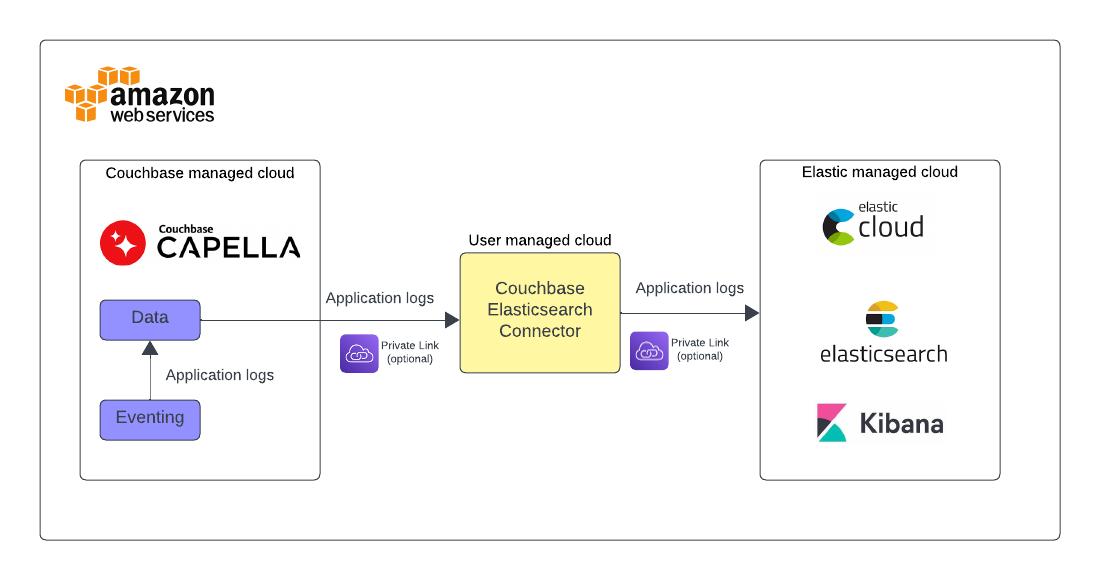
이 블로그 포스팅에서는 효율적인 Eventing 애플리케이션 로그 전송 및 분석을 위해 Couchbase Capella를 ElasticSearch 및 AWS 서비스와 함께 사용하는 방법을 보여드리겠습니다.
카우치베이스 카펠라 는 다중 모델 NoSQL 클라우드 데이터 플랫폼입니다. 문서 데이터베이스 서비스 중 최고의 가격 대비 성능으로 대규모로 밀리초 단위의 데이터 응답을 제공합니다. Capella 이벤트 서비스를 사용하면 Capella의 데이터에 변경 사항이 있을 때 사용자 정의 비즈니스 로직을 실시간으로 트리거할 수 있습니다. 일반적인 사용 사례로는 문서 보강, 계단식 삭제, 데이터베이스 내부의 데이터 변경 사항 전파 등이 있습니다.
Elastic 스택(ELK 스택이라고도 함)은 강력한 중앙 집중식 로깅 솔루션을 제공하여 인사이트를 생성하고, KPI에 따라 경보를 설정하고, 애플리케이션 동작을 추적할 수 있습니다.
Capella Eventing 함수는 UI의 데이터 도구 Eventing 편집기를 사용하여 쉽게 만들 수 있습니다. 애플리케이션 로그를 이벤트화하면 사용자는 각 이벤트 기능에 특정한 사용자 정의 메시지를 통해 다양한 비즈니스 로직 관련 활동과 오류를 식별하고 캡처할 수 있습니다. 애플리케이션 로그는 Capella UI에서 볼 수 있지만, 전문 로깅 솔루션을 사용해 중앙 집중식으로 로그를 관리하고 분석하는 것이 많은 시나리오에서 유용할 수 있습니다. 이 블로그에서는 Eventing 애플리케이션 로그를 Elastic으로 가져오는 방법과 중앙 집중식 로그 저장 및 분석에 도움이 되는 단계별 지침을 보여드립니다.
전제 조건
-
- 데이터 및 이벤트 서비스를 통한 카우치베이스 카펠라 배포. 가입하기 를 클릭하여 평가판 계정을 신청하세요.
- ElasticSearch 클라우드 배포. 가입하기 를 클릭하여 평가판 계정을 신청하세요.
- AWS 계정 실행을 위한 EC2 인스턴스 Couchbase ElasticSearch 커넥터 다운로드할 수 있습니다. 여기.
필요한 단계 개요
아카펠라 클러스터 설정: 데이터 및 이벤트 서비스로 카펠라 클러스터를 생성하는 것으로 시작하세요. 빠른 가이드는 다음에서 확인할 수 있습니다. 카우치베이스 카펠라 문서.
버킷/범위/컬렉션 생성: Couchbase에서 필요한 버킷, 범위 및 컬렉션을 만듭니다. 여기에는 '데이터', '이벤트-로그' 및 각각의 범위와 컬렉션이 포함됩니다.
이벤트 함수 준비: 데이터 수집 및 변환을 위한 이벤트 함수를 준비합니다. 여기에는 합성 데이터 세트를 생성하고 로그를 생성하도록 수정하는 작업이 포함됩니다.
ElasticSearch 클러스터 및 인덱스 생성: 효율적인 데이터 처리를 위해 ElasticSearch 클러스터를 설정하고 인덱스를 생성하세요.
VPC 및 비공개 링크 설정: Elastic Connector를 위한 새 VPC를 생성하고 Couchbase Capella에서 VPC로의 비공개 링크를 설정합니다.
ElasticSearch 트래픽 필터: 안전한 데이터 전송을 위해 트래픽 필터링을 구현합니다.
Couchbase ElasticSearch 커넥터 설치 및 실행: EC2 머신에 Couchbase ElasticSearch 커넥터를 설치하고 로그 전송을 위해 구성합니다.
데이터 시각화 및 분석: 수집된 데이터 소스를 사용하여 로그를 시각화하고 분석하여 로그를 통해 얻을 수 있는 인사이트를 탐색합니다.
세부 구성
카우치베이스 환경
두 개의 버킷과 그 범위 및 컬렉션을 만들어야 합니다. 한쪽에는 데이터와 이벤트 함수를 관리하는 데 필요한 모든 것을 만들 것입니다. 다른 쪽에는 이벤트 함수에 의해 생성된 로그 전용의 두 번째 버킷을 만들겠습니다.
이 간단한 활동의 기초는 다음에서 찾을 수 있습니다. 카우치베이스 카펠라 문서 를 참조해 원리와 관련된 작업을 설명하세요. 버킷을 만들려면 몇 가지 설정을 구성해야 하는데, 그 중 가장 중요한 설정은 메모리 할당량입니다. 테스트 목적으로 100MB를 선택할 수 있으며, 그렇지 않으면 정확한 평가 가 필요합니다.
다음과 같은 구조의 버킷 두 개를 만듭니다:
-
- 이름: "데이터"
- 범위 이름: "이벤트"
- 컬렉션 이름: "메타"
이벤트 함수 체크포인트용 스토리지
- 컬렉션 이름: "메타"
- 범위 이름: "인벤토리"
- 컬렉션 이름: "데이터"
실제 데이터를 위한 스토리지
- 컬렉션 이름: "데이터"
- 범위 이름: "이벤트"
- 이름: "이벤트 로그"
- 범위 이름: "이벤트"
- 컬렉션 이름: "로그"
로그 저장소. 선택적으로 TTL을 설정하여 저장 용량을 줄일 수 있습니다.
- 컬렉션 이름: "로그"
- 범위 이름: "탄력적 체크포인트"
- 컬렉션 이름: "커넥터"
카우치베이스-엘라스틱서치 커넥터용 스토리지 체크포인트
- 컬렉션 이름: "커넥터"
- 범위 이름: "이벤트"
- 이름: "데이터"
데이터 모집단
이제 두 개의 이벤트 함수를 만들어 보겠습니다. 이벤트 함수를 처음 만드는 경우 환경에 익숙해질 수 있습니다. 이 가이드를 따르십시오..
이러한 기능의 목적은 다음과 같습니다:
-
- 첫 번째 기능작업할 수 있는 데이터를 만듭니다. 제품 카탈로그를 나타내는 데이터 세트입니다.
이 함수는 간단한 json 문서를 생성하여 100,000회 반복에 걸쳐 약간의 가변성을 도입합니다. 이것은 실제 제품 카탈로그는 아니지만, 작동 방식을 기록해야 하는 이벤트 함수를 실험하기 위한 좋은 기반이 됩니다. 이 함수는 빈 문서를 생성하여 처음으로 트리거된다는 점에 유의하세요. - 두 번째 기능ELK 스택을 통해 관찰하고자 하는 일부 비즈니스 로직이 포함된 실제 이벤트 함수입니다.
- 첫 번째 기능작업할 수 있는 데이터를 만듭니다. 제품 카탈로그를 나타내는 데이터 세트입니다.
이벤트 함수는 모든 새 데이터 집합에서 무제한으로 실행되지만, 프로퍼티를 대체합니다. 카테고리 값과 일치할 때마다 "카테고리 3"를 입력하면 이 값이 "청바지". 함수의 여러 부분에서 다음과 같은 함수가 편리하게 호출되는 것을 관찰할 수 있습니다. logStuff: 그 목적은 전용 컬렉션에 로그 행을 저장하여 나중에 ElasticSearch에 복제하고 색인을 생성하는 것입니다.
데이터 모집단 함수
다음 구성으로 이벤트 함수를 만듭니다:
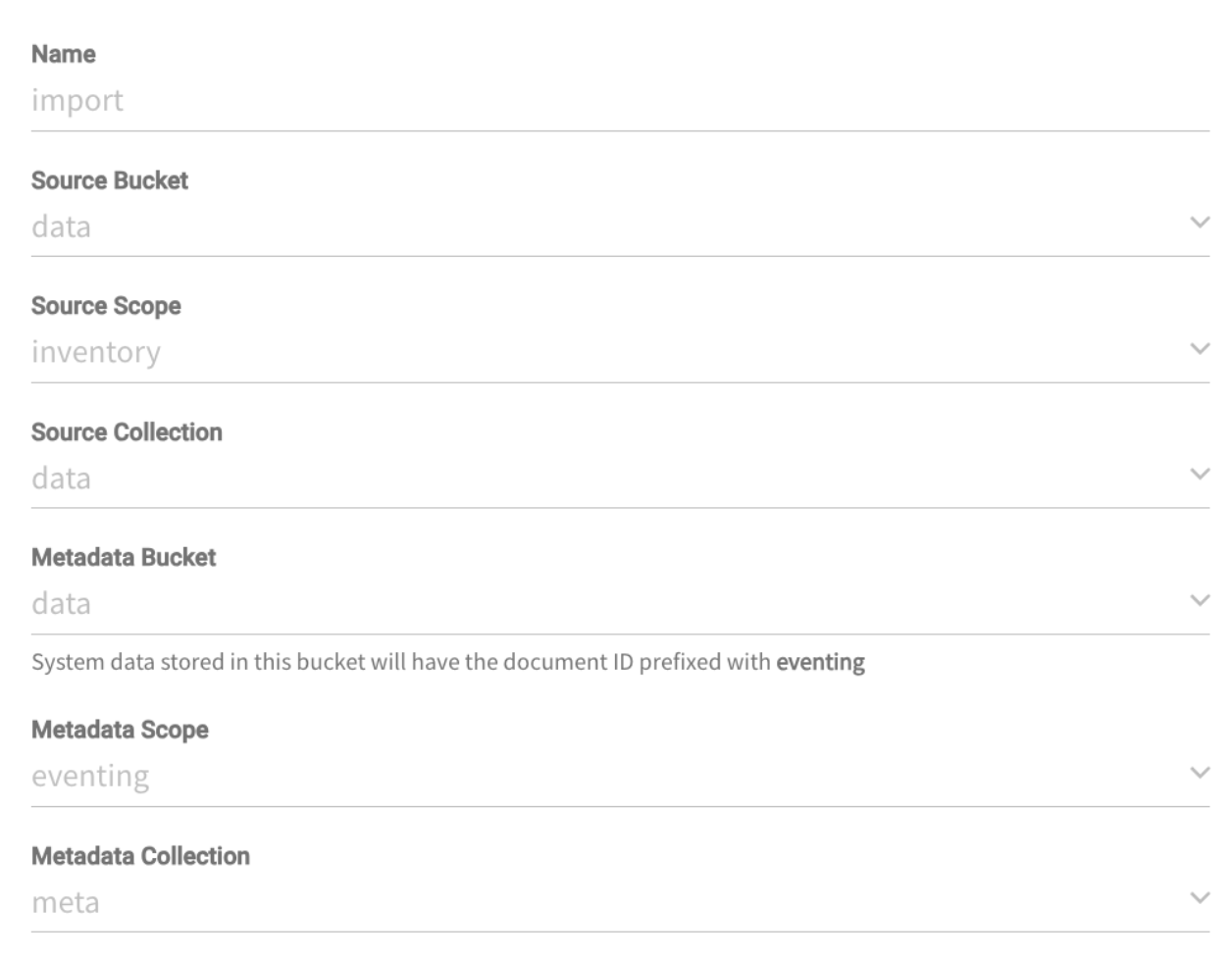
그리고 다음과 같은 버킷 바인딩이 있습니다:
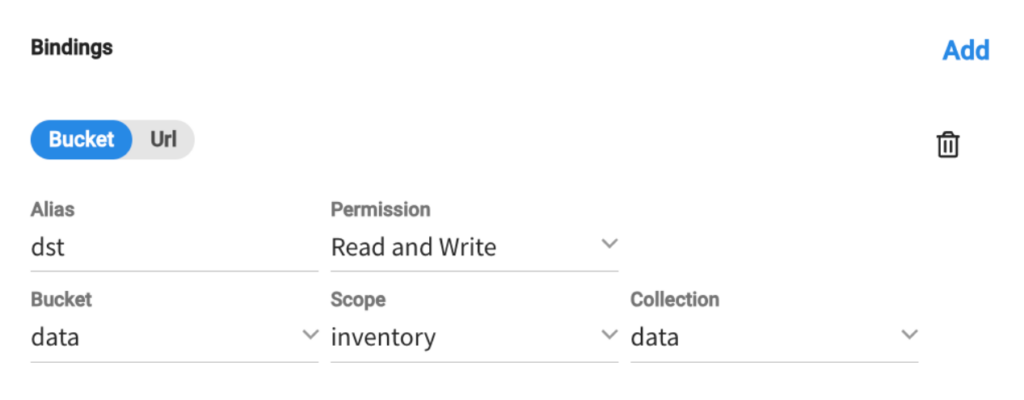
기능은 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
함수 온업데이트(doc, 메타) { // 문서 업데이트 처리를 위한 플레이스홀더 기능 만약(메타.id == 'start') { 에 대한(let i = 1; i <= 100000; i++) { var 항목 = { "type": "inventoryItem", "itemId": i, "name": "항목" + i, "가격": 수학.무작위() * 100, // 0에서 100 사이의 임의 가격 "inStock": true, "category": "카테고리" + (i % 10) // 10가지 카테고리 }; var 키 = "item_" + i; dst[키] = 항목; } } } 함수 OnDelete(메타) { // 문서 삭제 처리를 위한 플레이스홀더 기능 } |
함수가 문서를 가져오는 순간 data.inventory.data ID로 시작를 입력하면 100,000개의 무작위 문서가 생성됩니다.
참고: 이 문서를 생성하려면 다음 페이지로 이동하면 됩니다. 데이터 도구 탭에서 문서 을 클릭한 다음 새 문서 만들기 버튼(올바른 컬렉션을 선택하는 것을 잊지 마세요! 데이터 -> 인벤토리 -> 데이터).
데이터 변환 기능
이 두 번째 함수는 나중에 ELK 스택에서 사용할 임시 저장소에 로그를 보존하는 방법을 보여줍니다. 비즈니스 로직을 수행하는 동안 data.inventory.data 컬렉션에 일부 애플리케이션 로그를 저장합니다. eventing-logs.eventing.logs 를 생성하여 나중에 ElasticSearch로 내보낼 수 있도록 합니다.
구성입니다:
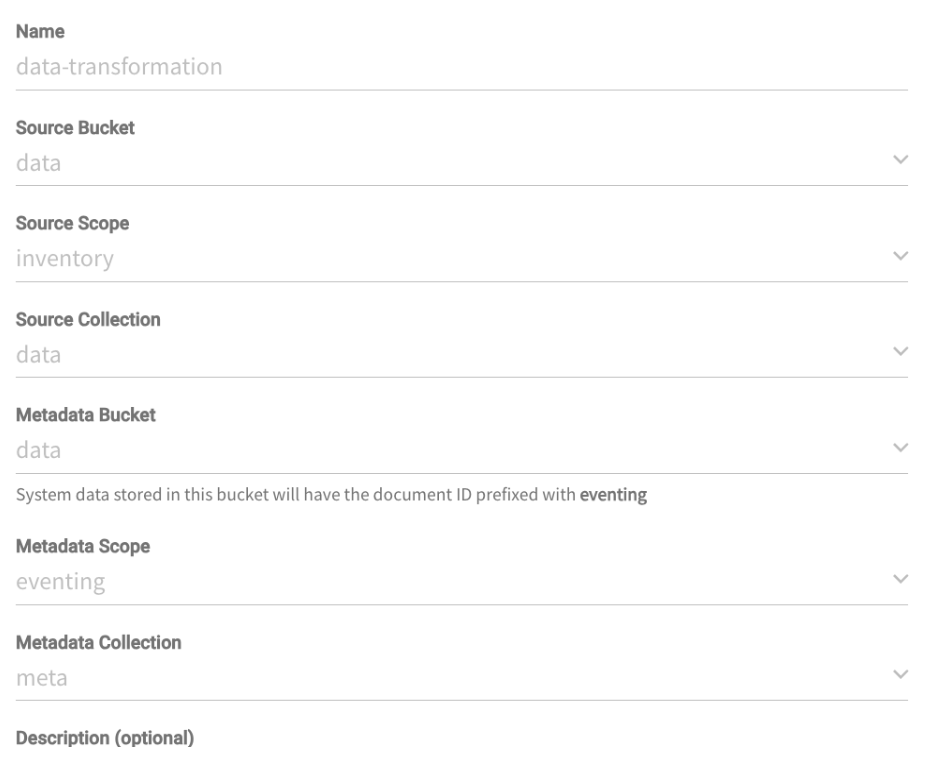
바인딩:
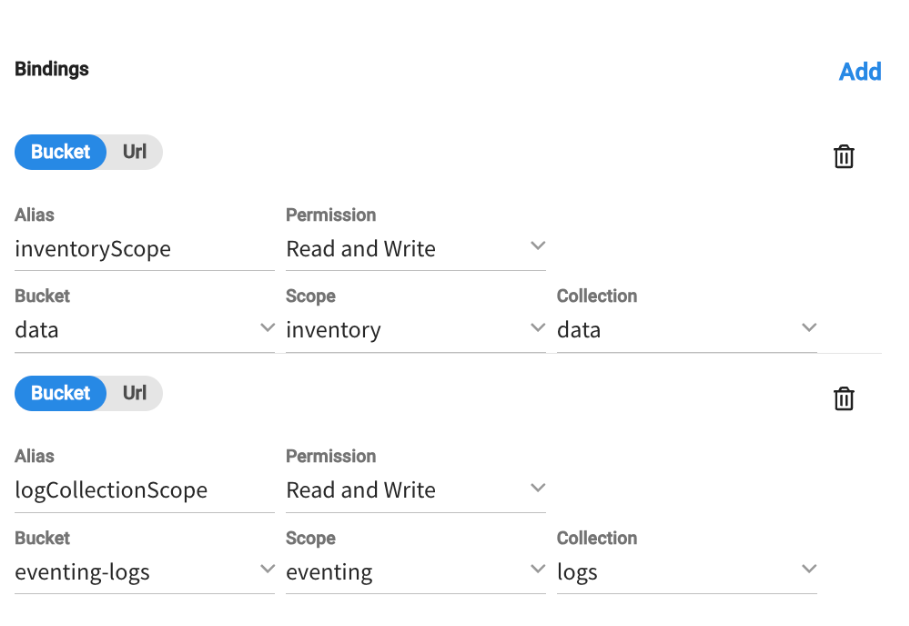
기능:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
함수 온업데이트(doc, 메타) { logStuff("debug", "평가 시작" + 메타.id); 만약(doc.카테고리 == "카테고리 3") { logStuff("정보", "수정 시작" + 메타.id); doc.카테고리 = "jeans"; 인벤토리 범위[메타.id] = doc; logStuff("정보", "수정 종료" + 메타.id); } logStuff("debug", "평가 종료" + 메타.id); } 함수 OnDelete(메타, 옵션) { } 함수 simpleHash(str) { let 해시 = 0; 에 대한 (let i = 0; i < str.길이; i++) { const char = str.charCodeAt(i); 해시 = (해시 << 5) - 해시 + char; 해시 &= 해시; // 32비트 정수로 변환 } 반환 new Uint32Array([해시])[0].toString(36); } 함수 logStuff(레벨, 메시지) { var 날짜 = new 날짜(); 날짜.toISOString(); var 로그 라인 = { "@타임스탬프": 날짜, "log": { "level": 레벨, "logger": "couchbase.eventing", "origin": { "function": "데이터-변환-고양이-3-투-티" }, "original": 메시지 }, "메시지": 메시지, "ecs": { "버전": "1.6.0" } } var logEntryId = "데이터 변환-" + 수학.floor(수학.무작위() * 10000000) + 날짜; 로그 수집 범위[simpleHash(logEntryId)] = 로그 라인; } |
이 함수는 특정 범주의 데이터를 수정하고 레이블을 변환하는 역할을 담당합니다. 이 과정에서 나중에 ELK 스택으로 분석할 로그를 통해 함수가 어떻게 수행되는지 추적해야 합니다.
그리고 logStuff 함수는 ECS 호환 형식의 JSON 문서를 생성하여 별도의 버킷에 보관합니다.
이벤트 함수가 생성되면 다음 사항을 기억하세요. 배포 그것.
데이터 세트가 생성되고 변환 함수가 실행되면 ElasticSearch로 전송할 준비가 된 로그 버킷이 채워져야 합니다.
참고: 충돌을 피하기 위해 로그 행은 공간을 절약하기 위해 타임스탬프와 임의의 숫자를 나중에 해시 처리하여 생성됩니다.
Elastic Cloud 구성
데이터 동기화를 시작하기 전에 ElasticSearch에서 인덱스를 생성해야 합니다. Elasticsearch 엔드포인트 URL 를 만들고 API 키 관리 권한이 있습니다.
다음은 CURL 예제입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
curl -X PUT "https://:443/couchbase-ecs" \ -H "권한 부여: ApiKey"<당신의 API 키>"" \ -H "콘텐츠 유형: 애플리케이션/json" \ -d ' { "설정": { "number_of_shards": 1, "number_of_replicas": 1 }, "매핑": { "속성": { "@타임스탬프": { "type": "날짜" }, "log": { "속성": { "level": { "type": "키워드" }, "logger": { "type": "키워드" }, "origin": { "속성": { "function": { "type": "키워드" } } }, "원본": { "type": "텍스트" } } }, "메시지": { "type": "텍스트" }, "ecs": { "속성": { "버전": { "type": "키워드" } } } } } }' |
인덱스는 로거의 데이터 유형을 매핑하여 효율적으로 검색할 수 있도록 합니다.
ElasticSearch 커넥터
네트워크 구성
EC2 머신으로 VPC를 생성해야 합니다. 공용 IP 주소로 를 호스팅할 인스턴스를 생성합니다. 이 테스트에는 2-4 cpus의 일반 EC2 인스턴스가 적합합니다(저희는 t2.medium을 사용했습니다). 물론 이것이 프로덕션 환경이 될 경우, 이 머신의 규모를 평가하는 것이 이 배포를 위한 중요한 단계가 될 것입니다.
다음 단계는 새로 만든 VPC와 새로 만든 VPC 간의 연결을 보호하는 것입니다:
-
- 카우치베이스 아카펠라, 그리고
- Elastic Cloud
가장 실용적인 방법(테스트 목적으로만!)은 공용 연결을 사용하는 것입니다. Capella 클러스터 설정에서 다음을 수행해야 합니다. EC2 인스턴스의 공용 IP를 화이트리스트에 추가합니다. 를 사용하여 Elasticsearch 커넥터가 데이터베이스에 대한 연결을 설정할 수 있도록 합니다. Elastic Cloud의 경우, 그 대신에 API 키.
비공개 링크를 통해 이동할 수 있는 대안도 있으며, 자세한 설명서는 여기에서 확인할 수 있습니다:
카우치베이스-엘라스틱서치 커넥터
EC2 인스턴스를 프로비저닝한 후에는 Couchbase 웹사이트에서 실행 파일을 다운로드해야 합니다. 그 전에 다음을 살펴보시기 바랍니다. 요구 사항에서 그리고 여기에서 다운로드.
이제 다음과 같이 수정하여 구성해야 합니다. $CBES_HOME/config/default-connector.toml 파일을 만듭니다.
다음은 공감을 불러일으킬 만한 몇 가지 섹션이며, 간결하게 하기 위해 일부 섹션은 삭제했습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
[그룹] 이름 = 'example-group' [그룹.정적] 회원번호 = 1 # 1에서 '총회원수'를 포함한 값입니다. 총회원 = 1 [...] [카우치베이스] 호스트 = [''] 네트워크 = 'auto' 버킷 = '이벤트-로그' 메타데이터버킷 = '이벤트-로그' 메타데이터 컬렉션 = 'elastic-checkpoints.connector' # 카펠라 사용자 아이디 사용자 이름 = 'hello' # 비밀번호로 이 파일을 수정하는 것을 잊지 마세요. 경로 비밀번호 = 'secrets/couchbase-password.toml' #C아카펠라 환경은 항상 안전합니다. 보안 연결 = true [...] [엘라스틱서치] 호스트 = ['https://:443'] 사용자 이름 = '탄력적' # ElasticSearch ApiKey로 이 파일을 수정하는 것을 잊지 마세요. 경로 비밀번호 = 'secrets/elasticsearch-password.toml' 보안 연결 = true [...] [엘라스틱서치.elasticCloud] 활성화 = true [...] # 참이면 Elasticsearch에서 일치하는 문서를 절대 삭제하지 마세요. 무시삭제 = true [[엘라스틱서치.유형]] matchOnQualifiedKey = true 접두사 = 'eventing.logs. 색인 = 'couchbase-ecs' [...] |
모범 사례 및 팁
다음은 몇 가지 유의해야 할 사항입니다:
-
- Couchbase ElasticSearch 커넥터 - -. 데이터 유형을 올바르게 입력했는지 확인하세요, [[elasticsearch.type]]. 이 작업이 제대로 수행되지 않으면 커넥터가 데이터를 공급하지 않습니다.
- 카우치베이스 카펠라 - 커넥터의 데이터베이스 자격 증명을 만드는 것을 잊지 마세요!
- ElasticSearch
- 인덱스가 생성되면 인사이트를 구축할 수 있는 데이터 소스를 만들 수 있습니다.
- 관리 목적(예: 인덱스 생성) 또는 애플리케이션(예: 커넥터를 통한 데이터 전송) 용도로 ApiKey를 만들 수 있습니다. 올바른 것을 사용하고 있는지 확인하세요.
- 데이터 보존
- 로그를 저장하면 디스크가 많이 소모될 수 있습니다. 이를 방지하려면 다음과 같이 하세요:
- 삭제 알림을 ElasticSearch 커넥터에서 제외하는 경우 무시 삭제 = true 플래그
- 너무 오래된 로그를 자동으로 정리할 수 있도록 로그를 포함하는 컬렉션에 대한 TTL을 설정합니다.
- 로그를 저장하면 디스크가 많이 소모될 수 있습니다. 이를 방지하려면 다음과 같이 하세요:
결론
이 튜토리얼을 통해 카펠라에 배포된 이벤트 함수에 대한 통합 가시성을 구현하는 방법을 살펴봤습니다. 다음 단계로 다음을 수행할 수 있습니다. 가입하기 에서 Capella 평가판을 다운로드하여 가장 강력한 NoSQL 데이터베이스가 제공하는 다양한 기능을 직접 체험해 보세요. 방향을 잡는 데 도움이 되도록 다음을 사용할 수도 있습니다. 우리의 놀이터 그리고 우리의 Capella iQ를 통해 안전한 환경에서 개발하고 실험하는 방법을 배울 수 있습니다.

