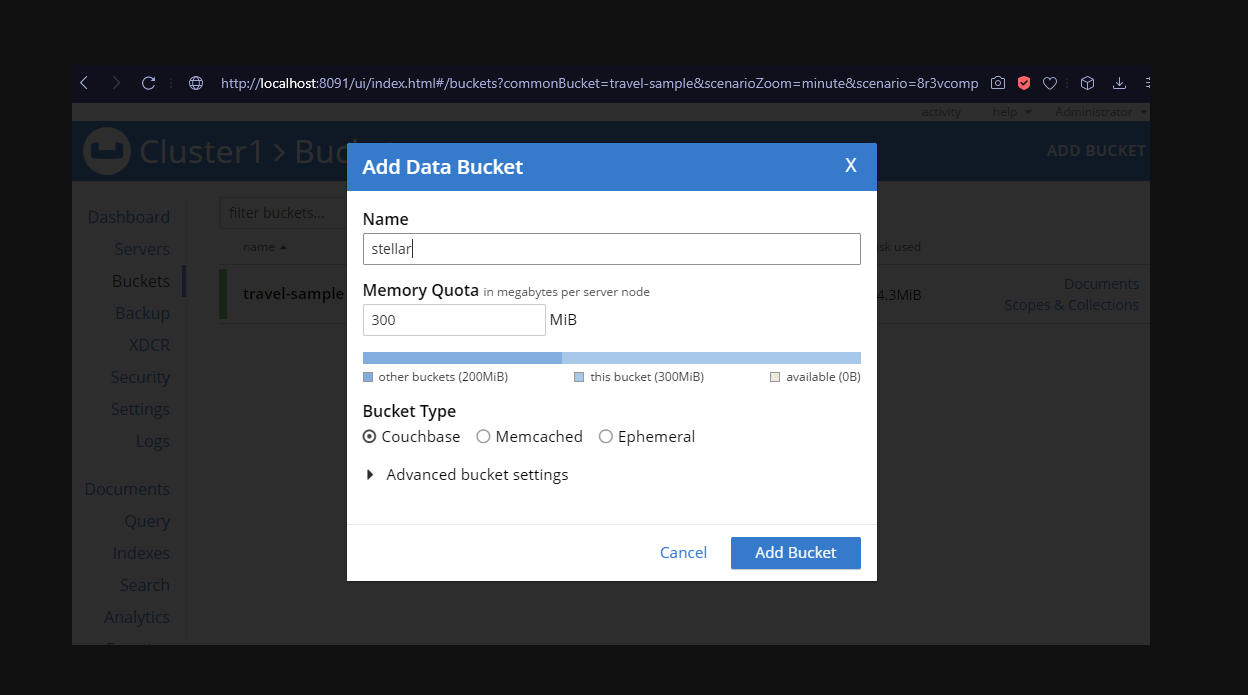
그림 1. Couchbase 클러스터에 새 데이터 버킷을 추가합니다.
그림 2와 같이 사용 가능함을 표시하는 녹색으로 바뀌기까지 예열하는 데 1분 정도 걸립니다.
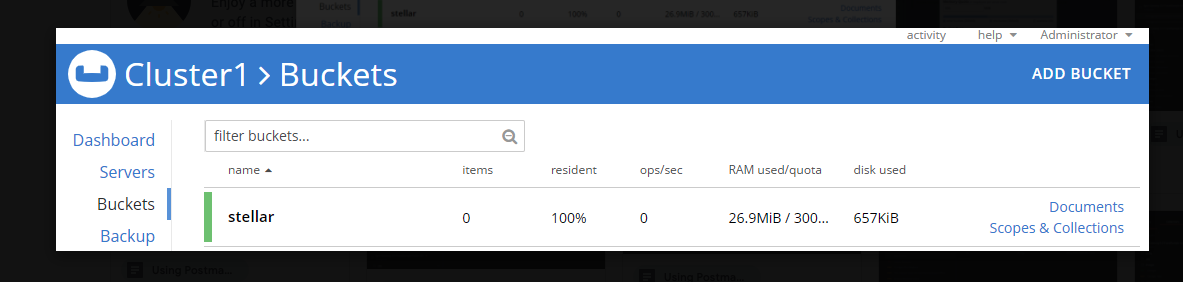
그림 2. 이제 새 버킷을 사용할 수 있습니다.
스텔라 지갑 주소
다음으로 모니터링할 스텔라 지갑 주소가 필요합니다. 흥미로운 계정을 찾으려면 Stellar.expert 및 해당 계정 브라우저 를 클릭해 지갑 ID를 찾습니다.
제 실험에서는 작지만 흥미로운 토큰 컬렉션이 있는 이 주소를 사용하고 있습니다:
|
1 |
GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ |
Python SDK
다음으로 Python 3과 Couchbase Python SDK를 사용하겠습니다. 파이썬 SDK를 설치하려면 pip 명령에 설명된 대로 문서. 또한 요청 패키지를 다운로드해야 합니다.
|
1 |
python3 -m pip install --upgrade pip setuptools wheel |
Python을 실행하고 Couchbase 모듈을 가져와서 설치를 테스트합니다:
|
1 2 3 4 5 |
tyler@megaserv:python-stellar$ python3 Python 3.8.10 (default, Nov 26 2021, 20:14:08) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import couchbase |
오류 없이 완료되면 완료된 것입니다. Press CTRL+D 를 클릭하여 종료합니다.
Couchbase에 연결
그리고 안녕하세요 카우치베이스 문서에 있는 예제는 Python 스크립트에 추가해야 하는 기본 연결 정보를 보여줍니다. 새 버킷에 연결하려면 최소한 다음이 필요합니다:
- 관리자 사용자 이름/비밀번호(또는 새 버킷에 대한 액세스 권한이 있는 사용자 이름/비밀번호)
- 카우치베이스 서버/클러스터의 이름/IP
- 새 버킷의 이름(예:, 스텔라)
라는 스크립트를 만듭니다. app.py:
|
1 2 3 4 5 6 7 |
from couchbase.cluster import Cluster, ClusterOptions from couchbase.auth import PasswordAuthenticator cluster = Cluster('couchbase://localhost', ClusterOptions( PasswordAuthenticator('Administrator', 'Administrator'))) cb = cluster.bucket('stellar') |
계속하기 전에 스크립트를 실행하여 오류가 발생하는지 확인할 수 있습니다.
Stellar.org 계정 스키마 검토하기
이 프로젝트의 경우 계정 정보를 직접 다운로드합니다. 스텔라 웹 API 를 호출하고 나중에 쿼리할 수 있도록 Couchbase에 원시 JSON 데이터를 저장합니다.
Stellar 계정에 액세스하려면 Horizon 서비스를 사용하여 해당 계정의 /공개/자산 엔드포인트. 예를 들어, 저는 Postman.co 을 사용하여 그림 3과 같이 스키마에 대한 느낌을 얻기 위해 결과 JSON을 빠르게 볼 수 있습니다.
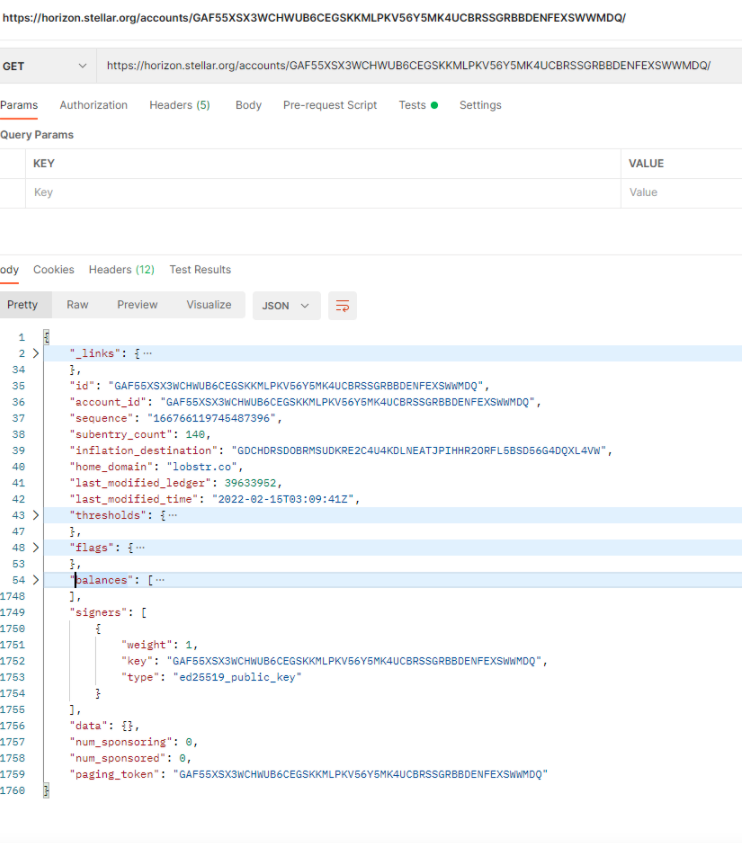
그림 3. Stellar 계정 JSON 문서 샘플.
그림에서 몇 가지 개체와 목록을 축소하여 더 명확하게 볼 수 있도록 했습니다. 다음과 같은 루트 수준 요소는 계정_id, 서브엔트리_수및 마지막_수정_시간 는 잠재적으로 유용할 수 있습니다. 하지만 대부분의 항목은 잔액 객체, 실제로는 거의 1700줄에 달합니다.
아래 그림 4에서 자산 보유자의 핵심과 감자를 좀 더 자세히 살펴보겠습니다.
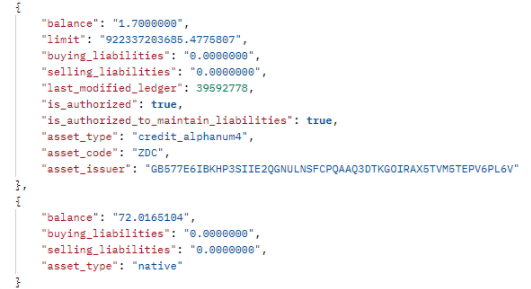
그림 4. 잔액 목록의 두 항목.
위 그림에는 두 가지 유형의 잔액이 표시되어 있습니다. 표시되지 않은 수십 개의 다른 잔액이 있지만 모두 여기에 표시된 첫 번째 잔액과 유사합니다. 토큰 수 잔액(1.7), 자산_코드(ZDC 는 조디악 토큰), 그리고 자산 발행자 주소(여러 계정이 동일한 자산을 발행할 수 있으므로)를 입력합니다. 또한 자산 유형 (credit_alphanum4).
위의 두 번째 항목은 유일하게 다른 자산 유형 목록에서 (네이티브). 이 경우 계정 수준의 기본 잔액, 즉 소유자의 Lobstr 지갑 네이티브 토큰입니다. 스텔라 루멘 (XLM). 이 잔액은 자산 거래 계좌를 통해 다른 자산의 잔액과 교환할 수 있으며 그 반대의 경우도 마찬가지입니다.
워크플로 계획
위의 내용을 염두에 두고 관심 있는 모든 정보를 저장하고 액세스하는 방법을 계획할 수 있습니다. 그렇다면 우리는 무엇에 관심이 있을까요?
먼저 계정에 대한 통계를 매일 업데이트하고 싶습니다. 따라서 매일 스크립트를 실행하여 데이터베이스의 정보를 업데이트한다고 가정해 보겠습니다.
현재 잔액은 기본 XLM 금액과 다른 토큰 잔액을 포함하여 알면 좋습니다. 우리가 저장하는 문서에 이러한 세부 정보를 보관하는 한, 언제든지 조회할 수 있습니다. 또한 문서가 새로운 항목으로 덮어쓰이지 않도록 키가 일종의 타임스탬프 또는 증분 ID인지 확인해야 합니다.
다른 문서에서 기본 합계 등을 최신 상태로 유지하기 위해 중간 계산을 할 수도 있지만 이는 다음 게시물에 남겨두겠습니다.
다음 두 단계는 이 JSON 문서를 다운로드한 다음 Couchbase에 업로드하는 것입니다. 그런 다음 웹 콘솔 UI에서 결과를 살펴보고 쿼리와 차트를 테스트해 보겠습니다.
Python으로 스텔라 계정 데이터 다운로드하기
물론 이것은 앞으로 몇 주에 걸쳐 구축할 수 있는 매우 간단한 예시입니다.
웹 API에 액세스하려면 Python 요청 모듈을 사용하여 결과를 JSON 객체에 저장합니다.
|
1 2 3 4 5 6 7 8 9 |
import requests url = "https://horizon.stellar.org/accounts/GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ/" response = requests.request("GET", url) jsondoc = response.json() #for key, value in jsondoc.items(): # print(key, ":", value) |
아주 보기 흉한 형태로 인쇄하는 것이 얼마나 쉬운지 보여드리기 위해 간단한 루프 예제를 포함했습니다. 더 예쁜 인쇄 기술이 있지만 여기서는 코드를 더 작성하는 대신 Couchbase에 내장된 기술을 사용하여 더 쉽게 만들겠습니다.
카우치베이스에 JSON 문서 보내기
다음으로 Couchbase 버킷 객체를 사용하여 업서트 호출을 수행합니다. Upsert 는 문서 또는 데이터베이스 삽입 문과 동일하지만 이미 존재하는 경우 기존 문서를 업데이트합니다. 우리의 경우 고유 ID를 생성하여 문서 ID로 사용하려고 합니다.
를 사용하여 유닉스 타임스탬프를 추가해 보겠습니다. 시간 모듈을 생성하고 파이썬 SDK 시작 가이드에 표시된 대로 키를 빌드하며, 여기에는 몇 가지 기본 예외 캡처도 포함되어 있습니다.
모든 것을 종합하기
이제 한 걸음 물러나서 모든 것을 구분하고 재사용 가능성을 높이기 위해 다양한 함수로 구축된 통합 코드 예제를 살펴보겠습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import requests, time from couchbase.cluster import Cluster, ClusterOptions from couchbase.auth import PasswordAuthenticator account = 'GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ' def connect(): cluster = Cluster('couchbase://localhost', ClusterOptions(PasswordAuthenticator('Administrator', 'Administrator'))) return cluster.bucket('stellar') def getjson(): url = "https://horizon.stellar.org/accounts/%s/" % account print("Fetching: " + url) response = requests.request("GET", url) return response.json() def upsert_document(connection, doc): now = int( time.time() ) try: key = str(now) + "_" + account[:5] result = connection.upsert(key, doc) print(result) except Exception as e: print("Error",e) cb = connect() json = getjson() upsert_document(cb, json) |
결과에는 사용된 웹 API URL이 나열되고 오류 또는 작업 결과 세부 정보:
|
1 2 3 4 |
$ python app.py Fetching: https://horizon.stellar.org/accounts/GAF55XSX3WCHWUB6CEGSKKMLPKV56Y5MK4UCBRSSGRBBDENFEXSWWMDQ/ OperationResult<rc=0x0, key='1644906573_GAF55', cas=0x16d3e1d051760000, tracing_context=0, tracing_output=None> |
웹 콘솔에서 토큰 결과 보기
스크립트를 몇 번 실행하면 이제 프로젝트 버킷에 몇 개의 문서가 있을 것입니다. 프로젝트 버킷에서 스텔라 버킷을 누른 후 문서 버튼(오른쪽 상단)을 클릭하면 상호 작용할 수 있는 문서 목록이 표시되며, 그림 5와 같이 한 가지 결과가 표시됩니다.
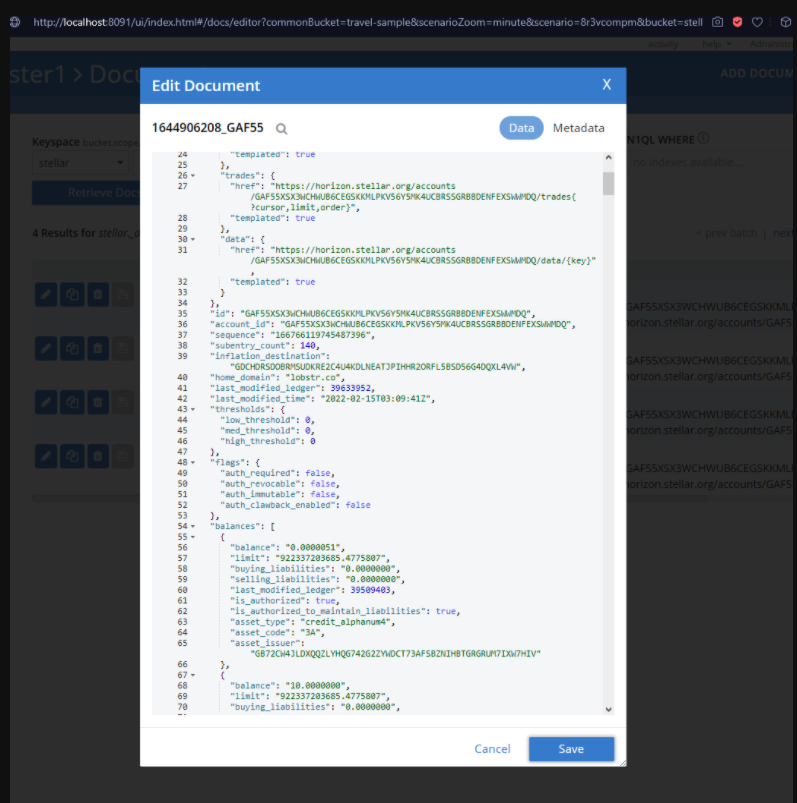
그림 5. Couchbase 웹 콘솔에서 열린 Stellar 계정 문서 샘플.
쿼리를 사용하려면 몇 가지 인덱스를 만들어야 합니다. 인덱스의 쿼리 탭을 클릭하고 다음을 입력합니다. N1QL 쿼리 문을 사용하여 몇 가지 인덱스를 설정할 수 있습니다. 기본 문서 컬렉션을 사용하고 있으므로 버킷 이름 앞에 이를 나타내는 접두사를 붙였습니다. (향후 게시물에서는 다양한 목적에 따라 문서를 분리하고 이를 위해 컬렉션을 사용하겠습니다.)
|
1 2 3 4 |
create primary index on default:stellar; create index idx_account_id on default:stellar(id); create index idx_modified on default:stellar(last_modified_time); create index idx_entrycount on stellar(subentry_count); |
각기 다른 자산에 대해:
|
1 2 3 4 |
create index idx_asset_code on stellar(balances.asset_code); create index idx_asset_type on stellar(balances.asset_type); create index idx_asset_issuer on stellar(balances.asset_issuer); create index idx_asset_balance on stellar(balances.balance); |
그런 다음 기본 쿼리로 인덱스를 테스트합니다:
|
1 |
select count(*) from stellar; |
그리고 결과 창에 버킷의 문서 수와 함께 기본 출력이 표시되어야 합니다(이 경우), 7 문서에 표시된 것처럼
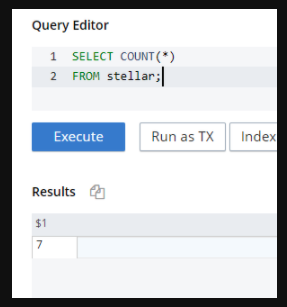
그림 6. 버킷의 문서 수를 계산하는 샘플 쿼리.
JSON 문서 집합에서 속성 쿼리하기
N1QL은 표준 SQL과 매우 유사하지만 JSON 인텔리전스가 내장되어 있으므로 쿼리를 쉽게 작성할 수 있습니다. 다음과 같은 함수를 통해 항목에 액세스할 수 있습니다. 잔액 목록 객체를 마치 각 열인 것처럼 사용합니다. 사용 UNNEST, 각 하위 항목은 쿼리에서 액세스 가능한 필드 이름이 됩니다.
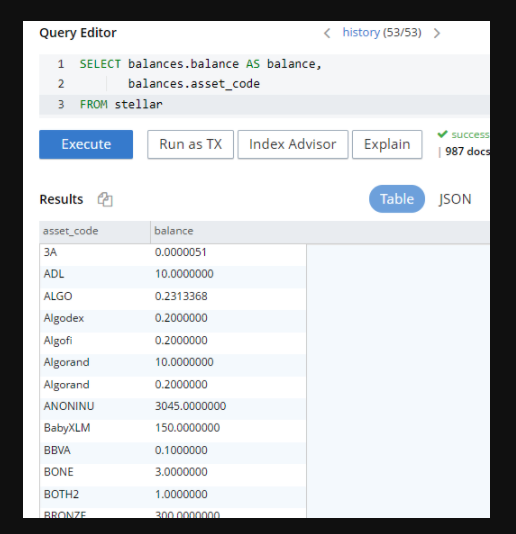
예를 들어, 다음 쿼리는 모든 자산과 잔액을 나열합니다:
|
1 2 3 |
SELECT balances.balance AS balance, balances.asset_code FROM stellar UNNEST balances |
쿼리 창에는 기본적으로 JSON으로 결과가 표시되지만 테이블 옵션으로 전환하여 지금까지의 결과를 확인할 수 있습니다:
다음 단계
다음 글에서는 좀 더 깊이 들어가서 차트를 만들고 쿼리 마법을 사용해 보겠습니다.
다음은 논의한 주제에 대해 자세히 알아볼 수 있는 몇 가지 추가 링크입니다:
- 카우치베이스 파이썬 SDK 사용 시작하기
- Couchbase N1QL 점검표(PDF)
- 스텔라 탈중앙화 거래소(stellar.org)
- 블록체인 기본 사항
- Stellar 개발자 API 문서(계정)
- 스텔라 루멘 - XLM - 미래의 토큰