이 게시물은 Karen Yua가 공동 작성했습니다.n고등학생 인턴.
데이터 과학은 데이터에서 지식을 추출하고 그 지식을 적용하여 문제를 해결합니다. 다음 두 개의 게시물에서는 Couchbase 데이터 플랫폼이 어떻게 다양한 데이터 과학 요구 사항을 충족하고 그 과정에서 필요한 도구의 수를 단순화하고 줄일 수 있는지 알아보겠습니다.
개요
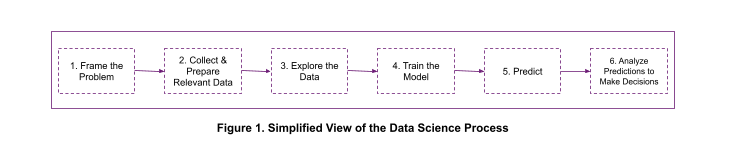
데이터 과학 워크플로에는 그림 1과 같이 여러 단계가 포함됩니다. 데이터 과학자는 각 단계마다 다른 도구를 사용해야 하므로 프로세스가 복잡해지고 효율성이 떨어집니다.
예를 들어, 데이터 과학자는 탐색적 데이터 분석을 수행하여 학습 데이터의 어떤 속성이 사용 사례에 중요한지 결정합니다. 이를 위해 데이터 과학자는 일반적으로 데이터베이스에서 다른 도구(예: Jupyter 노트북)로 학습 데이터를 로드합니다. 하지만 학습 데이터 세트는 방대하고 많은 메모리를 소모합니다. 또한 대용량 데이터 세트를 전송하면 네트워크 대역폭이 소모되고 프로세스 속도가 느려집니다. 데이터를 분석하기에 가장 좋은 곳은 데이터가 저장되어 있는 데이터베이스입니다.
데이터 과학자는 데이터베이스에서 필수 속성만 읽으면 됩니다. 이렇게 하면 데이터 분석이 간소화되고 트레이닝 세션 메모리 사용량이 줄어들며 네트워크 데이터 전송량이 제한됩니다. 예를 들어, 각각 10개의 필드가 있는 수백만 개의 JSON 문서로 데이터를 훈련한다고 가정해 보겠습니다. 이 중 8개 필드만 학습에 필요한 경우, 데이터 과학자는 나머지를 무시함으로써 약 201TB의 메모리를 절약할 수 있습니다(모든 필드의 크기가 같다고 가정).
이 글과 다음 글에서 알아보겠습니다:
- Couchbase 쿼리 서비스를 사용해 탐색적 데이터 분석(EDA)을 수행하고 데이터 과학 결과를 시각화하는 방법을 알아보세요. 쿼리 및 분석 서비스는 학습 데이터 및 예측과 동일한 Couchbase 클러스터에서 실행됩니다. 이러한 서비스를 사용하여 학습 데이터와 예측을 분석하면 데이터 과학 프로세스를 쉽고 효율적으로 수행할 수 있습니다.
- Couchbase Python SDK의 쿼리 및 분석 API를 사용하여 학습 데이터를 효율적으로 읽고 머신 러닝(ML)에 적합한 데이터 구조(예: 판다 데이터 프레임)에 원활하게 저장하는 방법을 알아보세요.
- 학습 데이터와 예측뿐만 아니라 ML 모델(최대 20MB 크기)까지 저장하여 모든 데이터 과학 프로세스 스토리지 요구 사항을 충족하는 Couchbase.
문제 프레임
데이터 과학 프로세스(그림 1)는 일반적으로 문제 정의에서 시작됩니다. 이 글에서는 고객 이탈 예측을 예로 들어보겠습니다.
온라인 스트리밍 서비스 회사의 영업팀은 월 구독료를 인상하면 더 많은 수익을 올릴 수 있는지 알고 싶어합니다. 하지만 월간 비용을 너무 높이면 고객 이탈률이 높아질 수 있습니다.
고객 이탈을 억제하면서 수익을 극대화하는 월별 비용은 얼마일까요? 이 질문에 답하려면 데이터 과학자는 월별 비용이 특정 금액만큼 증가했을 때(예: $1, $2 등) 이탈 점수를 예측해야 합니다.
관련 데이터 수집 및 준비
문제를 정의한 후 데이터 과학자는 문제 해결에 필요한 적절한 데이터를 수집합니다. 이 원시 데이터는 누락된 값을 처리하기 위해 정리 및 사전 처리가 필요할 수 있습니다.
이 글에서는 온라인_스트리밍.csv 사용 가능한 데이터 세트 여기. 이것은 Couchbase에서 만든 합성 데이터 세트입니다. 가상의 온라인 스트리밍 서비스 회사의 고객 레코드 50만 개를 시뮬레이션합니다.
README에 언급된 단계를 사용하여 이 데이터 세트를 Couchbase 클러스터에 로드합니다. 여기.
데이터 살펴보기
필요한 데이터를 수집하고 준비한 후, 데이터 과학자는 데이터에 대한 인사이트를 얻기 위해 데이터를 탐색합니다. 탐색적 데이터 분석(EDA)은 데이터의 구조를 파악하고 중요한 변수를 추출하기 위해 종종 시각화 기술을 사용하는 접근 방식입니다.
앞서 언급했듯이 이 분석을 수행하기에 가장 좋은 장소는 데이터가 저장된 데이터베이스입니다.
데이터 과학자는 EDA를 위해 Couchbase 쿼리 및 분석 서비스를 사용할 수 있습니다. 이러한 서비스는 학습 데이터가 저장된 클러스터와 동일한 Couchbase 클러스터에서 실행됩니다. 분석을 위해 학습 데이터를 다른 곳으로 옮길 필요가 없습니다. 따라서 프로세스가 간단하고 효율적입니다.
카우치베이스 다차원 확장(MDS)에 대해 설명합니다. 여기를 사용하면 이러한 서비스를 독립적으로 확장할 수 있습니다. 그 결과 쿼리 속도가 빨라집니다. Couchbase 분석 서비스의 병렬 데이터 관리 기능은 데이터 분석을 더욱 효율적으로 만들어 줍니다.
여기에 설명된 쿼리 기능을 사용하려면 먼저 쿼리 UI에서 다음 명령을 실행하여 온라인_스트리밍 버킷에 기본 인덱스를 생성합니다. 선택 쿼리 컨텍스트 을 드롭다운 메뉴에서 클릭하고 입력합니다: 에 기본 인덱스 생성 온라인_스트리밍
기본 인덱스를 만드는 대신 인덱스 어드바이저 기능(조언 문을 입력합니다. cbq 도구)를 사용하여 쿼리별로 생성할 적절한 인덱스를 찾기 위해 Couchbase 쿼리 서비스의 어디 절을 사용합니다.
탐색적 데이터 분석의 핵심 단계 중 하나는 데이터 집합의 속성을 이해하는 것입니다.
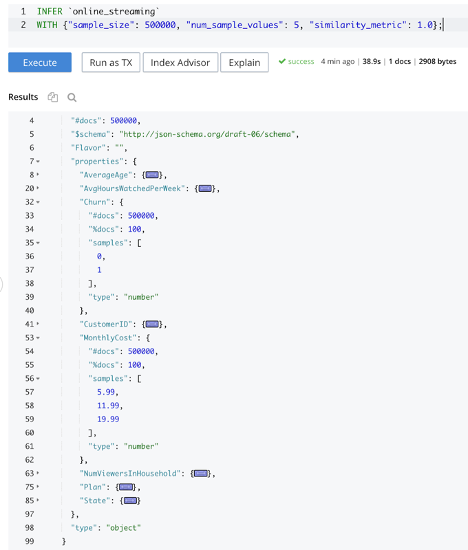
그리고 INFER 문을 사용하면 도움이 될 수 있습니다. 이를 통해 사용자는 문서의 구조, 다양한 속성의 데이터 유형 등을 유추할 수 있습니다. 참고 INFER 는 결정론적이라기보다는 통계적 성격을 띠고 있습니다. 여기.
아래 쿼리에서 볼 수 있듯이, 아래 쿼리에서 INFER 문을 보면 이 버킷에 500,000개의 문서가 있고 이 문서에 요금제 및 고객 ID와 같은 속성이 포함되어 있음을 알 수 있습니다. 개별 속성을 확장하면 추가 세부 정보를 볼 수 있습니다. 예를 들어 월별 비용에는 $5.99, $11.99 및 $19.99의 세 가지 가능한 값이 있습니다.
지도 학습 알고리즘인 로지스틱 회귀를 사용하여 이탈 예측자를 학습시킵니다.
그리고 이탈 속성은 지도 학습을 위한 레이블(출력, 대상)로 사용됩니다. 이탈 는 0 또는 1로 설정되며, 1은 고객이 이탈했음을 나타냅니다. 학습 프로세스는 레이블(이탈)과 입력(데이터 세트의 다른 속성) 간의 관계를 학습하려고 시도합니다.
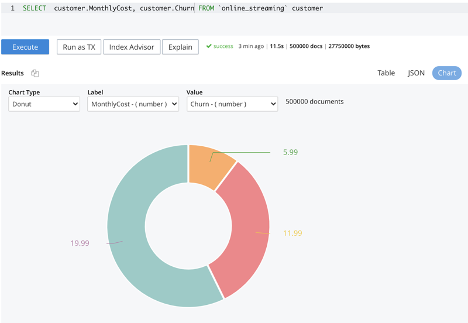
쿼리 및 분석 차트(카우치베이스 서버 7.0.2 이상)를 사용하여 속성 간의 패턴이나 상관 관계를 시각화할 수 있습니다. 이를 통해 교육 프로세스에 어떤 속성을 포함할지 결정하는 데 도움이 될 수 있습니다. 아래 차트는 월 비용이 높은 고객이 이탈할 가능성이 더 높다는 것을 보여줍니다. 분명한 것은 월별 비용은 이탈 예측자를 학습시킬 때 포함해야 할 중요한 속성입니다.
카우치베이스 쿼리 및 분석 서비스는 통계 분석에 사용할 수 있는 평균 및 표준 편차와 같은 많은 기본 제공 함수도 제공합니다. 날짜 및 문자열과 같은 다른 쿼리 함수는 데이터 전처리에 도움이 될 수 있습니다.
모델 훈련
데이터를 탐색한 후 데이터 과학자는 모델 학습을 진행합니다. 그림 2에 표시된 단계를 사용하여 고객 이탈 예측 모델을 학습시킵니다. 필요한 경우, 기능을 Couchbase 버킷에 저장할 수도 있습니다.
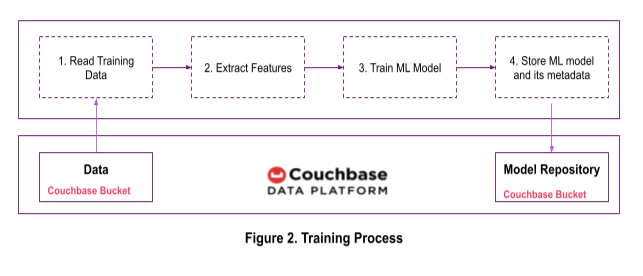
1단계: 카우치베이스에서 효율적으로 학습 데이터 읽기
우리는 이미 쿼리 서비스를 사용하여 EDA 중에 중요한 속성을 식별했습니다. 학습 데이터를 읽는 동안 해당 속성만 가져올 것입니다. 이렇게 하면 네트워크를 통해 읽는 데이터의 크기와 학습 세션에 데이터를 저장하는 데 필요한 메모리 양이 줄어듭니다.
Couchbase Python SDK(버전 3)의 쿼리 API를 사용하여 다음을 수행합니다. 효율적으로 전체 교육 데이터 세트를 읽으려면 선택 이탈 예측자 학습에 관련된 속성만 입력합니다.
이 코드에서 볼 수 있듯이 쿼리 API를 사용하여 읽은 데이터는 판다스 데이터 프레임에 쉽게 저장할 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import numpy as np import pandas as pd # Connect to Couchbase cluster using the Python SDK from couchbase.cluster import Cluster, ClusterOptions from couchbase.auth import PasswordAuthenticator # Fill-in the hostname or IP address, user_name and password for your cluster. # E.g. Cluster.connect("couchbase://localhost", ClusterOptions(PasswordAuthenticator("Administrator", # "password"))) cluster = Cluster.connect(<host>, ClusterOptions(PasswordAuthenticator(<user_name>, <password>))) # Connect to online_streaming bucket cb = cluster.bucket('online_streaming') # Use the Query API to get all documents from the bucket # Specify only the needed attributes in the SELECT clause query_result = cb.query("SELECT c.AverageAge, c.AvgHoursWatchedPerWeek, c.Churn, c.MonthlyCost, c.NumViewersInHousehold, c.Plan FROM `online_streaming` as c") # Easily store the read data to a Pandas data frame data = pd.DataFrame(list(query_result)) data.head() |
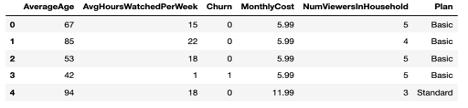
다음을 참조하세요. 카우치베이스 파이썬 SDK 문서 를 참조하여 SDK 사용에 대한 정보를 확인하세요.
다음 글에서 설명하는 대로 Couchbase Python SDK의 애널리틱스 API도 학습 데이터를 읽을 수 있습니다.
2단계: 특징 추출
데이터 과학자는 원시 데이터를 적절한 피처로 변환하여 학습 기능에 전달합니다. 피처 엔지니어링 기법의 유형은 데이터 유형에 따라 다릅니다.
가장 일반적인 기능 엔지니어링 단계 중 하나는 원핫 인코딩을 사용하여 범주형 데이터를 숫자 값으로 변환하는 것입니다. 이 Python 코드를 사용하여 범주형 데이터를 인코딩하고 입력(X) 및 레이블(Y) 데이터 프레임을 만들겠습니다.
|
1 2 3 4 5 6 7 |
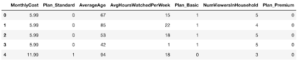
# Get one-hot encoding for categorical features categoricals = data.select_dtypes(include = object).columns data = pd.get_dummies(data, columns=categoricals) # Drop the 'Churn' column since it is a label and not a feature feature_names = list(set(list(data.columns)) - set(['Churn'])) X = data[feature_names] Y = data['Churn'] |
에서 볼 수 있듯이 X.head() 출력에서 원핫 인코딩이 이전에 다음 중 하나로 설정된 계획 열을 대체했습니다. 기본, 표준 또는 프리미엄세 개의 숫자 열이 있는 계획-표준, 계획-기본 그리고 플랜-프리미엄.
3단계: ML 모델 학습
다음으로 데이터 과학자는 사용 사례와 관련된 ML 모델 학습을 진행합니다.
아래 코드를 사용하여 2단계에서 생성한 기능을 사용하여 이탈 예측자를 학습시키겠습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from sklearn.model_selection import train_test_split # train_test_split function splits the data into two subsets for training and testing. # The test_size parameter below ensures that the test subset is 20% of the # training data. X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=101, shuffle=False) from sklearn.linear_model import LogisticRegression # We will use Logistic regression to train the churn predictor lm = LogisticRegression(max_iter=200) lm.fit(X_train, Y_train) lm.score(X_train, Y_train) lm.score(X_test, Y_test) |
4단계: ML 모델 및 해당 메타데이터 저장하기
데이터 과학자는 나중에 예측을 생성하기 위해 학습된 모델을 저장해야 합니다. 이 단계는 연구를 재현하는 데에도 중요합니다. 데이터 과학은 반복적인 프로세스이며 여러 버전의 모델이 있을 수 있습니다.
아래 코드를 사용하여 이탈 예측 모델(버전 1)과 해당 메타데이터를 모델 저장소 버킷을 만듭니다. 계속 진행하기 전에 Couchbase 클러스터에 이 버킷을 만드세요.
이탈 예측 모델의 크기는 1KB 미만입니다. 최대 20MB 크기의 모델은 다음 문서에 설명된 대로 JSON 또는 바이너리 형식으로 Couchbase에 저장할 수 있습니다. 여기. 학습된 모델에서 예상되는 기능의 이름은 모델 메타데이터에 저장됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import pickle from datetime import datetime def store_model_on_couchbase(model, feature_names, model_id): # Store model in Binary format from couchbase_core._libcouchbase import FMT_BYTES bucket = cluster.bucket('model_repository') model_bytes = pickle.dumps(model) bucket.upsert(model_id, model_bytes, format=FMT_BYTES) now = datetime.now() model_metadata = {'model_id': model_id, 'feature_names': list(feature_names), "creation time": now.strftime("%d/%m/%Y %H:%M:%S")} # Store model metadata under a separate key key = model_id + "_metadata" bucket.upsert(key, model_metadata) |
|
1 |
store_model_on_couchbase(lm, feature_names, 'churn_predictor_model_v1') |
모델과 해당 메타데이터가 Couchbase에 성공적으로 저장되었는지 확인합니다.

결론
이 글에서는 Couchbase가 데이터 과학을 쉽게 만드는 방법에 대해 알아보았습니다. 고객 이탈 예측을 예로 들어, 쿼리 서비스를 사용하여 탐색적 분석을 수행하는 방법, Python SDK를 사용하여 대규모 학습 데이터 세트를 효율적으로 읽고 이를 ML에 적합한 데이터 구조(예: 판다 데이터 프레임)로 쉽게 저장하는 방법을 살펴보았습니다. 또한 최대 20MB 크기의 ML 모델과 그 메타데이터를 Couchbase에 저장하는 방법도 살펴봤습니다.
다음 글에서는 예측을 만들고, 이를 Couchbase에 저장하고, 쿼리 차트를 사용하여 분석하는 방법에 대해 알아보겠습니다.
다음 단계
머신 러닝과 Couchbase에 대해 자세히 알아보고 싶다면 다음 단계와 리소스를 통해 시작하세요:
- Couchbase Cloud 무료 평가판 시작하기 - 설치가 필요하지 않습니다.
- 카우치베이스 내부 살펴보기: 아키텍처 개요 - 이 백서를 통해 기술적 세부 사항을 자세히 알아보세요.
- 카우치베이스 살펴보기 쿼리, 전체 텍스트 검색, 이벤트및 분석 서비스.
- 이 ML 블로그를 확인하세요:
