En el vertiginoso entorno actual, la capacidad de acceder rápidamente a los datos, comprenderlos y actuar en consecuencia ya no es un lujo, sino una necesidad. Sin embargo, muchas organizaciones se encuentran con que, aunque son ricas en datos, la obtención de información oportuna y procesable sigue siendo un reto importante, sobre todo para los usuarios empresariales no técnicos.
Además, los usuarios técnicos necesitan entender sus datos para saber qué consultas construir para obtener los resultados, lo que requiere mucho tiempo y esfuerzo y no está a un solo clic de permitir al usuario preguntar lo que tiene en mente en un lenguaje natural sencillo.
Además, el usuario tiene que dedicar tiempo a entender los datos, incluso con las visualizaciones. A menudo se plantea la cuestión del "por qué" cuando se presentan los datos, y los datos sin el crucial "por qué" dejan un vacío entre la presentación de los datos y su verdadera comprensión. En esencia, la analítica empresarial de autoservicio sigue siendo difícil de alcanzar.
¿Qué es Polaris?
Polaris es una interfaz conversacional multiagente impulsada por IA creada para analizar datos en nuestra base de datos Couchbase Operational. Polaris aprovecha una arquitectura multiagente que permite a los usuarios interactuar con sus datos empresariales a través de una interfaz intuitiva y conversacional, transformando el análisis de datos complejos en un diálogo sencillo. Por ejemplo, si una empresa dispone de datos de ventas empresariales globales en varias regiones y líneas de productos, y un analista de negocio desea comprender "¿Por qué disminuyeron las ventas del producto X en el segundo trimestre en la región noreste?".nuestra aplicación puede ejecutar de forma autónoma todo el flujo de trabajo de análisis.
Recupera y filtra los datos de ventas pertinentes por región, producto y periodo de tiempo, compara las tendencias de rendimiento entre regiones o productos comparables, visualiza patrones y anomalías clave y genera un informe narrativo que resume las causas fundamentales, como la reducción del gasto promocional, los problemas de disponibilidad de existencias o un cambio en el comportamiento de los clientes. Para hacerlo aún más interesante, el analista de negocio puede hacer una pregunta de seguimiento para entender en detalle alguna parte del informe o pedir más visualizaciones, lo que permite una rápida toma de decisiones basada en datos.
Abordemos ahora el tema más candente: los agentes de IA.
¿Qué son los agentes de IA y cuáles son sus capacidades?
Los agentes de IA son sistemas autónomos impulsados por inteligencia artificial, que suelen incluir grandes módulos de lenguaje (LLM) que pueden realizar tareas, tomar decisiones e interactuar con entornos del mundo real, a menudo sin supervisión humana constante. A diferencia de los chatbots tradicionales o los programas basados en reglas, los agentes de IA también aprenden de su experiencia. El objetivo de un agente es que haga todo lo que hace un operador humano de forma autónoma y automática. Todavía es un objetivo lejano, pero la industria de la IA está avanzando hacia él. Veamos ahora las capacidades de los Agentes de IA:
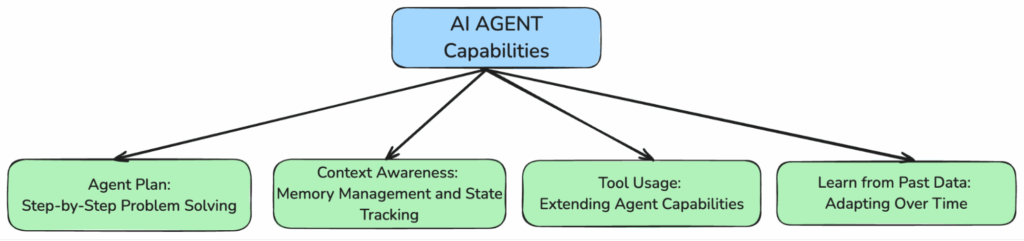
Plan Agente: Solución de problemas paso a paso
Los agentes de IA dividen las tareas complejas en pasos claros y manejables: identifican el problema, ejecutan cada fase y realizan los ajustes necesarios. En los sistemas multiagente, cada agente puede encargarse de una tarea específica, lo que permite resolver problemas de forma eficaz y coordinada.
Conocimiento del contexto: Gestión de memoria y seguimiento de estados
Los agentes mantienen el contexto a través de las interacciones, recordando entradas anteriores y adaptándose a los flujos de trabajo en curso. Este seguimiento del estado crea experiencias de usuario más naturales, coherentes e inteligentes.
Uso de herramientas: Ampliación de las capacidades del agente
Los agentes pueden interactuar con herramientas externas -API, bases de datos, scripts- para realizar acciones reales, no sólo ofrecer sugerencias. Esto los transforma de asistentes pasivos en ejecutores activos dentro de los flujos de trabajo.
Aprender de los datos del pasado: Adaptación a lo largo del tiempo
Al analizar los datos históricos y el comportamiento, los agentes mejoran con el tiempo: anticipan las necesidades de los usuarios, perfeccionan las respuestas y optimizan los flujos de trabajo en función de los patrones de uso.
¿Qué es un sistema multi-agente (MAS)?
La arquitectura multiagente es un diseño de sistema en el que varios agentes independientes trabajan juntos para resolver problemas o realizar tareas. Cada agente tiene su propia función, como recopilar datos, analizar información o tomar decisiones. Estos agentes se comunican y colaboran para alcanzar un objetivo común, lo que hace que el sistema esté más organizado. Es como un equipo en el que cada miembro hace un trabajo específico, pero todos trabajan para conseguir el mismo resultado. Hemos utilizado la arquitectura multiagente para Polaris.
¿Por qué se ha abandonado la arquitectura de agente único?
Un único agente de IA opera de forma independiente, gestionando tareas específicas de forma autónoma. Esto funciona bien para aplicaciones sencillas, como un sistema de Generación Mejorada de Recuperación (RAG), en el que un agente responde a las consultas del usuario basándose en un LLM y un conocimiento. Sin embargo, en las aplicaciones prácticas, las interacciones con el usuario rara vez son sencillas. A menudo implican una lógica compleja, un razonamiento en varios pasos y la necesidad de trabajar con modelos de datos dinámicos y requisitos empresariales cambiantes. En este punto, los sistemas de agente único empiezan a alcanzar límites de rendimiento y escalabilidad. Pueden flaquear al encadenar varias operaciones, adaptarse a los cambios de esquema o coordinar flujos de trabajo matizados.
¿Por qué funcionan las arquitecturas multiagente (MAS)?
La separación de intereses inherente al diseño de MAS da lugar a sistemas más robustos y fáciles de mantener. Cada agente se centra en su tarea específica, lo que reduce la complejidad y facilita la identificación y resolución de problemas. Este enfoque brilla en escenarios como el control autónomo de vehículos, donde agentes separados se ocupan de la navegación, la detección de obstáculos y la dinámica del vehículo, lo que permite centrar el desarrollo y la resolución de problemas en cada área.
Supervisor frente a sistemas multiagente en red

Arquitectura multiagente descentralizada (entre iguales)

Elegimos: Arquitectura basada en supervisores
Nuestra aplicación utiliza el Agente supervisor LangGraph:
-
- Razonamiento centralizado, consistencia y coherencia
- El razonamiento complejo se beneficia de tener una visión global de los datos, la intención del usuario y el contexto. El supervisor puede mantener una lógica coherente en múltiples pasos.
- Un único punto de decisión garantiza que los resultados estén alineados (por ejemplo, el gráfico coincide con la explicación, el resumen refleja el análisis).
- El control central permite la asignación dinámica de tareas a subagentes especializados (por ejemplo, generador de gráficos, agente de consulta). Evita la duplicación de esfuerzos y optimiza el uso de recursos.
- Recuperación de errores y escalabilidad más sencillas
- Los errores pueden detectarse y gestionarse de forma centralizada. El supervisor puede reintentar tareas, reasignar funciones o generar respuestas alternativas.
- El control central permite la asignación dinámica de tareas a subagentes especializados (por ejemplo, generador de gráficos, agente de consulta). Evita la duplicación de esfuerzos y optimiza el uso de recursos.
- Más facilidad para añadir, sustituir o actualizar subagentes sin rediseñar todo el sistema.
- Razonamiento centralizado, consistencia y coherencia
Núcleo Polaris
En esencia, Polaris utiliza una red de agentes de IA especializados, cada uno de ellos optimizado para diferentes aspectos del ciclo de vida de la interacción de datos. Veamos ahora cuáles son los componentes y la arquitectura multiagente de alto nivel de Polaris con la ayuda de un ejemplo:
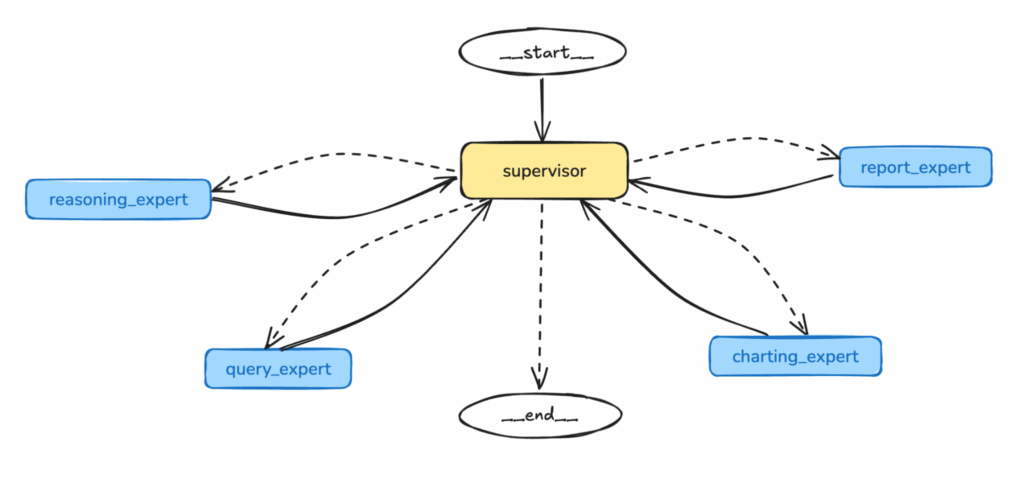
Comprensión y orquestación: Agente supervisor
En Agente supervisor actúa como controlador central y orquestador inteligente del sistema multiagente.
Funciones:
-
- Análisis de intenciones: Analizar los datos introducidos por el usuario y extraer las intenciones y parámetros relacionados con la tarea.
- Ejemplo: El usuario pregunta: "¿Por qué bajaron las ventas totales de productos electrónicos en el primer trimestre de 2024 en la región APAC?". El Agente Supervisor lo analiza para identificar la Intención: "Razón- análisis causal de la caída de ventas", Categoría de Producto: "Electrónica", Periodo de tiempo: "Q1 2024" , Región: "APAC".
- Lógica de enrutamiento de agentes: Implementa un motor de decisión o una capa de orquestación basada en reglas para dirigir las tareas a los agentes apropiados.
- Ejemplo: Basándose en la intención analizada "análisis causal para la caída de ventas" el Agente Supervisor decide enrutar primero la tarea al Experto en Consultas para obtener los datos de ventas, después al Experto en Gráficos para su visualización, después al agente de razonamiento para la identificación causal, finalmente al Experto en Informes para su resumen.
- Gestión del contexto: Mantiene el contexto y el estado global de la conversación.
- Tratamiento de errores y recuperación: Supervisa el éxito/fracaso de las tareas y puede reasignar o reformular subtareas en función de los comentarios de los agentes.
- Ejemplo: Si el Experto en Consultas informa de que una columna solicitada, Tipo_de_producto, no existe en el esquema, el Agente Supervisor podría redirigir la petición al Experto en Razonamiento para sugerir columnas relevantes alternativas o informar al usuario sobre los datos que faltan.
- Análisis de intenciones: Analizar los datos introducidos por el usuario y extraer las intenciones y parámetros relacionados con la tarea.
Extracción de datos relevantes: Experto en consultas
El Experto en Consultas traduce las preguntas en lenguaje natural a SQL++ , obteniendo así los datos necesarios.
Funciones:
-
- Inferencia de esquemas y anotaciones: Infiere el esquema de datos utilizando el comando INFER de SQL++ que obtiene los nombres de las columnas, el tipo de datos de las columnas y los documentos de muestra, esto junto con la ayuda de anotaciones ayuda a comprender los datos, las relaciones entre tablas, los tipos de datos y las restricciones.
- Ejemplo: Cuando SQL++ INFER se ejecuta en una colección, puede identificar un campo simplemente como "importe": NÚMERO. Sin más contexto, el experto en consultas no sabría si esto se refiere a importe_venta, importe_descuentoo cantidad. Sin embargo, a través de anotaciones, se le dice explícitamente a Polaris: "importe" campo en 'ventas_empresa' colección representa 'importe total de las ventaspara una transacción. Esta anotación es crucial porque cuando el usuario pregunta "ventas totales", el Experto en Consultas mapea ahora con confianza ventas a la importe generando correctamente SUMA(importe).
- Canonicalización de entradas: Transforma la entrada original en lenguaje natural del usuario en una forma más verbosa, inequívoca y estructurada. Esto ayuda a la herramienta de CI a comprender mejor la tarea.
- Ejemplo: Entrada del usuario: "ventas el mes pasado." Entrada canonizada: "Recuperar el importe total de ventas de la categoría "Electrónica" de los últimos 30 días a partir de la fecha actual.“
- Traducción de NL a SQL++: Llamada a la herramienta IQ para convertir NL a SQL++
- Comprobación de la calidad de los datos y recuperación de errores: el agente inspecciona los valores nulos y otros problemas de integridad de los datos que podrían afectar a la interpretación. Si la calidad de los datos es deficiente (por ejemplo, todos los NULL en una columna), el agente reformula la consulta o devuelve una advertencia para que intervenga el usuario. Basándose en el diagnóstico de errores, el agente ajusta automáticamente la consulta (por ejemplo, corrige los nombres de las columnas o limita el tamaño de los resultados) y reintenta la ejecución de forma inteligente.
- Ejemplo: Si el importe_venta puede contener nulos, el Experto en Consultas los añade automáticamente: AND importe_venta IS NOT NULL a la consulta generada para garantizar la exactitud de los cálculos de suma.
- Inferencia de esquemas y anotaciones: Infiere el esquema de datos utilizando el comando INFER de SQL++ que obtiene los nombres de las columnas, el tipo de datos de las columnas y los documentos de muestra, esto junto con la ayuda de anotaciones ayuda a comprender los datos, las relaciones entre tablas, los tipos de datos y las restricciones.
Generación de ideas: Experto en gráficos
Se encarga de convertir los resultados de las consultas estructuradas en representaciones visuales significativas, adaptadas a la naturaleza de los datos y a la consulta del usuario.
Funciones:
-
- Lógica de selección de gráficos: Utiliza la heurística basada en reglas para seleccionar los tipos de gráficos adecuados en función de las características de los datos (por ejemplo, dimensiones, métricas, series temporales).
- Ejemplo: En base a las reglas dadas en el prompt y el tipo de datos, el experto elegirá un gráfico apropiado, por ejemplo si son datos de ventas y series temporales donde necesitamos identificar alguna tendencia, seleccionará un gráfico de líneas.
- Generación dinámica de visualizaciones: Construye visualizaciones utilizando bibliotecas como Plotly y Seaborn.
- Lógica de selección de gráficos: Utiliza la heurística basada en reglas para seleccionar los tipos de gráficos adecuados en función de las características de los datos (por ejemplo, dimensiones, métricas, series temporales).
Informes y resúmenes: Experto en informes
Recopila información, visualizaciones y contexto en informes estructurados.
Funciones:
-
- Agregación de contenidos: Resume automáticamente los resultados de la consulta, incorpora visualizaciones, la metodología e incluye metadatos (por ejemplo, fuentes de datos, parámetros de consulta).
- Control de versiones y registros de auditoría: Integra opcionalmente el control de versiones y el registro para el cumplimiento y la trazabilidad de los informes generados.
Explicación y razonamiento: Experto en razonamiento
Proporciona razonamiento causal, análisis de tendencias y generación de hipótesis mediante la interpretación de datos a través de la lente del conocimiento del dominio y la inferencia lógica.
Funciones:
-
- Razonamiento basado en LLM: Aprovecha los LLM para razonar sobre los resultados de los datos, descubrir patrones latentes y generar narrativas explicativas.
- Aumento contextual: Utiliza conocimientos específicos del dominio extraídos de la base de datos del usuario para proporcionar explicaciones fundamentadas.
Flujo de trabajo
La plataforma Polaris está diseñada para convertir preguntas en lenguaje natural en información inteligente y multimodal mediante la organización de un equipo de agentes especializados. Así es como se desarrolla el flujo de trabajo:
- Inicialización del sistema Polaris
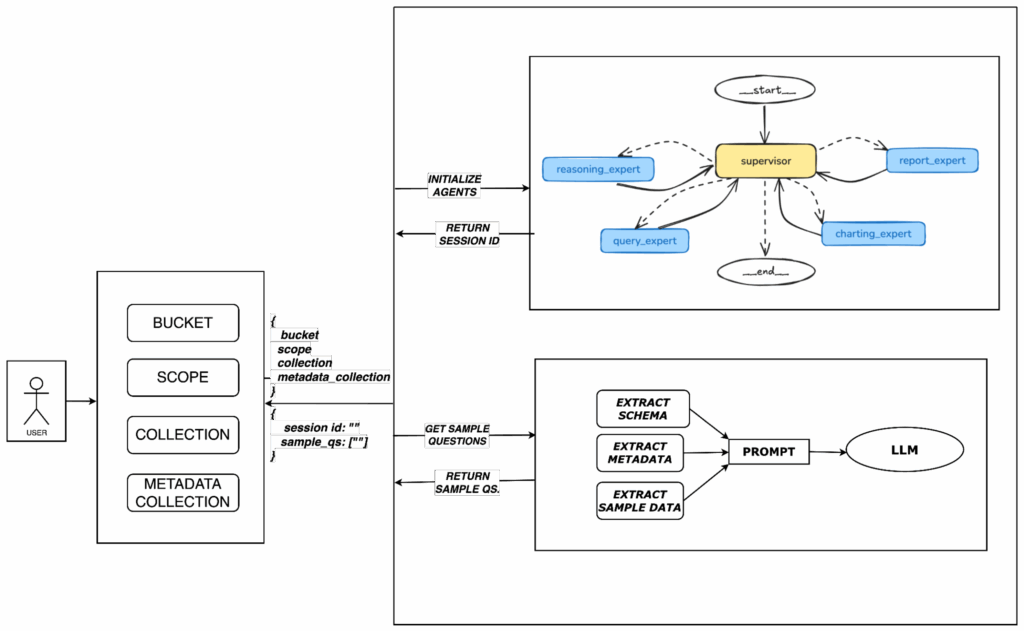 El usuario comienza seleccionando el cubo, ámbito, recopilación y recogida de metadatos. Basándose en este contexto, Polaris inicializa agentes especializados y utiliza el esquema, los metadatos y los datos de muestra para impulsar un LLM, que genera preguntas de ejemplo para guiar la exploración del usuario.
El usuario comienza seleccionando el cubo, ámbito, recopilación y recogida de metadatos. Basándose en este contexto, Polaris inicializa agentes especializados y utiliza el esquema, los metadatos y los datos de muestra para impulsar un LLM, que genera preguntas de ejemplo para guiar la exploración del usuario.
- Interacción con el lenguaje natural

- Procesamiento inteligente de consultas
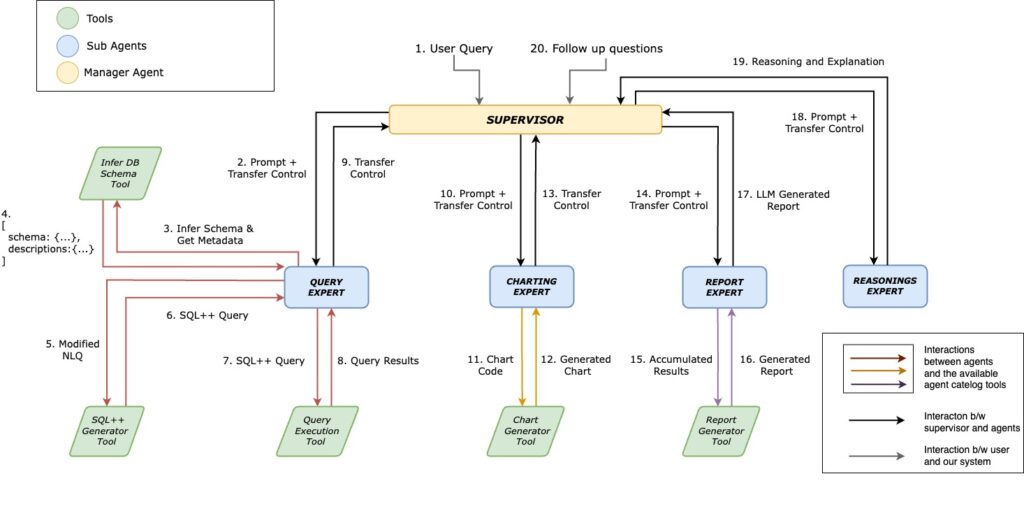
Diagrama de diseño de alto nivel
- En Experto en consultas se encarga de las principales tareas de acceso a los datos: inferir el esquema, traducir la consulta en lenguaje natural a SQL++ mediante una herramienta generadora y ejecutar la consulta.
- Entre las herramientas de apoyo al Query Expert se incluyen las siguientes Herramienta de inferencia de esquemas, Herramienta generadora de SQLy Herramienta de ejecución de consultas.
- Generación de respuestas polifacéticas
Basándose en los resultados de la consulta inicial, el Supervisor coordina:- En Experto en gráficosque crea visualizaciones de datos mediante un Herramienta de generación de gráficos.
- En Informe Expertoresponsable de generar resúmenes textuales utilizando un Herramienta generadora de informes.
- En Experto en razonamientoque añade contexto, fundamentos o explicaciones adicionales para enriquecer la respuesta.
- Información exhaustiva
Polaris sintetiza los resultados estructurados de la consulta, los resultados visuales y las explicaciones narrativas en una respuesta coherente y fácil de usar. Esta información multimodal se devuelve a través de la interfaz de chat, combinando claridad, profundidad e interactividad. - Exploración iterativa
Se anima a los usuarios a hacer preguntas de seguimiento. Dado que el sistema conserva el contexto y el estado a lo largo de la sesión, la red de agentes puede basarse en interacciones anteriores para realizar una exploración profunda e iterativa de los datos.


Utilización de los agentes ReAct
¿Qué es un agente ReAct?
"Un agente ReAct es un agente de IA que utiliza el marco de "razonamiento y actuación" (ReAct) para combinar el razonamiento de la cadena de pensamiento (CoT) con el uso de herramientas externas. El marco ReAct mejora la capacidad de un gran modelo de lenguaje (LLM) para manejar tareas complejas y la toma de decisiones en flujos de trabajo agénticos".Dave Bergmann, IBM
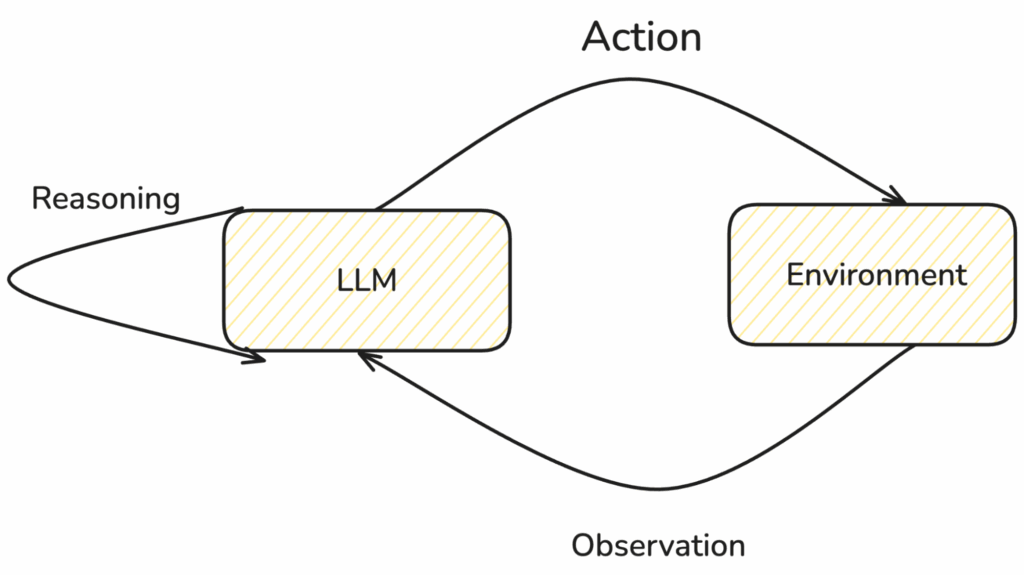
Funcionamiento de un agente ReAct
A diferencia de los sistemas tradicionales de Inteligencia Artificial (IA), los agentes ReAct no separan la toma de decisiones de la ejecución de tareas. Este marco crea intrínsecamente un bucle de retroalimentación en el que el modelo resuelve los problemas repitiendo iterativamente este proceso intercalado. pensamiento-acción-observación proceso. Utilizamos el LangGraph ReAct incorporado en nuestra aplicación, y cada uno de los expertos se modela como un agente ReAct.
Los arquitectos invisibles: el poder de las indicaciones eficaces en el análisis de datos basado en IA
En el ámbito del análisis de datos, la atención se centra a menudo en algoritmos, modelos estadísticos y técnicas de visualización. Sin embargo, detrás de cada gráfico perspicaz, cada informe bien estructurado y cada conclusión basada en datos hay un aspecto crucial que pasa desapercibido: la indicación.
Lista de tareas pendientes
Los avisos de listas de tareas proporcionan al modelo una lista de tareas persistente y estructurada a la que se remite en cada paso. En lugar de basarse en la memoria o en mensajes anteriores, el plan completo se inyecta en cada aviso. De este modo, el agente tiene una idea clara de todas las tareas que debe realizar. Así se evitan los desvíos, las repeticiones y la omisión de pasos.
Indicación de identidad
La indicación de identidad le dice al modelo qué esno sólo lo que debe hacer. Esto establece un papel o personaje coherente que influye en la forma en que el modelo se comporta y responde. Prompts como "Eres muy competente en tareas de visualización de datos". puede desencadenar al instante un comportamiento específico del dominio: respuestas claras, seguras y centradas.
Sugerencias para la autorreflexión
Las instrucciones de autorreflexión obligan al modelo a evaluar sus propios resultados tras completar una tarea. De este modo, el modelo puede hacer una introspección y verificar si ha alcanzado el objetivo del usuario, y hacer correcciones si es necesario. En nuestra aplicación, hemos implementado la solicitud de autorreflexión en el módulo Agente experto en consultas. Una vez generada y ejecutada la consulta SQL, el agente comprueba si están presentes todos los puntos de datos necesarios.
La orientación es más un arte que una ciencia: no existe una fórmula única. Sin embargo, aplicando una heurística probada y un marco de tareas claro, podemos guiar a los modelos hacia resultados más precisos, útiles y conscientes del contexto. La clave es la experimentación, la iteración y el aprendizaje de lo que funciona mejor en su aplicación específica.
Demostración de Polaris, la interfaz conversacional multiagente
Retos y trabajo futuro
Polaris representa un cambio de paradigma en la forma en que las organizaciones pueden aprovechar sus activos de datos, especialmente a través de interacciones de lenguaje natural, lo que permite el descubrimiento intuitivo de datos y acelera significativamente la toma de decisiones. Un gran avance ha sido nuestro desarrollo de una arquitectura multiagente dinámica que adapta su enfoque en función del contexto y puede trabajar con diversos conjuntos de datos.
Sin embargo, aún quedan varios retos pendientes. Uno de ellos es la gestión de las anotaciones de datos. Garantizar anotaciones coherentes y significativas en diversas columnas es fundamental para mantener la calidad de los conocimientos generados por los agentes de IA. Podríamos estudiar la posibilidad de integrarnos en un catálogo global de datos para facilitar esta tarea. Otro reto importante es la limpieza de los datos. Aunque mitigamos algunos de estos problemas en el nivel de consulta mediante cláusulas condicionales y una limpieza básica de los datos, aún hay margen de mejora en la validación y el preprocesamiento de los datos.
Además, la recuperación de datos a gran escala ha sido un obstáculo técnico. En el mundo real, los conjuntos de datos recuperados suelen superar los límites de la ventana contextual de los grandes modelos lingüísticos actuales. Para solucionar este problema, realizamos operaciones de agregación y generamos resúmenes visuales, como gráficos, para proporcionar información de alto nivel sin sobrecargar el modelo.
De cara al futuro, el trabajo se centrará en mejorar los procesos de anotación, mejorar la gestión de la calidad de los datos y explorar métodos más eficaces de resumen y colaboración entre agentes para ampliar aún más Polaris.
Conclusión: el comienzo de una nueva era de interacción de datos
Polaris es algo más que una nueva herramienta: al combinar la potencia de un sistema de IA multiagente con la sencillez de una conversación en lenguaje natural, Polaris democratiza el acceso a los datos, capacita a los usuarios empresariales y acelera el proceso que va de los datos a la toma de decisiones. Creemos que Polaris aportará un valor significativo a nuestros clientes, fomentando una empresa más ágil, más informada sobre los datos y más competitiva.
