카우치베이스는 미션 크리티컬 배포의 고가용성을 더욱 개선하고 운영자의 개입을 줄입니다. 카우치베이스는 일반적인 디스크 장애 감지를 강화하고 불량 디스크가 있는 노드를 자동으로 페일오버하여 운영자의 시간과 에너지를 절약합니다. 또한 데이터 손실을 방지하기 위해 복제본 수에 따라 여러 서버 장애를 처리하고, 랙이나 영역을 사용할 수 없는 경우 전체 서버 그룹을 페일오버할 수 있습니다.
이제 사용자는 다음에서 디스크, 다중 노드 및 전체 서버 그룹(랙 영역)에 대한 자동 페일오버를 구성할 수 있습니다. 카우치베이스 서버 5.5.
이러한 개선 사항을 자세히 살펴보겠습니다.
디스크 문제 발생 시 자동 페일오버
Couchbase Server 5.5 이전 버전에서는 노드에서 디스크 관련 문제가 발생하면 클러스터 관리자가 자동으로 장애 조치하지 않았습니다. 노드는 메모리가 부족하거나 다른 문제가 발생할 때까지 잠시 동안 계속 작동합니다.
그러나 클러스터 관리자에는 "디스크에 데이터를 보존하는 동안 디스크 장애가 감지된 경우" 및 "영구 저장소에 사용되는 디스크 공간이 최소 90%의 용량에 도달했습니다."

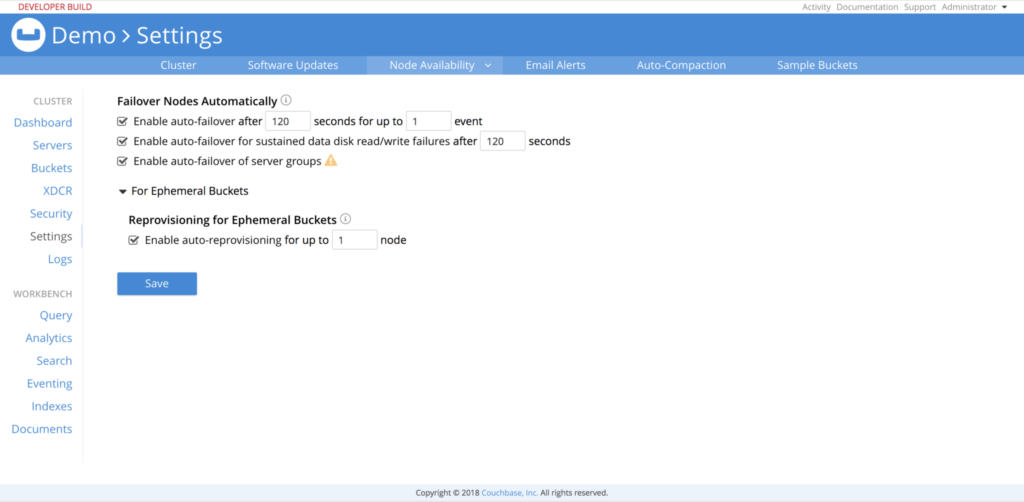
Couchbase Server 5.5에서 사용자는 Couchbase 웹 콘솔의 노드 가용성 설정에서 또는 CLI/REST API를 통해 다음 설정을 구성할 수 있습니다.
-
- 지속적인 데이터 디스크 읽기/쓰기 장애에 대한 자동 페일오버 활성화
- 이 기능을 사용하려면 노드 자동 장애 조치를 사용 설정하세요.
- 기본적으로 꺼져 있습니다.
- 기간(초)
- 최소는 5초, 최대는 3600초로 설정할 수 있으며 기본값은 120초입니다.
- 지속적인 데이터 디스크 읽기/쓰기 장애에 대한 자동 페일오버 활성화
어떻게 작동하나요?
카우치베이스 클러스터 관리자는 다음 두 가지 통계를 계속 모니터링합니다.
- 디스크에 항목 쓰기를 시도하는 동안 실패한 횟수입니다.
- 디스크에서 읽기를 시도하는 동안 실패한 횟수입니다.
자동 장애 조치 시간 초과 기간 동안 이 통계가 계속 증가하고 '디스크 문제 시 자동 장애 조치'가 켜져 있으면 클러스터 관리자가 노드를 자동으로 장애 조치합니다.
위의 통계는 통계 페이지에서 다음과 같이 확인할 수 있습니다.
- # 디스크 읽기 실패
- # 디스크 쓰기 실패
참고 - 한 통계는 증가하고 다른 통계는 증가하지 않을 수 있습니다. 예를 들어 디스크가 가득 차면 쓰기가 실패하여 '쓰기 실패'가 증가하지만 읽기는 계속 진행될 수 있습니다.
둘 이상의 노드 자동 페일오버
Couchbase Server 5.5 이전 버전에서는 자동 장애 조치 횟수 또는 할당량이 1로 설정되어 있어 사용자 개입이 필요하기 전에 하나의 노드만 자동으로 장애 조치할 수 있었습니다. 이는 클러스터의 여러 노드 또는 모든 노드의 연쇄 반응 장애를 방지하기 위한 제약이었습니다.
그러나 클러스터 관리자는 첫 번째 노드에서 "노드가 자동 장애 조치되었습니다"라는 기본 제공 알림과 "최대 자동 장애 조치 노드 수에 도달했습니다.".

카우치베이스 서버 5.5에서 사용자는 클러스터의 모든 버킷이 1개 이상의 복제본으로 구성된 경우 여러 인스턴스의 장애 조치를 구성할 수 있으며, 이 경우 최대 3개의 인스턴스가 자동으로 장애 조치될 수 있습니다. 없이 필요 자동 장애 조치 할당량 재설정과 같은 수동 개입이 필요합니다.
이제 사용자는 다음을 구성할 수 있습니다. Couchbase 웹 콘솔의 노드 가용성 설정 또는 CLI/REST API를 통해 다음과 같이 설정할 수 있습니다.
-
- 기본 1개 이벤트 및 최대 3개 이벤트에 대해 자동 장애 조치 활성화
- 이렇게 하면 기능이 활성화되며 자동 장애 조치가 활성화된 경우에만 이 기능을 켤 수 있습니다.
- 기본적으로 꺼져 있습니다.
- 기간(초)
- 최소 5초, 최대 3600초로 설정할 수 있으며 기본값은 120초입니다.
- 사용자가 언제든지 편집 가능
- 기본 1개 이벤트 및 최대 3개 이벤트에 대해 자동 장애 조치 활성화
어떻게 작동하나요?
클러스터 관리자는 클러스터의 모든 버킷에 대해 구성된 복제본의 수를 확인합니다. 구성된 복제본이 서로 다른 버킷의 경우 클러스터 관리자는 모든 버킷에 구성된 최대 복제본만 고려합니다.
예를 들어 - 클러스터에 다음이 있는 경우
-
- 1개의 복제본이 있는 버킷과 2개의 복제본이 있는 버킷을 설정한 다음 최대 1개의 노드만 자동 페일오버를 허용합니다.
- 2개의 복제본이 있는 2개의 버킷을 설정한 다음 최대 2개의 노드에 대한 자동 페일오버를 허용합니다.
- 2개의 복제본, 2개의 복제본, 3개의 복제본으로 구성된 3개의 버킷을 설정한 다음 최대 2개의 노드에 대한 자동 페일오버를 허용합니다.
최대 자동 장애 조치 할당량은 데이터, 쿼리, 인덱스 및 검색 노드를 포함한 클러스터의 모든 노드에 적용됩니다.
두 개 이상의 노드에 동시에 장애가 발생하면 나중에 설명하는 서버 그룹 자동 장애 조치를 제외하고는 사용자가 설정한 최대 수에 관계없이 자동 장애 조치가 작동하지 않습니다. 이 제약 조건은 네트워크 파티션으로 인해 클러스터의 두 개 이상의 절반이 서로 장애를 일으키지 않도록 하기 위해 마련된 것입니다. 데이터 무결성과 일관성을 보호합니다.
참고 - 여러 노드에 장애가 발생하면 클러스터의 부하가 증가합니다. 둘 이상의 노드에 대한 자동 장애 조치를 허용하려는 사용자는 장애를 처리할 수 있는 충분한 용량이 있는지 확인해야 합니다.
자동 페일오버 서버 그룹(랙 영역 인식)
랙 영역 인식을 사용하면 각 서버 그룹이 물리적으로 랙 또는 가용성 영역에 속하는 클러스터에서 서버를 논리적으로 그룹화할 수 있습니다.
Couchbase Server 5.5에서 사용자는 Couchbase 웹 콘솔의 노드 가용성 설정에서 또는 CLI/REST API를 통해 다음 설정을 구성할 수 있습니다.
- 서버 그룹 자동 장애 조치 사용
- 이 기능을 사용하려면 노드 자동 장애 조치를 사용 설정하세요.
- 다음과 같습니다. 꺼짐 기본값입니다.
어떻게 작동하나요?
서버 그룹의 자동 장애 조치가 작동하려면 - 다음과 같이 하세요.
- 클러스터에는 장애 발생 시 최소 3개의 서버 그룹이 필요합니다. 이 제약 조건은 서버 그룹이 두 개만 있고 그 사이에 네트워크 파티션이 있는 경우 두 서버 그룹이 서로 장애 조치를 시도할 수 있기 때문에 필요합니다.
- 서버 그룹의 모든 노드에 장애가 발생했습니다. 이는 전체 영역 또는 랙에 영향을 미친 상호 연관된 장애를 나타냅니다.
- 장애가 발생한 모든 노드는 동일한 서버 그룹에 속합니다. 이렇게 하면 네트워크 파티션으로 인해 클러스터의 두 개 이상의 절반이 서로 장애를 일으키는 것을 방지할 수 있습니다.
추가 리소스
- Couchbase Server 5.5 다운로드
- 카우치베이스 서버 5.5 문서
- 카우치베이스 서버 5.5 도커 컨테이너
- 에 대한 의견을 공유하세요. 카우치베이스 포럼
둘 이상의 노드에 대해 자동 페일오버를 수행하는 경우. 복제본 수의 최소 공통 분모를 확인하고 이를 기반으로 해당 수의 노드 장애 조치를 수행할 수 있나요?