인덱싱 서비스를 최대한 활용하는 방법에 대한 훌륭한 블로그가 있습니다: "올바른 인덱스를 만들고, 올바른 성과를 얻으십시오."블로그와 그 조언은 모두 시간의 시험을 견뎌냈습니다. 그렇다면 그 이름을 딴 검색어 관련 블로그를 만들어 보는 건 어떨까요?
올바른 성능을 얻으려면 올바른 쿼리를 작성해야 한다는 점은 쿼리 서비스에서도 마찬가지라고 생각합니다. 인덱스 서비스는 쿼리 성능의 단일 기여자라는 이유로 많은 비난을 받을 수 있습니다. 하지만 사용 중인 쿼리와 인덱스를 모두 변경해야 할 때가 있습니다.
여기서는 Couchbase가 자랑하는 엔터프라이즈급 성능을 얻기 위해 쿼리 조정이 필요한 경우를 예로 보여드리겠습니다. 다음 예는 고객 중 한 분이 보내주신 질문을 기반으로 한 것이므로, Couchbase를 '분노'로 사용하는 많은 분들에게 도움이 되길 바랍니다.
사용자 환경
독자가 원한다면 따라 할 수 있는 블로그를 좋아하기 때문에 쉽게 따라 할 수 있도록 예를 들어 보겠습니다. 이 예시에서 기본 규칙을 설정하기 위해 사용할 수 있는 몇 가지 구성 요소는 다음과 같습니다:
- 언제나 유용한 https://cloud.couchbase.com/sign-up 개발 환경. 발리의 해변에서 해먹에 누워 계신가요? 여러분만의 카우치베이스 도커 컨테이너를 가동하면 선풍기가 불을 뿜고 모히토에 모래가 바로 들어올 것입니다. 인터넷만 연결되어 있다면 30분 동안 무료로 개발 환경을 제공해 드릴 수 있습니다! 물론 이미 사용 중인 Couchbase 환경을 자유롭게 사용할 수 있습니다.
- 여행 샘플 데이터 세트
- 편리한 N1QL 배열 문서
- 배열 작업에 대한 편리한 포켓 레퍼런스 블로그
참고: 여기서는 범위/수집 기능을 사용하므로 버킷 컨텍스트가 여행 샘플 데이터 세트의 기본 범위로 설정되어 있습니다.
실제 상황
이 예제의 배경을 설정하기 위해 일반적인 사용 사례인 마케팅 캠페인 생성을 사용할 수 있습니다. 이 쿼리의 한 가지 예는 리뷰를 남기고 '좋아요'를 누른 호텔 방문자를 찾는 것입니다. 이 데이터는 로열티 프로그램에 대한 보상, 더 나은 타겟팅/유사한 호텔 숙박 또는 리뷰/좋아요를 남길 가능성이 높은 사용자에 대한 인사이트 제공으로 이어질 수 있습니다. 이러한 모든 인사이트는 호텔 고객에게 더 나은 서비스를 제공하기 위한 귀중한 데이터를 제공합니다.
이 특정 예제의 주된 목적은 단일 JSON 문서 내에서 여러 배열을 쿼리할 수 있는 가능성을 보여주고, 올바른 인덱스를 생성한 후 쿼리 서비스에서 훨씬 더 많은 성능을 끌어낼 수 있는 씨앗을 심는 것입니다. 결국, 동적 데이터 필드를 허용하는 시스템을 활용하고 있으며 배열은 데이터 형식으로 JSON을 사용하는 유연성의 큰 부분을 차지합니다.
겸손한 시작
링크된 블로그에 설명된 대로 n1ql에서 배열을 쿼리하는 일반적인 방법은 다음과 같습니다:
|
1 |
선택 (ANY v IN [1, 2, 3, 4, 5] 만족 v > 4 END) as is_found, (ANY v IN [1, 2, 3, 4, 5] 만족 v = 7 END) as not_found; |
이 예제에서는 다음과 같이 말합니다: "배열에서 SATISFIES 문에 있는 조건과 일치하는 항목을 가져와"라고 말합니다.
이 메서드를 JSON 문서에서 여러 배열을 쿼리하는 시도에 적용하면 다음과 같이 보일 수 있습니다:
|
1 2 3 |
선택 공개_좋아요, 리뷰 FROM _기본값 어디 유형="호텔" AND ANY r IN 리뷰 만족 r.작성자 = "오젤라 시프" END AND ANY l IN 공개_좋아요 만족 l = "오젤라 시프" END LIMIT 1; |
그러나 N1QL은 현재 문서의 배열에서 인덱싱 가능한 단일 배열을 구성해야 하므로 이렇게 하면 성능이 좋은 쿼리로 이어지지 않습니다, 여기에 언급된 바와 같이.
여러 배열 필드에 대한 인덱스 만들기
그렇다면 이러한 인덱스는 어떻게 구성할 수 있을까요? 호텔에 좋아요를 누르고 리뷰를 남긴 게스트의 데이터를 수집하는 사용 사례를 예로 들어 살펴보겠습니다.
|
1 2 3 4 5 |
만들기 INDEX `리뷰어_좋아요_IDX` 켜기 `_기본값`( DISTINCT 배열 ( DISTINCT 배열 [l,r.작성자] FOR r IN 리뷰 END) FOR l in 공개_좋아요 END) 어디 유형="호텔"; |
여기서 하는 일은 좋아요와 리뷰가 결합된 단일 배열로 인덱스를 만드는 것입니다. 이는 모범 사례이며, 설명서의 참고 사항을 지원합니다. 여러분이 옳다고 생각할 수 있는 방법을 보여드리기 위해 지원되지 않으며 여러 배열 필드를 색인화하지 않는 방법을 소개합니다:
|
1 |
만들기 INDEX `NOT_THE_RIGHT_IDX` 켜기 `_기본값`( DISTINCT (배열 r.필드 FOR r in json_obj END), 좋아요); |
이렇게 하면 여러 배열 필드를 인덱싱하게 되므로 권장하지 않습니다.
쿼리 개선
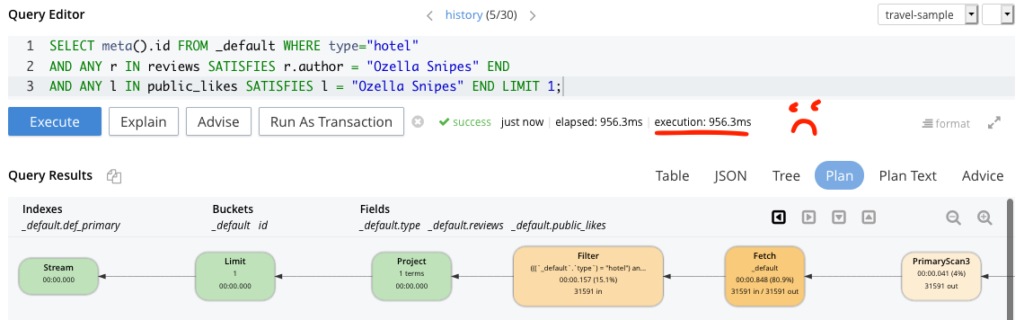
다음은 쿼리 워크벤치에서 실행한 두 가지 쿼리의 예입니다. 개선된 쿼리를 사용하여 실행 시간을 956.3ms에서 ~4ms로 줄였습니다. 이 블로그의 마지막에 개선된 쿼리가 있으니 직접 사용해 보세요.
비성능 쿼리
향상된 성능 쿼리

본질적으로는 두 쿼리 모두 작동하지만 두 쿼리를 실행하는 데 걸리는 시간이 크게 다른데, 이는 후자의 쿼리에서 세심하게 만들어진 모범 사례 인덱스를 사용하고 있기 때문입니다. 여기까지 잘 따라가셨다면 직접 실행해 보셔도 됩니다. 호텔 문서 중 하나에서 'Ozella Sipes'를 리뷰 작성자와 공개 좋아요 사용자로 추가하여 쿼리 작동을 테스트해 보았습니다. 사용하는 이름에 따라 결과가 달라질 수 있습니다.
|
1 2 3 4 5 |
선택 메타().id FROM _기본값 어디 유형="호텔" AND ANY l IN 공개_좋아요 만족 ( ANY r IN 리뷰 만족 [l,r.작성자] = ["오젤라 시프", "오젤라 시프"] END) END LIMIT 1; |
이 블로그가 도움이 되었기를 바라며, 경우에 따라 올바른 성능을 얻기 위해 올바른 쿼리를 사용하는 것도 고려해야 한다는 인사이트를 얻으셨기를 바랍니다!