He estado queriendo mostrar la mayoría de las nuevas características de búsqueda de Couchbase disponibles en 4.5 en un simple proyecto. Y ha habido cierto interés recientemente sobre almacenamiento de archivos o binarios en Couchbase. Desde una perspectiva general y genérica, las bases de datos no están hechas para almacenar archivos o binarios. Normalmente lo que harías es almacenar archivos en un almacén binario y sus metadatos asociados en la BD. Los metadatos asociados serán la localización del archivo en el almacén binario y tanta información como sea posible extraída del archivo.
Así que este es el proyecto que os mostraré hoy. Es una aplicación Spring Boot muy simple que permite al usuario subir archivos, almacenarlos en un almacén binario, donde el texto asociado y los metadatos se extraen del archivo, y le permiten buscar archivos basados en los metadatos y el texto. Al final podrás buscar archivos por mimetype, tamaño de imagen, contenido de texto, básicamente cualquier metadato que puedas extraer del archivo.
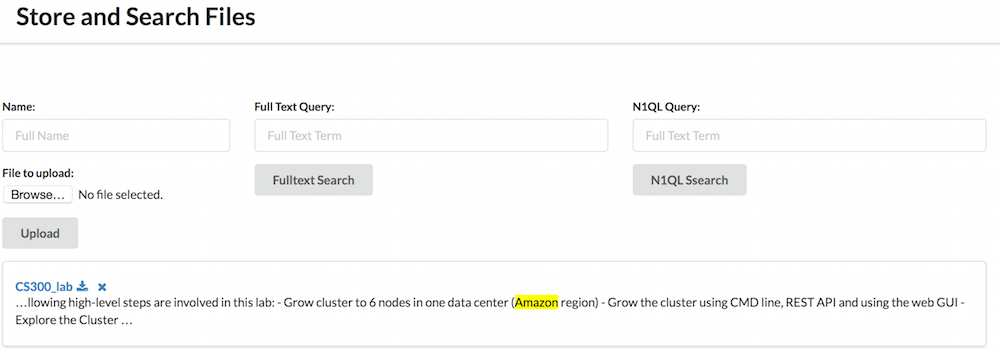
La tienda binaria
Esta es una pregunta que nos hacen a menudo. Ciertamente se pueden almacenar datos binarios en una BD, pero los ficheros deben estar en un almacén binario apropiado. Decidí crear una implementación muy simple para este ejemplo. Básicamente hay una carpeta en el sistema de archivos declarada en tiempo de ejecución que contendrá todos los archivos cargados. Un resumen SHA1 se calculará a partir del contenido del archivo y se utilizará como nombre de archivo en esa carpeta. Obviamente podrías usar otros almacenes binarios más avanzados como Manta de Joyent o Amazon S3 por ejemplo. Pero vamos a mantener las cosas simples para este post :) He aquí una descripción de los servicios utilizados.
Servicio SHA1
Este es el más simple, con un método que básicamente devuelve un resumen SHA-1 basado en el contenido del archivo. Para simplificar el código aún más estoy usando Apache commons-codec:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
@Service public class SHA1Service { public String getSha1Digest(InputStream is) { try { return DigestUtils.sha1Hex(is); } catch (IOException e) { throw new RuntimeException(e); } } } |
Servicio de extracción de datos
Este servicio sirve para extraer metadatos y texto de los archivos subidos. Hay muchas formas diferentes de hacerlo. Yo he optado por ExifTool y Poppler.
ExifTool es una gran herramienta de línea de comandos para leer, escribir y editar metadatos de archivos. También puede generar metadatos directamente en JSON. Y por supuesto no se limita al estándar Exif. Es compatible con una amplia variedad de formatos. Poppler es una biblioteca de utilidades PDF que me permitirá extraer el contenido de texto de un PDF. Como se trata de herramientas de línea de comandos, utilizaré plexus-utils para facilitar las llamadas CLI.
Existen dos métodos. El primero es extraerMetadatos y es responsable de la extracción de metadatos de ExifTool. Equivale a ejecutar el siguiente comando:
|
1 2 |
exiftool -n -json somePDFFile |
En -n está aquí para asegurarse de que todos los valores numéricos se darán como números y no como cadenas y -json para asegurarse de que la salida está en formato JSON. Esto puede darle una salida como esta:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[{ "SourceFile": "Desktop/someFile.pdf", "ExifToolVersion": 10.11, "FileName": "someFile.pdf", "Directory": "Desktop", "FileSize": 20468, "FileModifyDate": "2016:03:29 13:50:29+02:00", "FileAccessDate": "2016:03:29 13:50:33+02:00", "FileInodeChangeDate": "2016:03:29 13:50:33+02:00", "FilePermissions": 644, "FileType": "PDF", "FileTypeExtension": "PDF", "MIMEType": "application/pdf", "PDFVersion": 1.4, "Linearized": false, "ModifyDate": "2016:03:29 02:42:32-07:00", "CreateDate": "2016:03:29 02:42:32-07:00", "Producer": "iText 2.1.6 by 1T3XT", "PageCount": 1 }] |
Hay algunas informaciones interesantes como el tipo mime, el tamaño, la fecha de creación y más. Si el tipo mime del archivo es aplicación/pdf entonces podemos intentar extraer texto de él con poppler, que es lo que hace el segundo método del servicio. Es equivalente a la siguiente llamada CLI:
|
1 2 |
pdftotext -raw somePDFFile - |
Este comando envía el texto extraído a la salida estándar. Que podemos recuperar y poner en un texto completo en un objeto JSON. Código completo del servicio a continuación:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
package org.couchbase.devex.service; import java.io.File; import org.codehaus.plexus.util.cli.CommandLineException; import org.codehaus.plexus.util.cli.CommandLineUtils; import org.codehaus.plexus.util.cli.Commandline; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.stereotype.Service; import com.couchbase.client.java.document.json.JsonArray; import com.couchbase.client.java.document.json.JsonObject; @Service public class DataExtractionService { private final Logger log = LoggerFactory.getLogger(DataExtractionService.class); public JsonObject extractMetadata(File file) { String command = "/usr/local/bin/exiftool"; String[] arguments = { "-json", "-n", file.getAbsolutePath() }; Commandline commandline = new Commandline(); commandline.setExecutable(command); commandline.addArguments(arguments); CommandLineUtils.StringStreamConsumer err = new CommandLineUtils.StringStreamConsumer(); CommandLineUtils.StringStreamConsumer out = new CommandLineUtils.StringStreamConsumer(); try { CommandLineUtils.executeCommandLine(commandline, out, err); } catch (CommandLineException e) { throw new RuntimeException(e); } String output = out.getOutput(); if (!output.isEmpty()) { JsonArray arr = JsonArray.fromJson(output); return arr.getObject(0); } String error = err.getOutput(); if (!error.isEmpty()) { log.error(error); } return null; } public String extractText(File file) { String command = "/usr/local/bin/pdftotext"; String[] arguments = { "-raw", file.getAbsolutePath(), "-" }; Commandline commandline = new Commandline(); commandline.setExecutable(command); commandline.addArguments(arguments); CommandLineUtils.StringStreamConsumer err = new CommandLineUtils.StringStreamConsumer(); CommandLineUtils.StringStreamConsumer out = new CommandLineUtils.StringStreamConsumer(); try { CommandLineUtils.executeCommandLine(commandline, out, err); } catch (CommandLineException e) { throw new RuntimeException(e); } String output = out.getOutput(); if (!output.isEmpty()) { return output; } String error = err.getOutput(); if (!error.isEmpty()) { log.error(error); } return null; } } |
Cosas bastante simples como se puede ver una vez que utilice plexus-utils.
BinaryStoreService
Este servicio es responsable de ejecutar la extracción de datos y almacenar archivos, eliminarlos o recuperarlos. Empecemos por la parte de almacenamiento. Todo ocurre en el storeFile método. Lo primero que se hace es recuperar el digest del fichero, y luego escribirlo en la carpeta de almacenamiento binario declarada en la configuración. Una vez que el archivo está escrito, se llama al servicio de extracción de datos para recuperar los metadatos como un JsonObject. A continuación, la ubicación del almacén binario, el tipo de documento, el resumen y el nombre del archivo se añaden a ese objeto JSON. Si el archivo cargado es un PDF, se llama de nuevo al servicio de extracción de datos para recuperar el contenido de texto y almacenarlo en un objeto texto completo campo. A continuación se crea un JsonDocument con el digest como clave y el JsonObject como contenido.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
public void storeFile(String name, MultipartFile uploadedFile) { if (!uploadedFile.isEmpty()) { try { String digest = sha1Service.getSha1Digest(uploadedFile.getInputStream()); File file2 = new File(configuration.getBinaryStoreRoot() + File.separator + digest); BufferedOutputStream stream = new BufferedOutputStream(new FileOutputStream(file2)); FileCopyUtils.copy(uploadedFile.getInputStream(), stream); stream.close(); JsonObject metadata = dataExtractionService.extractMetadata(file2); metadata.put(StoredFileDocument.BINARY_STORE_DIGEST_PROPERTY, digest); metadata.put("type", StoredFileDocument.COUCHBASE_STORED_FILE_DOCUMENT_TYPE); metadata.put(StoredFileDocument.BINARY_STORE_LOCATION_PROPERTY, name); metadata.put(StoredFileDocument.BINARY_STORE_FILENAME_PROPERTY, uploadedFile.getOriginalFilename()); String mimeType = metadata.getString(StoredFileDocument.BINARY_STORE_METADATA_MIMETYPE_PROPERTY); if (MIME_TYPE_PDF.equals(mimeType)) { String fulltextContent = dataExtractionService.extractText(file2); metadata.put(StoredFileDocument.BINARY_STORE_METADATA_FULLTEXT_PROPERTY, fulltextContent); } JsonDocument doc = JsonDocument.create(digest, metadata); bucket.upsert(doc); } catch (Exception e) { throw new RuntimeException(e); } } else { throw new IllegalArgumentException("File empty"); } } |
Leer o borrar debería ser bastante sencillo de entender ahora:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
public StoredFile findFile(String digest) { File f = new File(configuration.getBinaryStoreRoot() + File.separator + digest); if (!f.exists()) { return null; } JsonDocument doc = bucket.get(digest); if (doc == null) return null; StoredFileDocument fileDoc = new StoredFileDocument(doc); return new StoredFile(f, fileDoc); } public void deleteFile(String digest) { File f = new File(configuration.getBinaryStoreRoot() + File.separator + digest); if (!f.exists()) { throw new IllegalArgumentException("Can't delete file that does not exist"); } f.delete(); bucket.remove(digest); } |
Tenga en cuenta que se trata de una aplicación muy ingenua.
Indexación y búsqueda de archivos
Una vez que haya cargado los archivos, querrá recuperarlos. La primera forma muy básica de hacerlo sería mostrar la lista completa de archivos. Entonces podrías usar N1QL para buscarlos basándote en sus metadatos o FTS para buscarlos basándote en su contenido.
Servicio de búsqueda
getFiles simplemente ejecuta la siguiente consulta: SELECT binaryStoreLocation, binaryStoreDigest FROMpor defectoWHERE type= 'archivo'. Esto envía la lista completa de archivos subidos con su compendio y la ubicación del almacén binario. Observe que la opción de coherencia está establecida en declaración_plus. Es una aplicación de documentos, así que prefiero una coherencia fuerte.
A continuación tiene búsquedaN1QLArchivos que ejecuta una consulta N1QL básica con una cláusula WHERE adicional. Así que por defecto es la misma consulta anterior con una parte adicional WHERE. Hasta ahora no hay una integración más estrecha. Podríamos tener un elegante formulario de búsqueda que permitiera al usuario buscar archivos basándose en sus tipos mime, tamaño o cualquier otro campo dado por ExifTool.
Y por último tiene buscarArchivosDeTextoCompleto que toma un String como entrada y lo utiliza en un Partido consulta. A continuación, se devuelve el resultado con fragmentos de texto en los que se ha encontrado el término. Este fragmento permite destacar el término en su contexto. También pido el binaryStoreDigest y binaryStoreLocation campos. Son los que se utilizan para mostrar los resultados al usuario.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
public List<Map<String, Object>> getFiles() { N1qlQuery query = N1qlQuery .simple("SELECT binaryStoreLocation, binaryStoreDigest FROM `default` WHERE type= 'file'"); query.params().consistency(ScanConsistency.STATEMENT_PLUS); N1qlQueryResult res = bucket.query(query); List<Map<String, Object>> filenames = res.allRows().stream().map(row -> row.value().toMap()) .collect(Collectors.toList()); return filenames; } public List<Map<String, Object>> searchN1QLFiles(String whereClause) { N1qlQuery query = N1qlQuery.simple( "SELECT binaryStoreLocation, binaryStoreDigest FROM `default` WHERE type= 'file' " + whereClause); query.params().consistency(ScanConsistency.STATEMENT_PLUS); N1qlQueryResult res = bucket.query(query); List<Map<String, Object>> filenames = res.allRows().stream().map(row -> row.value().toMap()) .collect(Collectors.toList()); return filenames; } public List<Map<String, Object>> searchFulltextFiles(String term) { SearchQuery ftq = MatchQuery.on("file_fulltext").match(term) .fields("binaryStoreDigest", "binaryStoreLocation").build(); SearchQueryResult result = bucket.query(ftq); List<Map<String, Object>> filenames = result.hits().stream().map(row -> { Map<String, Object> m = new HashMap<String, Object>(); m.put("binaryStoreDigest", row.fields().get("binaryStoreDigest")); m.put("binaryStoreLocation", row.fields().get("binaryStoreLocation")); m.put("fragment", row.fragments().get("fulltext")); return m; }).collect(Collectors.toList()); return filenames; } |
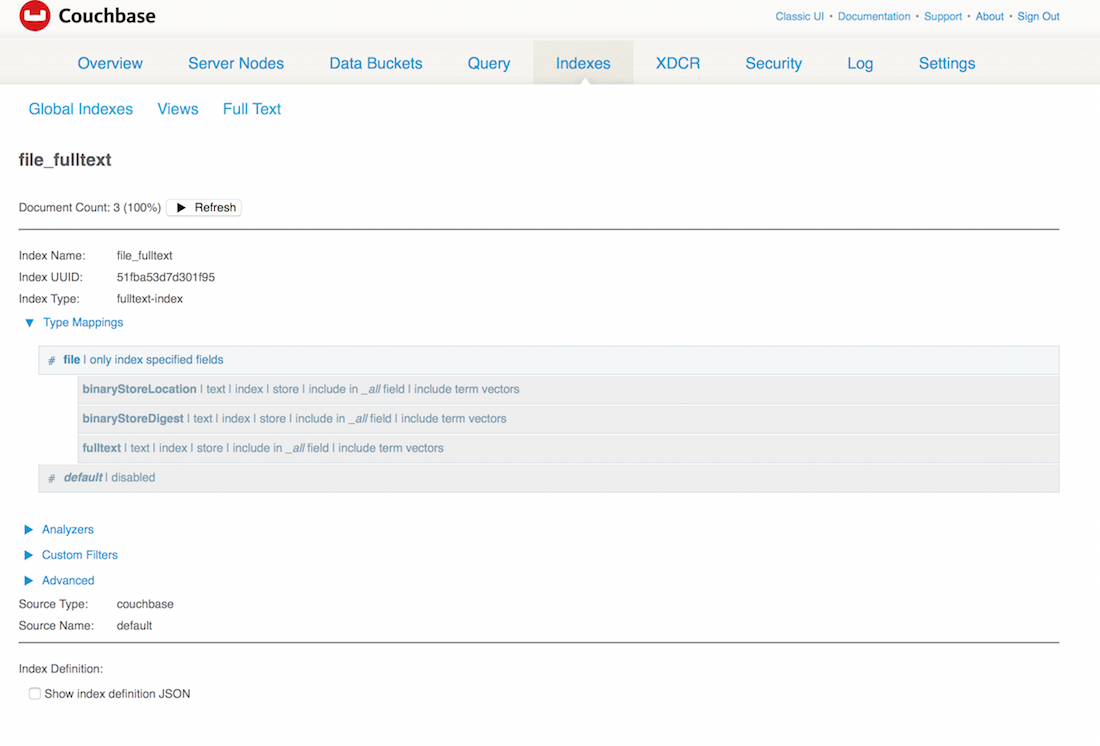
En TermQuery.on define qué índice estoy consultando. Aquí está definido como 'file_fulltext'. Significa que he creado un índice de texto completo con ese nombre:
Juntarlo todo
Configuración
Unas palabras sobre la configuración. Lo único configurable hasta ahora es la ruta del almacén binario. Como estoy usando Spring Boot, sólo necesito el siguiente código:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
package org.couchbase.devex; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Configuration; @Configuration public class BinaryStoreConfiguration { @Value("${binaryStore.root:upload-dir}") private String binaryStoreRoot; public String getBinaryStoreRoot() { return binaryStoreRoot; } } |
Con eso simplemente puedo añadir binaryStore.root=/Usuarios/ldoguin/binaryStore a mi aplicación.propiedades archivo. También quiero permitir la carga de archivos de 512 MB como máximo. Además, para aprovechar la autoconfiguración de Spring Boot Couchbase, necesito añadir la dirección de mi servidor Couchbase. Al final mi aplicación.propiedades se ve así:
|
1 2 3 4 5 |
binaryStore.root=/Users/ldoguin/binaryStore multipart.maxFileSize: 512MB multipart.maxRequestSize: 512MB spring.couchbase.bootstrap-hosts=localhost |
Usar la autoconfiguración de Spring Boot simplemente requiere tener spring-boot-starter-parent como padre y Couchbase en el classpath. Así que sólo es cuestión de añadir una dependencia java-client de Couchbase. Estoy especificando la versión 2.2.4 aquí porque por defecto es 2.2.3 y FTS sólo está en 2.2.4. Puedes echar un vistazo al archivo pom completo en Github. Felicitaciones a Stéphane Nicoll de Pivotal y Simon Baslé de Couchbase para esta maravillosa integración con Spring.
Controlador
Como esta aplicación es muy sencilla, he puesto todo bajo el mismo controlador. El punto final más básico es /archivos. Muestra la lista de archivos ya cargados. Sólo una llamada al searchService, poner el resultado en la página Modelo y luego renderizar la página.
|
1 2 3 4 5 6 7 |
@RequestMapping(method = RequestMethod.GET, value = "/files") public String provideUploadInfo(Model model) { List<Map<String, Object>> files = searchService.getFiles(); model.addAttribute("files", files); return "uploadForm"; } |
Utilizo Hoja de tomillo para renderizar y Interfaz semántica como framework CSS. Puede echar un vistazo a la plantilla utilizada aquí. Es la única plantilla utilizada en la aplicación.
Una vez que tenga una lista de archivos, puede descargarlos o eliminarlos. Ambos métodos están llamando al método del servicio de almacenamiento binario, el resto del código es el clásico Spring MVC:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
@RequestMapping(method = RequestMethod.GET, value = "/download/{digest}") public String download(@PathVariable String digest, RedirectAttributes redirectAttributes, HttpServletResponse response) throws IOException { StoredFile sf = binaryStoreService.findFile(digest); if (sf == null) { redirectAttributes.addFlashAttribute("message", "This file does not exist."); return "redirect:/files"; } response.setContentType(sf.getStoredFileDocument().getMimeType()); response.setHeader("Content-Disposition", String.format("inline; filename="" + sf.getStoredFileDocument().getBinaryStoreFilename() + """)); response.setContentLength(sf.getStoredFileDocument().getSize()); InputStream inputStream = new BufferedInputStream(new FileInputStream(sf.getFile())); FileCopyUtils.copy(inputStream, response.getOutputStream()); return null; } @RequestMapping(method = RequestMethod.GET, value = "/delete/{digest}") public String delete(@PathVariable String digest, RedirectAttributes redirectAttributes, HttpServletResponse response) { binaryStoreService.deleteFile(digest); redirectAttributes.addFlashAttribute("message", "File deleted successfuly."); return "redirect:/files"; } |
Obviamente también querrás subir algunos archivos. Es un simple Multipart POST. Se llama al servicio de almacenamiento binario, persiste el archivo y extrae los datos apropiados, luego redirige al servicio /archivos punto final.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@RequestMapping(method = RequestMethod.POST, value = "/upload") public String handleFileUpload(@RequestParam("name") String name, @RequestParam("file") MultipartFile file, RedirectAttributes redirectAttributes) { if (name.isEmpty()) { redirectAttributes.addFlashAttribute("message", "Name can't be empty!"); return "redirect:/files"; } binaryStoreService.storeFile(name, file); redirectAttributes.addFlashAttribute("message", "You successfully uploaded " + name + "!"); return "redirect:/files"; } |
Los dos últimos métodos se utilizan para la búsqueda. Simplemente llaman al servicio de búsqueda y añaden el resultado al Modelo de página y lo renderizan.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
@RequestMapping(method = RequestMethod.POST, value = "/fulltext") public String fulltextQuery(@ModelAttribute(value = "name") String query, Model model) throws IOException { List<Map<String, Object>> files = searchService.searchFulltextFiles(query); model.addAttribute("files", files); return "uploadForm"; } @RequestMapping(method = RequestMethod.POST, value = "/n1ql") public String n1qlQuery(@ModelAttribute(value = "name") String query, Model model) throws IOException { List<Map<String, Object>> files = searchService.searchN1QLFiles(query); model.addAttribute("files", files); return "uploadForm"; } |
Y esto es más o menos todo lo que necesitas para almacenar, indexar y buscar archivos con Couchbase y Spring Boot. Es una aplicación simple y hay muchas, muchas otras cosas que podrías hacer para mejorarla, empezando por un formulario de búsqueda adecuado que exponga los campos extraídos de ExifTool. Múltiples cargas de archivos y arrastrar y soltar sería un buen plus. ¿Qué más te gustaría ver? Háznoslo saber en los comentarios.