최근에 Elasticsearch Connector 4.2의 기능을 익히기 위해 설명서를 살펴보던 중 파이프라인이라는 구성을 발견했습니다. 저는 이것이 무엇을 의미하는지, 어떤 용도로 사용되는지 궁금했습니다. 그렇게 하면서 커넥터와 그 구성을 실험해 보았고, 이 포스팅을 통해 제 경험을 공유하고 싶었습니다.
개요
이 게시물에서는 복제 및 변환에 대해 다룹니다. 여행 샘플 Elasticsearch 커넥터와 Elasticsearch 수집 노드 파이프라인을 사용하여 Couchbase에서 Elasticsearch로 랜드마크 데이터 세트를 전송합니다.
이 블로그 게시물에서 사용할 다양한 구성 요소에 대해 간단히 살펴보겠습니다.
카우치베이스 는 오픈 소스, 분산형 JSON 문서 데이터베이스입니다. 밀리초 미만의 데이터 작업을 위한 관리형 캐시를 갖춘 스케일아웃 키-값 저장소, 효율적인 쿼리를 위한 특수 제작된 인덱서, SQL과 유사한 쿼리를 실행하기 위한 강력한 쿼리 엔진을 제공합니다.
Elasticsearch 는 강력한 검색 및 분석 엔진을 갖춘 전체 텍스트 분산형 NoSQL 데이터베이스로, Elastic Stack의 핵심입니다. Elasticsearch는 SQL 세계에서 테이블과 유사한 인덱스(때로는 인덱스라고도 함)에 문서를 저장합니다.
수집 노드 파이프라인 는 문서를 색인하기 전에 사전 처리하기 위해 Elasticsearch가 제공하는 강력한 도구입니다. 수집 노드 파이프라인은 선언된 순서대로 실행되는 하나 이상의 프로세서로 구성됩니다. Elasticsearch는 기본적으로 프로세서 세트와 함께 제공되며, 필요에 따라 사용자 정의 프로세서를 구축할 수도 있습니다. 모든 프로세서 목록은 다음 설명서를 참조하세요. 여기.
Elasticsearch 커넥터 는 Couchbase에서 구축한 도구로, Couchbase에서 Elasticsearch로 데이터를 복제할 수 있게 해줍니다.
Kibana 는 무료 개방형 사용자 인터페이스로, Elasticsearch 데이터를 시각화하고 Elastic Stack을 탐색할 수 있게 해줍니다. 또한 Kibana는 수집 노드 파이프라인을 관리하고 평가할 수 있게 해줍니다.
전제 조건 및 가정
이 게시물에서는 위에 나열된 모든 구성 요소에 대한 기본적인 이해가 있고 macOS를 실행하는 컴퓨터를 사용하여 예시를 살펴본다고 가정합니다.
시작하기
새 터미널 창을 실행하고 /사용자/ 아래에 있는 사용자 디렉토리로 이동합니다. 라는 새 디렉터리를 만듭니다. 커넥터. 이를 다음과 같이 참조합니다. "BASE_DIR" 를 클릭해 주세요.
|
1 |
mkdir 커넥터 |
Elasticsearch 및 Kibana 설치 및 실행
-
-
다운로드 최신 버전의 Elasticsearch와 Kibana로 이동하여 BASE_DIR. Elasticsearch--darwin-x86_64.tar.gz와 kibana--darwin-x86_64.tar.tz 파일 두 개가 보일 것입니다.
-
다운로드한 파일의 압축을 풀고 디렉터리 이름을 es 그리고 kibana
-
새 터미널을 시작하고 다음 위치로 이동합니다. BASE_DIR 를 누른 다음다음 명령을 입력합니다. (한 번에 하나씩)
|
1 |
타르 -xzvf 엘라스틱서치-7.8.0-darwin-x86_64.tar.gz && 타르 -xzvf kibana-7.8.0-darwin-x86_64.tar.gz |
|
1 |
mv 엘라스틱서치-7.8.0-darwin-x86_64 es && mv kibana-7.8.0-darwin-x86_64 kibana |
3. Elasticsearch 시작
새 터미널 창을 실행하고 디렉토리로 이동합니다. BASE_DIR/es 다음 t다음 명령을 입력합니다.
|
1 |
bin/엘라스틱서치 |
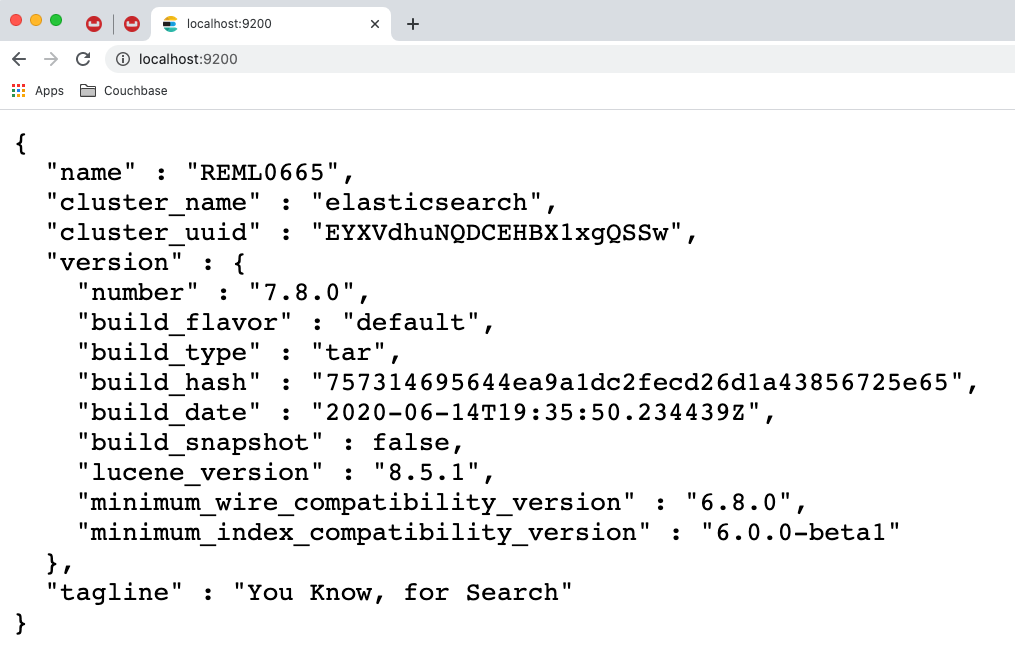
이제 웹 브라우저를 열고 다음 주소로 이동합니다. http://localhost:9200아래와 같은 응답이 표시되어야 하며, 이는 Elasticsearch 서버를 사용할 수 있음을 나타냅니다.
4. Kibana 시작
새 터미널 창을 실행하고 디렉토리로 이동합니다. BASE_DIR/kibana 다음 t다음 명령을 입력합니다.
|
1 |
bin/kibana |
Kibana가 작동하는 모습을 보려면 웹 브라우저를 열고 다음 위치로 이동하세요. http://localhost:5601 .
Elasticsearch 커넥터 설치
-
-
다운로드 최신 버전의 Elasticsearch 커넥터로 이동하여 BASE_DIR. 이 글을 작성하는 시점에서 사용 가능한 가장 최신 버전의 커넥터는 4.2.2입니다. 다음과 같이 보이는 파일을 다운로드하셨을 것입니다.<version>.zip.
-
다운로드한 파일의 압축을 풀고 디렉터리 이름을 cbes.
-
새 터미널을 시작하고 다음 위치로 이동합니다. BASE_DIR 및 t다음 명령을 입력합니다. (한 번에 하나씩). 메시지가 표시되면 "A" 를 클릭하여 파일 압축을 해제합니다.
|
1 |
압축 해제 카우치베이스-엘라스틱서치-커넥터-4.2.2.zip |
|
1 |
mv 카우치베이스-엘라스틱서치-커넥터-4.2.2 cbes |
이제 다음과 같은 중요한 디렉토리를 살펴보겠습니다. cbes
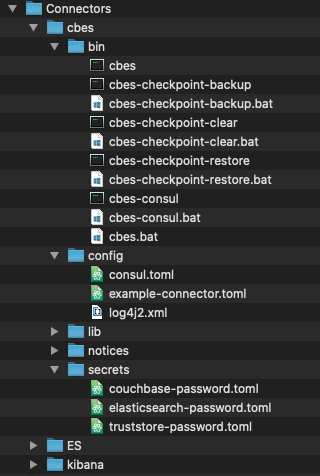
bin - 에는 커넥터를 관리하는 데 필요한 모든 명령줄 유틸리티가 포함되어 있습니다.
구성 - 에는 참조로 사용할 수 있는 기본 구성 파일이 포함되어 있습니다.
비밀 - 에는 Couchbase 및 Elasticsearch 서버에 연결하기 위한 자격 증명이 포함되어 있습니다.
Elasticsearch 수집 노드 파이프라인 구축하기
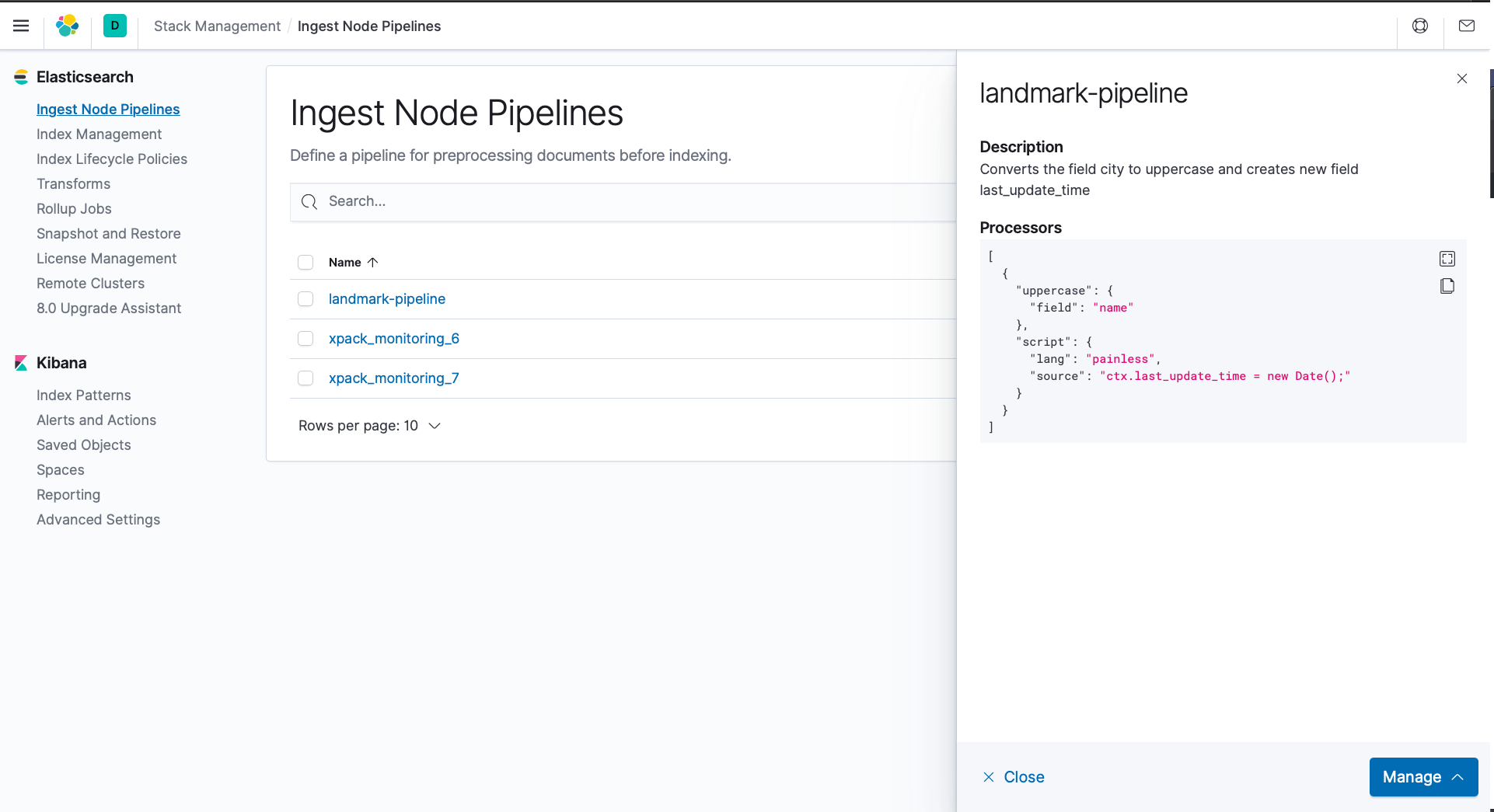
파이프라인을 구축해 보겠습니다. 이름을 "랜드마크 파이프라인". 당사의 파이프라인은 다음과 같습니다.
-
-
-
- 새 필드 삽입
마지막_업데이트_시간 를 입력하면 현재 날짜/시간이 됩니다. - 필드에 대해 데이터를 대문자로 변환합니다.
이름.
- 새 필드 삽입
-
-
기존 프로세서 중 두 대를 사용하여 수집 파이프라인을 구축할 것입니다.
스크립트 프로세서 : 에 정의된 스크립트를 실행합니다. 간편한 스크립팅 언어.
대문자 프로세서 : 지정된 필드의 값을 대문자로 변환합니다.
1. 새 터미널 창을 실행하고 다음 명령을 실행합니다.
|
1 2 3 4 5 |
curl -X PUT "localhost:9200/_ingest/pipeline/landmark-pipeline?pretty" -H '콘텐츠 유형: 애플리케이션/json' -d' { "description" : "필드 이름을 대문자로 변환하고 새 필드 last_update_time을 만듭니다", "processors" : [ { "대문자": { "field": "name" }, "script": { "lang": "painless", "source": "ctx.last_update_time = new Date();" } } ] }' |
위의 curl 명령은 Elasticsearch 데이터베이스 내에 파이프라인 정의를 생성하고 저장합니다.
2. 웹 브라우저를 열고 다음 주소에서 Kibana로 이동합니다. http://localhost:5601. 방금 만든 파이프라인을 발견에서 볼 수 있어야 합니다. -> 노드 파이프라인 수집.
Elasticsearch 커넥터 구성
1. 새 터미널 창을 실행하고 다음 위치로 이동합니다. BASE_DIR/cbes/config
2. 파일 복사 예제-커넥터.toml 로 설정하고 이름을 기본-커넥터.toml 다음 명령을 실행하여
|
1 |
cp 예제-커넥터.toml 기본값-커넥터.toml |
커넥터는 구성 파일 default-connector.toml이 있다고 가정하고 모든 구성에 대해 이 파일을 읽습니다. 그러나 - -config 명령줄 옵션을 사용하여 커넥터를 배포할 때 구성을 지정할 수도 있습니다. 이 글에서는 기본 구성을 사용하겠습니다.
3. 선택한 편집기에서 default-connector.toml을 열고 다음 구성 설정을 수정합니다. Elasticsearch 커넥터 구성 설정에 대한 자세한 정보가 필요하면 다음으로 이동하세요. 여기.
이 단계를 건너뛰려면 전체 수정된 구성 파일을 찾을 수 있습니다. 여기.
팁: TOML 구성 파일 형식을 처음 사용하는 경우 Nate Finch의 훌륭한 TOML 소개또는 공식 사양.
a ) 아래 [그룹] 테이블에서 이름 키를 "landmark-example-group"으로 설정합니다.
|
1 2 |
[그룹] 이름 = '랜드마크-예시-그룹' |
b) 아래 [elasticsearch.docStructure] 테이블에 문서ContentAtTopLevel 키를 "true"로 설정합니다.
|
1 2 |
[엘라스틱서치.문서 구조] 문서 콘텐츠 최상위 수준 = true |
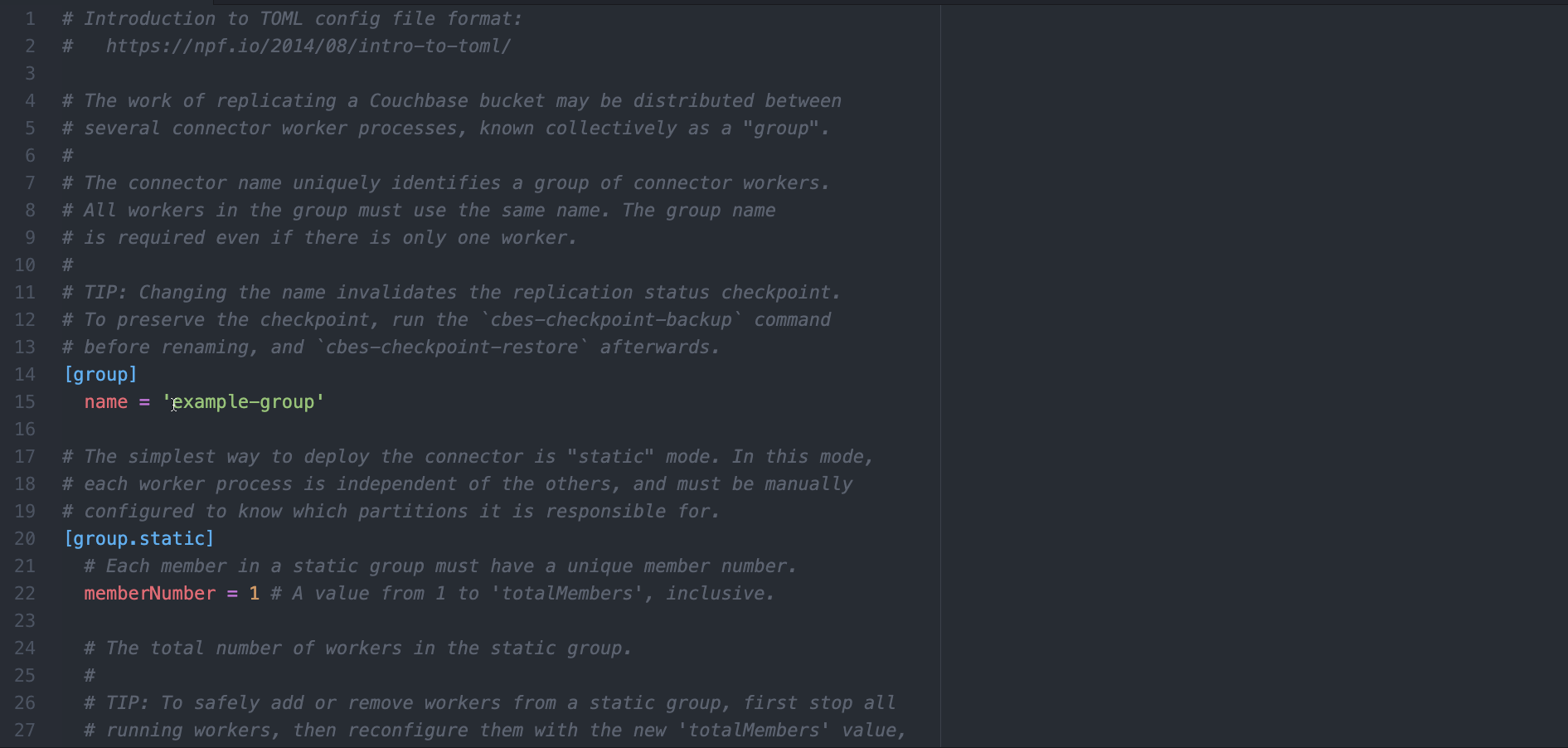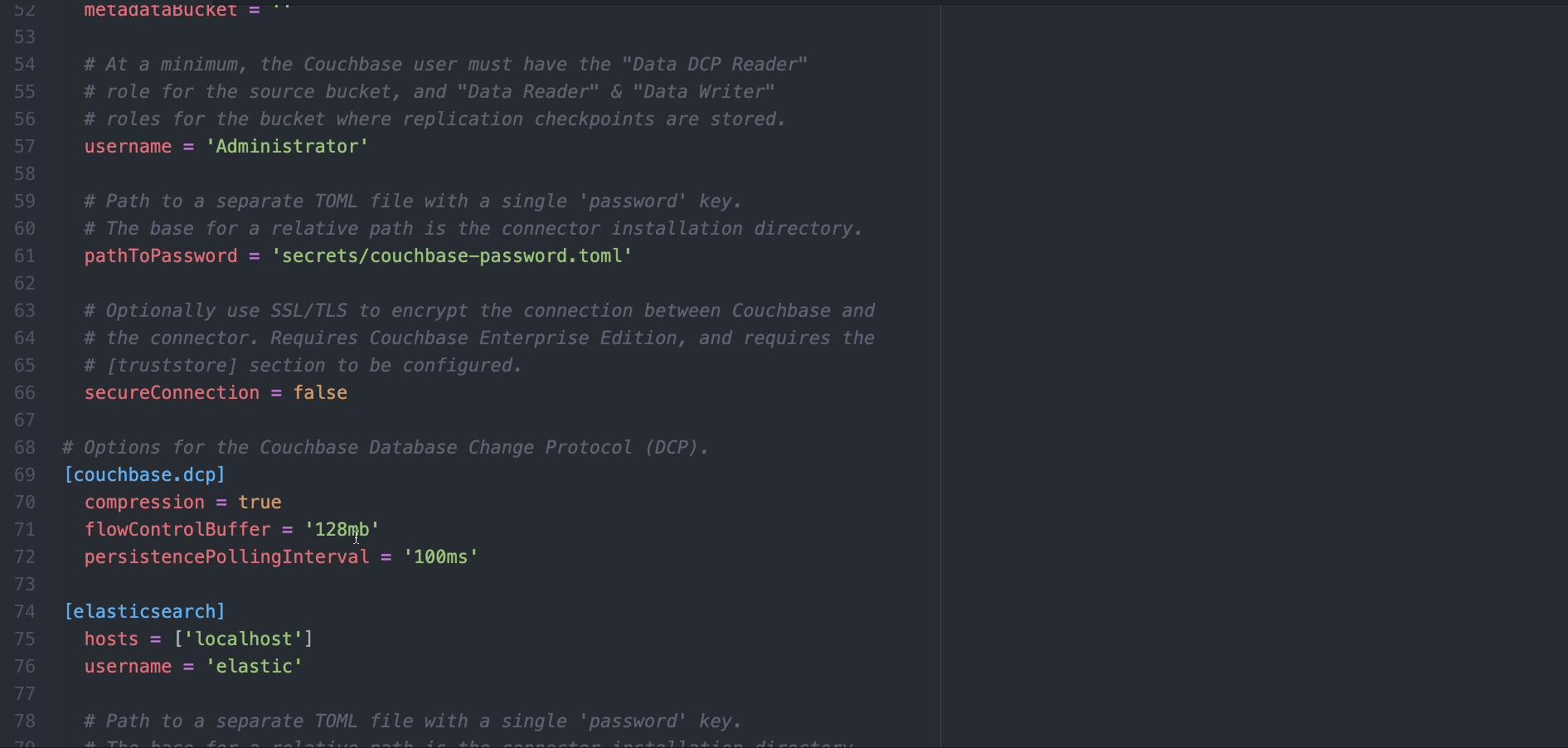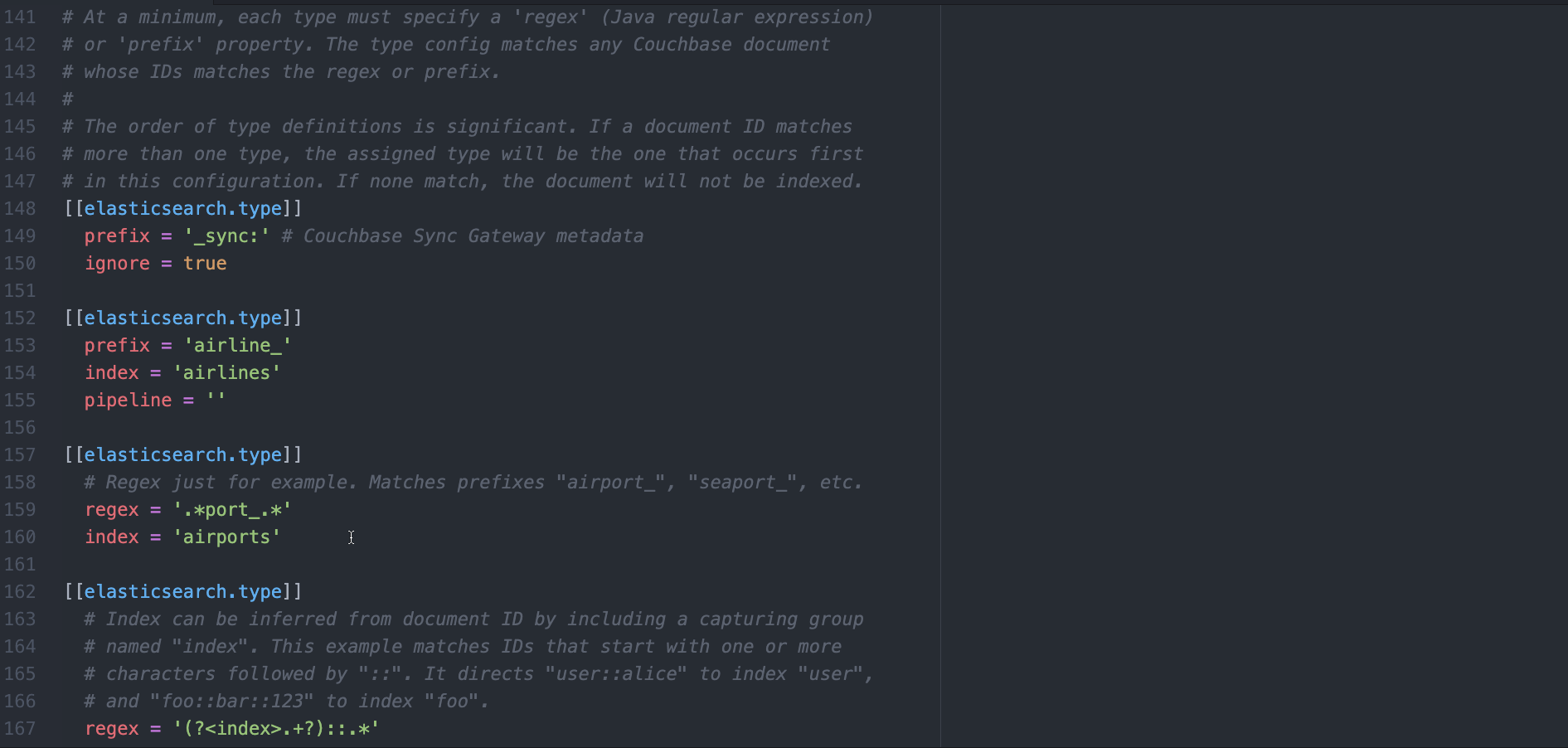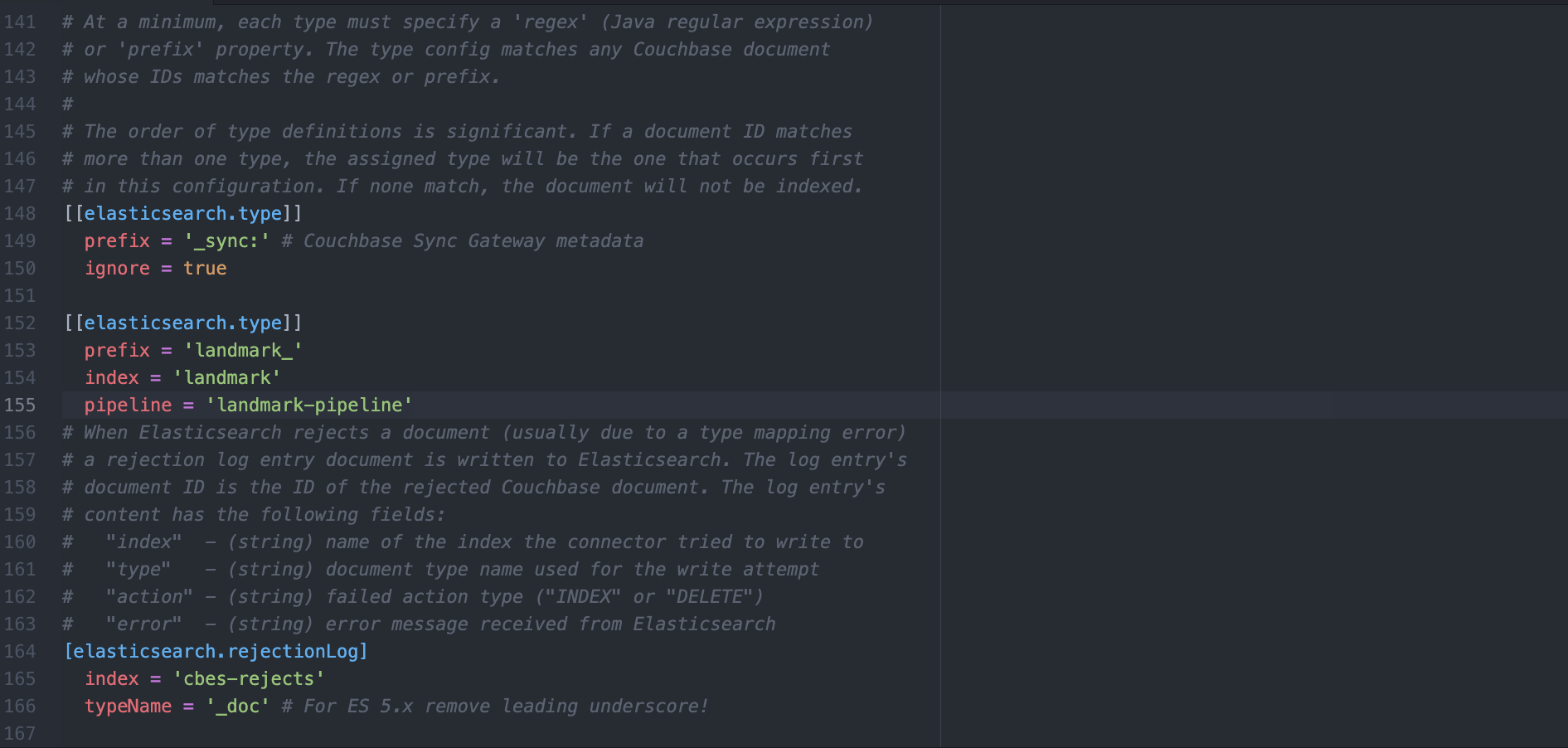
c) 기존 [[elasticsearch.type]] 테이블을 삭제하고 다음으로 바꿉니다.
|
1 2 3 4 5 6 7 8 |
[[엘라스틱서치.유형]] 접두사 = '_sync:' 무시 = true [[엘라스틱서치.유형]] 접두사 = 'landmark_' 색인 = '랜드마크' 파이프라인 = '랜드마크 파이프라인' |
Elasticsearch 커넥터 배포
모든 준비가 완료되었습니다. 이제 이 모든 것이 실제로 작동하는 것을 볼 차례입니다.
Elasticsearch 커넥터는 세 가지 모드로 배포할 수 있습니다.
솔로 : 커넥터가 독립형 프로세스로 실행되는 가장 간단한 모드입니다. 트래픽이 적은 환경이나 개발 환경에서는 단독 모드를 사용하는 것이 좋습니다.
분산 : 이 모드에서는 여러 커넥터가 서로 다른 프로세스로 실행됩니다. 트래픽이 보통에서 높은 수준인 시나리오에서는 이 모드를 사용하는 것이 좋습니다. 하나의 전용 프로세스만 전체 작업을 수행하는 단독 모드와 달리 분산 모드에서는 둘 이상의 프로세스가 있으며 각 커넥터가 작업 부하를 공유하도록 독립적으로 구성됩니다.
자율 운영 모드 : 이는 조정된 서비스에 의해 관리되는 분산 모드라고 생각할 수 있습니다. 조정된 서비스는 서비스 검색 및 구성 관리를 처리합니다. 커넥터 프로세스를 추가하거나 제거하기 전에 프로세스를 중지했다가 다시 시작해야 하는 분산 모드와 달리, 조정된 서비스는 장애 발생 시에도 워커 프로세스가 추가되거나 제거되면 자동으로 워크로드를 분산합니다.
이 글에서는 솔로 모드로 커넥터를 배포하겠습니다. 커넥터를 시작하기 전에 Couchbase의 소스에서 문서 수를 확인해 보겠습니다.
1. 웹 브라우저를 열고 예를 들어 Couchbase 클러스터로 이동합니다. http://127.0.0.1:8091/ui/index.html
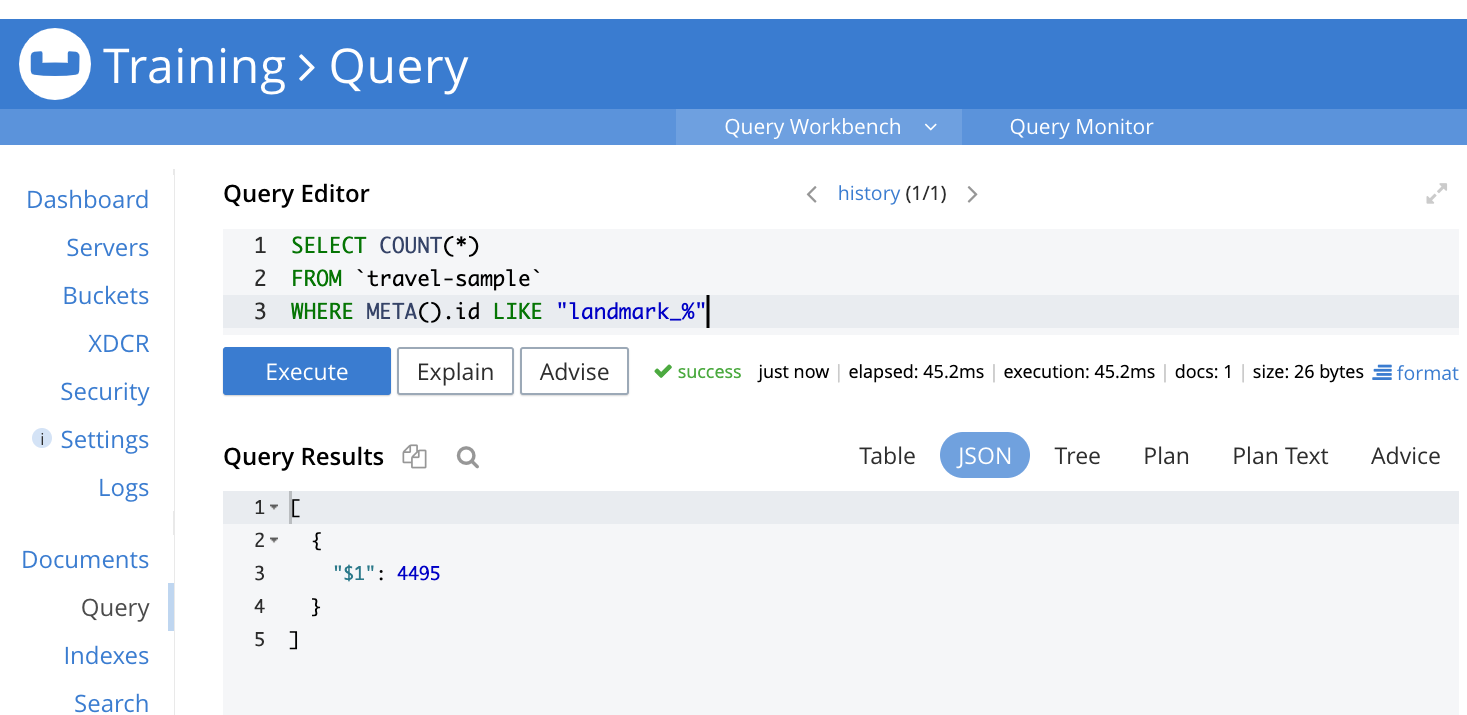
쿼리 메뉴로 이동하여 다음 쿼리를 실행합니다.
|
1 2 3 |
선택 COUNT(*) FROM `여행-샘플` 어디 메타().id 좋아요 'landmark_%' |
이 쿼리는 문서 키가 "landmark_"로 시작하는 여행 샘플 버킷에 있는 문서 수를 반환해야 합니다. 이 경우 문서 수는 4495개입니다.
2. 커넥터를 시작하겠습니다.
새 터미널 창을 실행하고 다음 위치로 이동합니다. BASE_DIR/cbes 디렉토리와 t다음 명령을 입력합니다.
|
1 |
bin/cbes |
커넥터가 문서 복사를 시작해야 합니다. (여기서 문서 키가 "landmark_"로 시작하는 경우) 에서 여행 샘플 버킷을 Elasticsearch에 추가합니다. 이 작업이 진행되는 동안, 수집 노드 파이프라인은 이름 값을 대문자로 변환하고 last_update_time 필드도 생성합니다.
3. 이제 문서가 복제될 때 원하는 변환이 적용되었는지 확인해 보겠습니다.
새 브라우저를 열고 다음 주소에서 Kibana로 이동합니다. http://localhost:5601
-
-
-
- 다음으로 이동합니다. 검색 -> 색인 패턴으로 이동하여 색인 패턴을 정의합니다. 랜드마크가 선택 사항으로 표시되어야 합니다.
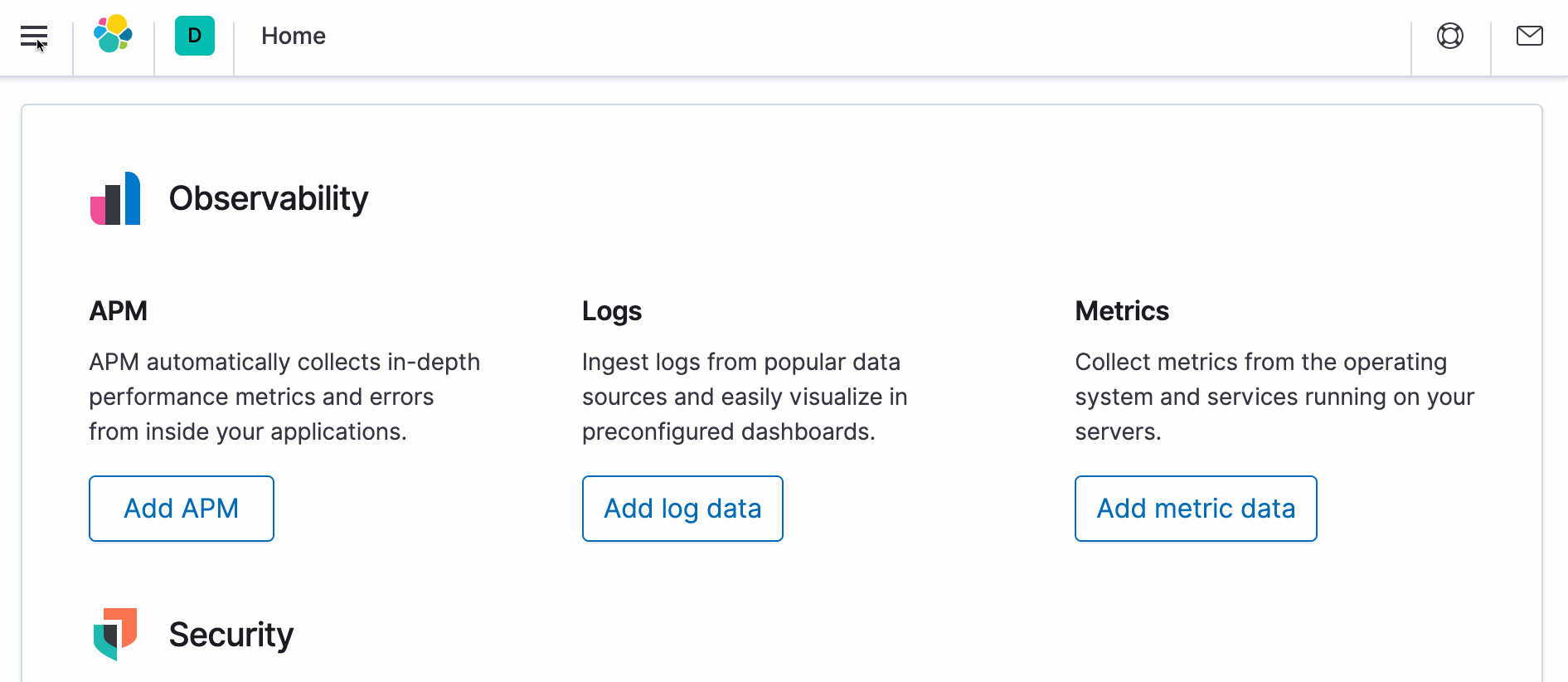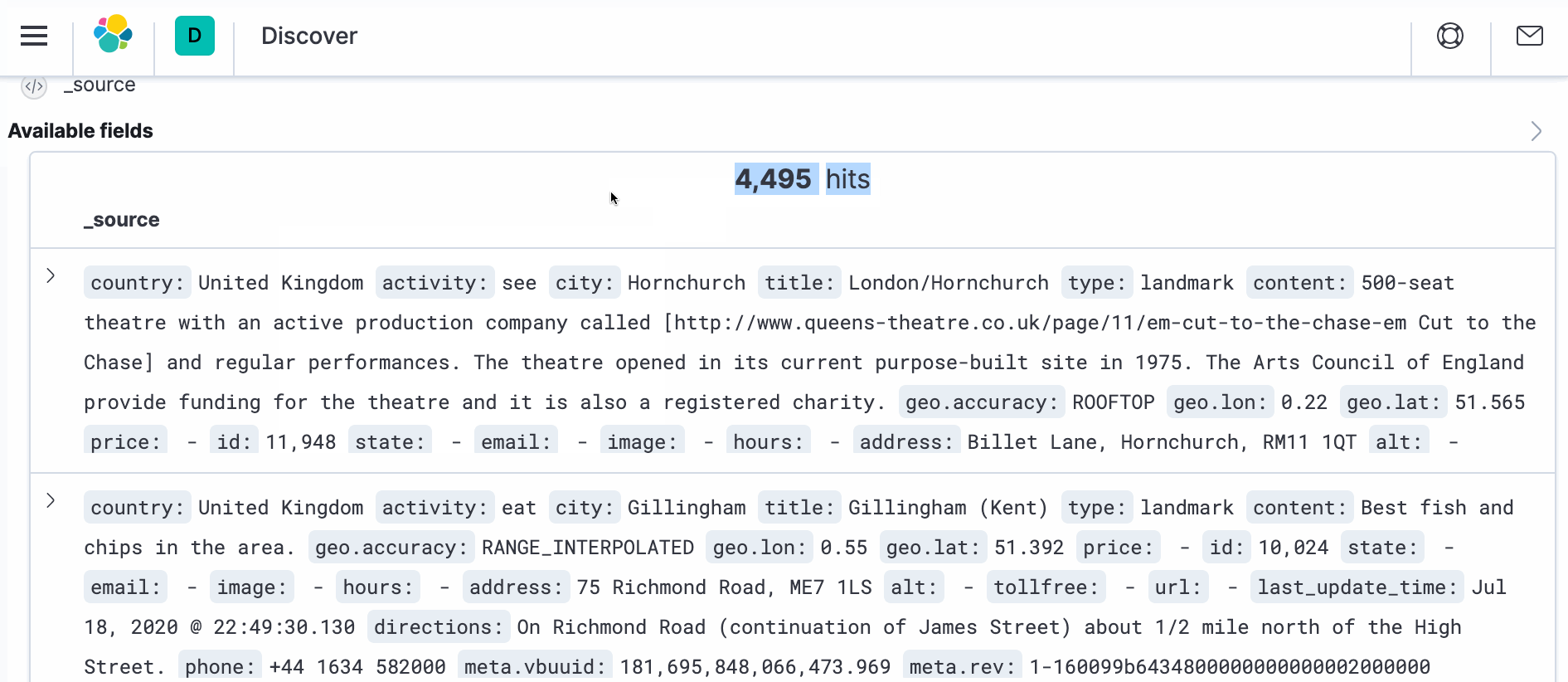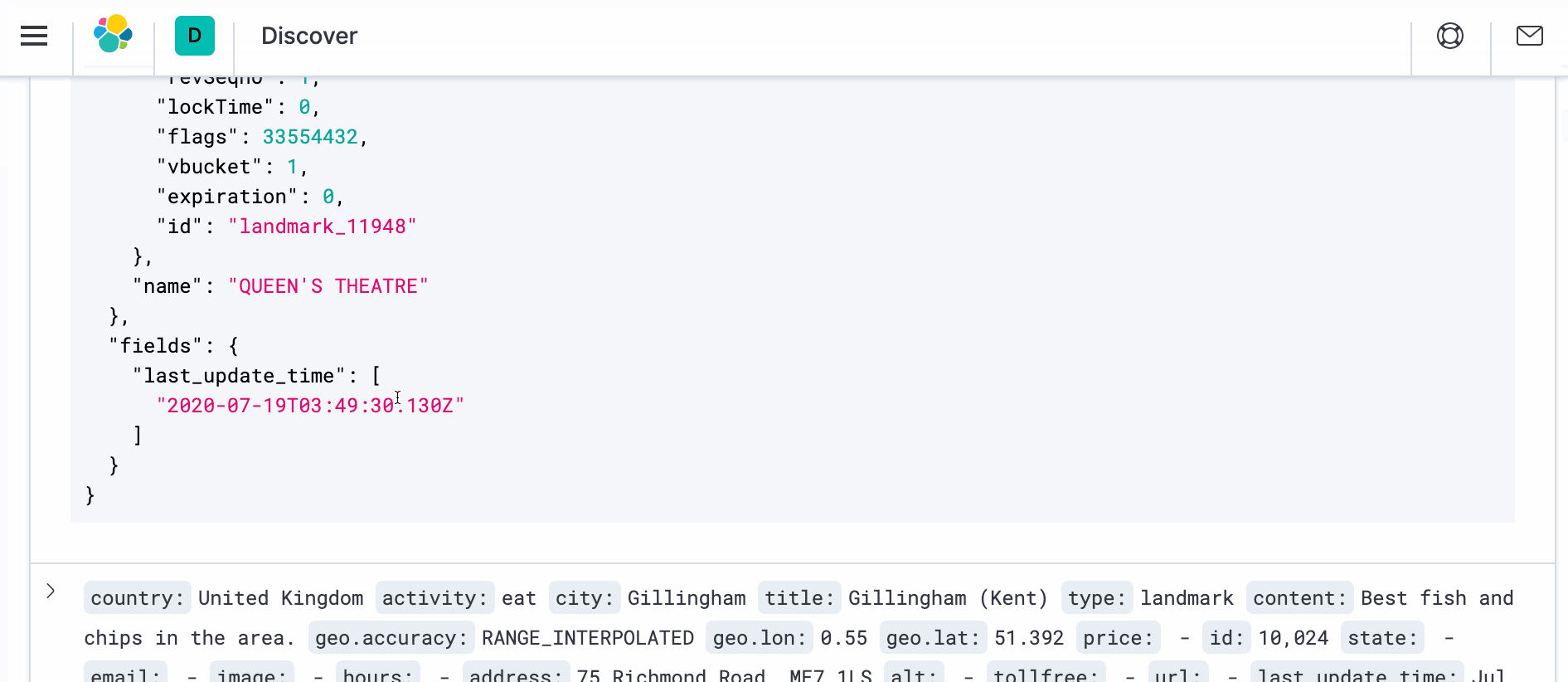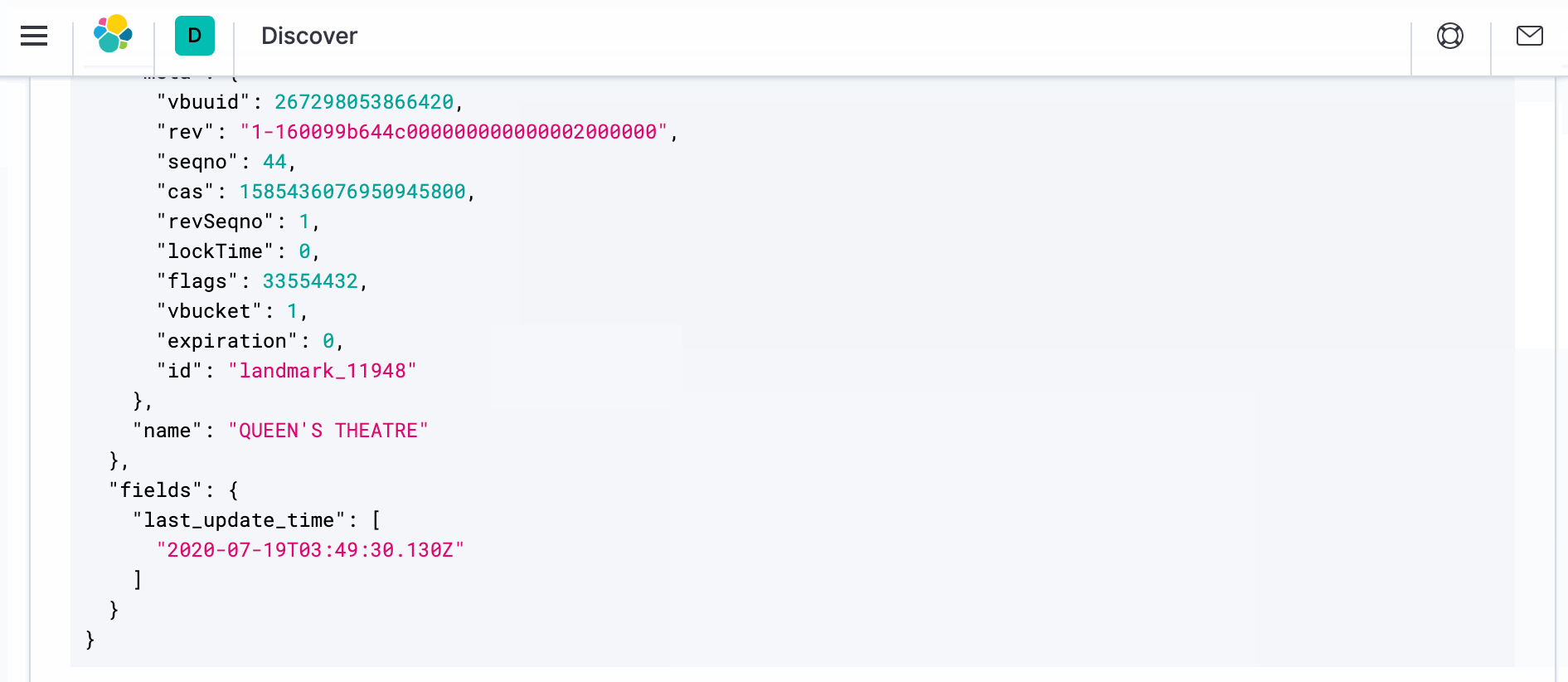
- 다음으로 검색 -> 색인 관리에서 색인 관리로 이동합니다. 원하는 문서 수(4495)가 표시될 것입니다.
- 변환이 적용된 실제 문서를 보려면 새 브라우저 창을 열고 다음 주소에서 Kibana로 이동하세요. http://localhost:5601. Discover로 이동하면 오른쪽에 _source 아래에 다음이 표시됩니다. ">" 기호를 클릭합니다. 이를 클릭한 다음 JSON을 클릭합니다. 아래와 같은 문서가 표시됩니다.
-
-
반복
동일한 데이터 집합이지만 다른 프로세서로 동일한 예제를 시도하거나 오류가 발생하여 처음부터 다시 시작하려는 경우, 매우 간단합니다. 다음과 같이 하면 됩니다.
-
-
-
Kibana 실행 중인 프로세스 중지 (컨트롤 + C를 누릅니다)
-
를 실행하여 Elasticsearch에서 모든 데이터를 삭제합니다. 새 터미널을 열고 다음 명령을 입력합니다.
-
-
|
1 |
curl -X 삭제 'http://localhost:9200/_all' |
3. Elasticsearch 커넥터를 실행 중인 프로세스 중지 (컨트롤 + C를 누릅니다)
4. C시작하여 커넥터 체크포인트 배우기 새 터미널을 열고 다음 명령을 입력합니다.
|
1 |
cbes-체크포인트-clear |
5. Kibana를 다시 시작하고, 파이프라인을 수정하고, 원하는 대로 커넥터 구성을 수정한 다음 커넥터를 다시 시작합니다.
결론
지금까지 Couchbase Elasticsearch 커넥터를 사용하여 수집 노드 파이프라인을 사용해 단독 모드에서 Couchbase에서 Elasticsearch로 데이터 세트를 복제하는 방법을 살펴봤습니다. 이제 Elasticsearch 커넥터 내에서 다양한 파이프라인 프로세서와 구성 설정을 탐색할 준비가 되셨습니다.
마지막으로 "큰 감사" 이 블로그의 결승선을 통과할 수 있도록 도와준 제 동료 Matt Ingenthron, David Nault, Jared Casey에게 감사의 인사를 전합니다!
이 게시물이 마음에 들었거나 궁금한 점이 있으면 댓글을 남겨 주세요.