Couchbase는 세계 최고의 NoSQL 문서 데이터베이스입니다. 엣지, 온프레미스 및 클라우드에서 탁월한 성능, 유연성 및 확장성을 제공합니다. Spark는 가장 인기 있는 인메모리 컴퓨팅 환경 중 하나입니다. 이 두 플랫폼을 결합하여 매우 빠른 쿼리, 데이터 엔지니어링, 데이터 과학 및 머신 러닝 기능을 실행할 수 있습니다.
이 빠른 시작에서는 데이터브릭*을 사용하여 Couchbase를 설정하고 Couchbase 데이터 쿼리 및 Spark SQL 쿼리를 실행하는 간단한 단계를 안내해 드립니다.
*참고: 이 빠른 시작의 단계는 데이터브릭스 런타임 10.4 LTS에 대해 검증되었습니다.
설정
전제 조건
이 빠른 시작을 완료하려면 다음이 필요합니다:
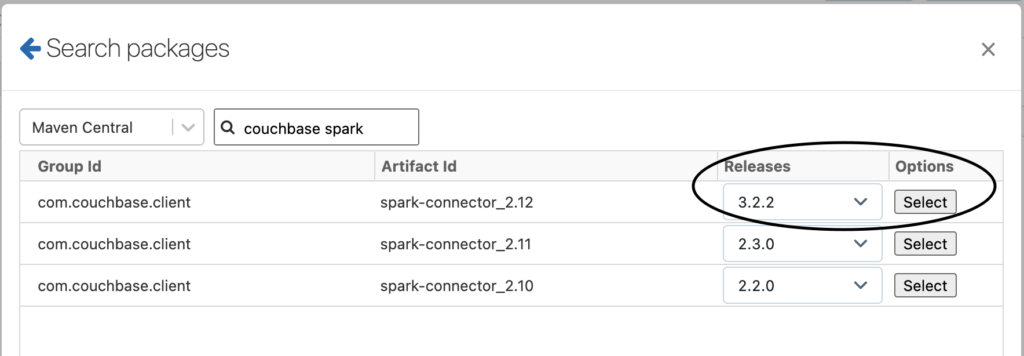
-
- 그리고 설치 라이브러리 설정은 아래 예시와 같이 구성됩니다:
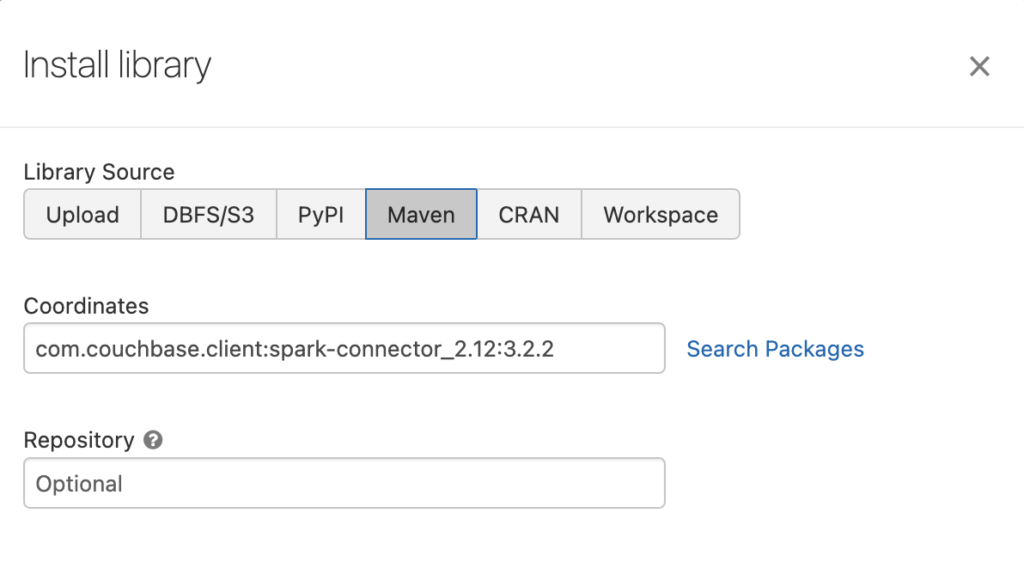
구성
시작하기 전에 Databricks 클러스터에서 다음 매개 변수를 구성해야 합니다. 고급 옵션 스파크 구성. 다음과 같이 할 수 있습니다. 클러스터를 생성할 때 (아래 화면 인쇄물 참조):
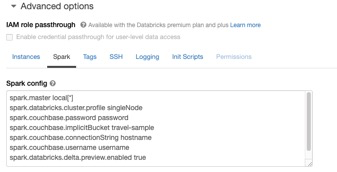
아래 설정을 복사하여 붙여넣고 다음에서 매개변수를 바꿀 수 있습니다. <> 의 Couchbase 클러스터 값과 함께 고급 옵션 Spark 구성:
|
1 2 3 4 5 |
스파크.카우치베이스.비밀번호 <비밀번호> 스파크.카우치베이스.묵시적 버킷 <여행-샘플> 스파크.카우치베이스.연결 문자열 <호스트 이름> 스파크.카우치베이스.사용자 이름 <사용자 이름> 스파크.데이터브릭.델타.미리 보기.활성화 true |
먼저 필요한 가져오기를 실행해 보겠습니다. 위의 구성으로 클러스터에 연결된 빈 노트북에 아래 샘플 코드를 복사합니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
가져오기 com.카우치베이스.스파크._ 가져오기 org.아파치.스파크.sql._ 가져오기 com.카우치베이스.클라이언트.scala.json.JsonObject 가져오기 com.카우치베이스.스파크.kv.Get 가져오기 com.카우치베이스.클라이언트.scala.kv.MutateInSpec 가져오기 com.카우치베이스.스파크.kv.MutateIn 가져오기 com.카우치베이스.클라이언트.scala.kv.룩업인스펙 가져오기 com.카우치베이스.스파크.kv.룩업인 가져오기 com.카우치베이스.클라이언트.scala.쿼리.쿼리 옵션 가져오기 com.카우치베이스.스파크.쿼리.쿼리 옵션 가져오기 com.카우치베이스.클라이언트.scala.분석.애널리틱스 옵션 |
이제 Couchbase에서 키별로 몇 가지 문서를 가져와 보겠습니다. 여행 샘플 데이터베이스를 생성합니다:
|
1 2 3 4 |
sc .couchbaseGet(Seq(Get("airline_10"), Get("airline_10642"))) .수집() .foreach(결과 => println(결과.contentAs[JsonObject])) |
좋아요, 클러스터에 연결하여 첫 번째 RDD(복원력 있는 분산 데이터 세트)를 반환했습니다.
SQL++(SQL 기반의 카우치베이스 쿼리 언어)를 사용하여 데이터를 쿼리할 수 있습니다. 아래 코드를 예시로 실행해 보세요:
|
1 2 3 4 |
sc .카우치베이스 쿼리[JsonObject]("select country, count(*) as count as count from `travel-sample` where type = 'airport' group by country order by count desc") .수집() .foreach(println) |
애널리틱스 서비스 쿼리
다음은 운영 분석 및 실시간 분석을 위한 애널리틱스 서비스의 예시이며, 아래는 애널리틱스 쿼리의 예시입니다:
|
1 2 |
val 쿼리 = "SELECT ht.city,ht.state,COUNT(*) AS num_hotels FROM `travel-sample`.inventory.hotel ht GROUP BY ht.city,ht.state HAVING COUNT(*) > 30" sc.카우치베이스 분석 쿼리[JsonObject](쿼리).수집().foreach(println) |
이제 Spark SQL에 대해 알아보겠습니다.
아래 코드를 사용하여 다음에 대한 임시 보기를 만들 수 있습니다. 항공사 그리고 공항 데이터프레임:
|
1 2 3 4 5 6 7 8 9 |
val 항공사 = 스파크.읽기.형식("couchbase.query") .옵션(쿼리 옵션.필터, "유형 = '항공사'") .load() 항공사.createOrReplaceTempView("항공사") val 공항 = 스파크.읽기.형식("couchbase.query") .옵션(쿼리 옵션.필터, "유형 = '공항'") .load() 공항.createOrReplaceTempView("공항") |
이제 예를 들어 뷰에서 Spark SQL 쿼리를 실행할 수 있습니다:
항공사를 오름차순으로 가져옵니다:
|
1 |
%sql 선택 * 에서 항공사 주문 by 이름 asc limit 10 |
국가별로 항공사를 그룹화하세요:
|
1 |
%sql 선택 국가, 카운트(*) 에서 항공사 그룹 by 국가; |
마지막으로 다음을 사용하여 국가별 공항을 시각화해 보겠습니다. UDF (사용자 정의 함수)와 데이터브릭스 매핑 기능을 함께 사용할 수 있습니다. 아래 SQL++를 사용하여 UDF를 생성합니다:
|
1 2 3 4 5 6 7 8 |
val 국가 지도 = (s: 문자열) => { s 일치 { case "프랑스" => "FRA" case "미국" => "USA" case "영국" => "GBR" } } 스파크.udf.등록("countrymap", 국가 지도) |
국가별 공항 수를 선택하고 결과를 시각화합니다:
|
1 |
%sql 선택 국가 지도(국가), 카운트(*) 에서 공항 그룹 by 국가; |
이 빠른 시작을 완료하면 아래의 시각화와 비슷한 결과가 나타납니다:
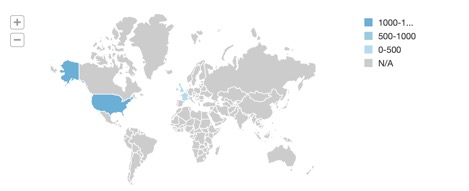
우리가 성취한 것
이 빠른 시작에서는 Databricks와 함께 Couchbase 스파크 커넥터를 활용하여 RDD를 만들고, Couchbase 및 Spark SQL 쿼리를 실행하고, UDF를 만들고, Databricks 매핑 기능을 활용하여 결과를 시각화하는 방법을 간략하게 설명해 드렸습니다. 이 단계에서는 Databricks 노트북 인터페이스에서 Couchbase 클러스터의 데이터에 액세스하고, 분석하고, 시각화하는 데 사용되는 프로세스를 보여드립니다.
다음 단계
자세히 알아보기 카우치베이스 카펠라:
-
- 카펠라에 가입하여 체험해 보세요. 30일 무료 체험.
- 평가판 클러스터를 Playground에 연결 를 클릭하거나 프로젝트를 연결하여 직접 테스트해 보세요.
- 보기 카우치베이스 개발자 포털 어느 정도의 튜토리얼/퀵스타트 가이드 시작하는 데 도움이 되는 학습 경로를 확인하세요!
- 문서 보기 를 클릭해 Couchbase SDK에 대해 자세히 알아보세요.
이 게시물을 읽어주셔서 감사합니다! 질문이나 의견이 있으시면 다음 링크를 통해 문의해 주세요. 카우치베이스 포럼!