인덱스 빌드 및 업데이트의 성능이 대폭 업그레이드되었습니다. 범위 및 컬렉션이 Couchbase 7에 도입되었습니다.
Couchbase Server 7.0 릴리스 는 버킷 데이터를 다음과 같이 분리합니다. 논리적 범위 및 컬렉션 를 JSON 문서 데이터베이스 위에 올려놓을 수 있습니다. 이러한 분리를 통해 데이터를 다양한 스키마와 테이블로 구성할 수 있으며, 이는 대부분의 RDBMS 사용자가 이미 익히 알고 있는 개념입니다. 또한, 범위 및 컬렉션을 통해 보다 세밀한 역할 기반 액세스 제어 가능 에 저장된 데이터로 이동합니다.
참고: 범위 및 컬렉션을 도입한다고 해서 특정 데이터의 유형 는 분리되어 자체 컬렉션에 저장되어야 합니다. 실제로는 그 반대입니다. 컬렉션은 무엇보다도 먼저 JSON 문서 모음를 사용하므로 스키마가 없는 데이터베이스의 모든 유연성을 유지할 수 있습니다. 또는 오히려, 당신 애플리케이션에 필요한 스키마를 생성합니다.
이러한 인덱스 서비스 최적화를 통해 버킷 모델에서 새로운 컬렉션 모델로 마이그레이션할 수도 있고, 이미 잘 구성되어 있는 카우치베이스 클러스터를 사용합니다. 이 문서에서는 배포에 가장 적합한 것을 결정하는 데 도움이 되도록 인덱스 서비스를 최적화한 몇 가지 방법을 보여드리겠습니다. 자세히 살펴보겠습니다.
버킷 모델을 위한 인덱스 파이프라인
아래 다이어그램은 카우치베이스 버킷 모델에 따른 인덱스 빌드 파이프라인을 보여줍니다.
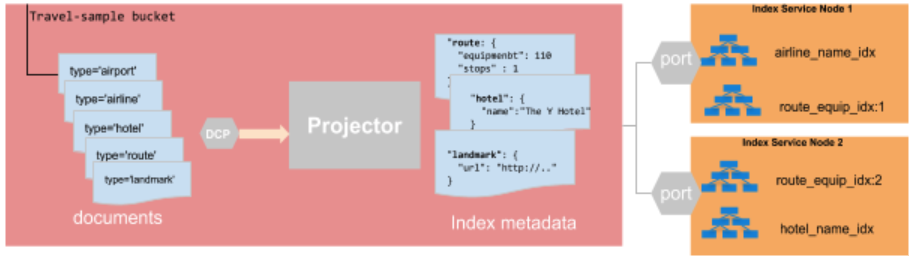
- 데이터 서비스의 프로젝터 프로세스는 버킷 데이터를 인덱싱 서비스로 스트리밍하는 일을 전적으로 담당합니다.
- 프로젝터는 인덱스 메타데이터를 기반으로 문서를 인덱스 서비스로 스트리밍할지 여부를 결정하기 위해 모든 변형을 평가하기 위해 단일 DCP(데이터베이스 변경 프로토콜) 스트림을 사용합니다.
- 프로젝터는 인덱스 서비스가 인덱스에 대해 유지 관리하는 특정 열만 스트리밍합니다.
위의 다이어그램에서 명확하지 않은 경우 프로젝터는 다음을 고려해야 합니다. 모두 다음에 대한 버킷 변이 모두 를 클러스터의 인덱스에 추가합니다.
컬렉션 모델을 위한 인덱스 파이프라인
카우치베이스 7.0의 새로운 컬렉션 모델에서, 데이터와 인덱스 서비스 간의 DCP 스트리밍은 컬렉션 수준에서 이루어집니다. 이 변경은 더 많은 DCP 스트림을 의미하지만, 실제로는 프로젝터가 변형을 전송할 인덱스 서비스를 결정할 때 다운스트림 처리에 도움이 됩니다.
초기 인덱스 빌드와 인덱스 업데이트의 작동 방식에는 약간의 차이가 있습니다. 먼저, 새로운 컬렉션 모델에서 초기 인덱스 빌드 프로세스를 살펴보겠습니다.
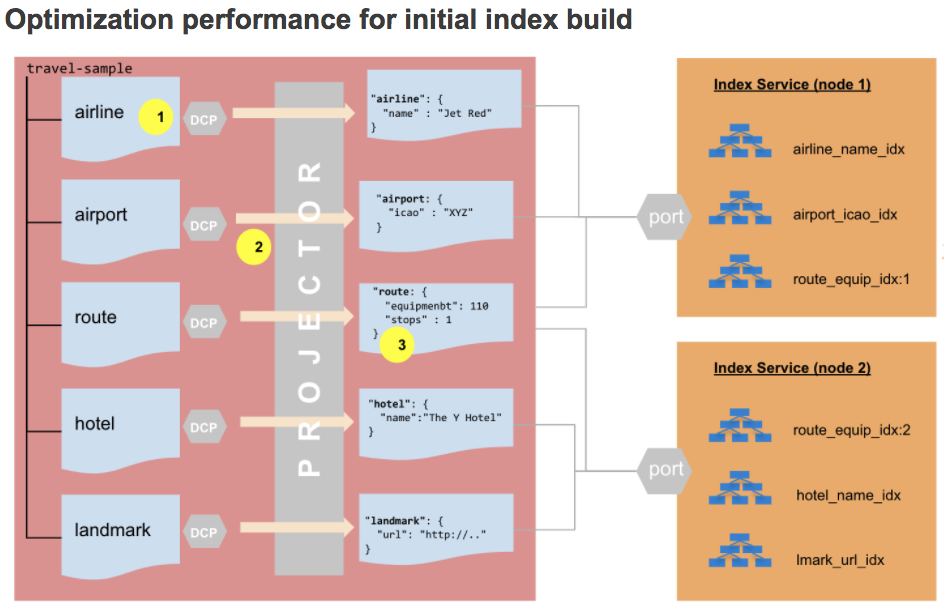
- 인덱스는 컬렉션 단위로 생성됩니다.
- 초기 인덱스 빌드 중에 각 컬렉션에 대해 DCP 스트림이 생성되므로 프로젝터의 작업 부하가 줄어듭니다.
- 프로젝터는 더 이상 인덱스를 평가할 필요가 없습니다.
어디절을 사용하여 돌연변이가 인덱스에 적합한지 여부를 결정합니다.
이제 Couchbase 7.0의 새로운 인덱스 업데이트 프로세스를 살펴보겠습니다:
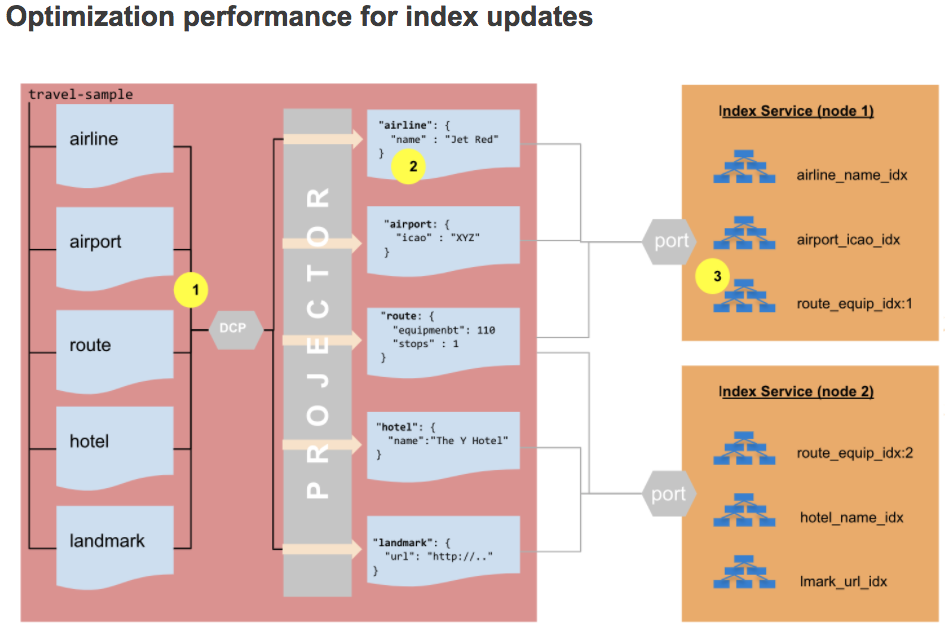
- 이제 DCP 스트림 데이터의 접두사 앞에
컬렉션 ID를 사용하여 프로젝터가 변경 사항을 전송할 인덱스를 알 수 있도록 합니다. - 프로젝터는 더 이상 인덱스를 평가할 필요가 없습니다.
어디절을 사용합니다. - 인덱스 수집 검사는 버킷의 모든 인덱스가 아니라 업데이트된 문서의 컬렉션에 정의된 인덱스로 제한됩니다. 이 제한으로 인해 CPU 및 디스크 I/O가 크게 절약됩니다.
결론
구성 관점에서 보면, 카우치베이스 컬렉션을 도입해도 인덱스 서비스에 대해 아무것도 변경할 필요가 없습니다. 하지만 특정 컬렉션에 인덱스를 만들 때는 버킷 이름 대신 컬렉션 이름을 지정해야 합니다.
7.0 릴리즈에서는 이러한 변경 사항을 구현하여 전체 버킷에서 변이를 처리하는 대신 더 작은 데이터 세트로 작업할 수 있는 이점을 제공합니다. 이 작은 데이터의 이점은 프로젝터에서 인덱서를 거쳐 다운스트림 스토리지 계층에 이르기까지 인덱스 서비스의 모든 단계에 적용됩니다.
Couchbase Server 7.0 릴리스에 대해 자세히 알아보려면 다음을 참조하세요, 새로운 기능 확인 및/또는 7.0 릴리스 노트.
지금 Couchbase 7.0 체험하기
아주 좋은 블로그 게시물입니다!