El liderazgo de Red Hat en el espacio de orquestación de contenedores con OpenShift refleja el liderazgo de Couchbase en el espacio de bases de datos en contenedores con su Autonomous Operator. Este hecho es la base de la asociación entre Red Hat y Couchbase. He trabajado personalmente en la asociación durante los últimos dos años. Quería aprovechar esta oportunidad para discutir por qué ahora es un gran momento para ejecutar Couchbase en Red Hat OpenShift.
El "estado" actual de Kubernetes
Antes de unirme a Couchbase trabajé en una empresa de monitorización SaaS. Trabajar en una empresa de monitorización te da una visión única de las tecnologías que utilizan tus clientes. En 2017 se podía ver el punto de inflexión de Kubernetes y OpenShift en los paneles de monitorización de nuestros clientes. Estaba claro que Red Hat OpenShift estaba ganando la guerra de la orquestación de contenedores entre las grandes empresas. Pero había algo que definitivamente no se veía: bases de datos en Kubernetes. Especialmente en producción. De hecho, ejecutar cualquier carga de trabajo "con estado" en Kubernetes se consideraba arriesgado. La arquitectura típica implicaba ejecutar las cargas de trabajo sin estado en Kubernetes u OpenShift y ejecutar las bases de datos en otro lugar.
Como le dirá cualquier ingeniero de bases de datos, la gestión del estado en un aplicación distribuida es difícil. Cuando se añaden múltiples capas de abstracción y escalado elástico, la cosa se complica aún más. Kubernetes es y fue excelente en la gestión de recursos informáticos y de memoria, pero el almacenamiento no era algo gestionado directamente por Kubernetes. En otras palabras, Kubernetes y OpenShift eran geniales para gestionar cargas de trabajo sin estado, pero solo unos pocos valientes se atrevieron a ejecutar aplicaciones persistentes y con estado directamente en Kubernetes (es decir, bases de datos). El patrón típico consistía en alojar la base de datos en otro lugar (véase "Entonces" en el diagrama siguiente).
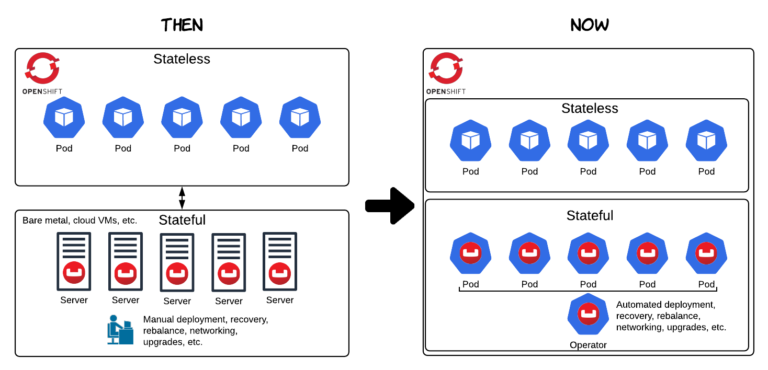
Almacenamiento - Volúmenes persistentes
La comunidad quería abordar este problema y Volúmenes persistentes fue un elemento fundamental. Persistent Volumes (PVs) proporcionó una solución a la gestión del almacenamiento y el aislamiento en forma de una API que permite conectar diferentes clases de almacenamiento a los pods en ejecución. Los PV tienen un ciclo de vida independiente de cualquier pod individual, lo que les permite mantener sus datos incluso después de la destrucción de un pod. Esto significa que no tiene que preocuparse por la pérdida de datos en un escenario de desastre cuando pierde una base de datos o un nodo OpenShift.
Varios proveedores de almacenamiento han añadido compatibilidad con Kubernetes a través de la API Persistent Volumes, incluidos los proveedores de nube y el socio de Red Hat, Portworx. Esto significa que tiene opciones a la hora de elegir su almacenamiento. Esto es fundamental desde el punto de vista de un proveedor de bases de datos, ya que elegir el almacenamiento adecuado puede tener un gran impacto en el rendimiento y la fiabilidad.
El marco del operador
La segunda gran innovación y la que ha permitido a Couchbase convertirse en el líder de las bases de datos NoSQL en OpenShift, es el Marco para operadores. Couchbase fue la primera empresa de bases de datos NoSQL en invertir seriamente en el desarrollo de un operador (véase "Los principales operadores de Kubernetes avanzan en el modelo de capacidad del operador"). Colaboramos con el equipo de CoreOS desde el principio durante el desarrollo del Operator Framework. Hoy en día, los clientes de Couchbase pueden confiar en Couchbase Autonomous Operator para gestionar muchas de las operaciones de su clúster, incluyendo el despliegue, escalado, recuperación de desastres, actualizaciones y mucho más. Esto representa un enorme valor para los clientes de Couchbase y también está ayudando a impulsar la adopción de OpenShift.
¿Qué es un Operador? Esta cita del equipo de Red Hat CoreOS lo resume mejor:
"Conceptualmente, un Operador toma el conocimiento operativo humano y lo codifica en software que se empaqueta y comparte más fácilmente con los consumidores.. Piense en un Operador como una extensión del equipo de ingeniería del proveedor de software que vigila su entorno Kubernetes y utiliza su estado actual para tomar decisiones en milisegundos. Los operadores siguen un modelo de madurez que va desde la funcionalidad básica hasta la lógica específica de una aplicación. Los Operadores avanzados están diseñados para gestionar actualizaciones sin problemas, reaccionar ante fallos automáticamente y no tomar atajos, como saltarse un proceso de copia de seguridad del software para ahorrar tiempo."
https://coreos.com/blog/introducing-operator-framework
Dado que la gestión del estado distribuido es un reto, y los diferentes sistemas gestionan el estado de manera diferente en función de detalles de implementación muy específicos, nunca fue razonable esperar que la comunidad Kubernetes codificara para cada posible escenario que todas y cada una de las aplicaciones con estado pudieran encontrar. Operator Framework permite a los desarrolladores salvar esa distancia, y hacerlo de un modo que se ajusta al paradigma de Kubernetes. Por ejemplo: En un escenario de desastre, cuando un nodo OpenShift que ejecuta un pod de Couchbase se cae, el Operador Autónomo de Couchbase restaurará automáticamente y con gracia el clúster y reequilibrará tus datos sin ninguna interrupción de los servicios que utilizan Couchbase. Y si estás usando Volúmenes Persistentes, incluso volverá a conectar el volumen de tu pod perdido a tu nuevo pod de Couchbase - acelerando enormemente el tiempo que se tarda en reequilibrar tus datos.
Gestor del ciclo de vida del operador
A medida que los operadores han ido madurando, también lo han hecho las herramientas que los rodean. El mejor ejemplo es el Gestor del ciclo de vida del operador (OLM). OLM estaba en vista previa técnica desde OpenShift 3.11. A partir de OpenShift 4 es una función oficialmente compatible. Normalmente, la instalación de un Operator requiere privilegios de administrador de clúster y algunos pasos manuales, como la instalación de un Definición de recursos personalizados. OLM automatiza la tarea de instalación y también puede administrar las actualizaciones por usted sin requerir privilegios de administrador de cluster. El OLM se conecta directamente al OperatorHub lo que significa que a medida que se publiquen nuevas actualizaciones de Operator, aparecerán en el catálogo de OperatorHub y se podrán instalar a través del OLM. Esto permite a los usuarios encontrar el Operator que necesitan e instalarlo en un par de clics.
Uno de sus principales beneficios es la productividad de los desarrolladores. Ofrece a los desarrolladores "operadores como servicio" dentro de sus entornos de desarrollo de OpenShift.
¿Por qué Couchbase?
En los últimos años, el término "nativo de la nube" se ha convertido en parte del lenguaje común de la tecnología. Aparece con especial frecuencia en el contexto de los debates sobre Kubernetes y OpenShift. Kubernetes se presenta a menudo como la plataforma para las aplicaciones nativas de la nube. Cloud Native significa software diseñado para aprovechar el modelo de computación en nube. En la práctica, esto significa aplicaciones que se ajustan más a un patrón de arquitectura orientada a microservicios y servicios (en contraposición a una arquitectura monolítica), que pretenden escalar horizontalmente (en contraposición a escalar verticalmente) y que pueden ejecutarse en contenedores relativamente ligeros. Esto supone un problema para las bases de datos relacionales tradicionales (y algunas NoSQL), que siguen en gran medida patrones monolíticos y no fueron diseñadas para escalar horizontalmente de la forma en que lo hizo Couchbase.
Aquí es donde Couchbase brilla en relación con otras opciones. Al principio de la vida de Couchbase, fue empujado y desafiado a soportar cargas de trabajo a escala web en entornos de nube por sus mayores usuarios. Couchbase adoptó una arquitectura desde el principio que se asemeja a lo que ahora llamamos Cloud Native. En Couchbase, esto se refleja en nuestro Escala multidimensional capacidad. El escalado multidimensional permite que cada uno de los servicios de Couchbase (datos, índice, consulta, análisis, búsqueda de texto completo y eventos) se escale de forma independiente, mientras está en línea y sirviendo tráfico. Esto es exactamente como querrías diseñar una aplicación con la nube nativa en mente.
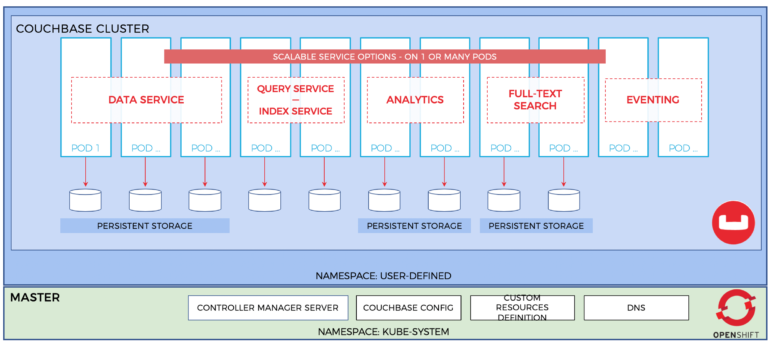
Además del escalado multidimensional, otras funciones de Couchbase, como la fragmentación automática y una interfaz administrativa robusta e integrada, solo ayudan a suavizar la experiencia de gestionar tus cargas de trabajo NoSQL en OpenShift.
Hacia dónde vamos
Couchbase Autonomous Operator 2.0 Beta
Nuestro objetivo es automatizar todas las mejores prácticas operativas de Couchbase necesarias para ejecutar clústeres con nuestro Operador. El objetivo final es que nuestros clientes y los clientes de Red Hat puedan operar eficientemente su propio Couchbase DBaaS ejecutándose en cualquier entorno OpenShift en la nube, on prem, o ambos. Incluso la propia oferta DBaaS de Couchbase se basa en gran medida en Couchbase Autonomous Operator.
Recientemente hemos lanzado el Couchbase Autonomous Operator 2.0 Beta. Aunque seguimos añadiendo nuevas funciones al propio Operator, reconocemos que Couchbase es sólo una pieza de la infraestructura. En la práctica, hay otras funciones como la monitorización de métricas y registros y la seguridad que abarcan múltiples piezas de la infraestructura. Operator 2.0 incluye integración con Couchbase Prometheus Exporter para recoger y exponer las métricas de Couchbase Server. Esto significa que puede monitorizar Couchbase junto con sus otras aplicaciones dentro de su entorno Ret Hat OpenShift.
Habilitación de cargas de trabajo en nubes múltiples e híbridas
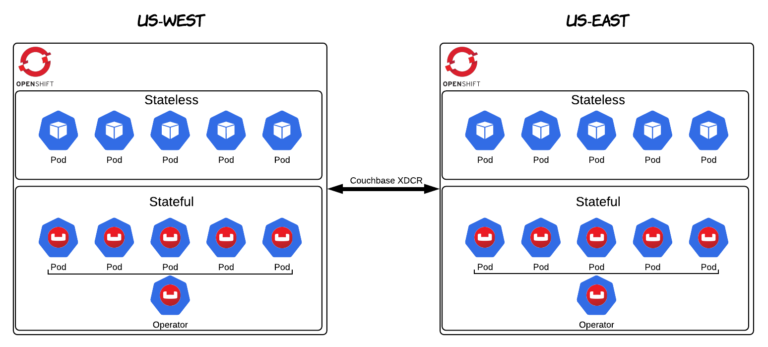
Sería negligente si no mencionara otra característica clave de Couchbase - Replicación entre centros de datos (XDCR). XDCR siempre ha sido una característica popular de Couchbase. La razón por la que es importante en este contexto es por su papel a la hora de permitir cargas de trabajo con estado en nubes múltiples e híbridas en OpenShift. OpenShift ya facilita el despliegue de aplicaciones en diferentes nubes y on-prem. Con XDCR también se puede lograr la replicación de datos a través de clústeres OpenShift. En las próximas semanas nosotros (Red Had y Couchbase) planeamos proporcionar más contenido y actualizaciones sobre este tema en concreto. ¡Permanece atento!
Recursos
- Red Hat OpenShift Blog:Los principales operadores de Kubernetes avanzan en el modelo de capacidad de operador
- Anuncio de Couchbase Autonomous Operator 2.0 Beta
- Instalación del Operador Autónomo Couchbase en Red Hat OpenShift
- Página de Red Hat Partner de Couchbase