Recientemente anunciamos el último avance del Operador autónomo de Couchbase (CAO) 2.0 beta. Esta versión es una actualización significativa de Couchbase Autonomous Operator. Couchbase Autonomous Operator 2.0 introduce varias características nuevas de nivel empresarial con capacidades totalmente autónomas: seguridad, monitorización, alta disponibilidad y capacidad de gestión. En este blog, examinaremos en profundidad cómo funciona una de ellas.
Colección de métricas Prometheus
El último operador proporciona integración nativa con Couchbase Prometheus Exporter para recopilar y exponer métricas de Couchbase Server. Prometheus puede extraer estas métricas exportadas y visualizarlas en herramientas como Grafana.
Describiremos los pasos para desplegar el clúster con Couchbase Prometheus Exporter y veremos algunas de las métricas a través de Grafana. Este será un simple despliegue de prueba de un solo clúster y no detallará todos los demás pasos necesarios para un despliegue a nivel de producción.
Seguiremos de cerca la Tutorial de Couchbase Autonomous Operator 2.0 Beta sobre la instalación en Amazon EKS.
Requisitos previos
Supongo que ya tiene un Nube privada virtual de Amazon (VPC) a utilizar. Siga la documentación de Primeros pasos con Amazon EKS e instala lo siguiente:
- kubectl
- aws-iam-authenticator
- eksctl
- Pares de claves de Amazon EC2
- Couchbase Autonomous Operator 2.0 Beta
Arquitectura de implantación
Una rápida visión general de la arquitectura de nuestro despliegue.
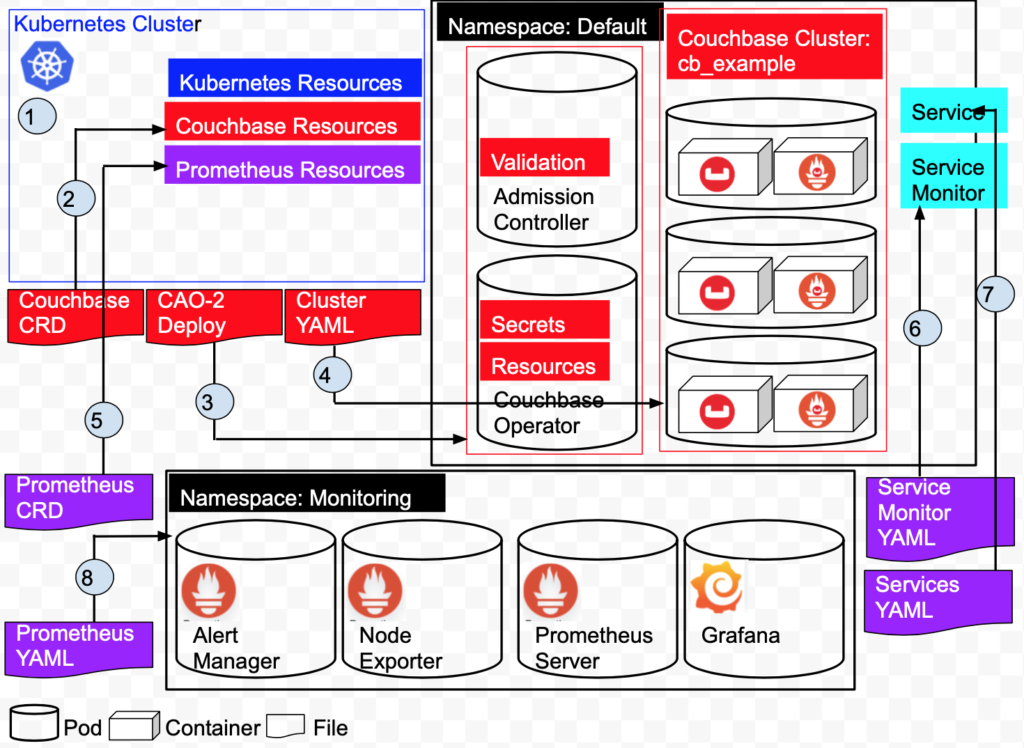
Consulte el diagrama anterior:
1: Cree el clúster de Kubernetes en Amazon EKS. El clúster administra los recursos y servicios de Kubernetes.
2: Añade recursos de Couchbase instalando las definiciones de recursos personalizadas de Couchbase.
3: Instala el Operador Autónomo Couchbase. Esto crea 2 Pods, el Operador y el Controlador de Admisión en el espacio de nombres Default.
4: Despliega un Cluster Couchbase de 3 nodos en el espacio de nombres Default. Esto crea 3 pods, cada pod tiene un contenedor Couchbase 6.5.0 y un contenedor Couchbase Metrics Exporter.
5: Cree un ServiceMonitor que indique a Prometheus que supervise un recurso de servicio que defina los puntos finales que Prometheus rastrea.
6: Crear un Servicio definirá el puerto que describimos anteriormente en nuestro ServiceMonitor en el espacio de nombres Default.
7: Añada recursos de Prometheus instalando las definiciones de recursos personalizadas de Prometheus.
8: Cree los pods Prometheus/Grafana en el espacio de nombres Monitoring.
Crear el clúster y configurar kubectl
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
$ eksctl create cluster \ --name prasadCAO2 \ --region us-east-1 \ --zones us-east-1a,us-east-1b,us-east-1c \ --nodegroup-name standard-workers \ --node-type t3.medium \ --nodes 3 \ --nodes-min 1 \ --nodes-max 4 \ --ssh-access \ --ssh-public-key ~/couchbase-prasad.pub \ --managed [ℹ] eksctl version 0.16.0 [ℹ] using region us-east-1 [ℹ] subnets for us-east-1a - public:192.168.0.0/19 private:192.168.96.0/19 [ℹ] subnets for us-east-1b - public:192.168.32.0/19 private:192.168.128.0/19 [ℹ] subnets for us-east-1c - public:192.168.64.0/19 private:192.168.160.0/19 [ℹ] using SSH public key "/Users/krishna.doddi/couchbase-prasad.pub" as "eksctl-prasadCAO2-nodegroup-standard-workers-42:57:cd:cb:28:33:4a:d9:59:4e:73:3b:c0:e8:a3:fe" [ℹ] using Kubernetes version 1.14 [ℹ] creating EKS cluster "prasadCAO2" in "us-east-1" region with managed nodes [ℹ] will create 2 separate CloudFormation stacks for cluster itself and the initial managed nodegroup [ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=us-east-1 --cluster=prasadCAO2' [ℹ] CloudWatch logging will not be enabled for cluster "prasadCAO2" in "us-east-1" [ℹ] you can enable it with 'eksctl utils update-cluster-logging --region=us-east-1 --cluster=prasadCAO2' [ℹ] Kubernetes API endpoint access will use default of {publicAccess=true, privateAccess=false} for cluster "prasadCAO2" in "us-east-1" [ℹ] 2 sequential tasks: { create cluster control plane "prasadCAO2", create managed nodegroup "standard-workers" } [ℹ] building cluster stack "eksctl-prasadCAO2-cluster" [ℹ] deploying stack "eksctl-prasadCAO2-cluster" [ℹ] building managed nodegroup stack "eksctl-prasadCAO2-nodegroup-standard-workers" [ℹ] deploying stack "eksctl-prasadCAO2-nodegroup-standard-workers" [✔] all EKS cluster resources for "prasadCAO2" have been created [✔] saved kubeconfig as "/Users/krishna.doddi/.kube/config" [ℹ] nodegroup "standard-workers" has 3 node(s) [ℹ] node "ip-192-168-13-207.ec2.internal" is ready [ℹ] node "ip-192-168-62-181.ec2.internal" is ready [ℹ] node "ip-192-168-93-184.ec2.internal" is ready [ℹ] waiting for at least 1 node(s) to become ready in "standard-workers" [ℹ] nodegroup "standard-workers" has 3 node(s) [ℹ] node "ip-192-168-13-207.ec2.internal" is ready [ℹ] node "ip-192-168-62-181.ec2.internal" is ready [ℹ] node "ip-192-168-93-184.ec2.internal" is ready [ℹ] kubectl command should work with "/Users/krishna.doddi/.kube/config", try 'kubectl get nodes' [✔] EKS cluster "prasadCAO2" in "us-east-1" region is ready |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 15m $ kubectl get nodes NAME STATUS ROLES AGE VERSION ip-192-168-13-207.ec2.internal Ready <none> 4d4h v1.14.9-eks-1f0ca9 ip-192-168-62-181.ec2.internal Ready <none> 4d4h v1.14.9-eks-1f0ca9 ip-192-168-93-184.ec2.internal Ready <none> 4d4h v1.14.9-eks-1f0ca9 |
Configurar kubectl
Este comando es vital, ya que establece las variables pertinentes del nombre de recurso de Amazon (ARN) en ~/.kube/config. Opcionalmente, puede añadir --region regionName para especificar un clúster en una región diferente a la predeterminada. (Su región predeterminada debería haberse especificado cuando configuró por primera vez la CLI de AWS a través de aws configuremando).
|
1 2 3 |
$ aws eks update-kubeconfig --name prasadCAO2 Added new context arn:aws:eks:us-east-1:429712224361:cluster/prasadCAO2 to /Users/krishna.doddi/.kube/config |
Instalar las definiciones personalizadas de recursos (CRD)
Nota: He descargado el Operator para MacOS, he renombrado el paquete de couchbase-autonomous-operator-kubernetes_2.0.0-macos-x86_64 a cao-2 y cd'd en este directorio.
El primer paso para instalar el Operador es instalar las definiciones de recursos personalizadas (CRD) que describen los tipos de recursos de Couchbase.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
cao-2 $ kubectl create -f crd.yaml customresourcedefinition.apiextensions.k8s.io/couchbasebuckets.couchbase.com created customresourcedefinition.apiextensions.k8s.io/couchbaseephemeralbuckets.couchbase.com created customresourcedefinition.apiextensions.k8s.io/couchbasememcachedbuckets.couchbase.com created customresourcedefinition.apiextensions.k8s.io/couchbasereplications.couchbase.com created customresourcedefinition.apiextensions.k8s.io/couchbaseusers.couchbase.com created customresourcedefinition.apiextensions.k8s.io/couchbasegroups.couchbase.com created customresourcedefinition.apiextensions.k8s.io/couchbaserolebindings.couchbase.com created customresourcedefinition.apiextensions.k8s.io/couchbaseclusters.couchbase.com created customresourcedefinition.apiextensions.k8s.io/couchbasebackups.couchbase.com created customresourcedefinition.apiextensions.k8s.io/couchbasebackuprestores.couchbase.com created |
Instalar el Operador Autónomo 2.0
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
cao-2 $ bin/cbopcfg | kubectl create -f - serviceaccount/couchbase-operator-admission created clusterrole.rbac.authorization.k8s.io/couchbase-operator-admission created clusterrolebinding.rbac.authorization.k8s.io/couchbase-operator-admission created secret/couchbase-operator-admission created deployment.apps/couchbase-operator-admission created service/couchbase-operator-admission created mutatingwebhookconfiguration.admissionregistration.k8s.io/couchbase-operator-admission created validatingwebhookconfiguration.admissionregistration.k8s.io/couchbase-operator-admission created serviceaccount/couchbase-operator created role.rbac.authorization.k8s.io/couchbase-operator created rolebinding.rbac.authorization.k8s.io/couchbase-operator created deployment.apps/couchbase-operator created service/couchbase-operator created |
Comprobar el estado del Operador
|
1 2 3 4 5 |
cao-2 $ kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE couchbase-operator 1/1 1 1 96s couchbase-operator-admission 1/1 1 1 97s |
El Operador está listo para desplegar recursos CouchbaseCluster cuando tanto el Controlador Dinámico de Admisión (couchbase-operator-admission) como el Operador (couchbase-operator) están completamente listos y disponibles.
Preparar la configuración del clúster Couchbase
Voy a desplegar un cluster de 3 nodos de Couchbase Server 6.5.0 con Prometheus Couchbase Exporter. Para ello, he creado mi-cluster.yaml en el directorio actual. Este es sólo mi ejemplo. Aquí está el archivo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
apiVersion: v1 kind: Secret metadata: name: cb-example-auth type: Opaque data: username: QWRtaW5pc3RyYXRvcg== # Administrator password: cGFzc3dvcmQ= # password --- apiVersion: couchbase.com/v2 kind: CouchbaseCluster metadata: name: cb-example spec: image: couchbase/server:6.5.0 security: adminSecret: cb-example-auth paused: false antiAffinity: true softwareUpdateNotifications: true serverGroups: - us-east-1a - us-east-1b - us-east-1c securityContext: runAsUser: 1000 runAsNonRoot: true fsGroup: 1000 platform: aws cluster: clusterName: cb-example dataServiceMemoryQuota: 512Mi indexServiceMemoryQuota: 256Mi searchServiceMemoryQuota: 256Mi indexStorageSetting: memory_optimized autoFailoverTimeout: 120s autoFailoverMaxCount: 3 autoFailoverOnDataDiskIssues: true autoFailoverOnDataDiskIssuesTimePeriod: 120s autoFailoverServerGroup: false autoCompaction: databaseFragmentationThreshold: percent: 30 size: 1Gi viewFragmentationThreshold: percent: 30 size: 1Gi parallelCompaction: false timeWindow: start: 02:00 end: 06:00 abortCompactionOutsideWindow: true tombstonePurgeInterval: 72h servers: - size: 3 name: all_services services: - data - index - query - search buckets: managed: false selector: matchLabels: cluster: cb-example monitoring: prometheus: enabled: true image: couchbase/exporter:1.0.1 resources: requests: cpu: 100m memory: 100Mi |
Notas:
- Sólo he utilizado un conjunto mínimo de parámetros de configuración. Consulte la Documentación de recursos del clúster Couchbase para obtener una lista completa.
- Incluí la sección de secretos en el mismo archivo para simplificar las cosas.
- Sólo se utilizan los servicios de Datos, Consulta, Índice y Búsqueda.
- Gestionar mis propios cubos en lugar de dejárselo al Operador.
- Anote la etiqueta de la agrupación cb-ejemplo ya que Prometheus lo utilizará más tarde para descubrir el servicio.
Consejo: Asegúrese de que buckets.managed está establecido en false. De lo contrario, si crea un bucket manualmente una vez que el clúster esté en funcionamiento, Kubernetes lo eliminará automáticamente.
Despliegue del clúster Couchbase
|
1 2 3 4 |
cao-2 $ kubectl create -f my-cluster.yaml secret/cb-example-auth created couchbasecluster.couchbase.com/cb-example created |
Tanto el secreto como el cluster están creados. Esto no significa que estén funcionando todavía, para ello tendrás que verificarlo como se describe en el siguiente paso.
Verificar la implantación
|
1 2 3 4 5 6 7 8 |
cao-2 $ kubectl get pods NAME READY STATUS RESTARTS AGE cb-example-0000 2/2 Running 0 9m5s cb-example-0001 2/2 Running 0 8m53s cb-example-0002 2/2 Running 0 8m42s couchbase-operator-5c4bd54bbf-fcj9m 1/1 Running 0 10m couchbase-operator-admission-6789cd5847-w9rfd 1/1 Running 0 10m |
Asegúrese de que todas las vainas están Listo y Ejecutar. En caso de que haya algún problema, puede obtener los registros del Operador.
Opcional: Obtener los registros
Si encuentra algún problema en el paso anterior, puede comprobar los registros como se muestra a continuación.
|
1 2 3 4 5 6 7 8 |
cao-2 $ kubectl logs couchbase-operator-5c4bd54bbf-fcj9m {"level":"info","ts":1586879846.061044,"logger":"main","msg":"couchbase-operator","version":"2.0.0","revision":"release"} ...... {"level":"info","ts":1586879986.2216492,"logger":"cluster","msg":"Pod added to cluster","cluster":"default/cb-example","name":"cb-example-0002"} {"level":"info","ts":1586879987.0798743,"logger":"couchbaseutil","msg":"Rebalancing","cluster":"default/cb-example","progress":0} {"level":"info","ts":1586879993.087347,"logger":"cluster","msg":"Rebalance completed successfully","cluster":"default/cb-example"} {"level":"info","ts":1586879993.124682,"logger":"cluster","msg":"Reconcile completed","cluster":"default/cb-example"} |
Aquí, el clúster Couchbase desplegado sin ningún error.
Opcional: Examine un pod de Couchbase.
Vamos a describir un pod de Couchbase para comprobar qué está ejecutando.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
cao-2 $ kubectl describe pod cb-example-0000 Name: cb-example-0000 Namespace: default ... Labels: app=couchbase couchbase_cluster=cb-example ... {"containers":[{"name":"couchbase-server","image":"couchbase/server:6.5.0","ports":[{"name":"admin","containerPort":8091,"protocol":"TCP"} ... server.couchbase.com/version: 6.5.0 Status: Running ... Controlled By: CouchbaseCluster/cb-example Containers: couchbase-server: Container ID: docker://7b0e5df433582ad432114248fdce922fd92f63435b110265b823c013fea8c2ac Image: couchbase/server:6.5.0 ... State: Running ... metrics: Container ID: docker://b4406ec41d2119978971c8fa41fb8077ace782611298ba23d254a0d4383ab5ca Image: couchbase/exporter:1.0.0 Image ID: ... Port: 9091/TC ... State: Running |
De la salida anterior, vemos que cada pod Couchbase está ejecutando 2 contenedores. El primero está ejecutando Couchbase Server 6.5.0 y el otro está ejecutando Couchbase Prometheus Exporter que está utilizando el puerto 9091.
Acceder a la interfaz de administración de Couchbase
En un entorno de producción real, normalmente desplegarías usando DNS y un LoadBalancer actuando como proxy y accederías a Couchbase UI de forma segura, con SSL usando registros DNS SRV. Como estamos en un entorno de pruebas, accederemos a Couchbase UI directamente desde el puerto 8091. Necesitamos un paso más para conseguirlo y es el Port Forwarding.
Reenvío de puertos
|
1 2 3 4 |
cao-2 $ kubectl port-forward cb-example-0000 8091 & [1] 11375 cao-2 $ Forwarding from 127.0.0.1:8091 -> 8091 Forwarding from [::1]:8091 -> 8091 |
Ahora hemos desplegado tres pods, sin embargo, es suficiente con hacer un port forward desde un pod para acceder a la Couchbase Admin UI.
Acceder a la interfaz de usuario

https://localhost:8091
Crear los cubos

Añadir cubo de muestras y crear cubo de almohadas
Ejecutar una carga de trabajo para generar algunas métricas
Utilizaremos cbc-pillowfight para generar la carga de trabajo. Afortunadamente, esto se incluye junto con el Operador y vamos a desplegarlo. Vamos a hacer una pequeña modificación en el archivo YAML primero, de modo que no se detiene con la carga de los datos, pero realiza operaciones en el cubo. Usaremos el cubo almohada que acabamos de crear.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
apiVersion: batch/v1 kind: Job metadata: name: pillowfight spec: template: metadata: name: pillowfight spec: containers: - name: pillowfight image: sequoiatools/pillowfight:v5.0.1 command: ["cbc-pillowfight", "-U", "couchbase://cb-example-0000.cb-example.default.svc/pillow?select_bucket=true", "-I", "10000", "-B", "1000", "-c", "10000", "-t", "1", "-u", "Administrator", "-P", "password"] restartPolicy: Never |
Cambia el cubo de predeterminado a almohada y cambia la opción -c (número de bucles) de 10 a 10.000.
Entonces:
|
1 2 |
cao-2 $ kubectl create -f pillowfight-data-loader.yaml job.batch/pillowfight created |
Pruebas locales de Prometheus y Grafana
Ahora tenemos un Cluster Couchbase de tres nodos con el Prometheus Couchbase Exporter. El exportador está enviando las métricas de Couchbase al puerto 9091. Ahora, podríamos reenviar ese puerto al igual que reenviamos el puerto 8091 para acceder a la interfaz de usuario de la consola web de Couchbase desde nuestro escritorio. Con ese puerto redireccionado, podríamos tener Prometheus y Grafana ejecutándose en contenedores Docker en el escritorio y utilizar el puerto 9091 redireccionado para obtener las métricas en Prometheus y visualizarlas en Grafana.
Este planteamiento tiene una limitación. En primer lugar, tendríamos que reenviar el puerto 9091 desde los 3 nodos y esos nombres de nodo estarían codificados. Hardcoding nombres de nodo es un gran problema en un entorno Kubernetes. Por otra parte, usted realmente no estaría haciendo el reenvío de puertos en un entorno de producción, donde normalmente se despliega con DNS y utilizaría el DNS SRV para conectarse al clúster. Por último, su mejor práctica para ejecutar Prometheus y Grafana en Kubernetes sí mismo, alineando con el paradigma nativo de la nube.
Próximos pasos
En Parte 2Vamos a hacer precisamente eso, aparte del DNS, ya que queremos que sea lo más sencillo posible para realizar pruebas rápidas.
Recursos:
- Descargar Couchbase Autonomous Operator 2.0 Beta para Kubernetes
- Introducción a Couchbase Autonomous Operator 2.0 Beta
- Tutorial - Operador autónomo de Couchbase en EKS
- Comparta su opinión sobre el Foros de Couchbase
Gracias Prasad por compartir. ¿Puedo preguntar cuáles son las métricas clave para monitorear para decidir cuándo escalar el clúster y es posible configurar el auto-escalado de clúster couchbase en K8s?
Saludos