Couchbase는 DCP 커넥터를 사용하는 Apache Kafka의 소스로 훌륭합니다.
그러나 빠르고 메모리를 우선시하며 안정적인 스토리지를 제공하기 때문에 데이터를 소화하는 엔드포인트로도 훌륭합니다.
이 블로그 게시물에서는 생산자와 소비자를 위한 간단한 Java 애플리케이션을 구축하여 Kafka에서 게시된 메시지를 Couchbase에 저장하는 방법을 보여드리겠습니다.
여기서는 이미 Kafka 클러스터가 있다고 가정합니다(단일 노드 클러스터일지라도). 그렇지 않은 경우 해당 설치 가이드를 따르세요.
이 블로그 환경은 4가지 부분으로 구성되어 있습니다:
- 카프카 프로듀서
- 아파치 카프카 대기열
- 카프카 소비자
- 카우치베이스 서버
프로듀서
대기열에 메시지를 제출하려면 프로듀서가 필요합니다.
대기열에서 해당 메시지가 소화되고 있으며 해당 토픽을 구독한 모든 애플리케이션이 해당 메시지를 읽을 수 있습니다.
메시지의 소스는 Mockaroo를 사용하여 만든 더미 JSON 파일이 될 것이며, 이를 분할하여 대기열로 전송할 것입니다.
샘플 JSON 데이터는 다음과 유사합니다:
|
1 2 3 4 5 6 7 8 9 |
{ "id":1, "gender":"Female", "first_name":"Jane", "last_name":"Holmes", "email":"jholmes0@myspace.com", "ip_address":"230.49.112.20", "city":"Houston" } |
프로듀서 코드입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
import com.fasterxml.jackson.databind.JsonNode; import com.fasterxml.jackson.databind.ObjectMapper; import com.fasterxml.jackson.databind.node.ArrayNode; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.io.File; import java.nio.charset.Charset; import java.nio.file.Files; import java.nio.file.Paths; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.concurrent.Future; public class KafkaSimpleProducer { public static void main(String[] args) throws Exception { Map<String, Object> config = new HashMap<>(); config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); config.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> producer = new KafkaProducer<String, String>(config); File input = new File("sampleJsonData.json"); byte[] encoded = Files.readAllBytes(Paths.get(input.getPath() )); String jsons = new String(encoded, Charset.defaultCharset()); System.out.println("Splitting file to jsons...."); List splittedJsons = split(jsons); System.out.println("Converting to JsonDocuments...."); int docCount = splittedJsons.size(); System.out.println("Number of documents is: " + docCount ); System.out.println("Starting sending msg to kafka...."); int count = 0; for ( String doc : splittedJsons) { System.out.println("sending msg...." + count); ProducerRecord<String,String> record = new ProducerRecord<>( "couchbaseTopic", doc ); Future meta = producer.send(record); System.out.println("msg sent...." + count); count++; } System.out.println("Total of " + count + " messages sent"); producer.close(); } public static List split(String jsonArray) throws Exception { List splittedJsonElements = new ArrayList(); ObjectMapper jsonMapper = new ObjectMapper(); JsonNode jsonNode = jsonMapper.readTree(jsonArray); if (jsonNode.isArray()) { ArrayNode arrayNode = (ArrayNode) jsonNode; for (int i = 0; i < arrayNode.size(); i++) { JsonNode individualElement = arrayNode.get(i); splittedJsonElements.add(individualElement.toString()); } } return splittedJsonElements; } } |
카프카 프로듀서 앱의 출력
소비자
이것은 매우 간단하며, 대기열에서 메시지를 가져오고 Couchbase Java SDK를 사용하여 Couchbase에 문서를 삽입하기만 하면 됩니다. 간단하게 하기 위해 동기화 자바 SDK를 사용하겠지만 비동기화를 사용하는 것도 충분히 가능하고 권장하기도 합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
import com.couchbase.client.java.Bucket; import com.couchbase.client.java.Cluster; import com.couchbase.client.java.CouchbaseCluster; import com.couchbase.client.java.document.JsonDocument; import com.couchbase.client.java.document.json.JsonObject; import kafka.consumer.Consumer; import kafka.consumer.ConsumerConfig; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector; import kafka.message.MessageAndMetadata; import java.util.*; public class KafkaSimpleConsumer { public static void main(String[] args) { Properties config = new Properties(); config.put("zookeeper.connect", "localhost:2181"); config.put("zookeeper.connectiontimeout.ms", "10000"); config.put("group.id", "default"); ConsumerConfig consumerConfig = new kafka.consumer.ConsumerConfig(config); ConsumerConnector consumerConnector = Consumer.createJavaConsumerConnector(consumerConfig); Map<String, Integer> topicCountMap = new HashMap<>(); topicCountMap.put("couchbaseTopic", 1); Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumerConnector.createMessageStreams(topicCountMap); List<KafkaStream<byte[], byte[]>> streams = consumerMap.get("couchbaseTopic"); List nodes = new ArrayList<>(); nodes.add("localhost"); Cluster cluster = CouchbaseCluster.create(nodes); final Bucket bucket = cluster.openBucket("kafkaExample"); try { for (final KafkaStream<byte[], byte[]> stream : streams) { for (MessageAndMetadata<byte[], byte[]> msgAndMetaData : stream) { String msg = convertPayloadToString(msgAndMetaData.message()); System.out.println(msgAndMetaData.topic() + ": " + msg); try { JsonObject doc = JsonObject.fromJson(msg); String id = UUID.randomUUID().toString(); bucket.upsert(JsonDocument.create(id, doc)); } catch (Exception ex) { System.out.println("Not a json object: " + ex.getMessage()); } } } } catch (Exception ex) { System.out.println("EXCEPTION!!!!" + ex.getMessage()); cluster.disconnect(); } cluster.disconnect(); } private static String convertPayloadToString(final byte[] message) { String string = new String(message); return string; } } |
카프카 소비자 콘솔 출력
카우치베이스 서버
이제 Couchbase 서버에서 결과를 확인할 수 있습니다.
카프카 예시 버킷 - 1000개의 문서로 채워져 있습니다.
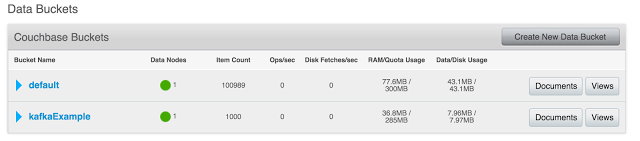
카우치베이스 버킷
각 문서는 이와 비슷하게 생겼습니다:

샘플 문서
간단한 3단계 솔루션.
프로덕션 환경에서는 프로듀서, 소비자, 카프카 또는 카우치베이스가 각각 하나 이상의 머신에 설치되어 있다는 점에 유의하세요.
의 전체(Maven 종속성 포함) 코드 GitHub.
Roi.