모든 분산 시스템의 필수적인 측면은 사용자에게 고가용성(HA) 및 부하 분산 기능을 원활하게 제공하는 것입니다. 사용자의 입력이 거의 또는 전혀 필요 없는 Couhbase의 글로벌 보조 색인1 (GSI)는 사용자에게 카우치베이스 클러스터 내에서 HA와 로드 밸런싱을 모두 제공합니다.
인덱스 플래너란?
인덱스 플래너는 Couchbase 인덱싱 서비스에서 인덱스의 최적 배치를 결정하기 위해 사용하는 라이브러리입니다. Couchbase 인덱싱 서비스를 위한 HA 인식 인덱스 배치 및 로드 밸런싱을 원활하게 지원합니다. 인덱스 플래너는 다음 두 가지 사용 사례에서 최적의 인덱스 배치를 결정하는 데 사용됩니다. 새 인덱스 생성 그리고 (2) 인덱스 서비스 재조정 즉, 클러스터에서 인덱서 노드가 추가 및/또는 제거되는 경우2.
인덱스 플래너 작동 방식
Couchbase 인덱싱 서비스를 호스팅하는 "노드" 집합(하드웨어 구성이 다를 수 있음)과 자체 "로드 매개변수"가 있는 인덱스 집합이 주어지면, Index Planner는 사용자에게 최적의 배치를 제공합니다.3 의 인덱스를 이러한 인덱서 노드에 배치해야 합니다. 로드 매개변수의 값이 서로 다른 수백 개의 인덱스를 수십 개의 인덱서 노드에 최적으로 배치하려면 매우 큰 솔루션 공간을 탐색해야 합니다. 따라서 결정론적으로 '최적의' 솔루션을 찾으려면 기하급수적인 시간이 필요합니다. 따라서 인덱스 플래너는 "최적의" 솔루션을 찾는 대신 확률론적 방법을 사용합니다. 시뮬레이션 어닐링 방법을 사용하여 대략적인 글로벌 최적 솔루션을 찾습니다. 실험적으로 시뮬레이션 어닐링은 카우치베이스 서버의 인덱스 배치 알고리즘에 좋은 결과를 가져오는 것으로 입증되었습니다.
인덱스 플래너가 고려하는 로드 매개변수는 (1) 인덱스의 크기 (2) 인덱스의 메모리 공간 (3) 인덱스의 스캔 속도 (4) 인덱스의 데이터 수집 속도 등 몇 가지를 예로 들 수 있습니다. 이러한 모든 로드 매개변수는 인덱스 플래너가 각 인덱스에서 생성되는 부하를 계산하는 데 도움이 되며, 특정 인덱스 배치에 따라 각 인덱서 노드에 가해지는 부하를 계산하는 데 차례로 도움이 됩니다. 다음과 같은 경우 인덱스 생성로드 매개변수의 실제 값은 알 수 없습니다. 따라서 인덱스 생성 시 인덱스 플래너는 이러한 로드 매개변수의 "예상 값"을 사용하여 실행됩니다. 재조정하는 동안 인덱스 플래너는 이러한 로드 매개변수의 값을 인덱스 통계.
예 1:
3개의 동일한 인덱서 노드인 "노드 1", "노드 2", "노드 3"이 있는 Couchbase 클러스터를 고려해 보겠습니다. "노드 3". 노드 1과 노드 2가 이미 각각 인덱스 1개씩, 즉 index1과 index2를 호스팅하고 있다고 가정해 보겠습니다. 사용자가 새 인덱스 "index3"를 추가하면, 현재 부하 분포를 기준으로 인덱스 플래너는 새 인덱스를 노드 3에 배치합니다.
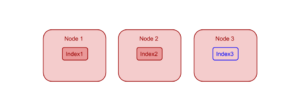
이것이 인덱스 플래너가 클러스터의 사용 가능한 모든 인덱스 노드에 인덱스를 배포하는 방법입니다. 추가적인 로드 밸런싱 기능을 제공하고 HA를 제공하기 위해 인덱싱 서비스를 통해 사용자는 인덱스 복제본을 만들 수 있습니다. 다음 섹션에서는 인덱스 복제본에 대해 설명합니다.
인덱스 복제본 배치를 위한 인덱스 플래너
고가용성을 위해 사용자는 항상 하나 이상의 인덱스 복제본 (HA 요구 사항에 따라). 카우치베이스 인덱싱 서비스는 마스터-마스터 복제본 정책을 구현합니다. 따라서 클러스터의 모든 복제본이 들어오는 쿼리를 처리할 수 있습니다.4. 카우치베이스 인덱싱 서비스는 스캔 요청이 모든 인덱스 복제본에 균일하게 분산되도록 합니다.
인덱스 플래너는 "항상" 동일한 인덱스의 복제본이 다른 인덱서 노드에 배치되도록 합니다. 이를 통해 사용자에게 고가용성을 제공합니다.
예 2:
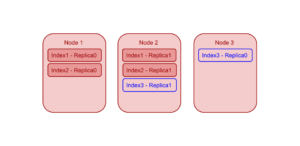
예제 1과 동일한 클러스터에서, 노드 1과 노드 2가 이미 각각 2개의 인덱스 복제본을 호스팅하고 있고 노드 3은 인덱스 복제본을 호스팅하지 않는다고 가정해 보겠습니다.5. 따라서 사용자가 두 개의 복제본(복제본0과 복제본1)이 있는 새 인덱스 "index3"을 추가하는 경우, 현재 부하 분포를 기준으로 인덱스 플래너는 새 인덱스 복제본 중 하나를 노드 3에 배치하지만 두 번째 복제본은 상대적으로 노드 간에 부하가 고르지 않더라도 노드 3에 배치하지 않습니다.
참고: 각 인덱스 복제본은 0부터 시작하는 ID(즉, replicaId)로 식별됩니다. 또한 사용자는 인덱스 생성 시 "num_replica" 매개변수를 사용하여 필요한 복제본 수를 지정할 수 있으며, 여기서 "num_replica" = 1은 총 2개의 인덱스 인스턴스(replicaId 0 및 replicaId 1)가 생성됨을 의미합니다.
랙 영역 인식을 위한 인덱스 플래너
Couchbase 클러스터 관리자는 사용자에게 클러스터 노드를 그룹화하여 다음과 같이 구성할 수 있는 기능을 제공합니다. 서버 그룹. 각 서버 그룹은 데이터 센터의 장애 조치 영역에 매핑할 수 있습니다. 예를 들어, 데이터센터의 단일 '랙'에 있는 모든 노드는 단일 서버 그룹에 속할 수 있습니다.
인덱스 플래너는 "랙 영역 인식"을 지원하며 항상 동일한 인덱스의 복제본을 다른 서버 그룹에 배치합니다. 서버 그룹 수가 복제본 수보다 적은 경우, 서버 그룹은 복제본을 1개 이상 호스팅할 수 있습니다.
예 3:
"노드 1", "노드 2", "노드 3", "노드 4" 등 4개의 동일한 인덱서 노드가 있는 Couchbase 클러스터를 예로 들어 보겠습니다. 노드 1과 노드 2는 "서버 그룹 1"에 속하고, 노드 3과 노드 4는 "서버 그룹 2"에 속합니다. 노드 1과 노드 2가 이미 각각 인덱스 1개씩을 호스팅하고 있다고 가정해 봅시다: 인덱스1 - 복제본0 및 인덱스2 - 복제본0. 이제 사용자가 2개의 복제본(복제본0과 복제본1)이 있는 새 인덱스 "index3"을 클러스터에 추가합니다. 따라서 인덱스 플래너는 노드 3 또는 노드 4에 하나의 복제본을 추가하여 부하를 분산시킵니다. 그러나 서버 그룹 1에 속하는 노드 3 또는 노드 4가 이미 하나의 복제본을 호스팅하고 있기 때문에 두 번째 복제본은 서버 그룹 1로 이동해야 합니다. 인덱스 플래너는 여러 노드에 걸쳐 상대적으로 고르지 않은 부하 분산을 의미하더라도 이 선택을 합니다.
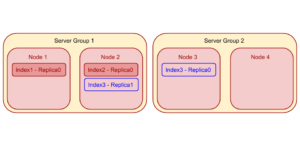
인덱스 파티션 배포를 위한 인덱스 플래너
카우치베이스 사용자는 다음을 만들 수 있습니다. 분할 인덱스 를 사용하여 인덱스 빌드와 관련하여 더 나은 부하 분산을 얻고 대용량 인덱스에 대해 더 빠른 스캔 결과를 얻을 수 있습니다. 파티션 인덱스의 도움으로, 인덱스 데이터는 파티션 키의 해시값에 따라 여러 파티션에 분산됩니다. 인덱스 플래너는 파티션을 인식하며 인덱스 빌드 로드와 인덱스 스캔 로드에 따라 여러 인덱서 노드에 인덱스 파티션을 배포할 수 있습니다.
인덱스 플래너는 인덱스의 파티션을 가능한 한 많은 인덱서 노드에 분산시킵니다. 이는 인덱스 스캔 부하와 인덱스 빌드 부하를 해당 인덱서 노드 간에 분산하는 데 유용합니다. 하지만 인덱스 플래너가 사용 가능한 모든 인덱서 노드에 파티션을 균일하게 분배하는 것은 보장하지 않습니다. 따라서 사용자는 '로드 매개변수'가 다른 파티션되지 않은 인덱스와 파티션된 인덱스가 여러 개 있는 경우 클러스터의 전체 부하를 더 잘 분배하는 데 도움이 됩니다.
예 4:
"노드 1", "노드 2", "노드 3", "노드 4" 등 4개의 동일한 인덱서 노드가 있는 Couchbase 클러스터를 예로 들어보겠습니다. 노드 1이 이미 2개의 파티션되지 않은 인덱스를 호스팅하고 있다고 가정해 보겠습니다. 이제 사용자가 분할 인덱스를 추가하는 경우6 "index3"(파티션 4개 포함), 인덱스 플래너 may 는 새 인덱스의 4개 파티션을 노드 2, 노드 3, 노드 4에만 분산합니다. 이렇게 하면 클러스터에서 전반적으로 더 나은 부하 분산을 보장합니다.
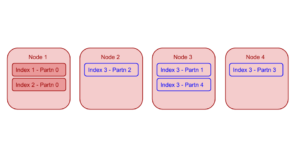
분할된 인덱스에는 복제본이 있을 수 있습니다. 인덱스의 각 파티션에는 고유한 파티션 복제본 세트가 있습니다. 인덱스 플래너는 필요한 부하 분산과 고가용성을 보장하기 위해 파티션 복제본이 인덱서 노드와 여러 서버 그룹에 분산되도록 합니다.
이 블로그의 다음 파트에서는 카우치베이스 인덱싱 서비스가 다양한 사용 사례에 인덱스 플래너를 사용하는 방법에 대해 설명합니다.
1 이 블로그 게시물에서 '인덱스'라는 용어는 카우치베이스의 글로벌 보조 인덱스에만 사용됩니다.
2 클러스터에서 제거되지 않은 노드에 있는 인덱스는 리밸런싱의 영향을 받지 않습니다.
3 최적의 배치는 모든 HA 요구 사항을 준수하는 최상의 부하 분산을 의미합니다.
4 글로벌 보조 인덱스 복제본은 서로 완전히 독립적으로 구축되고 유지 관리됩니다. 이러한 복제본이 제공하는 들어오는 쿼리는 Couchbase GSI를 준수합니다. 일관성 모델.
5 사용자는 클러스터에서 두 개의 노드로 시작하여 각각 2개의 복제본으로 인덱스를 생성한 다음 클러스터에 세 번째 노드를 추가하면 이러한 종류의 인덱스 배포를 끝낼 수 있습니다.
6 파티션 인덱스의 경우 파티션 ID는 1부터 시작합니다. 파티션 ID 0은 파티션이 없는 인덱스에 사용됩니다.