소개
Couchbase Kafka Connector 1.2.0이 출시되었습니다. 다양한 버그 수정과 함께 이전에 제공되던 Kafka 생산자 외에 Kafka 소비자를 위한 새로운 샘플 코드가 추가되었습니다. 약관을 빠르게 살펴보세요:
- 카프카 제작자는 카프카에 데이터를 기록하므로 카프카의 관점에서 보면 메시지의 원천이 됩니다.
- 카프카 용어로 소비자는 토픽을 구독한 다음 카프카 클러스터에서 방출되는 게시된 메시지의 피드로 무언가를 하는 프로세스입니다. 기본적으로 싱크입니다.
이 블로그에서는 Couchbase에 쓰는 "Hello World!" 스타일의 샘플 Kafka 소비자를 시작하고 실행해 보겠습니다. 그 과정에서 샘플 소비자와 생산자를 실제로 실행하고 수정할 수 있도록 Kafka 브로커와 단일 노드 Couchbase Server가 포함된 샌드박스 환경도 제공됩니다.
필수 구성 요소 설치
그리고 샘플 의 일부입니다. 카우치베이스 카프카 커넥터 소스 트리. 이를 얻으려면 전체 리포지토리를 복제하면 됩니다:
|
1 |
$ git clone git://github.com/couchbase/couchbase-kafka-connector.git /tmp/kafka-connector |
이제 미리 구성된 Kafka 및 Couchbase Server 이미지를 사용하여 테스트 환경을 설정해 보겠습니다. 로컬로 설정하려면 Vagrant, VirtualBox 및 Ansible을 설치해야 합니다. 이러한 서비스를 다른 곳에 설치한 경우 이 가이드의 호스트 주소를 적절하게 조정해야 합니다.
|
1 |
$ cd /tmp/kafka-connector/env |
종속성 버전을 확인합니다:
|
1 2 3 |
$ ansible --version $ vboxmanage --version $ vagrant -v |
Vagrant용 플러그인을 사용하여 사람이 읽을 수 있는 이름을 상자에 지정할 수 있습니다. 아직 설치하지 않았다면 다음 명령을 사용하세요:
|
1 |
$ vagrant plugin install vagrant-hostsupdater |
이제 서버를 프로비저닝하고 실행할 준비가 되었습니다:
|
1 |
$ vagrant up |
참고: 시간 초과로 인해 서버 설치에 실패한 경우 몇 분 후에 '배건트 업'을 다시 시도하면 작동할 수 있습니다.
호스트가 응답하는지 확인합니다:
|
1 2 |
$ ping couchbase1.vagrant $ ping kafka1.vagrant |
로 이동하면 자격 증명을 사용하여 구성된 단일 노드 Couchbase Server를 볼 수 있습니다. 관리자/비밀번호.
샘플 구축
클래스 경로 문제를 방지하려면 maven을 사용하여 각 샘플 애플리케이션에 대해 독립된 JAR 파일을 만드세요.
생성기 애플리케이션은 최소한의 CLI 애플리케이션입니다. 이 애플리케이션은 Couchbase Java SDK를 사용하여 STDIN의 입력 줄을 JSON 문서로 래핑하고 이를 Couchbase Server의 "기본" 버킷으로 보냅니다:
|
1 2 |
$ cd /tmp/kafka-connector/samples/generator $ mvn assembly:assembly |
프로듀서는 Couchbase Server에 연결하여 모든 돌연변이를 Kafka로 전송합니다. 이 애플리케이션은 백그라운드에서 couchbase-kafka-connector 프로젝트를 사용합니다.
|
1 2 |
$ cd /tmp/kafka-connector/samples/producer $ mvn assembly:assembly |
Consumer는 전형적인 Kafka 소비자로, 기본적으로 "default" 토픽으로 들어오는 모든 메시지를 STDOUT으로 출력합니다.
|
1 2 3 |
$ cd /tmp/kafka-connector/samples/consumer $ mvn assembly:assembly |
샘플 실행
이제 모든 준비가 완료되었으니 모든 샘플을 실행할 차례입니다. 각 셸 세션은 중지될 때까지 프로세스를 실행하므로 세 개의 서로 다른 셸 세션이 필요합니다. 여러분이 현재 /tmp/kafka-connector/samples 디렉터리로 이동합니다.
먼저, 발전기를 시작합니다:
|
1 2 |
$ java -jar generator/target/kafka-samples-generator-1.0-SNAPSHOT-jar-with-dependencies.jar |
연결 설정을 출력한 다음 명령 프롬프트로 넘어가야 합니다. >. 여기에 무엇이든 입력할 수 있으며 Couchbase Server 관리자 UI에서 제대로 생성되고 있는지 확인할 수 있습니다:
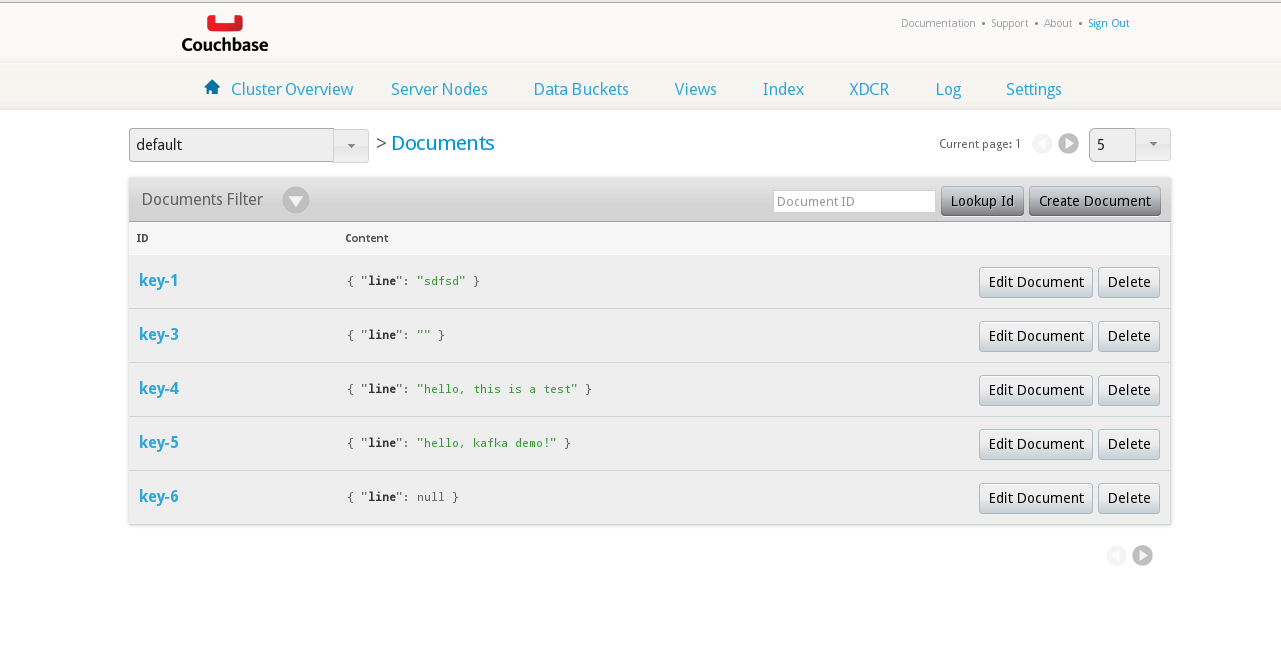
버킷에 있는 생성기의 문서
|
1 2 3 4 5 |
... INFO: Opened bucket default > hello, kafka demo! >> key=key-5, value={"line":"hello, kafka demo!"} |
현재 커넥터 예제를 실행할 수 있습니다.
|
1 |
$ java -jar producer/target/kafka-samples-producer-1.0-SNAPSHOT-jar-with-dependencies.jar |
생성기에 입력하는 모든 라인에 대해 다음과 같은 프로듀서의 라인이 표시됩니다:
|
1 |
RECEIVED: com.couchbase.kafka.DCPEvent@4e44cb88 |
이 샘플은 페이로드를 Kafka로 보내기 직전에 필터 클래스 구현에서 이를 작성합니다. Kafka가 이러한 메시지를 어떻게 수신하는지 확인해 보겠습니다.
|
1 2 3 |
$ java -jar consumer/target/kafka-samples-consumer-1.0-SNAPSHOT-jar-with-dependencies.jar 1: {"line":"hello, kafka demo!"} 2: {"line":"hello, this is a test"} |
세 서비스가 모두 실행되는 한 계속 플레이할 수 있습니다.
카우치베이스 카프카 커넥터로 개발하기
이제 코드를 살펴봅시다. 세 가지 애플리케이션 모두 실험에 매우 친숙하며, 예를 들어 생성기는 단 몇 줄에 들어갑니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
public class Example { public static void main(String args[]) throws IOException { Random random = new Random(); Cluster cluster = CouchbaseCluster.create("couchbase1.vagrant"); Bucket bucket = cluster.openBucket(); BufferedReader input = new BufferedReader(new InputStreamReader(System.in)); String line; do { System.out.print("> "); line = input.readLine(); if (line == null) { break; } String key = "key-" + random.nextInt(10); JsonObject value = JsonObject.create().put("line", line); bucket.upsert(JsonDocument.create(key, value)); System.out.printf(">> key=%s, value=%sn", key, value); } while (true); } } |
기본적으로 제너레이터는 "couchbase1.vagrant" 인스턴스에서 버킷 "default"에 대한 연결을 열고 임의의 키에 메시지를 씁니다. 이를 확장하여 다른 유형의 이벤트를 전송할 수 있습니다. 또 다른 방법은 키를 제거하는 것입니다.
기본적으로 Kafka용 Couchbase 커넥터는 서버 모드에서 실행되며, 활성 스레드를 빌려서 새로운 이벤트에 대해 Couchbase Server를 적극적으로 수신 대기합니다. 아이디어나 변경 사항을 적용할 수 있는 몇 가지 지점이 있습니다. 가장 눈에 띄는 것은 구성 빌더로, 연결하려는 서비스의 자격 증명과 주소를 지정할 수 있을 뿐만 아니라 다양한 직렬화기와 필터 클래스도 지정할 수 있습니다.
샘플 애플리케이션은 이 중 몇 가지를 구현합니다. 필터 클래스가 가장 간단합니다:
|
1 2 3 4 5 6 7 8 9 |
public class SampleFilter implements Filter { @Override public boolean pass(DCPEvent dcpEvent) { System.out.println("RECEIVED: " + dcpEvent); return true; } } |
여기에서 원하는 사용자 지정 수표를 입력할 수 있으며, 다음과 같은 경우 pass() 반환 false를 입력하면 커넥터는 메시지를 삭제하고 Kafka로 전송하지 않습니다.
커넥터 배포와 함께 제공되는 기본 인코더는 모든 메시지를 JSON으로 표현하려고 시도하지만 필요한 것이 아닐 수 있으므로 다음과 같이 적용하고 변환할 수 있습니다. DCPEvent 인스턴스를 생성하고 바이트 배열을 반환하며, 이 배열은 Kafka에 저장됩니다. 이 예제에서는 이벤트를 문자열 표현으로 변환하기만 합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
public class SampleEncoder extends AbstractEncoder { public SampleEncoder(final VerifiableProperties properties) { super(properties); } @Override public byte[] toBytes(final DCPEvent dcpEvent) { if (dcpEvent.message() instanceof MutationMessage) { MutationMessage message = (MutationMessage) dcpEvent.message(); return message.content().toString(CharsetUtil.UTF_8).getBytes(); } else { return dcpEvent.message().toString().getBytes(); } } } |
고급 설정은 다음과 같습니다. 상태 직렬화기 인터페이스를 구현합니다. 이를 구현하면 라이브러리가 스트림 커서를 추적하는 방법(즉, 카우치베이스 서버 내의 모든 파티션의 시퀀스 번호)과 커넥터 재시작 후 다시 시작할지 여부를 제어할 수 있습니다. 배포판에는 상태 직렬화기의 Zookeeper 구현이 있습니다. 여기 샘플에서는 다음을 구현했습니다. 널 상태 직렬화기 는 아무것도 유지하지 않지만 최소한의 구현을 보여줍니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
public class NullStateSerializer implements StateSerializer { public NullStateSerializer(final CouchbaseKafkaEnvironment environment) { } @Override public void dump(BucketStreamAggregatorState aggregatorState) { } @Override public void dump(BucketStreamAggregatorState aggregatorState, short partition) { } @Override public BucketStreamAggregatorState load(BucketStreamAggregatorState aggregatorState) { return new BucketStreamAggregatorState(aggregatorState.name()); } @Override public BucketStreamState load(BucketStreamAggregatorState aggregatorState, short partition) { return new BucketStreamState(partition, 0, 0, 0xffffffff, 0, 0xffffffff); } } |
데모 클러스터의 마지막 구성 요소는 Kafka 소비자입니다. AbstractConsumer는 매우 전형적인 소비자 사례입니다. 두 부분으로 구성됩니다: 로 구성되어 있으며, 카프카 주제에 대한 부트스트랩과 포지셔닝을 구현하는 PrintConsumer를 사용하여 "비즈니스 로직"을 전달하거나 전달되는 모든 메시지를 출력할 수 있습니다. AbstractConsumer:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
public class PrintConsumer extends AbstractConsumer { public PrintConsumer(String[] seedBrokers, int port) { super(seedBrokers, port); } public PrintConsumer(String seedBroker, int port) { super(seedBroker, port); } @Override public void handleMessage(long offset, byte[] bytes) { System.out.println(String.valueOf(offset) + ": " + new String(bytes)); } } |
여기에 있는 다른 예제에서와 마찬가지로 샘플 소비자를 수정해 볼 수 있습니다. 모든 것을 Couchbase Server로 다시 전송하여 회로를 닫을 수도 있습니다. Kafka는 Couchbase Server와 마찬가지로 분산 소프트웨어이므로 자체 클러스터에서 실행할 때 이 점을 염두에 두고 그에 따라 main() 함수를 조정하세요. 이 샘플에서는 하나의 파티션, 파티션(0), 따라서 메인 화면은 다음과 같습니다:
|
1 2 3 4 5 6 |
public class Example { public static void main(String args[]) { PrintConsumer example = new PrintConsumer("kafka1.vagrant", 9092); example.run("default", 0); } } |
물론 프로덕션 클러스터에서는 둘 이상의 파티션을 실행하게 됩니다.
결론
이 글이 Couchbase와 카프카를 시작하는 데 도움이 되었기를 바랍니다. 건배!