저희는 다음과 같이 발표하게 되어 매우 기쁩니다. Couchbase 7.6 출시데이터베이스 기술의 지형을 재정의할 획기적인 업데이트입니다. 이 최신 릴리스는 데이터베이스 기술 향상을 위한 Atlassian의 노력을 입증하는 것으로, 다음과 같은 AI 및 머신 러닝 통합이 크게 향상되었습니다. 벡터 검색LangChain 통합을 통해 개발자가 더욱 지능적이고 반응성이 뛰어난 애플리케이션을 구축할 수 있도록 지원합니다.
이 버전의 핵심은 고급 그래프 탐색 기능을 도입하여 복잡한 데이터 관계와 네트워크 분석을 위한 새로운 길을 열었다는 점입니다. 개발자의 효율성이 향상되고, RDBMS 사용 사례와 NoSQL의 민첩성 및 확장성이 원활하게 통합됩니다.
이러한 혁신과 함께, 쿼리 및 검색 성능에 대한 향상된 모니터링을 통해 사용자 환경을 개선하고 실시간 데이터 작업의 효율성과 응답성을 최적으로 보장하는 데 중점을 두었습니다. 또한, 이번 릴리스에서는 더욱 강화된 BI 시각화 도구로 BI 기능을 확장하여 더욱 심층적인 데이터 인사이트와 강력한 분석을 가능하게 합니다.
Couchbase 7.6은 단순한 업데이트가 아니라 데이터베이스 기술의 미래를 주도하는 데 필요한 도구와 기능을 제공하는 혁신의 결과물입니다. 다음은 그 중 일부입니다.
AI 통합
벡터 검색
최신 애플리케이션의 진화하는 기술 수요에 맞춰 검색 기능을 대폭 강화한 7.6 릴리스에서 새로운 벡터 검색 기능을 소개합니다. 데이터 복잡성이 증가함에 따라 고급 검색 메커니즘의 필요성이 중요해지고 있습니다. Vector Search는 개발자가 시맨틱 검색을 구현하고, 머신 러닝 모델을 강화하며, Couchbase 환경 내에서 직접 AI 애플리케이션을 지원할 수 있는 솔루션을 제공합니다.
벡터 검색을 사용하면 키워드 일치나 용어 빈도 검색을 뛰어넘는 검색이 가능합니다. 쿼리에서 사용된 문맥인 의미론적 의미를 기반으로 검색할 수 있습니다. 사실상 쿼리의 의도를 파악하여 콘텐츠에 정확한 키워드나 용어가 없는 경우에도 보다 관련성 높은 결과를 제공합니다.
자세한 내용은 카우치베이스 문서.
SQL++를 사용한 벡터 검색
사용자 프로필, 과거 상호작용 데이터, 콘텐츠 메타데이터 등 모든 콘텐츠를 저장하는 데 Couchbase의 NoSQL 데이터베이스 기능을 사용할 수 있습니다. 그런 다음 OpenAI와 같은 머신러닝 모델을 사용하여 임베딩을 생성합니다. 그런 다음 카우치베이스 벡터 검색은 임베딩을 색인하고 시맨틱 및 하이브리드 검색을 제공할 수 있습니다.
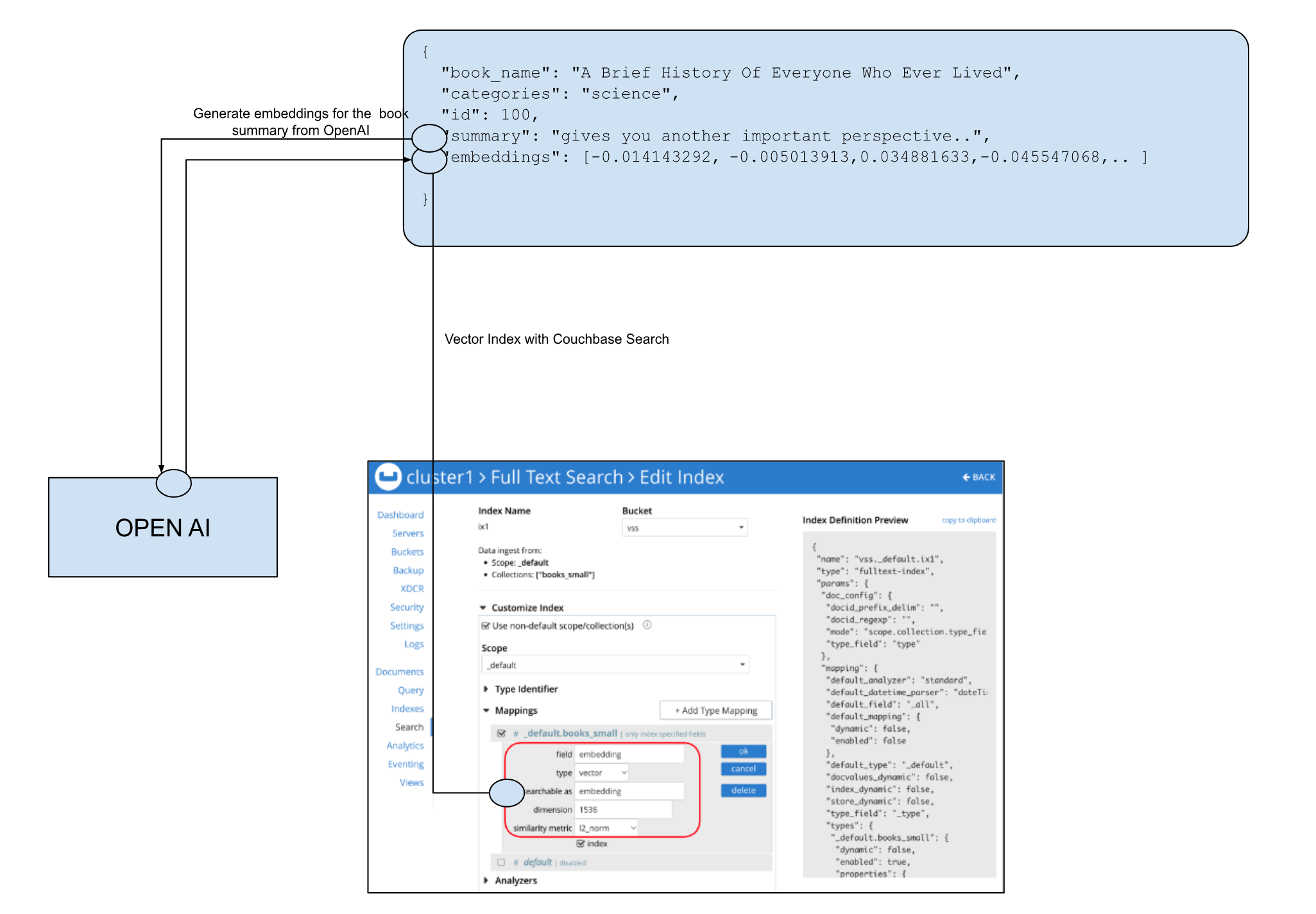
또한 SQL++를 사용하여 벡터 검색을 직접 수행하고, 검색 술어와 Couchbase SQL++의 유연성을 결합하여 하이브리드 검색을 수행할 수도 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT b.book_name, b.categories, b.summaries FROM `books` AS b WHERE SEARCH(b, { /* calling Couchbase SEARCH() */ "query": {"match_none": {} }, "knn": [{ "field": "embedding", "vector": [ -0.014143292,-0.005013913,..], "k": 3 }], "fields": ["book_name", "summaries"], "sort": ["-_score"], "limit": 5 }) AND b.catogories='Non fiction'; |
위 쿼리에 대한 임베딩을 가져오는 방법에 대한 섹션을 추가하지 않는 이유는 무엇인가요? 그 이유는 UDF에서 이를 수행하려면 UDF/JS가 CURL을 지원해야 하는데, 이는 Capella에서 지원되지 않기 때문입니다. 사용자는 애플리케이션 계층에서 임베딩을 가져올 수 있습니다.
재귀적 CTE
그래프 탐색
Couchbase SQL++ 기능에 재귀적 CTE가 도입되어 이제 특히 그래프 데이터 영역에서 복잡한 데이터 분석과 조작을 수행할 수 있습니다. 계층적 및 네트워크 데이터 구조를 손쉽게 탐색하고 분석하여 전례 없이 쉽고 효율적으로 인사이트를 얻을 수 있습니다. 소셜 네트워크, 조직 계층 구조 또는 상호 연결된 시스템을 탐색하든, 새로운 기능은 이러한 작업을 단순화하여 그 어느 때보다 직관적이고 생산적으로 데이터를 분석할 수 있게 해줍니다.
다음은 이 샘플 데이터 집합에서 두 정거장 미만인 LAX에서 MAD까지의 모든 항공편을 찾기 위한 Couchbase SQL++ 재귀적 CTE 쿼리의 예입니다. 이 샘플 데이터는 여행 샘플이 아니라 2008년 AA 노선의 단순화된 버전에 기반한 것입니다.
| 소스_공항_코드 | 목적지_공항_코드 | 항공사 |
| LAX | MAD | AA |
| LAX | LHR | AA |
| LHR | MAD | AA |
| LAX | OPO | AA |
| OPO | MAD | AA |
| MAD | OPO | AA |
| SQL++ 쿼리 | 결과 |
| /* 경유지가 2개 미만인 LAX에서 MAD까지의 모든 노선 나열 */. WITH RECURRIVE RouteCTE AS ( 선택 [r.source_airport_code, r.destination_airport_code] AS 경로, r.destination_airport_code AS lastStop, 1 AS 깊이 FROM 경로 R 어디 r.source_airport_code = 'LAX' UNION ALL 선택 ARRAY_APPEND(r.route,f.destination_airport_code) AS 경로, F.목적지_공항_코드 AS lastStop, r.depth + 1 AS 깊이 FROM RouteCTE r JOIN 경로 F 켜기 r.lastStop = f.source_airport_code 어디 f.destination_airport_code != 'LAX' AND r.depth < 3 )옵션 {"levels":3} 선택 r.* FROM RouteCTE AS r 어디 r.lastStop = 'MAD' AND r.depth < 3; |
[ { "경로": [ "LAX", "MAD" ] }, { "경로": [ "LAX", "LHR", "MAD" ] }, { "경로": [ "LAX", "OPO", "MAD" ] } ] |
계층적 데이터 구조
재귀적 CTE를 사용하여 조직 계층 구조와 같은 계층적 데이터 구조를 탐색할 수도 있습니다.
| SQL++ 쿼리 | 결과 |
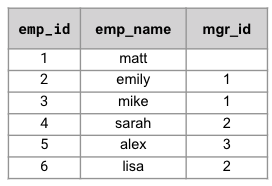
| /* 모든 직원과 해당 직원의 조직 계층 구조 나열 */ WITH RECURRIVE orgHier as ( 선택 [e.emp_name] 여기를 클릭하세요, e.emp_id, 0 lvl FROM 직원 e 어디 e.manager_id 는 null UNION 선택 ARRAY_APPEND(o.hier, e1.emp_name) hier, E1.EMP_ID, O.LVL+1 lvl FROM 직원 E1 JOIN orgHier o 켜기 e1.manager_id=o.emp_id ) 선택 o.* FROM orgHier o; |
[ { "emp_id": 1, "여기": [ "매트" ], "lvl": 0 }, { "emp_id": 2, "여기": [ "매트", "에밀리" ], "lvl": 1 }, { "emp_id": 3, "여기": [ "매트", "마이크" ], "lvl": 1 }, { "emp_id": 5, "여기": [ "매트", "마이크", "알렉스" ], "lvl": 2 }, { "emp_id": 4, "여기": [ "매트", "에밀리", "사라" ], "lvl": 2 }, { "emp_id": 6, "여기": [ "매트", "에밀리", "리사" ], "lvl": 2 } ] |
자세한 내용은 다음 카우치베이스 문서를 참조하세요. 재귀 쿼리.
개발자 효율성
KV 범위 스캔
Couchbase의 키/값(K/V) 작업은 데이터베이스에 저장된 데이터에 액세스하는 가장 효율적인 방법입니다. 이러한 작업은 문서의 고유 키를 사용하여 읽기, 쓰기 및 업데이트 작업을 수행합니다. 하지만 이러한 작업은 개별 문서 단위로 작동합니다. 대규모 데이터 검색 사용 사례의 경우, 애플리케이션에 쿼리 서비스의 SQL++를 사용하는 것이 좋습니다.
그러나 쿼리 및 색인 노드를 설정하는 것이 경제적으로 타당하지 않은 경우, 이제 KV 범위 스캔을 사용할 수 있는 옵션이 있습니다. 이 새로운 기능을 사용하면 애플리케이션에서 키 범위, 키 접두사 또는 무작위 샘플링을 기반으로 모든 문서를 반복할 수 있습니다. API는 내부적으로 여러 v버킷으로 요청을 전송합니다. 최대_통화 설정을 사용하여 데이터 노드 전반의 로드 밸런스를 조정합니다. 그런 다음 vbucket 스트림이 논리적으로 병합되어 하나로 반환됩니다. 스트림 를 애플리케이션에 추가합니다.
| KV 가져오기 | KV 범위 스캔 |
| public 클래스 CouchbaseReadHotelExample { public 정적 void 메인(String[] args) { // 클러스터에 연결 클러스터 클러스터 = 클러스터.연결("couchbase://localhost", "username", "비밀번호"); // 'travel-sample' 버킷에 대한 참조 가져오기 버킷 버킷 = cluster.bucket("travel-sample"); // '인벤토리' 범위 및 '호텔' 컬렉션에 액세스합니다. 범위 인벤토리 범위 = 버킷.범위("인벤토리"); 호텔 컬렉션 = 인벤토리 범위 컬렉션("호텔"); 문자열 문서 키 = "hotel_12345"; GetResult = hotelCollection.get(documentKey); |
public static void main(String... args) { 클러스터 클러스터 = 클러스터.연결("couchbase://localhost", "username", "비밀번호"); 버킷 버킷 = cluster.bucket("travel-sample"); 범위 범위 = bucket.scope("_default"); 컬렉션 컬렉션 = scope.collection("_default"); System.out.println("\n예시: [범위-스캔 범위]"); // tag::rangeScanAllDocuments[] |
자세한 내용은 카우치베이스 KV 운영 문서.
쿼리 순차 스캔
KV 범위 스캔 기능을 기반으로 하는 쿼리 순차 스캔은 이제 인덱스 없이도 SQL++를 사용해 모든 데이터베이스 CRUD 작업을 수행할 수 있게 해줍니다. 이 기능을 통해 개발자는 작업에 필요한 인덱스를 고려할 필요 없이 소규모 데이터세트로 데이터베이스 작업을 시작할 수 있습니다.
쿼리 관점에서 쿼리 계획은 쿼리에 사용 가능한 인덱스를 선택합니다. 그러나 아무것도 발견되지 않으면 순차 스캔으로 돌아갑니다. 쿼리 계획에도 인덱스 스캔 대신 순차 스캔이 사용됨을 표시합니다.
| // 항공사별 SFO->LHR 출발 항공편 수 선택 a.name, array_count(r.schedule) 항공편 FROM 경로 R INNER JOIN 항공사 A 켜기 r.airline = a.IATA 어디 r.sourceairport='SFO' AND r.destinationairport='LHR'; |
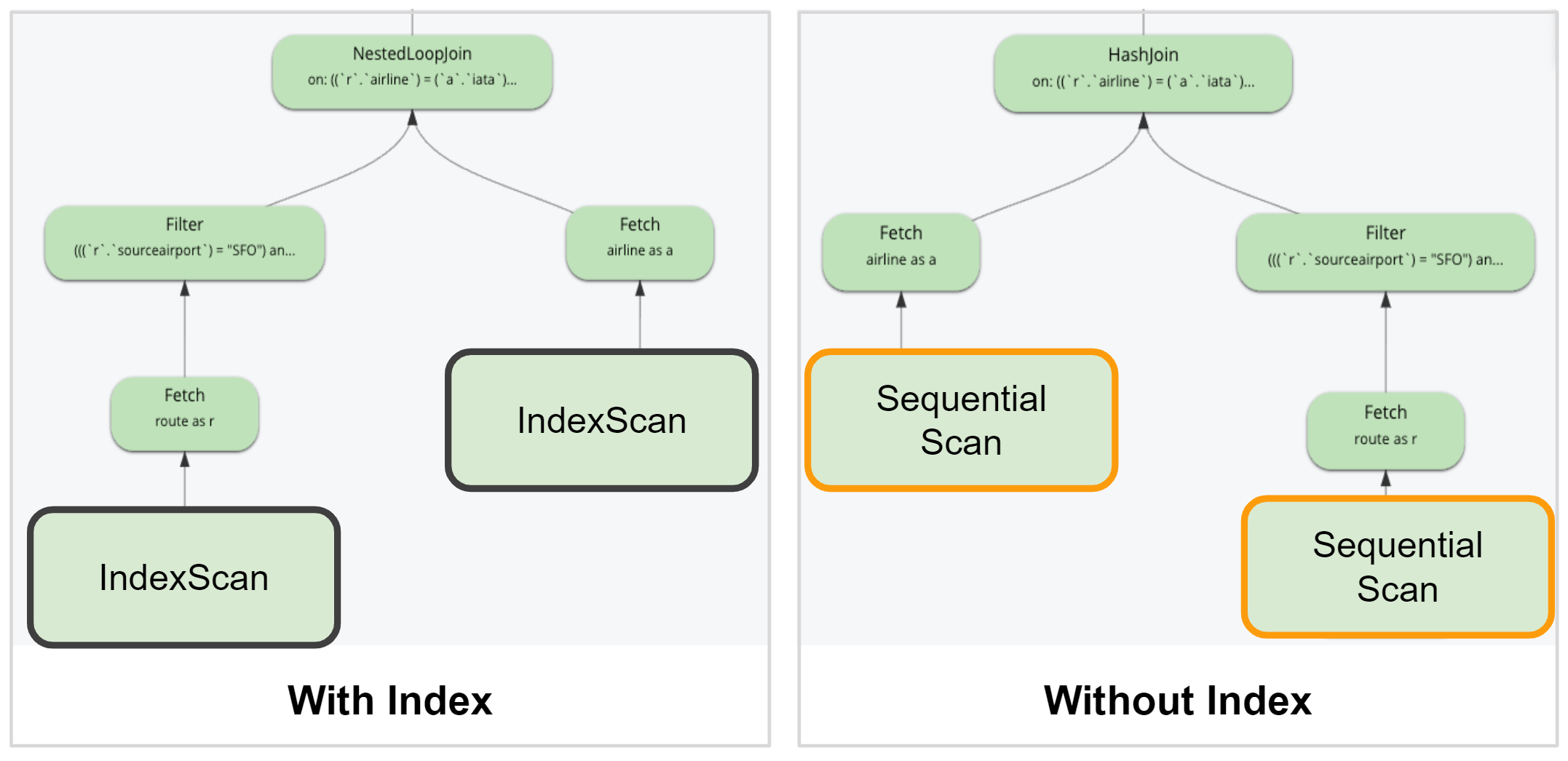
순차 스캔은 소규모 개발 데이터 세트에 적합하다는 점에 유의하세요. 쿼리 성능이 우선시되는 경우에는 여전히 인덱스를 사용해야 합니다.
자세한 내용은 다음 카우치베이스 문서를 참조하세요. 순차 스캔.
복제본에서 읽기 쿼리
복제본에서 읽기는 모든 Couchbase 서비스에서 사용할 수 있는 고가용성 기능의 일부입니다. KV 작업에 SDK를 사용하는 경우, 복제본 읽기를 사용하면 장애 조치 중과 같이 활성 복사본을 사용할 수 없는 경우 애플리케이션이 복제본 vbucket이 있는 데이터 노드에서 읽을 수 있습니다.
| 시도 { // 활성 노드에서 읽기를 시도합니다. GetResult 결과 = collection.get(documentKey); System.out.println("활성 노드의 문서: " + result.contentAsObject()); } catch (DocumentNotFoundException activeNodeException) { System.out.println("활성 노드 읽기에 실패했습니다, 복제본 읽기 시도 중..."); // 활성 노드 읽기가 실패하면 사용 가능한 복제본에서 읽기를 시도합니다. 시도 { GetReplicaResult replicaResult = collection.getAnyReplica(documentKey); System.out.println("복제본의 문서: " + replicaResult.contentAsObject()); } catch (예외 replicaReadException) { System.err.println("복제본에서 문서를 가져오는 중 오류가 발생했습니다: " + replicaReadException.getMessage()); } |
그러나 애플리케이션이 SDK를 사용하여 SQL++ 쿼리를 실행하는 경우에는 이 접근 방식을 적용할 수 없습니다. 데이터 가져오기 작업이 쿼리 서비스 계층에서 발생하기 때문입니다. 아래 예제에서 복제본에서 쿼리 읽기가 없는 경우 쿼리가 가져오는 활성 데이터 노드에 문제가 있는 경우 쿼리는 애플리케이션에 시간 초과 오류를 반환합니다. 아래 애플리케이션에서 재시도를 수행하면 전체 쿼리를 처음부터 다시 실행해야 합니다.
| 시도 { // N1QL 쿼리 실행하기 문자열 문 = "SELECT * FROM QueryResult 결과 = cluster.query(statement); // 결과 집합의 행을 반복합니다. 에 대한 (QueryRow row : result.rows()) { System.out.println(행); } } catch (QueryException e) { System.err.println("쿼리가 실패했습니다: " + e.getMessage()); } |
이제 Couchbase 7.6은 복제본에서 쿼리 읽기를 지원합니다. 즉, 쿼리 서비스가 다른 데이터 노드로 연결을 전환할 수 있습니다. kv타임아웃 를 가져오던 데이터 노드로부터 가져옵니다. 다른 데이터 노드로 전환하는 로직은 쿼리 서비스 내에서 투명하게 수행되며, 애플리케이션에서 아무런 조치를 취할 필요가 없습니다.
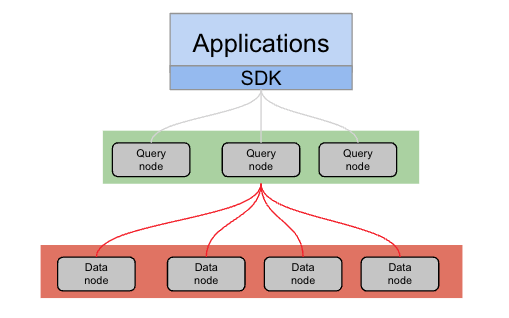
복제본에서 쿼리 읽기 기능을 사용할 때, 애플리케이션은 특히 쓰기 작업이 많은 환경에서 데이터 불일치 가능성을 염두에 두어야 합니다. 데이터 노드 간에 데이터가 지속적으로 복제된다는 것은 쿼리 서비스가 가져오기 작업 중에 노드 간에 전환될 때 불일치가 발생할 수 있음을 의미합니다. 이 시나리오는 데이터 업데이트가 자주 발생하는 시스템에서 더 자주 발생하며, 복제 프로세스로 인해 노드 간 동기화가 약간 지연될 수 있습니다.
이러한 이유로 애플리케이션에는 복제본에서 쿼리 읽기를 제어할 수 있는 옵션이 있습니다. 이 옵션은 요청, 노드 또는 클러스터 수준 설정에서 활성화/비활성화할 수 있습니다.
자세한 내용은 카우치베이스 쿼리 설정 문서.
SQL++ 시퀀스
이제 SQL++를 사용하여 Couchbase 서버 내에서 유지 관리되는 시퀀스 객체를 만들 수 있습니다. 시퀀스 객체는 데이터베이스 내에서 고유성을 보장하는 숫자 값의 시퀀스를 생성합니다. 애플리케이션은 Couchbase SQL++ 시퀀스를 사용하여 단일 카운터가 여러 클라이언트에 서비스를 제공할 수 있도록 보장할 수 있습니다.
| // SEQUENCE 구문 만들기
만들기 시퀀스 [IF NOT 존재] [IF NOT 존재] [ WITH ] |
자세한 내용은 카우치베이스 시퀀스 문서.
읽어주셔서 감사드리며, 새로운 기능들을 즐겨보시기 바랍니다. 7.6 관련 포스팅은 곧 추가될 예정입니다.