최근의 Kubernetes와 데이터베이스 도커화 여부에 대한 모든 논의와는 별개로, 오늘은 확장성과 탄력성이 아키텍처에서 큰 요구 사항일 때 이 두 가지가 왜 좋은 솔루션이 될 수 있는지 보여드리고자 합니다.
비결은 간단합니다: 쿠버네티스를 사용한 스프링 부팅 NoSQL을 사용하여 애플리케이션과 데이터베이스를 모두 배포할 수 있습니다.
왜 NoSQL과 스프링 데이터인가?
문서 데이터베이스를 사용하면 전체 구조가 단일 문서에 저장되므로 불필요한 조인을 많이 피할 수 있습니다. 따라서 데이터가 증가함에 따라 자연스럽게 관계형 모델보다 더 빠른 성능을 발휘합니다.
JVM 언어 중 하나를 사용 중이라면 Spring Data와 Spring Boot가 꽤 익숙할 것입니다. 따라서 사전 지식이 없어도 NoSQL을 빠르게 시작할 수 있습니다.
왜 쿠버네티스인가?
쿠버네티스(K8s)를 사용하면 클라우드에 구애받지 않는 환경에서 상태 저장 애플리케이션을 확장 및 축소할 수 있습니다. 최근 몇 가지 버전에서는 데이터베이스와 같은 상태 저장 애플리케이션을 실행할 수 있는 기능도 추가되었는데, 이것이 바로 요즘 K8이 화제가 되고 있는 (많은) 이유 중 하나입니다.
에서 보여드렸습니다. 이전 블로그 게시물 K8에 Couchbase를 배포하는 방법과 쉽게 확장 및 축소하여 "탄력적으로" 만드는 방법에 대해 설명합니다. 아직 읽어보지 않으셨다면 여기서 설명할 내용 중 중요한 부분이므로 몇 분만 더 시간을 내어 동영상 대본을 살펴보시기 바랍니다.
사용자 프로필 마이크로서비스 만들기
대부분의 시스템에서 사용자(및 모든 관련 엔티티)는 가장 자주 액세스하는 데이터입니다. 따라서 데이터가 증가함에 따라 시스템에서 가장 먼저 일종의 최적화를 거쳐야 하는 부분 중 하나입니다.
캐시 레이어를 추가하는 것이 가장 먼저 생각할 수 있는 최적화 유형입니다. 하지만 아직 '최종 해결책'은 아닙니다. 사용자가 수천 명에 달하거나 사용자 관련 엔티티도 메모리에 저장해야 하는 경우에는 상황이 조금 더 복잡해질 수 있습니다.
방대한 양의 사용자 프로필을 관리하는 것은 문서 데이터베이스에 적합한 것으로 잘 알려져 있습니다. 문서 데이터베이스의 포켓몬 고 사용 사례를 예로 들 수 있습니다. 따라서 확장성과 탄력성이 뛰어난 사용자 프로필 서비스를 구축하는 것은 확장성이 뛰어난 마이크로 서비스를 설계하는 방법을 보여줄 수 있는 충분한 과제인 것 같습니다.
필요한 것
- 카우치베이스
- JDK 및 롬복용 플러그인 이클립스 또는 인텔리전트
- Maven
- 구버네티스 클러스터 - AWS의 3개 노드에서 이 예제를 실행하고 있습니다(미니큐브는 사용하지 않는 것이 좋습니다). 설정 방법을 모르는 경우 다음을 참조하세요. 비디오.
코드
여기에서 전체 프로젝트를 복제할 수 있습니다:
|
1 |
https://github.com/couchbaselabs/kubernetes-starter-kit |
사용자라는 기본 엔티티를 만드는 것부터 시작하겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
@Document @Data @AllArgsConstructor @NoArgsConstructor @EqualsAndHashCode public class User extends BasicEntity { @NotNull @Id private String id; @NotNull @Field private String name; @Field private Address address; @Field private List<Preference> preferences = new ArrayList<>(); @Field private List<String> securityRoles = new ArrayList<>(); } |
이 엔티티에는 두 가지 중요한 속성이 있습니다:
- 보안 역할: 사용자가 시스템 내에서 수행할 수 있는 모든 역할.
- 환경설정: 언어, 알림, 통화 등 사용자가 가질 수 있는 모든 가능한 기본 설정이 포함됩니다.
이제 리포지토리를 조금 사용해 보겠습니다. Spring 데이터를 사용하고 있으므로 여기에서 거의 모든 기능을 사용할 수 있습니다:
|
1 2 3 4 5 |
@N1qlPrimaryIndexed @ViewIndexed(designDoc = "user") public interface UserRepository extends CouchbasePagingAndSortingRepository<User, String> { List<User> findByName(String name); } |
카우치베이스와 Spring 데이터에 대해 더 자세히 알고 싶으시다면, 이 튜토리얼을 확인하세요..
다른 두 가지 방법도 구현했습니다:
|
1 2 3 4 5 6 |
@Query("#{#n1ql.selectEntity} where #{#n1ql.filter} and ANY preference IN " + " preferences SATISFIES preference.name = $1 END") List<User> findUsersByPreferenceName(String name); @Query("#{#n1ql.selectEntity} where #{#n1ql.filter} and meta().id = $1 and ARRAY_CONTAINS(securityRoles, $2)") User hasRole(String userId, String role); |
- hasRole: 사용자에게 지정된 역할이 있는지 확인합니다:
- findUsersByPreferenceName: 이름 그대로 특정 환경설정이 포함된 모든 사용자를 찾습니다.
위 코드에서는 일반 JQL을 사용하는 것보다 쿼리가 훨씬 간단하기 때문에 N1QL 구문을 사용하고 있음을 알 수 있습니다.
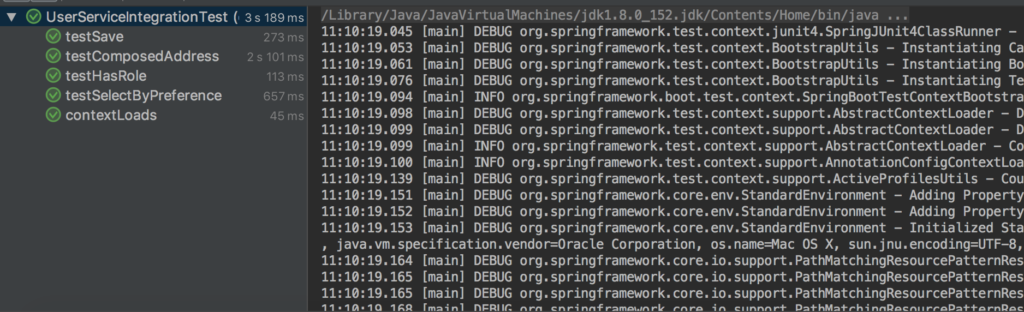
또한 모든 테스트를 실행하여 모든 것이 제대로 작동하는지 확인할 수 있습니다:
데이터베이스의 올바른 자격 증명으로 application.properties를 변경하는 것을 잊지 마세요:
|
1 2 3 4 |
spring.couchbase.bootstrap-hosts=localhost spring.couchbase.bucket.name=test spring.couchbase.bucket.password=couchbase spring.data.couchbase.auto-index=true |
마이크로서비스를 테스트하기 위해 몇 가지 Restful 엔드포인트를 추가했습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
@RestController @RequestMapping("/api/user") public class UserServiceController { @Autowired private UserService userService; @RequestMapping(value = "/{id}", method = GET, produces = APPLICATION_JSON_VALUE) public User findById(@PathParam("id") String id) { return userService.findById(id); } @RequestMapping(value = "/preference", method = GET, produces = APPLICATION_JSON_VALUE) public List<User> findPreference(@RequestParam("name") String name) { return userService.findUsersByPreferenceName(name); } @RequestMapping(value = "/find", method = GET, produces = APPLICATION_JSON_VALUE) public List<User> findUserByName(@RequestParam("name") String name) { return userService.findByName(name); } @RequestMapping(value = "/save", method = POST, produces = APPLICATION_JSON_VALUE) public User findUserByName(@RequestBody User user) { return userService.save(user); } } |
마이크로서비스 도커화
먼저 application.properties 를 사용하여 환경 변수에서 연결 자격 증명을 가져옵니다:
|
1 2 3 4 |
spring.couchbase.bootstrap-hosts=${COUCHBASE_HOST} spring.couchbase.bucket.name=${COUCHBASE_BUCKET} spring.couchbase.bucket.password=${COUCHBASE_PASSWORD} spring.data.couchbase.auto-index=true |
이제 Docker파일을 만들 수 있습니다:
|
1 2 3 4 5 6 |
FROM openjdk:8-jdk-alpine VOLUME /tmp MAINTAINER Denis Rosa <denis.rosa@couchbase.com> ARG JAR_FILE ADD ${JAR_FILE} app.jar ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"] |
그런 다음 Docker Hub에 이미지를 빌드하고 게시합니다:
- 이미지를 만듭니다:
|
1 |
./mvnw install dockerfile:build -DskipTests |
- 명령줄에서 Docker Hub에 로그인합니다.
|
1 |
docker login |

- 최근에 생성한 이미지의 이미지아이디를 가져옵니다:
1docker images

- 이미지아이디를 사용하여 새 태그를 만듭니다:
|
1 2 |
//docker tag YOUR_IMAGE_ID YOUR_USER/REPO_NAME docker tag 3f9db98544bd deniswsrosa/kubernetes-starter-kit |
- 마지막으로 이미지를 푸시합니다:
1docker push deniswsrosa/kubernetes-starter-kit
 이제 Docker Hub에서 이미지를 사용할 수 있습니다:
이제 Docker Hub에서 이미지를 사용할 수 있습니다:

데이터베이스 구성
이에 대한 전체 기사를 작성했습니다. 여기를 사용하되 짧게 유지하세요. 다음 명령을 실행하면 됩니다. 쿠버네티스 디렉터리 내부.
|
1 2 3 4 |
./rbac/cluster_role.sh kubectl create -f secret.yaml kubectl create -f operator.yaml kubectl create -f couchbase-cluster.yaml |
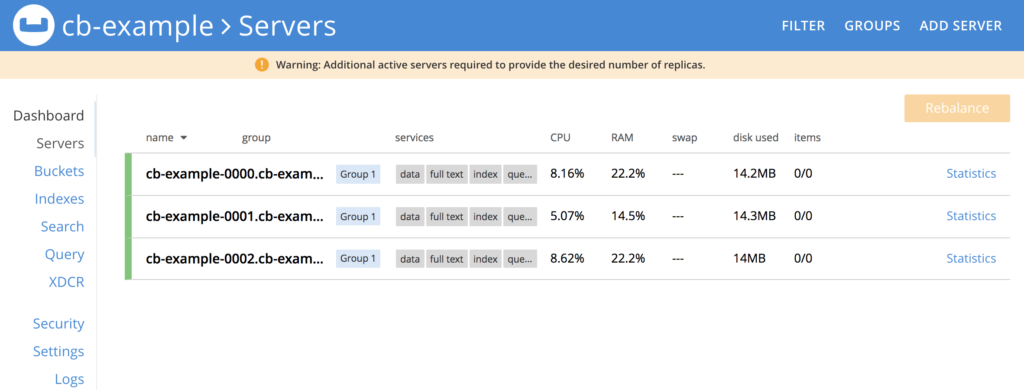
잠시 후 데이터베이스의 3개 인스턴스가 모두 실행되어야 합니다:

웹 콘솔의 포트를 로컬 머신으로 전달해 보겠습니다:
|
1 |
kubectl port-forward cb-example-0000 8091:8091 |
이제 https://localhost:8091 에서 웹 콘솔에 액세스할 수 있습니다. 다음 사용자 아이디를 사용하여 로그인할 수 있습니다. 관리자 및 비밀번호 비밀번호
다음으로 이동 보안 -> 사용자 추가 를 다음과 같은 속성으로 설정합니다:
- 사용자 이름: 카우치베이스 샘플
- 전체 이름: 카우치베이스 샘플
- 비밀번호: 카우치베이스 샘플
- 비밀번호를 인증합니다: 카우치베이스 샘플
- 역할: 아래 이미지를 참조하세요:
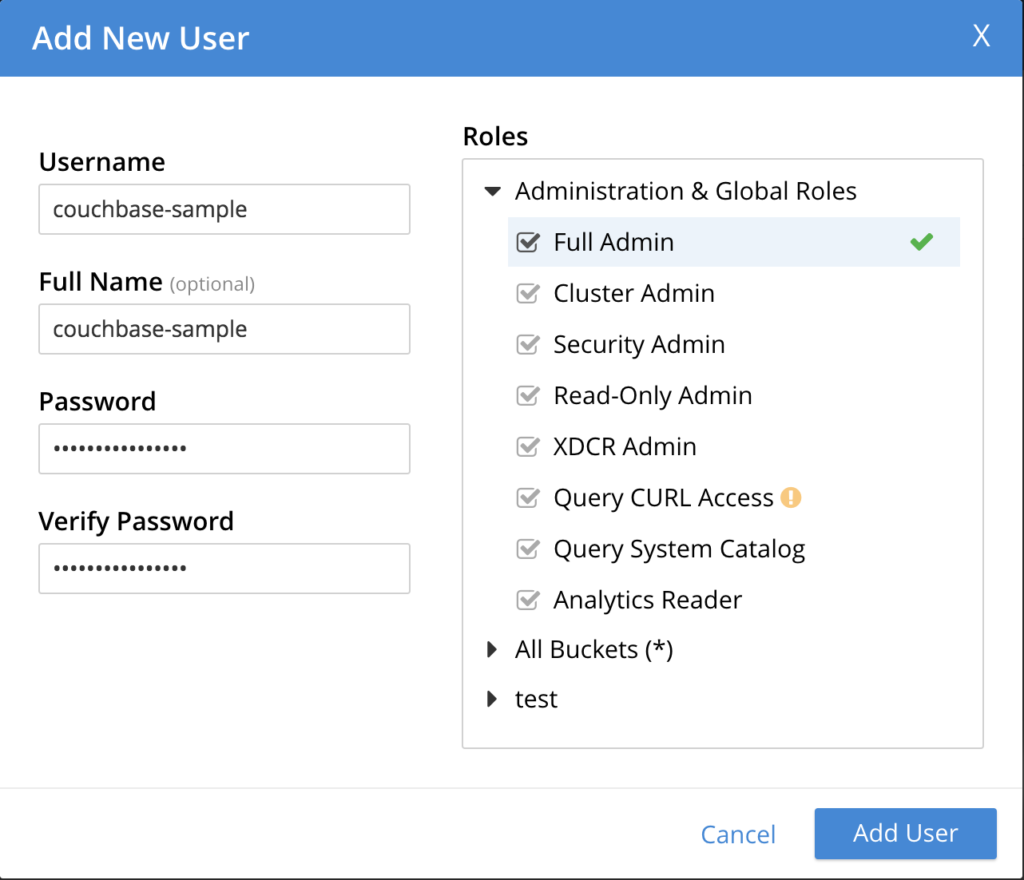
OBS: 프로덕션 환경에서는 앱을 관리자로 추가하지 마세요.
마이크로서비스 배포
먼저 데이터베이스에 연결하기 위한 비밀번호를 저장할 Kubernetes 시크릿을 만들어 보겠습니다:
|
1 2 3 4 5 6 7 |
apiVersion: v1 kind: Secret metadata: name: spring-boot-app-secret type: Opaque data: bucket_password: Y291Y2hiYXNlLXNhbXBsZQ== #couchbase-sample in base64 |
다음 명령을 실행하여 비밀번호를 생성합니다:
|
1 |
kubectl create -f spring-boot-app-secret.yaml |
파일 spring-boot-app.yaml 앱 배포를 담당하고 있습니다. 그 내용을 살펴보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
apiVersion: apps/v1beta1 kind: Deployment metadata: name: spring-boot-deployment spec: selector: matchLabels: app: spring-boot-app replicas: 2 # tells deployment to run 2 pods matching the template template: # create pods using pod definition in this template metadata: labels: app: spring-boot-app spec: containers: - name: spring-boot-app image: deniswsrosa/kubernetes-starter-kit imagePullPolicy: Always ports: - containerPort: 8080 name: server - containerPort: 8081 name: management env: - name: COUCHBASE_PASSWORD valueFrom: secretKeyRef: name: spring-boot-app-secret key: bucket_password - name: COUCHBASE_BUCKET value: couchbase-sample - name: COUCHBASE_HOST value: cb-example |
이 파일에서 몇 가지 중요한 부분을 강조하고 싶습니다:
- 복제본: 2 -> 쿠버네티스는 앱의 인스턴스 2개를 실행합니다.
- 이미지: 데니스워스로사/쿠버네티스 스타터 키트 -> 이전에 만든 도커 이미지입니다.
- 컨테이너: 이름: -> 여기에서 애플리케이션을 실행하는 컨테이너의 이름을 정의합니다. 실행해야 하는 인스턴스 수, 자동 확장 전략, 로드 밸런싱 등을 정의할 때마다 Kubernetes에서 이 이름을 사용하게 됩니다.
- 환경: -> 여기에서 앱의 환경 변수를 정의합니다. 앞서 만든 시크릿을 참조하고 있다는 점에 유의하세요.
다음 명령을 실행하여 앱을 배포합니다:
|
1 |
kubectl create -f spring-boot-app.yaml |
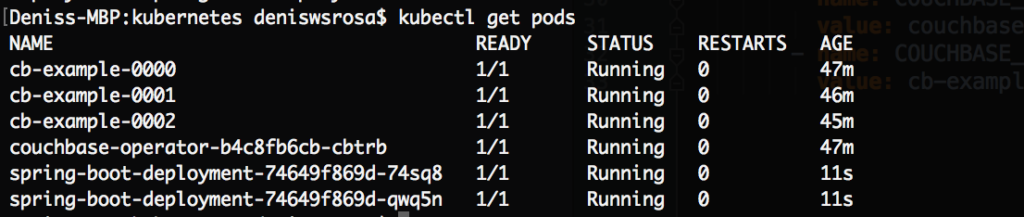
몇 초 후에 애플리케이션의 두 인스턴스가 이미 실행 중인 것을 확인할 수 있습니다:
마지막으로 마이크로서비스를 외부에 노출해 봅시다. 이를 수행하는 방법에는 수십 가지의 다양한 가능성이 있습니다. 여기서는 간단히 로드 밸런서를 만들어 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
apiVersion: v1 kind: Service metadata: name: spring-boot-load-balancer spec: ports: - port: 8080 targetPort: 8080 name: http - port: 8081 targetPort: 8081 name: management selector: app: spring-boot-app type: LoadBalancer |
선택기는 위 파일에서 가장 중요한 부분 중 하나입니다. 트래픽이 리디렉션될 컨테이너를 정의하는 곳입니다. 이 경우에는 이전에 배포한 앱을 가리키고 있습니다.
다음 명령을 실행하여 로드 밸런서를 생성합니다:
|
1 |
kubectl create -f spring-boot-load-balancer.yaml |
로드 밸런서가 가동되어 트래픽을 파드로 리디렉션하는 데 몇 분 정도 걸립니다. 다음 명령을 실행하여 상태를 확인할 수 있습니다:
|
1 |
kubectl describe service spring-boot-load-balancer |
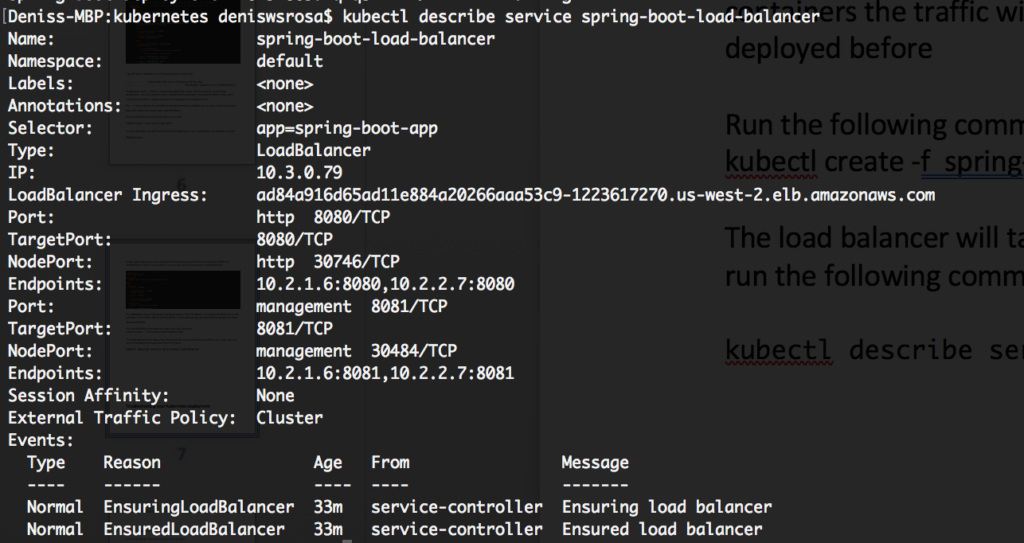
위 이미지에서 볼 수 있듯이 로드 밸런서는 ad84a916d65ad11e884a20266aaa53c9-1223617270.us-west-2.elb.amazonaws.com에서 액세스할 수 있으며, 대상 포트 8080은 트래픽을 두 엔드포인트로 리디렉션합니다: 10.2.1.6:8080 및 10.2.2.7:8080
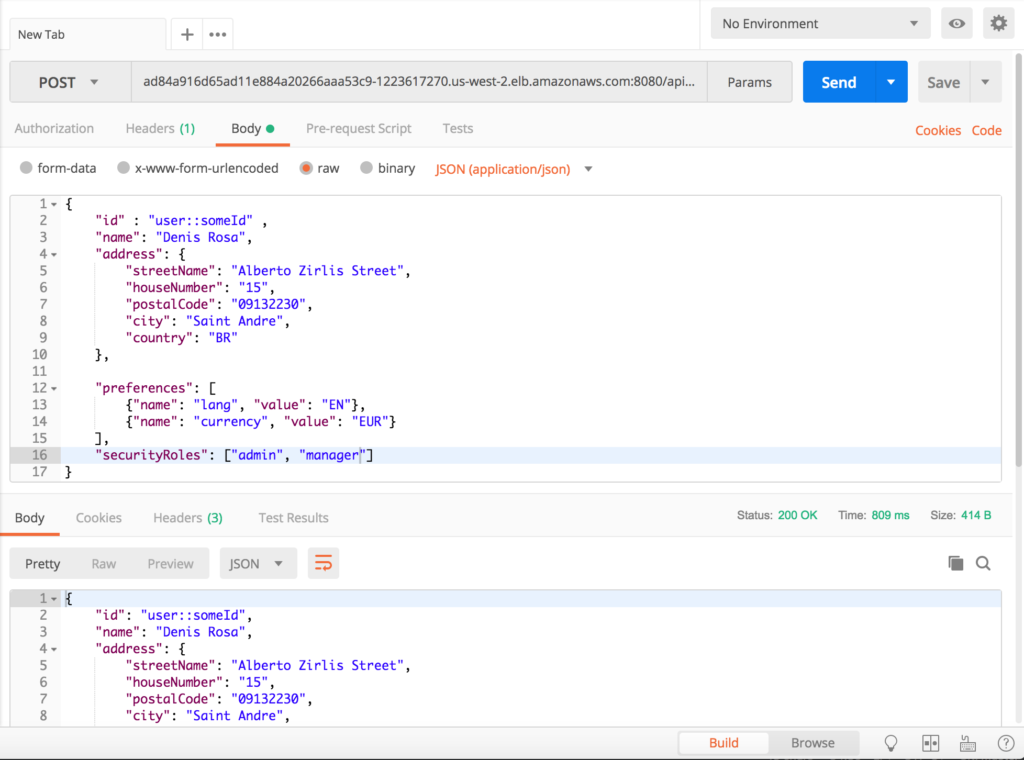
마지막으로 애플리케이션에 액세스하여 요청을 보낼 수 있습니다:
- 새 사용자 삽입하기:
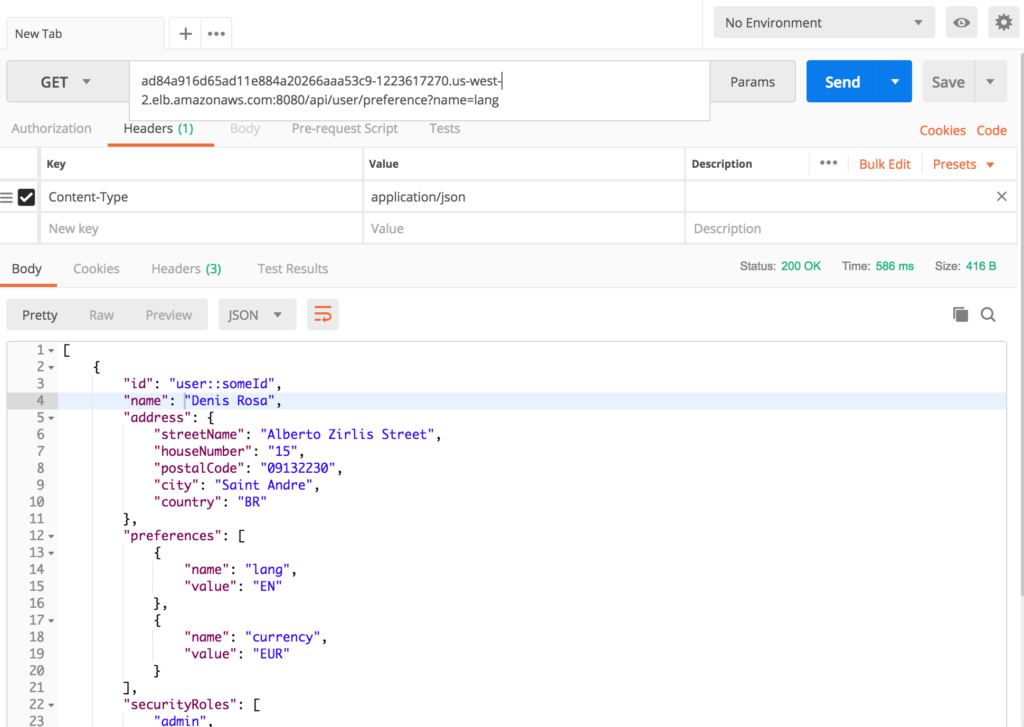
- 사용자 검색하기:
Elastic은 어떨까요?
여기서 정말 흥미로운 일이 벌어집니다. 마이크로서비스 전체를 확장해야 한다면 어떻게 해야 할까요? 블랙 프라이데이가 다가오는데 웹사이트를 방문하는 수많은 사용자를 지원하기 위해 인프라를 준비해야 한다고 가정해 봅시다. 이는 쉽게 해결할 수 있는 문제입니다:
- 애플리케이션을 확장하려면 애플리케이션의 복제본 수를 변경하기만 하면 됩니다. spring-boot-app.yaml 파일을 만듭니다.
12345678910...spec:selector:matchLabels:app: spring-boot-appreplicas: 6 # tells deployment to run 6 pods matching the templatetemplate: # create pods using pod definition in this templatemetadata:labels:...
그런 다음 다음 명령을 실행합니다:
|
1 |
kubectl replace -f spring-boot-app.yaml |
빠진 것이 있나요? 네. 데이터베이스는 어떻게 되나요? 그것도 확장해야 합니다:
- 크기 속성을 변경합니다. couchbase-cluster.yaml file:
|
1 2 3 4 5 6 7 8 9 |
... enableIndexReplica: false servers: - size: 6 name: all_services services: - data - index ... |
마지막으로 다음 명령을 실행합니다:
|
1 |
kubectl replace -f couchbase-cluster.yaml |
어떻게 축소할 수 있나요?
스케일링 다운은 스케일업만큼이나 간단하며, 둘 다 변경하기만 하면 됩니다. couchbase-cluster.yaml 그리고 spring-boot-app.yaml:
- couchbase-cluster.yaml
|
1 2 3 4 5 6 7 8 9 |
... enableIndexReplica: false servers: - size: 1 name: all_services services: - data - index ... |
- spring-boot-app.yaml:
|
1 2 3 4 5 6 7 8 9 10 |
... spec: selector: matchLabels: app: spring-boot-app replicas: 1 template: metadata: labels: ... |
그리고 다음 명령을 실행합니다:
|
1 2 |
kubectl replace -f couchbase-cluster.yaml kubectl replace -f spring-boot-app.yaml |
쿠버네티스에서 마이크로서비스 자동 확장하기
이 글의 2부에서는 이 주제에 대해 자세히 살펴보겠습니다. 그 동안 이 동영상에서 포드 자동 확장에 대해 확인할 수 있습니다.
쿠버네티스 배포 문제 해결하기
파드가 시작되지 않는 경우, 여러 가지 방법으로 문제를 해결할 수 있다. 아래 사례에서는 두 애플리케이션 모두 시작에 실패했습니다:
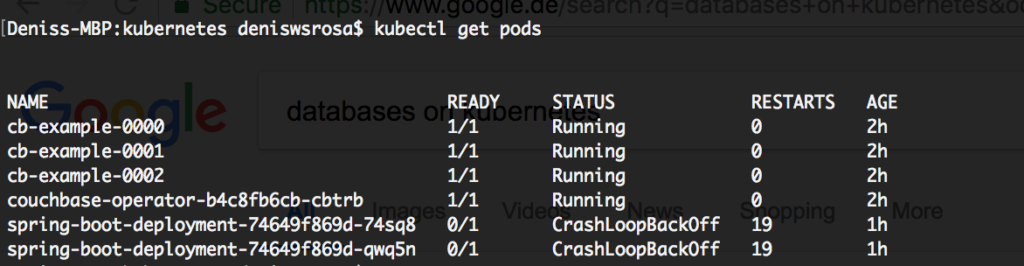
배포의 일부이므로 배포에 대해 설명하여 무슨 일이 일어나고 있는지 이해해 보겠습니다:
|
1 |
kubectl describe deployment spring-boot-deployment |
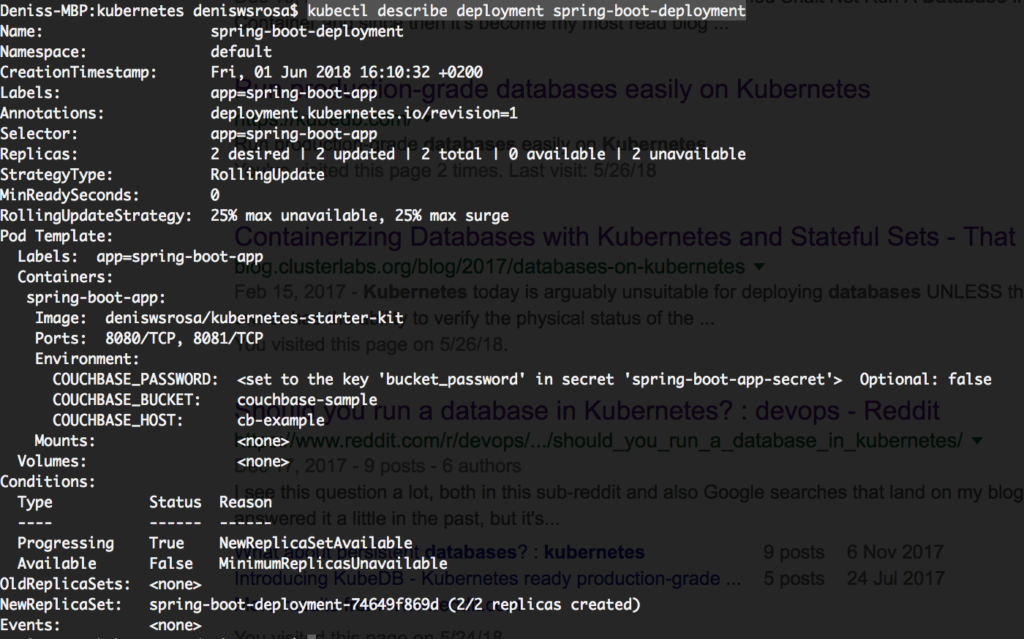
글쎄요, 이 경우에는 실제로 관련이 없습니다. 그렇다면 파드의 로그 중 하나를 살펴봅시다:
|
1 |
kubectl log spring-boot-deployment-74649f869d-74sq8 |
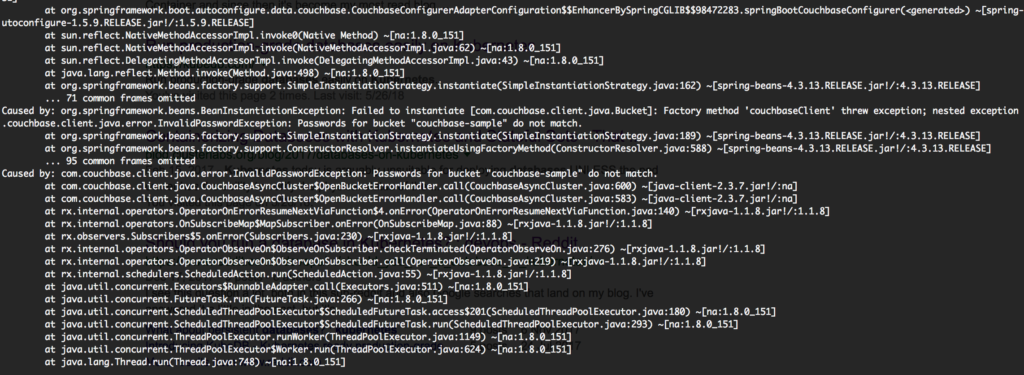
잡았습니다! Couchbase에서 사용자를 생성하는 것을 잊어버려서 애플리케이션이 시작되지 않았습니다. 사용자를 생성하기만 하면 몇 초 안에 파드가 시작됩니다:
결론
데이터베이스는 상태 저장 애플리케이션이며, 데이터베이스를 확장하는 것은 상태 저장 애플리케이션을 확장하는 것만큼 빠르지는 않지만(그리고 앞으로도 그럴 일은 없을 것입니다), 진정으로 탄력적인 아키텍처를 만들어야 한다면 인프라의 모든 구성 요소를 확장할 수 있도록 계획해야 합니다. 그렇지 않으면 다른 곳에 병목 현상을 만들 뿐입니다.
이 글에서는 Kubernetes에서 애플리케이션과 데이터베이스를 모두 탄력적으로 만드는 방법에 대해 간략하게 소개하려고 했습니다. 그러나 아직 프로덕션에 사용할 수 있는 아키텍처는 아닙니다. 아직 고려해야 할 다른 많은 것들이 있으며, 다음 글에서 그 중 일부를 다루겠습니다.
그동안 궁금한 점이 있으시면 다음 주소로 트윗해 주세요. @deniswsrosa 를 클릭하거나 아래에 댓글을 남겨 주세요.