¿Qué son los modelos de lenguaje visual?
Los modelos de lenguaje visual son sistemas de inteligencia artificial diseñados para comprender y razonar a partir de datos tanto visuales como textuales. A diferencia de los modelos tradicionales de visión por computadora (CV), que solo analizan imágenes, o de los grandes modelos de lenguaje (LLM), que solo procesan texto, los VLM conectan estas dos modalidades para crear una comprensión compartida.
Los modelos de lenguaje visual (VLM) suelen entrenarse con grandes conjuntos de datos que contienen imágenes y texto emparejados, como fotos con leyendas o documentos que combinan elementos visuales y lenguaje. A través de este entrenamiento, los VLM aprenden cómo las características visuales (por ejemplo, objetos, escenas y relaciones espaciales) se corresponden con las palabras y el significado. Esto permite a los modelos describir imágenes, responder preguntas sobre ellas y razonar sobre el contenido visual utilizando el lenguaje.
Cómo funcionan los modelos de lenguaje visual
Los modelos de lenguaje visual combinan la interpretación visual y la comprensión del lenguaje en un único sistema. Aunque las arquitecturas varían, la mayoría de los VLM siguen el mismo flujo de trabajo básico que se describe a continuación.
1. Codificación de imágenes y extracción de características visuales
- Las imágenes son procesadas por un codificador de visión, que suele ser una red neuronal convolucional (CNN) o un transformador de visión (ViT).
- El codificador extrae características visuales significativas, como objetos, formas, texturas y relaciones espaciales.
- Estas características se convierten en representaciones numéricas sobre las que el modelo puede razonar.
2. Codificación de texto y comprensión del lenguaje
- Las entradas de texto son procesadas por un codificador de lenguaje, que suele basarse en arquitecturas de transformador.
- El codificador capta el significado semántico, el contexto y las relaciones entre las palabras.
- El resultado es una representación estructurada del lenguaje que se ajusta a conceptos visuales.
3. Alineación intermodal entre la visión y el lenguaje
- El modelo aprende a mapear representaciones de imágenes y texto en un espacio de incrustación compartido.
- En este espacio, las imágenes y el texto relacionados se colocan más cerca unos de otros, mientras que los elementos que no guardan relación se separan.
- Esta alineación permite realizar tareas como la generación de leyendas para imágenes, la respuesta a preguntas visuales (VQA) y la recuperación de imágenes y texto.
- Modelos como CLIP son bien conocidos por su capacidad para aprender una alineación sólida entre imágenes y texto a gran escala.
4. Entrenamiento frente a inferencia en los modelos de lenguaje voluminoso (VLM)
- Formación:
- El modelo se entrena con grandes conjuntos de datos que combinan imágenes y texto (por ejemplo, pies de foto, descripciones o documentos).
- Los objetivos permiten que el modelo asocie correctamente las imágenes con el lenguaje pertinente.
- Conclusión:
- Una vez entrenado, el modelo aplica lo que ha aprendido a nuevas entradas.
- Puede interpretar imágenes, responder preguntas, generar descripciones o buscar contenido relevante sin necesidad de un entrenamiento adicional.
Modelos de lenguaje para la visión artificial frente a modelos tradicionales de visión artificial frente a modelos de lenguaje a gran escala
Aunque los tres tipos de modelos se engloban dentro del concepto más amplio de la IA, están diseñados para fines muy diferentes. Las diferencias clave residen en los datos que pueden procesar, su forma de razonar y el tipo de tareas para las que son más adecuados. Comprender estas distinciones ayuda a los equipos a elegir el modelo adecuado para cada problema. A continuación, se presenta una breve comparación que resume las diferencias clave:
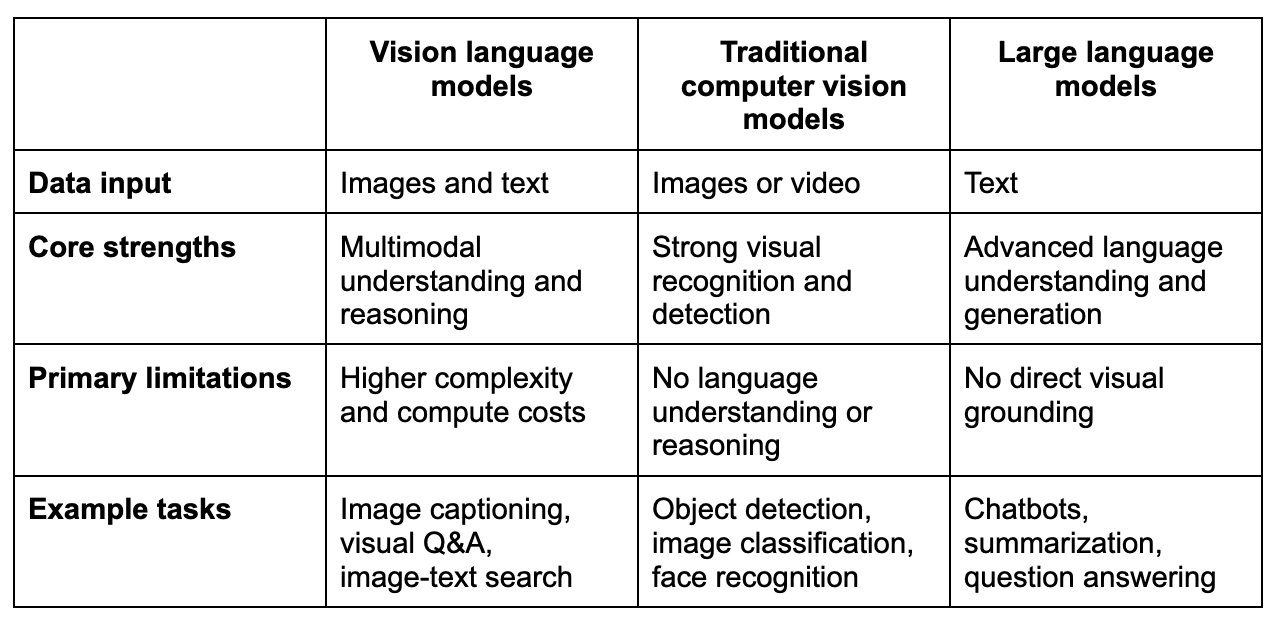
Explicación de las diferencias clave
- Los modelos de visión por computadora tradicionales se centran exclusivamente en las señales visuales y están optimizados para identificar lo que hay en una imagen, pero no para explicarlo en lenguaje natural.
- Los modelos de lenguaje grande (LLM) destacan en el razonamiento con texto, pero carecen de conciencia del contexto visual a menos que se les describa.
- Los VLM sirven de puente entre los modelos de visión por computadora (CV) y los modelos de lenguaje grande (LLM), lo que permite un razonamiento fundamentado tanto en imágenes como en texto.
Modelos de lenguaje grande (VLM) tan conocidos como CLIP aprenden a Alinear imágenes e idioma, mientras que las versiones multimodales de GPT-5 amplían esta capacidad al razonamiento y la interacción más generales.
Cuándo utilizar un modelo de lenguaje visual frente a un modelo monomodal
Utiliza un modelo de lenguaje de visión cuando:
- La tarea requiere comprender tanto las imágenes como el texto en su conjunto
- Los usuarios necesitan explicaciones, respuestas o razonamientos basados en contenido visual
- Las aplicaciones incluyen la búsqueda multimodal, la comprensión de documentos o la asistencia visual
Utiliza un modelo tradicional de visión artificial cuando:
- La tarea es puramente visual (por ejemplo, detectar defectos, contar objetos)
- La velocidad, la eficiencia o la implementación en el borde son fundamentales
- No se requiere ningún razonamiento ni explicación basada en el lenguaje
Utiliza un modelo de lenguaje grande cuando:
- El problema se refiere únicamente al texto (por ejemplo, resumen, generación de contenido)
- El contexto visual es innecesario o ya está implícito en el texto
- Necesitas un razonamiento flexible en lenguaje natural
Competencias y tareas clave
La capacidad de comprender conjuntamente el contenido visual y el lenguaje natural permite a los VLM interpretar, razonar e interactuar con imágenes de formas más flexibles y similares a las humanas, tales como:
Subtítulos de imágenes
Los VLM pueden generar descripciones en lenguaje natural de imágenes mediante la identificación de objetos, acciones y relaciones dentro de una escena. Esta capacidad se utiliza habitualmente en herramientas de accesibilidad, moderación de contenidos y gestión de medios.
Respuesta visual a preguntas
La respuesta visual a preguntas permite a los usuarios formular preguntas sobre una imagen y recibir respuestas relevantes que tienen en cuenta el contexto. Para responder con precisión, el modelo debe comprender tanto el contenido visual como la intención que subyace a la pregunta.
Búsqueda de imágenes y texto
Los VLM permiten la búsqueda multimodal al relacionar imágenes con texto y viceversa. Esto da lugar a casos de uso como la búsqueda de productos a partir de descripciones o la recuperación de imágenes relevantes mediante consultas en lenguaje natural.
Razonamiento multimodal
Los VLM pueden procesar información visual y textual para extraer conclusiones, comparar elementos o seguir instrucciones basadas en imágenes. Esta capacidad es fundamental para tareas complejas como la asistencia visual y el apoyo a la toma de decisiones.
Comprensión de documentos y escenas
Los VLM pueden interpretar documentos y escenas del mundo real que combinan texto y elementos visuales, como formularios, diagramas, capturas de pantalla o imágenes de calles. Esto permite el desarrollo de aplicaciones como el análisis de documentos, la automatización de flujos de trabajo y los sistemas sensibles al entorno.
Casos de uso de los modelos de lenguaje visual
Al combinar diferentes modalidades, los VLM permiten interacciones más ricas, una mayor automatización y conocimientos más precisos en numerosos sectores en los que es esencial comprender tanto el contenido visual como el lenguaje. Entre los casos de uso más comunes se incluyen:
- Búsqueda y descubrimiento visuales: Permite a los usuarios buscar productos, imágenes o contenido utilizando descripciones en lenguaje natural en lugar de palabras clave.
- Atención al cliente y resolución de problemas: Interpreta las capturas de pantalla o las fotos enviadas por los usuarios para ofrecer una asistencia más rápida y precisa.
- Procesamiento y análisis de documentos: Extraiga información de documentos que combinan texto, tablas, gráficos e imágenes, como facturas, contratos e informes.
- Herramientas de accesibilidad: Genera descripciones de imágenes y responde a preguntas visuales para ayudar a los usuarios con discapacidad visual.
- Atención sanitaria e imágenes médicas: Analice imágenes médicas junto con las notas clínicas para facilitar el diagnóstico, la documentación y la investigación.
- Comercio minorista y comercio electrónico: Potencia las recomendaciones visuales de productos, la búsqueda basada en imágenes y el etiquetado automático de catálogos.
- Sistemas autónomos y robótica: Ayudar a las máquinas a comprender su entorno y a seguir instrucciones verbales basadas en el contexto visual.
- Moderación de contenidos y seguridad: Identificar e interpretar el contenido visual junto con el texto para aplicar las políticas con mayor precisión.
Datos de entrenamiento y arquitecturas
Los modelos de lenguaje visual se basan en datos multimodales a gran escala y en arquitecturas especializadas para aprender las relaciones entre las imágenes y el lenguaje. La calidad de los datos y el diseño de la arquitectura del modelo desempeñan un papel fundamental en el rendimiento de un VLM en las distintas tareas.
Datos de entrenamiento para modelos de lenguaje visual
Los modelos de lenguaje visual requieren datos de entrenamiento diversos para captar tanto un amplio conocimiento multimodal como las relaciones específicas de cada tarea o ámbito entre imágenes y texto. Estos datos incluyen:
- Pares de imagen y texto: El formato de datos de entrenamiento más común, en el que las imágenes se combinan con leyendas, descripciones o texto circundante
- Conjuntos de datos a escala web: Amplias colecciones de imágenes y textos de acceso público que se utilizan para aprender conceptos visuales y lingüísticos generales
- Conjuntos de datos anotados: Datos cuidadosamente etiquetados para tareas como la respuesta visual a preguntas, la comprensión de documentos o la interpretación de escenas
- Datos específicos del dominio: Conjuntos de datos especializados (por ejemplo, imágenes médicas con notas clínicas o imágenes de productos con metadatos) que se utilizan para mejorar el rendimiento en sectores específicos
Arquitecturas comunes de VLM
Han surgido varios paradigmas arquitectónicos para los modelos de lenguaje visual, cada uno de los cuales equilibra la eficiencia, la flexibilidad y la capacidad de razonamiento de formas distintas:
- Modelos con doble codificador:
- Utiliza codificadores distintos para las imágenes y el texto
- Aprende a alinear representaciones visuales y lingüísticas en un espacio de incrustación compartido
- Ideal para tareas de recuperación y entrenamiento escalable (p. ej., CLIP)
- Modelos codificador-decodificador:
- Codifica entradas visuales y genera salidas de texto directamente
- Se utiliza habitualmente para la generación de leyendas de imágenes y la respuesta a preguntas visuales (p. ej., BLIP)
- Modelos multimodales unificados:
- Procesar imágenes y texto conjuntamente dentro de una única arquitectura basada en transformadores
- Permitir un razonamiento multimodal avanzado y una gestión flexible de las tareas
El papel de los transformadores y los mecanismos de atención
- Las arquitecturas de transformadores permiten que los modelos presten atención a las partes relevantes tanto de las imágenes como del texto.
- Los mecanismos de atención ayudan al modelo a comprender las relaciones entre las regiones visuales y las palabras o frases.
- Este diseño es fundamental para permitir un razonamiento complejo entre distintas modalidades.
Limitaciones de los modelos de lenguaje visual
Si bien los modelos de lenguaje con visión ofrecen potentes capacidades multimodales, también presentan importantes limitaciones que los equipos deben comprender antes de implementarlos en aplicaciones del mundo real.
- Calidad de los datos y sesgos: Los modelos de lenguaje de vídeo (VLM) se entrenan con grandes conjuntos de datos de imágenes y texto que pueden contener ruido, imprecisiones o sesgos sociales, lo cual puede afectar a los resultados del modelo y a su imparcialidad.
- Alto costo computacional: El entrenamiento y la ejecución de modelos de lenguaje grande (VLM) requieren una gran cantidad de recursos informáticos, lo que encarece su creación, implementación y escalabilidad.
- Referencias visuales limitadas: Los modelos pueden generar respuestas seguras pero incorrectas si los detalles visuales son sutiles, ambiguos o se encuentran fuera de su distribución de entrenamiento.
- Dificultades de generalización: El rendimiento puede disminuir cuando los modelos se enfrentan a ámbitos desconocidos, estilos de imagen o situaciones del mundo real que no están bien representados en los datos de entrenamiento.
- Cuestiones relacionadas con la interpretabilidad: A menudo resulta difícil entender por qué un VLM ha generado un resultado concreto, lo cual puede suponer un problema en entornos regulados o de alto riesgo.
- Restricciones de latencia: La complejidad del procesamiento multimodal puede provocar retrasos, lo que limita su idoneidad para aplicaciones en tiempo real o aplicaciones periféricas.
- Cuestiones éticas y de privacidad: El uso de imágenes que incluyan personas, espacios privados o información confidencial conlleva riesgos relacionados con la privacidad, el consentimiento y el uso indebido.
Reconocer estas limitaciones es fundamental para aplicar los modelos de lenguaje visual de forma responsable y para seleccionar las medidas de seguridad, los métodos de evaluación y los casos de uso adecuados.
Evaluación e indicadores de rendimiento
La evaluación de los modelos de lenguaje visual (VLM) requiere medir tanto la comprensión visual como el rendimiento lingüístico, a menudo en múltiples tareas. Dado que muchos resultados de los VLM son abiertos, una evaluación eficaz suele combinar métricas automatizadas con el criterio humano.
Métricas específicas para cada tarea
Dependiendo de cómo se formule la tarea concreta, los indicadores estándar de rendimiento predictivo incluyen:
- Precisión: Se utiliza habitualmente para tareas de clasificación, como la respuesta a preguntas visuales con conjuntos de respuestas fijos
- Precisión, recuperación y puntuación F1: Evalúa la capacidad del modelo para identificar resultados relevantes, especialmente en tareas de recuperación o detección
- Precisión Top-k: Evalúa si la respuesta correcta se encuentra entre las principales predicciones del modelo
Métricas de calidad de la generación
En el caso de tareas en las que el modelo genera texto libre, las métricas especializadas incluyen:
- BLEU: Mide el solapamiento entre el texto generado y los pies de foto o respuestas de referencia; se utiliza a menudo en tareas de subtitulación de imágenes y traducción
- ROUGE: Se centra en la recuperación y se aplica habitualmente a resultados de tipo resumen
- CIDEr y METEOR: Diseñado específicamente para evaluar leyendas de imágenes comparándolas con múltiples referencias humanas
Métricas de recuperación y alineación
Cuando el objetivo es evaluar la capacidad de los modelos para relacionar imágenes y texto, las métricas incluyen:
- Recall@K: Evalúa la frecuencia con la que aparece la imagen o el texto correcto entre los primeros K resultados
- Rango recíproco medio (MRR): Evalúa la calidad de la clasificación en tareas de recuperación de imágenes y texto
- Intermodal similitud puntuaciones: Mide el grado de alineación entre las representaciones de imágenes y textos en espacios de representación compartidos
Evaluación humana
Dado que las métricas automatizadas pueden carecer de matices, a menudo se recurre al criterio humano para ofrecer una evaluación más integral del comportamiento del modelo.
- Los revisores humanos evalúan aspectos que las métricas automatizadas no logran captar, como la corrección, la relevancia, el razonamiento y la fluidez.
- La evaluación humana es especialmente importante para el razonamiento multimodal y las tareas de generación de resultados abiertos.
Indicadores de rendimiento operativo
Más allá de la calidad de los resultados, una implementación práctica también requiere evaluar la eficiencia con la que funcionan los modelos en limitaciones de los sistemas en el mundo realcomo:
- Latencia: Tiempo necesario para procesar entradas de texto e imágenes y generar resultados
- Rendimiento: Número de solicitudes gestionadas durante un periodo de tiempo determinado
- Uso de recursos: Requisitos de memoria y potencia de cálculo durante la inferencia
Una estrategia de evaluación equilibrada garantiza que los modelos de lenguaje visual sean precisos, fiables y fáciles de implementar.
Tendencias futuras en los modelos de lenguaje visual
Los modelos de lenguaje visual siguen evolucionando a medida que la investigación va más allá de la simple correspondencia entre imágenes y texto para alcanzar una comprensión más profunda, el razonamiento y la interacción con el mundo real. Varias tendencias clave están dando forma a la próxima generación de capacidades de los VLM. Entre ellas se incluyen:
- Un razonamiento multimodal más sólido: Los modelos irán más allá de la mera descripción de imágenes para llevar a cabo un razonamiento paso a paso basado en pruebas visuales, lo que permitirá una toma de decisiones y un análisis más fiables.
- Arquitecturas multimodales unificadas: Es probable que los futuros modelos de lenguaje grande (VLM) sean capaces de gestionar imágenes, texto, vídeo, audio y otras modalidades dentro de un único modelo cohesivo, en lugar de hacerlo en componentes separados.
- Mejor conexión a tierra y mayor fiabilidad: La investigación se centra cada vez más en reducir las alucinaciones y mejorar la forma en que los modelos vinculan sus resultados directamente con los datos visuales.
- Entrenamiento e inferencia más eficientes: Los avances en la compresión de modelos, la destilación y la optimización del hardware reducirán los costos y harán que los modelos de lenguaje grande (VLM) sean más prácticos a gran escala y en dispositivos periféricos.
- Modelos de lenguaje de volumen especializados por dominio: Se espera que haya más modelos entrenados o ajustados para sectores específicos, como la salud, las finanzas, la industria manufacturera y la investigación científica.
- Integración con agentes y herramientas: Los VLM se combinarán cada vez más con agentes autónomos, lo que permite a los sistemas percibir el entorno, planificar acciones e interactuar con el mundo utilizando tanto la visión como el lenguaje.
- Mayor énfasis en la ética y la gobernanza: A medida que aumente su adopción, la transparencia, la protección de la privacidad y la reducción de sesgos pasarán a ser aspectos fundamentales en el desarrollo y la implementación de los VLM.
En conjunto, estas tendencias apuntan a que los modelos de lenguaje visual se convertirán en un capa base para sistemas de IA multimodales que puedan ver, comprender, razonar y actuar de manera más similar a los humanos en entornos complejos.
Puntos clave y recursos relacionados
Los modelos de lenguaje visual (VLM) representan un gran avance en el campo de la inteligencia artificial, ya que unifican la comprensión visual y el razonamiento del lenguaje natural en un solo sistema. Al aprender a partir de datos emparejados de imagen y texto y al alinear la visión y el lenguaje en representaciones compartidas, los VLM permiten interacciones más flexibles, sensibles al contexto y similares a las humanas en una amplia gama de aplicaciones.
Principales conclusiones
- Los modelos de lenguaje visual están diseñados para comprender conjuntamente imágenes y texto, a diferencia de los modelos tradicionales de visión artificial o los grandes modelos de lenguaje, que operan en una sola modalidad.
- Los VLM aprenden las relaciones entre las características visuales y el lenguaje mediante el entrenamiento con grandes conjuntos de datos que combinan imágenes y texto.
- La mayoría de los modelos de lenguaje y visión se basan en codificadores independientes para la visión y el lenguaje que se alinean en un espacio de representación compartido.
- Modelos como CLIP demostrar que la alineación de imágenes y texto a gran escala permite una recuperación y un razonamiento multimodales sólidos.
- Los modelos de lenguaje visual son especialmente eficaces para tareas que requieren una comprensión multimodal, como la generación de leyendas para imágenes, la respuesta a preguntas visuales y la interpretación de documentos o escenas.
- A pesar de sus capacidades, los modelos de lenguaje grande (VLM) se enfrentan a importantes limitaciones en cuanto a la calidad de los datos, el sesgo, el costo computacional, la generalización y la interpretabilidad.
- Los continuos avances en arquitectura, eficiencia y contextualización están posicionando a los modelos de lenguaje con visión como un componente fundamental de los futuros sistemas de IA multimodal.
Para obtener más información sobre temas relacionados con los avances en inteligencia artificial, puedes consultar los recursos relacionados que se indican a continuación:
Recursos relacionados
- Guía completa sobre el proceso de desarrollo de aplicaciones de IA – Blog
- Crea tu primer agente de IA de código abierto con Couchbase – Blog
- Costos del desarrollo de aplicaciones (desglose) – Blog
- Guía sobre la gestión de datos para la IA – Blog
- Una visión general del análisis de datos no estructurados – Blog
Preguntas frecuentes
¿Cómo se entrenan y evalúan los modelos de lenguaje visual? Los modelos de lenguaje visual se entrenan con conjuntos de datos a gran escala que combinan imágenes y texto, y se evalúan en tareas de referencia como la recuperación de imágenes y texto, la respuesta visual a preguntas, la generación de leyendas y el razonamiento multimodal.
¿Cómo entienden los modelos de lenguaje visual la relación entre las imágenes y el texto? Aprenden a traducir los datos visuales y textuales en un incrustación espacio en el que las imágenes y el texto relacionados se sitúan muy cerca unos de otros, lo que permite la alineación y el razonamiento entre modalidades.
¿Cómo gestionan los modelos de lenguaje visual las entradas multimodales? Las VLM procesan imágenes y texto mediante codificadores independientes y, a continuación, combinan sus representaciones utilizando mecanismos de atención o arquitecturas compartidas para razonar conjuntamente sobre ambas entradas.
¿Son adecuados los modelos de lenguaje con visión para en tiempo real ¿o aplicaciones periféricas? Aunque pueden utilizarse en tiempo real para algunas aplicaciones, los elevados costes computacionales y la latencia suelen requerir una optimización, modelos más pequeños o una implementación basada en la nube, en lugar de dispositivos periféricos.
¿Qué cuestiones éticas o relacionadas con la privacidad se asocian a los modelos de lenguaje visual? Entre las principales preocupaciones se encuentran los sesgos heredados de los datos de entrenamiento, el uso indebido de imágenes que contienen personas o información confidencial, y los retos relacionados con el consentimiento, la vigilancia y la privacidad de los datos.
¿Cómo pueden las empresas empezar a utilizar los modelos de lenguaje con visión? Las empresas pueden empezar por probar modelos preentrenados o API, identificar casos de uso multimodales de gran impacto y, poco a poco, ajustar o integrar modelos de lenguaje grande (VLM) en función de sus datos, su infraestructura y sus necesidades de cumplimiento normativo.