모든 벤치마크는 몇 가지 의문점을 제기합니다. 따라서 모든 벤치마크에서 전체 정보를 얻으려면 데이터를 직접 살펴봐야 합니다. 저는 TPC 시절부터 벤치마크 전쟁을 치르며 한동안 벤치마킹을 해왔지만, 지금은 많은 고객 및 파트너와 함께 내부 및 외부 벤치마크를 통해 제품에 대한 성능을 심층적으로 분석하는 Couchbase에서는 그렇지 않습니다.
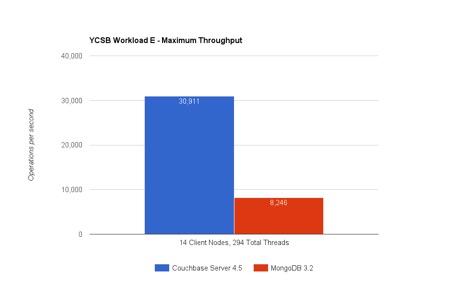
이미 Avalon에서 몽고DB 3.2와 카우치베이스 서버 4.5를 비교한 벤치마크 결과를 보신 분들도 계시리라 생각합니다. 전체 공개를 확인하실 수 있습니다. 여기. 여기에서는 벤치마크의 일부 세부 사항을 자세히 살펴보고 쿼리 실행(YCSB 워크로드 E)과 키 값 액세스(YCSB 워크로드 A) 모두에서 Couchbase Server가 더 빠른 이유를 설명해 보려고 합니다. 이제 결과를 자세히 살펴보겠습니다:
워크로드 E: 스레드 대화 쿼리
워크로드 E 는 스레드 대화를 시뮬레이션하며, 목표는 최대 50개의 대화(항목)를 찾는 범위 쿼리를 가능한 한 빨리 검색하는 것입니다. 쿼리에 수반되는 가벼운 삽입 워크로드도 있습니다(작업의 %5가 INSERT입니다). 따라서 어떻게 카우치베이스 서버가 몽고DB에 비해 초당 3.7배 이상 많은 쿼리를 실행할 수 있을까요?
카우치베이스 서버에서 글로벌 인덱스를 사용한 #1 쿼리 실행
카우치베이스와 몽고DB 배포(샤딩)를 사용하면 데이터를 노드에 고르게 분산할 수 있습니다. 각 노드는 전체 항목의 동일한 부분을 차지합니다. 이 테스트에는 9개의 노드에 1억 5천만 개의 항목이 분산되어 있습니다. 워크로드 E 범위 스캔 쿼리는 인덱스에서 작동합니다. MongoDB는 각 노드의 데이터에 맞춰 파티션을 인덱싱합니다. 즉, 모든 노드는 데이터를 로컬로 색인하는 인덱스 파티션을 갖게 됩니다. 이 테스트에서 Couchbase Server는 대신 글로벌 인덱스를 사용합니다. 글로벌 인덱스는 인덱스를 독립적으로 파티션합니다.
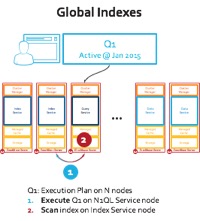
이것이 왜 중요할까요? 즉, MongoDB 쿼리를 실행하려면 9개의 서버 노드에 걸쳐 분산 수집이 필요합니다(아래 로컬 인덱스 그림 참조). 대신 Couchbase Server N1QL 엔진은 인덱스 중 하나를 사용하여 단일 네트워크 홉을 수행하여 범위 스캔을 수행합니다(아래 글로벌 인덱스 그림 참조).
 |
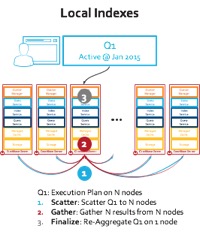 |
그림: 글로벌 및 로컬 인덱스 배포를 통한 쿼리 실행
여기에는 로컬 인덱스 아키텍처에 근본적인 문제가 있습니다: 단계#1에서는 범위 쿼리가 모든 노드에 분산되어 도착합니다. 이 모델에서는 쿼리 실행에 사용되는 인덱스가 데이터 분포에 맞춰 분산되어 있기 때문에 클러스터의 어떤 노드도 질문에 답할 수 없습니다. 모든 노드는 동일한 범위 스캔을 실행하고(참고로, YCSB Workload E의 쿼리는 "order by" 및 "limit 50"으로 범위 스캔을 실행합니다) 해당 범위에 속하는 항목을 가져와야 합니다. 즉, 조정 노드로 이동하는 노드 수*50개의 항목이 있다는 뜻입니다. 이 테스트는 수천 개의 쿼리를 실행하고 네트워크가 포화 상태가 될 때까지 낭비가 반복됩니다! 하지만 이것이 로컬 인덱스의 가장 심각한 문제는 아닙니다...
새 노드를 추가하거나 이 클러스터를 100개 노드로 확장한다고 가정해 보겠습니다. 새 노드마다 여전히 쿼리를 수행해야 합니다. 노드를 추가하여 쿼리를 확장할 수 없습니다! 실제로 노드 간에 네트워크가 포화 상태가 되면 상황이 더 나빠집니다. 또한 많은 양의 CPU 용량을 낭비하고 모든 노드가 항상 참여하게 됩니다.
글로벌 인덱스가 있는 N1QL에서 쿼리를 실행하는 경우에는 상황이 많이 달라집니다. N1QL은 '주문 기준' 및 '제한'을 인덱스에 밀어넣고 50개 항목만 가져옵니다. 네트워크 과부하 없음... 실제로 N1QL은 압축된 결과 집합(RAW)을 사용하여 더 효율적인 검색을 추가합니다. 노드를 추가하거나 100개 노드로 확장하면 처리량에서 실질적인 이점을 얻을 수 있습니다. 실제로 20개 또는 30개의 노드로 YCSB 워크로드 E 테스트를 반복할 수 있으며, Couchbase Server와 MongoDB 처리량 간에 더 큰 차이를 볼 수 있을 것으로 예상합니다.
#2 메모리 최적화 인덱스
글로벌 인덱스는 훌륭하지만 유지 관리가 어렵습니다. 노드 중 하나에 상주하는 글로벌 인덱스는 전체 클러스터에서 진행되는 업데이트 또는 적어도 인덱스와 관련된 모든 변형을 따라잡아야 합니다. 고속 스캔을 수행하면서 데이터 업데이트를 따라잡을 수 있는 매우 효율적인 인덱스 구조가 필요합니다.
Couchbase Server 4.5는 메모리 최적화 인덱스(MOI)라는 새로운 전역 인덱스용 스토리지 아키텍처를 도입했습니다. MOI는 메모리 스토리지에 최적화되어 메모리 공간을 더 적게 차지하며, 잠금 없는 인덱스 유지 관리 로직을 사용하여 대규모 병렬 처리로 데이터에 대한 대규모 업데이트를 인덱싱합니다. MongoDB는 많은 관계형 데이터베이스와 NoSQL 데이터베이스 중에서 상당히 고전적인 B-Tree 인덱스 버전을 사용합니다. 카우치베이스 서버는 HB+Tree와 일부 HB+Trie 인덱스도 함께 제공됩니다. 이러한 인덱스는 표준 저장소 모드와 맵 축소 보기에서 사용됩니다. 그러나 이 새로운 스킵리스트 구조와 잠금 없는 접근 방식은 글로벌 인덱스의 경우 인덱스 유지 관리 및 스캔 성능을 크게 향상시킵니다.
그림: 메모리 최적화된 글로벌 인덱스를 사용한 스킵리스트 잠금 없는 인덱싱
차이점을 빠르게 파악할 수 있도록, 다음은 표준 인덱스 저장 모드와 메모리 최적화 인덱스 저장 모드의 Couchbase Server 인덱싱을 비교한 것입니다. 메모리 최적화 인덱스는 쿼리 응답 시간이 20배 이상 빠릅니다.
이러한 기능 중 일부는 벤치마크에서 사용되지 않았지만, Couchbase Server는 다단계 중첩으로 배열 구조를 색인할 수 있다는 점을 언급할 가치가 있습니다. 예를 들어, 영화와 상영 시간은 관계형 세계에서 2개의 개별 테이블로 정규화될 수 있지만, MongoDB와 Couchbase 모두 상영 시간 배열이 포함된 단일 "영화" 문서로 데이터를 모델링합니다. 단일 영화의 상영 시간을 업데이트하려면 한 번의 업데이트를 실행하면 됩니다. 그러나 배열 인덱스는 각 개별 상영 시간을 인덱싱하기 때문에 많은 업데이트를 받게 됩니다. 인덱스의 업데이트 속도는 배열의 크기만큼 증폭됩니다... 즉, 항목 업데이트 속도가 낮은 시스템이라도 문서에 포함된 배열의 크기에 따라 10배, 20배 또는 100배의 업데이트 양을 따라잡아야 하는 배열 인덱스가 필요할 수 있습니다. MOI는 충분한 컴퓨팅 리소스로 10만 건 이상의 업데이트를 따라잡을 수 있기 때문에 이러한 조건에서 큰 도움이 됩니다.
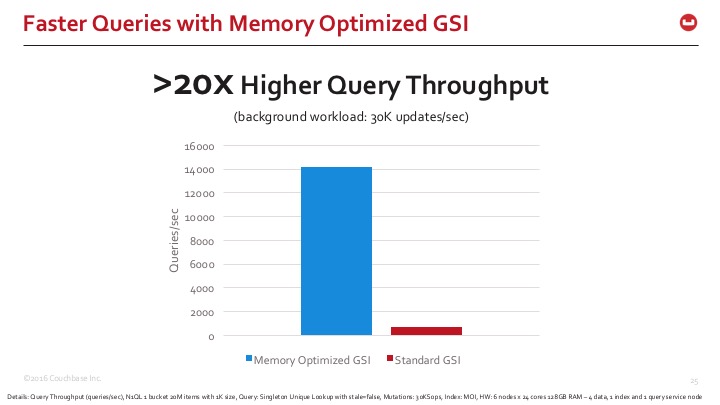
YCSB 워크로드 E 결과 자세히 알아보기
One consolidated view that tells the whole story is the %95th latency and throughput overlaid graph. This is how I view all performance results personally. – If you are the benchmarking type, you know the saying: “처리량 없이 지연 시간을 보는 것은 의미가 없으며, 그 반대의 경우도 마찬가지입니다.".
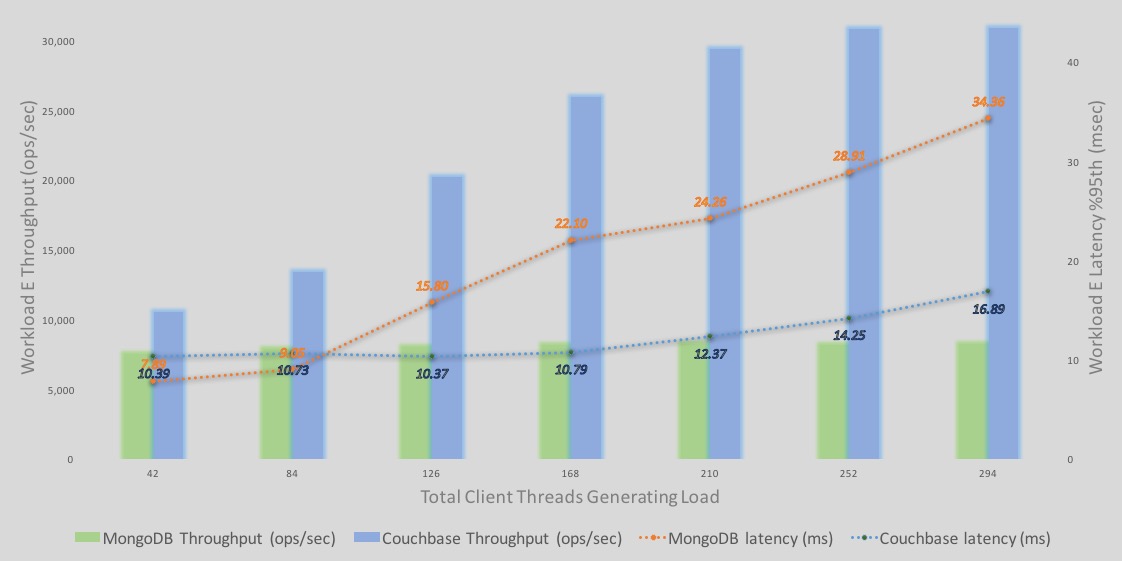
다음은 Workload E 쿼리 실행 처리량 및 지연 시간에 대한 자세한 분석입니다.
-바는 처리량을 나타냅니다. 파란색 는 카우치베이스이고 녹색 는 MongoDB입니다. Y축은 처리량 수치입니다.
-선들은 지연 시간을 나타냅니다. 파란색 는 카우치베이스이고 오렌지 는 MongoDB입니다. 오른쪽의 보조 Y축은 지연 시간 수치를 나타내며, 하강하는 지연 시간 선은 지연 시간이 더 길거나 길어짐을 나타냅니다. 즉, 지연 시간의 보조 축은 하강하는 축 (점선이 떨어지면 지연 시간이 길어짐).
몇 가지 관찰 사항;
–처리량: 카우치베이스 서버 처리량은 부하가 많아질수록 계속 증가합니다. MongoDB 처리량도 증가하지만 소량만 증가하다가 빠르게 레벨이 떨어집니다.
–지연 시간 의 경우 Couchbase가 MongoDB(42개 및 84개 클라이언트)보다 높게 시작합니다. 그러나 42개 및 84개 클라이언트 부하 모두에서 Couchbase Server 처리량이 더 높습니다. 동일한 처리량에서 두 엔진의 지연 시간은 이렇게 가벼운 부하에서는 비슷할 수 있습니다. 그러나 부하가 증가하면 지연 시간이 증가합니다. 하지만 글로벌 인덱스와 MOI의 효과로 인해 250개 이상의 클라이언트에 도달할 때까지 Couchbase가 더 나은 처리량을 제공합니다. 이 시점부터 Couchbase Server의 성능도 평준화됩니다.
워크로드 A: 사용자 세션 기록 및 읽기
워크로드 A 는 50% 읽기 및 50% 업데이트로 최근 사용자 작업을 캡처하고 읽는 워크로드를 시뮬레이션합니다. 이것은 기본적인 키/값 워크로드입니다. 여기서 초당 작업 수가 훨씬 더 높다는 것을 알 수 있습니다. 이는 각 작업이 단일 항목만 처리하기 때문입니다. 반면 워크로드 E는 쿼리당 50개의 항목을 처리합니다.
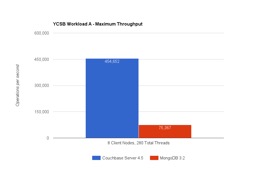
눈을 동그랗게 뜨고 1K 이상의 데이터를 읽고 쓰는 것이 그리 어렵지 않다고 생각할 수도 있습니다. 하지만 이를 효율적으로 수행하는 것은 어렵습니다. 많은 데이터베이스가 읽기 또는 쓰기 중 하나에 맞춰져 있지만, 둘 다에 맞춰져 있지는 않습니다! 두 가지를 함께 사용하면 따라잡기가 어려워집니다. 하지만 어떻게 카우치베이스 서버가 몽고DB에 비해 동일한 HW(아마존 웹 서비스에서 9노드 c3.8xlarge)에서 6배 더 많은 작업을 실행할 수 있을까요?
#3 더 빠른 캐시 데이터 액세스
Couchbase가 밀리초 미만의 빠른 읽기/쓰기를 수행할 수 있는 중요한 이유 중 하나는 내장된 캐싱을 활용하기 때문입니다. 제가 과거에 작업했던 다른 데이터베이스를 포함해 많은 데이터베이스는 데이터베이스에 과도한 부담을 주지 않기 위해 데이터베이스 앞에 캐싱 계층을 두라고 말합니다. 하지만 Couchbase Server는 별도의 캐싱 계층을 배포하지 않습니다. 여기에는 멤캐시드 빠른 데이터 액세스를 위해 이미 내장되어 있습니다. 때로는 메타데이터만, 때로는 데이터와 함께 필요한 문서 부분만 캐시할 수도 있습니다.
#4 프록시 없는 효율적인 클라이언트-서버 통신
Couchbase Server에는 클러스터 토폴로지 및 배포 맵을 캐시할 수 있는 스마트 클라이언트가 함께 제공됩니다. 즉, 클라이언트는 키 값을 가져올 때 통신할 정확한 Couchbase Server 노드를 이미 알고 있습니다. 통신에 홉이 없습니다. 중개자나 경로 재지정 없이 효율적으로 통신할 수 있습니다.
Couchbase Server 통신에 간접적으로 영향을 미치는 추가 기능이 있습니다: 문서 부분 읽기 및 업데이트. 여기서 문서의 하위 집합을 읽고 업데이트하도록 워크로드를 수정하면 새로운 API.
YCSB 워크로드 A 결과 자세히 알아보기
Here is the the %95th latency and throughput overlaid graph.
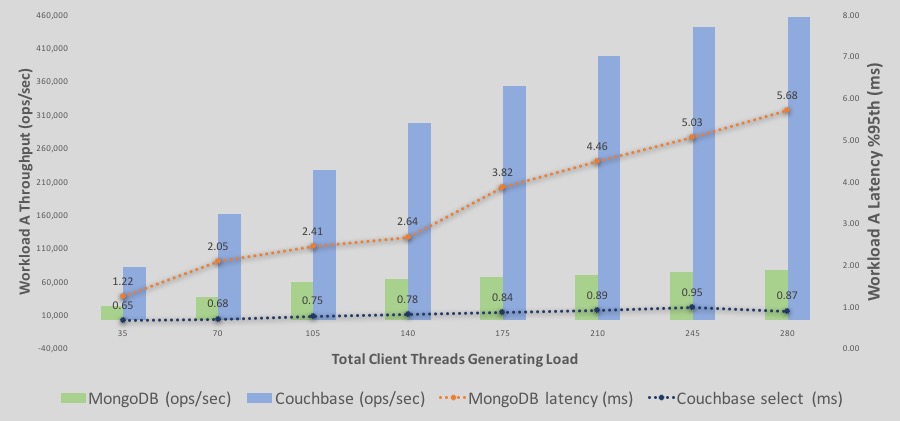
다음은 워크로드 A의 읽기/쓰기 실행 처리량과 지연 시간에 대한 자세한 분석입니다.
-바는 처리량을 나타냅니다. 파란색 는 카우치베이스이고 녹색 는 MongoDB입니다. Y축은 처리량 수치입니다.
-선들은 지연 시간을 나타냅니다. 파란색 는 카우치베이스이고 오렌지 는 MongoDB입니다. 오른쪽의 보조 Y축은 레이턴시 수치를 나타내며, 레이턴시 선이 내림차순으로 갈수록 레이턴시가 나빠지거나 높아집니다. 즉, 레이턴시의 보조 축은 하강하는 축입니다.
몇 가지 관찰 사항;
–처리량: 카우치베이스 서버 처리량은 부하가 증가함에 따라 계속해서 더 높아집니다. MongoDB 처리량도 140개 클라이언트까지 완만한 기울기로 증가합니다. 그러나 약 210개 이상의 스레드에서는 평준화됩니다.
–지연 시간 의 경우 Couchbase가 MongoDB보다 낮게 시작하여 계속 그런 식으로 유지됩니다. 결국 Couchbase는 여전히 밀리초 미만의 지연 시간 범위에 있는 반면, MongoDB는 95% 지연 시간에서 5ms 이상의 지연 시간을 기록합니다.
모든 벤치마크가 회의적인 시각을 불러일으킬 수 있다는 것을 알고 있지만, 여러분 모두 Couchbase Server를 사용해 보시고 사용자 지정 YCSB 실행에서 어떤 결과가 나타나는지 알려주시길 바랍니다. 기대한 결과가 나오지 않는다면 알려주세요.