Nos complace anunciar que el lanzamiento de Couchbase Cloud 1.6 viene con una serie de mejoras clave, sobre todo en la importación de datos.
Entre estas mejoras se incluye la importación de documentos mediante el Nube Couchbase Interfaz web con varias opciones de generación y configuración de claves. Se trata de una forma sencilla de importar rápidamente conjuntos de datos pequeños, normalmente de menos de 100 MB, en diversos formatos. Se trata de una ampliación de lo familiar cbimport herramientay aprovecha aún más las tecnologías nativas de la nube, como el almacenamiento local S3.
La nueva función Importar forma parte de una estrategia de migración de datos, de la nube a la nube, además de Backup/Restore y XDCR.
En esta entrada de blog, veremos algunos casos de uso y algunos "gotcha "s durante la Importación con Couchbase Cloud. Esto no pretende ser una mirada exhaustiva en profundidad a todas las características; para ello, consulte nuestra excelente documentación sobre Couchbase Cloud.
Resumen de funciones
Echemos un vistazo rápido a la lista de características de Couchbase Cloud 1.6:
| Función | Operación |
|---|---|
| Expresión de generación de claves personalizadas - El mismo formato familiar que la herramienta cbimport - O elija UUID generado automáticamente Comprobar la clave generada - Pegue un documento JSON de ejemplo en la interfaz de usuario y examine visualmente la clave generada Opciones de configuración - Saltar documentos - Documentos límite - Ignorar campos en documentos importados - Además CSV - Inferir tipos de campo - Además CSV - Omitir tipos vacíos |
Importaciones asíncronas y concurrentes - Continúa con otra actividad mientras se importan tus datos en segundo plano Notificación por correo electrónico - Reciba una notificación por correo electrónico cuando finalice la importación. Múltiples métodos para cargar archivos - A través del navegador web - Directamente a S3 a través de cURL Almacenamiento local de archivos importados - Reimportación sin recarga Importar historial de actividades - Audite su actividad de importación Conservación del registro de importación - Facilitar la resolución de problemas |
El conjunto de datos de ejemplo
Para ilustrar algunas de las funciones, utilizaremos documentos decididamente pequeños (sólo tres) y decididamente artificiosos. Dado que Importar le permite importar datos de una variedad de formatos de archivo, un rápido repaso de lo que estos tipos de archivo son:
-
- Lista JSON
- Una lista JSON es una lista (indicada mediante corchetes) de cualquier número de objetos JSON (indicados mediante llaves) separados por comas.
- Líneas JSON
- Líneas JSON es un archivo donde cada línea tiene un objeto JSON completo separado en esa línea.
- CSV (Variables separadas por comas)
- El formato CSV "aplana" los datos JSON y no admite matrices ni valores anidados.
- Archivo
- Archivo comprimido de documentos JSON individuales
- Lista JSON
Veamos ahora los tres documentos en sí:
Persona con id 101 |
Persona con id 102 |
Persona sin identificación |
| { "id": 101, "short.name": "JS", "%SS%": "091-55-1234", "nombre":{ "primero": "Juan", "full.name": "John P Smith", "apellido": "Smith" }, "contacto": { "@email": "john.smith@gmail.com“, "Oficina": { "cell#": "1-555-408-1234" } } } |
{ "id": 102, "short.name": "JS", "%SS%": "091-55-1234", "nombre":{ "primero": "Jane", "full.name": "Jane P Smith", "apellido": "Smith" }, "contacto": { "@email": "jane.smith@gmail.com“, "Oficina": { "cell#": "1-555-408-2345" } } } |
{ "short.name": "AS", "%SS%": "091-55-0000", "nombre":{ "primero": "Adán", "full.name": "Adam P Smith", "apellido": "Smith" } } |
El archivo people.json
Cree un archivo con los tres documentos anteriores.
|
1 2 3 4 5 |
[ {"%SS%":"091-55-2345","contact":{"@email":"jane.smith@gmail.com","Office":{"cell#":"1-555-408-2345"}},"id":102,"name":{"first":"Jane","full.name":"Jane P Smith","last":"Smith"},"short.name":"JS"}, {"%SS%":"091-55-1234","contact":{"@email":"john.smith@gmail.com","Office":{"cell#":"1-555-408-1234"}},"id":101,"name":{"first":"John","full.name":"John P Smith","last":"Smith"},"short.name":"JS"}, {"%SS%":"091-55-0000","name":{"first":"Adam","full.name":"Adam P Smith","last":"Smith"},"short.name":"AS"} ] |
El proceso de importación de datos
Ahora que tenemos el fichero de datos, vamos a empezar el proceso de Importación. Antes de empezar, he creado un cubo de prueba con un tamaño de 100 MB. Esto me basta para importar este pequeño conjunto de datos. Hay que tener en cuenta algunas cosas:
-
- Es necesario tener Administrador privilegios.
- El cubo debe existir.
- El tamaño del cubo debe ser suficiente para contener el conjunto de datos importado.
- No es necesario tener un usuario de la base de datos.
- No es necesario lista blanca tu IP.
Cargar el archivo
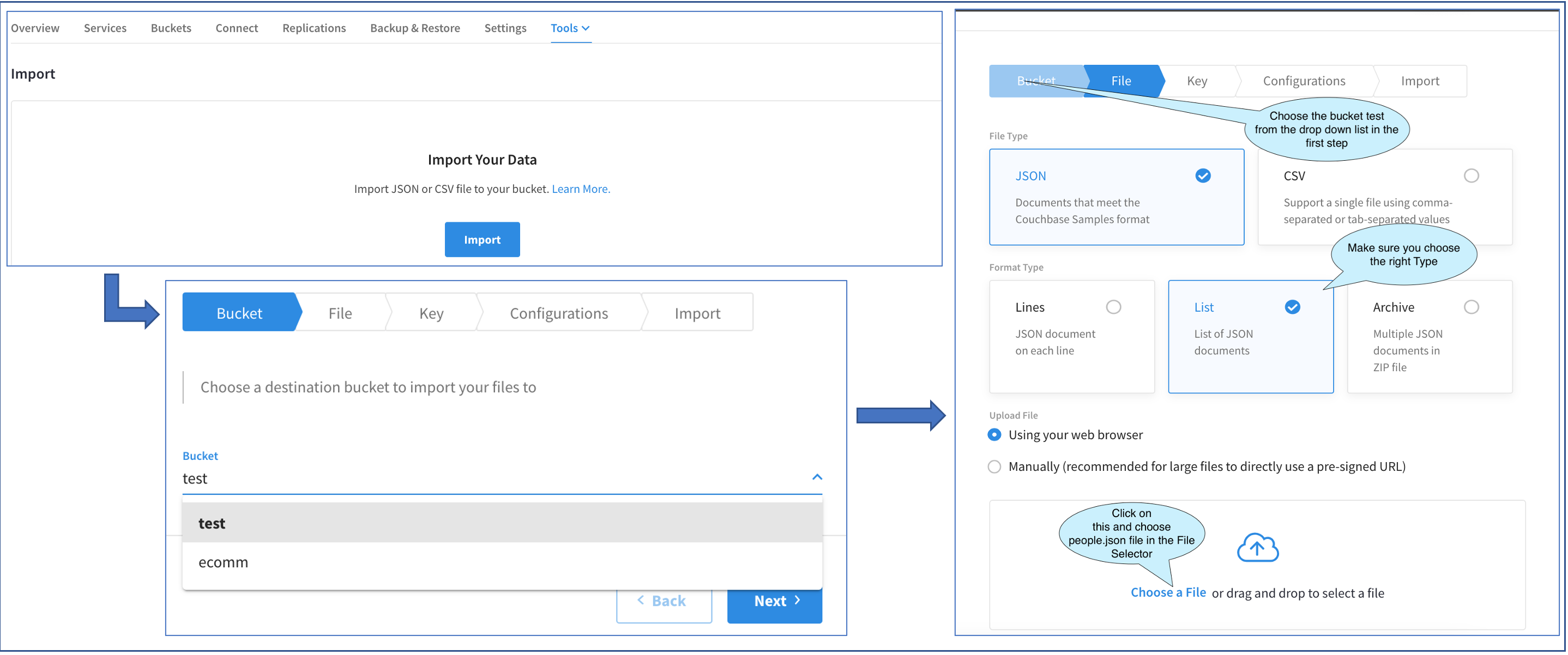
El diagrama anterior muestra la progresión de tres pantallas. Acceda a la primera pantalla principal de importación Cluster > Herramientas > Importar.
Dado que estamos realizando la importación por primera vez, la interfaz de usuario principal de importación sólo tiene un botón Importar . Al hacer clic en él, aparecerá la ventana Importación. El resto de las operaciones se realizarán en este Fly-out.
La primera pantalla del Fly-out nos permite elegir el cubo. Tengo dos cubos. Vamos a elegir el prueba cubo.
La siguiente pantalla nos pide que elijamos el Tipo de Archivo. Nuestro fichero de ejemplo es un fichero JSON y el tipo de fichero es un LISTA. Después de elegir eso, tenemos un par de opciones para subir el archivo. Podemos hacerlo a través del navegador o subirlo manualmente a través de una URL.
Normalmente, los archivos de menos de 100 MB pueden cargarse a través del navegador. Por lo tanto, vamos a elegir esa opción. Haciendo clic en Elija un archivo pone de relieve Selector de archivos (no se muestra aquí). Este es el selector de archivos estándar. Sigamos adelante y elijamos gente.json.
Si el archivo superaba los 100 MB, habríamos optado por cargarlo manualmente a través de una URL. Al hacer clic en esa opción, habría aparecido un cuadro de texto con un cURL que habremos copiado y ejecutado desde una ventana de terminal en nuestro portátil.
Independientemente del método de carga de archivos, el resto del proceso es el mismo.
Generar la clave
Una vez elegido el archivo, pasemos a la sección de generación de claves. Tenga en cuenta que en este momento, el archivo no se ha cargado todavía. Eso sucederá unos pasos más abajo.
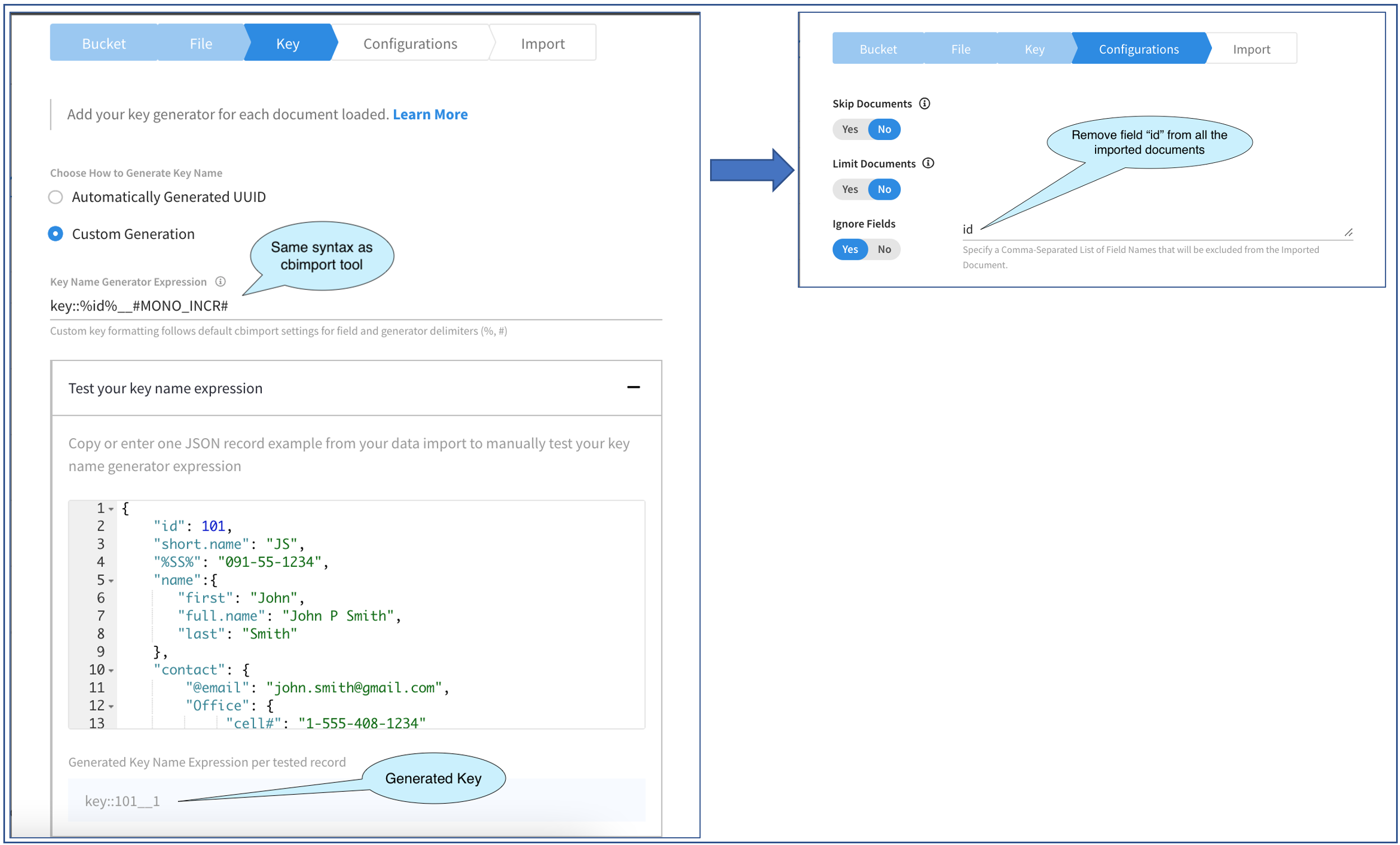
La imagen anterior muestra la progresión a través de dos pantallas en el menú desplegable de importación.
La primera pantalla nos permite especificar cómo se va a generar la clave del documento. Aquí se nos dan un par de opciones: O bien autogenerar la clave o generar la clave utilizando un expresión suministrado por nosotros. La primera opción es sencilla y puede utilizarse para pequeños casos de prueba en los que la clave del documento no es importante. Sigamos adelante y seleccionemos la segunda opción y generemos las claves de documento según un patrón determinado.
Necesitamos especificar la Expresión en la Expresión del Generador de Nombres de Clave. Se trata de una cadena y sigue la misma sintaxis que la de los generadores de claves de cbimport. La clave generada puede ser texto estático o derivado de un valor de campo en el documento a función generador como MONO_INCR o UUID con cualquier combinación de los tres.
Hay que tener en cuenta algunas cosas a la hora de construir la expresión:
-
- Los nombres de campo siempre van encerrados entre "%".
- Las funciones del generador siempre van encerradas en "#".
- Cualquier texto que no esté envuelto en "%" o "#" es texto estático y estará en el resultado de todas las claves generadas.
- Si una clave debe contener "%" o "#" en texto estático, debe escaparse con un doble "%" o "#" (por ejemplo, "%%" o "##").
- Si no se puede generar una clave porque el campo especificado en el generador de claves no está presente en el documento, se omitirá la clave.
La expresión que elegimos para este ejemplo es: key::%id%__#MONO_INCR#. Con esto queremos decir:
-
- Sustituya %id% por el valor del campo "id" del documento.
- Sustituye #MONO_INCR# por un número monótonamente creciente que empiece por 1.
- Tratar el resto como texto estático en la clave
Esta pantalla también permite comprobar la sintaxis de la expresión, así como la clave real generada por la expresión.
Para ello, tenemos que pegar un documento de muestra en la carpeta Editor JSON. Lo he hecho, como puedes ver. De los tres documentos del expediente, sólo los dos primeros tienen el id por lo que tuve cuidado al elegir un documento que sí tuviera el campo. Este validador, por supuesto, sólo funciona con documentos JSON y no con un documento CSV. Por último, como puedes ver en la imagen de arriba, he "embellecido" el documento JSON. Esto es por conveniencia. Esto habría funcionado incluso si hubiera pegado el documento como una sola línea. A medida que escribimos la expresión, el generado se muestra en la parte inferior. Es muy interactivo y te permite jugar con las expresiones y comprobar al instante la clave generada.
Cuando esté satisfecho, puede pasar a configuración y eso es exactamente lo que haremos. Esta pantalla ofrece tres opciones de las cuales nos interesa la última, Ignorar campos. Esta opción permite importar todos los documentos del fichero pero sin los campos especificados en el documento. Esta opción permite especificar varios campos, delimitados por comas.
En nuestro ejemplo, como hemos hecho que el valor de id parte de la clave del documento, realmente no necesitamos que esa misma información esté también en el documento, así que vamos a eliminarla. Para ello, he introducido la cadena como id. Tenga en cuenta que se trata de texto sin formato y que no debe encerrar los nombres de los campos dentro de "%".
Ejemplos de generación de claves
| Expresión de generación de claves | Clave generada |
|---|---|
| clave::%id%::#MONO_INCR# | clave::102::1 |
| clave::%id%::#UUID# | key::102::29ee002c-06e4-4dbf-bb5b-b2f148167536 |
| clave::%id%::###UUID# | key::101::#3c671afe-fb02-48aa-a027-d74a8d38bcbc |
tecla::%nombre.corto%_%%%SS%%% |
clave::AS_091-55-0000 |
key::%name.nombre.completo% |
clave::Adam P Smith |
| clave::%contacto.@email% | key::jane.smith@gmail.com |
| clave::%%%contacto.@email% | key::%jane.smith@gmail.com |
| contacto##::%contacto.@email% | contact#::jane.smith@gmail.com |
| Tel##:%contact.Office.cell#% | Tel#:1-555-408-1234 |
Verificar y ejecutar la importación
Ahora que la clave se ha generado a nuestra satisfacción y la importación de datos se ha configurado para ignorar el id en los documentos, pasemos al siguiente paso: verificar y ejecutar la importación.
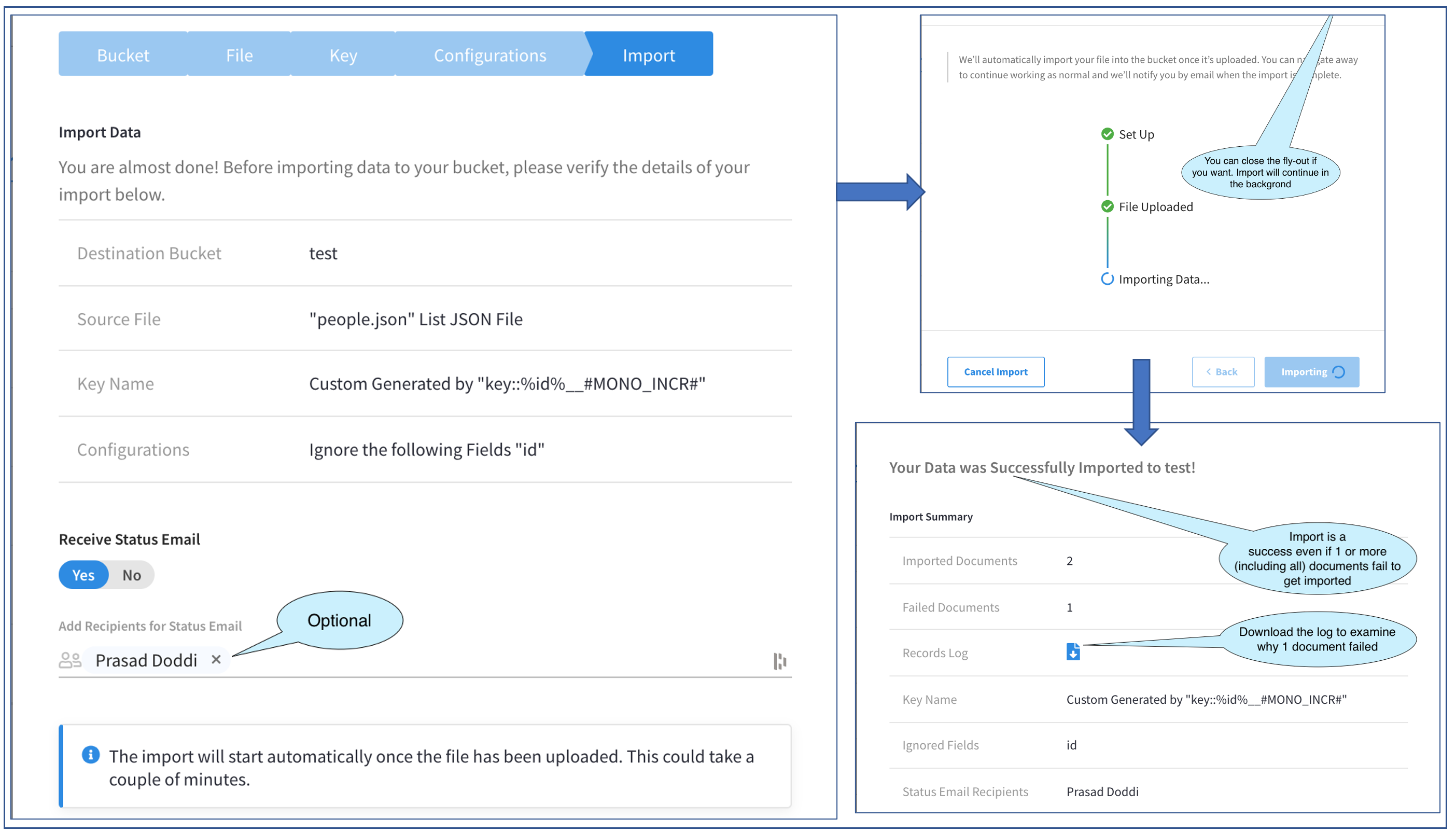
La imagen de arriba muestra la progresión a través de tres pantallas en el Fly-out.
Empecemos por la primera. Esta pantalla verifica lo que pretendemos hacer y nos permite volver atrás en caso de que nos hayamos saltado algo. Además, nos permite especificar una lista de usuarios que recibirán un correo electrónico de confirmación una vez realizada la importación. Esto es muy conveniente para archivos de importación grandes que pueden ejecutarse en segundo plano mientras nos dedicamos a otras tareas. Esto, por supuesto, es opcional. He elegido añadirme a mí mismo para recibir el correo de confirmación. La lista de usuarios que se muestran en el selector a Añadir destinatarios son los Administradores que forman parte del Proyecto.
La siguiente pantalla inicia la Importación propiamente dicha. La importación se ejecuta en la pantalla fondo y no necesita que el Fly-out esté abierto. Podemos cerrar la ventana desplegable pulsando el botón X en la esquina superior derecha (no visible en la imagen). También se nos da la opción de cancelar la Importación. En este ejemplo, la mantendré abierta hasta que se complete.
Una vez completado, aparecerá la tercera pantalla de la imagen anterior. Tenga en cuenta que todavía puede llegar a esta pantalla desde la página principal de importación, y lo comprobaremos más adelante.
La tercera pantalla muestra el Resultado de la importación. En este momento, también recibiremos el correo electrónico de confirmación. En nuestro ejemplo, esta pantalla nos dice que dos documentos se importaron con éxito y uno falló. El estado general es una importación correcta.
Una cosa importante a tener en cuenta aquí es que el éxito global de la Importación no depende del éxito de la importación de datos de todos, algunos o ninguno de los documentos. El éxito del proceso de importación consiste simplemente en que el proceso se haya completado sin bloquearse.
Volviendo a nuestro ejemplo, profundicemos un poco más en este fallo de un documento. Para solucionar problemas este fracaso, se nos proporciona un útil botón para descargar el Registro y esto es lo que haremos.
Resolución de problemas con el registro de registros
Este es el registro que he descargado. (He recortado algunas líneas).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Custom generator key: key::%id%__#MONO_INCR# User args: --verbose --ignore-field id ======================= 2021-06-03T01:50:07.322+00:00 (Rest) GET https://cb:8091/pools/default 200 2021-06-03T01:50:07.322+00:00 (Plan) Executing transfer plan ... 2021-06-03T01:50:07.330+00:00 (Rest) GET https://cb:8091/pools/default/buckets 200 2021-06-03T01:50:07.331+00:00 (Rest) GET https://cb:8091/pools/default/nodeServices 200 2021-06-03T01:50:07.356+00:00 ERRO: Key generation for document failed, field id does not exist -- jsondata.(*Parallelizer).... 2021-06-03T01:50:07.376+00:00 ERRO: Data transfer failed: Some errors occurred while transferring data, ... 2021-06-03T01:50:07.376+00:00 (Plan) Transfer plan failed due to error Some errors occurred while transferring data, ... 2021-06-03T01:50:07.376+00:00 JSON import failed: 2 documents were imported, 1 documents failed to be imported 2021-06-03T01:50:07.376+00:00 JSON import failed: Some errors occurred while transferring data, see logs for more details JSON import failed: 2 documents were imported, 1 documents failed to be imported JSON import failed: Some errors occurred while transferring data, see logs for more details |
La línea de error es: ERRO: Error en la generación de la clave del documento, el campo id no existe. El error dice que el campo "id" no existe en algún documento. Esto, por supuesto, es correcto y por qué este documento no se importó.
Comprobación de los documentos importados
Ahora que la importación está hecha, y también hemos realizado un poco de solución de problemas, vamos a seguir adelante y comprobar los documentos importados reales.
Necesitamos ver dos documentos con el formato Clave correcto y los documentos no deben tener el id ya que hemos configurado Importar para que ignore este campo. Para comprobarlo, vamos a abrir la ventana Herramientas > Visor de documentos.
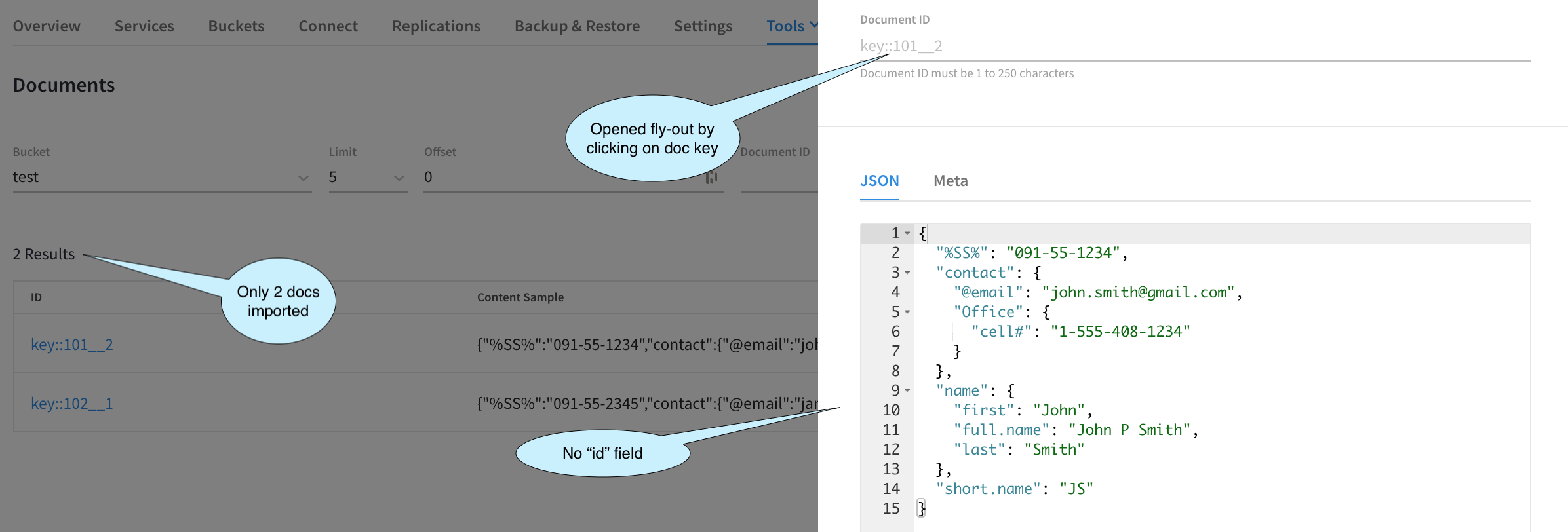
Esta imagen de arriba no hace sino confirmar que hemos logrado el resultado deseado.
Pantalla principal de importación: Lista de actividades
Una vez cerrada la ventana de importación, volvemos a la pantalla principal. Ahora, vemos una lista de todas nuestras actividades de importación de datos. En este ejemplo, he realizado varias importaciones y también he cancelado una para ilustrar la interfaz de usuario de la actividad.
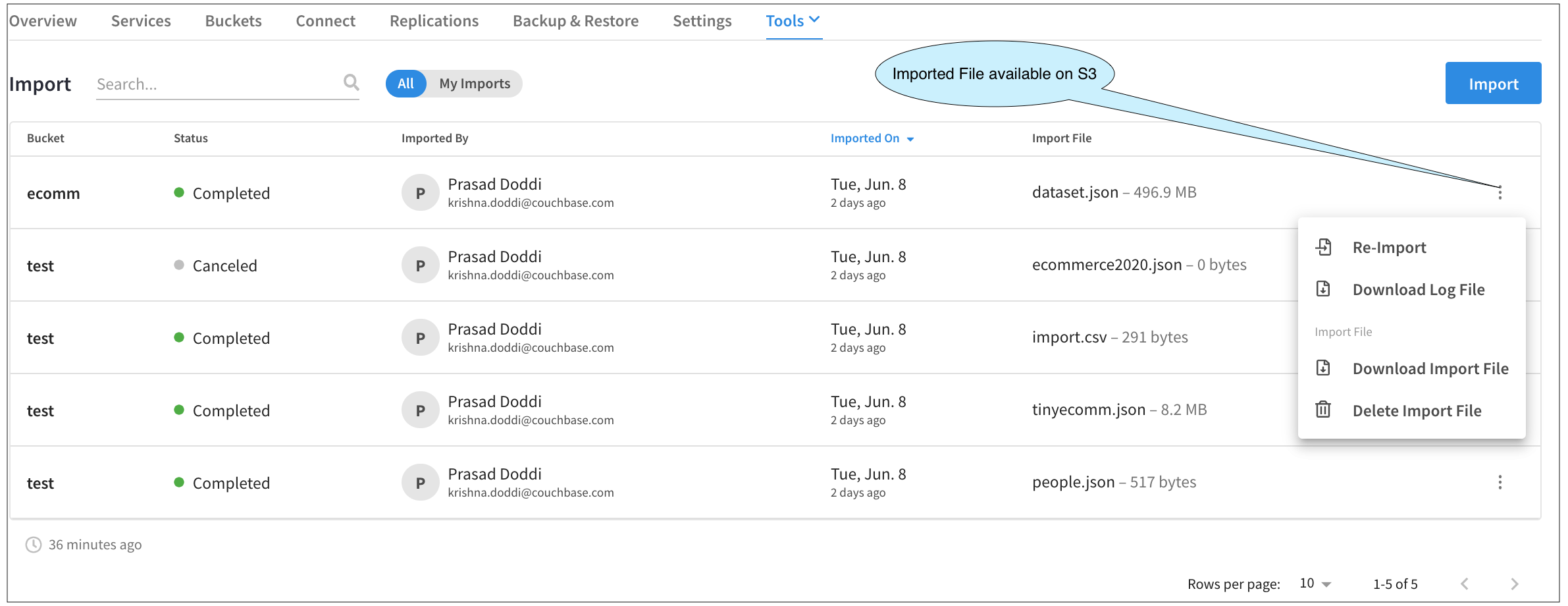
Si hubiéramos cerrado el menú desplegable de importación (haciendo clic en el botón X), entonces el estado de eso aparecería como En curso.
Esta pantalla no sólo actúa como registro de auditoría, sino que también podemos realizar otras actividades.
Al hacer clic en cualquier línea, aparece la ventana Resultado de la importación Desplegable. Al hacer clic en el botón botones de tres puntos en cada línea aparece un menú desde el que podemos descargar el archivo de registro, etc.
Uno de los platos más interesantes del menú es Volver a importar. Dado que los archivos subidos están ahora en el almacenamiento en la nube (S3 en el caso de AWS, por ejemplo), podemos utilizar el mismo archivo para la importación evitando el paso inicial de subir el archivo desde su ordenador portátil. Al hacer clic en esto, se le llevará a través de los pasos de importación una vez más, pero esta vez, le permitirá volver a utilizar el archivo importado y mantener todas las selecciones que había hecho anteriormente, como Tipo de archivo, Expresión clave, etc. Por supuesto, siempre puede cambiarlas. Dado que el proceso es prácticamente el mismo, no lo repasaremos en esta demostración.
Buenas prácticas y "¡te pillé!
He aquí algunas de las mejores prácticas que debe tener en cuenta para su proyecto, así como algunos errores comunes que debe evitar:
-
- Compruebe el tipo de archivo al importar
- No confundas
LÍNEASyLISTAtipo Archivos JSON. - Es posible que la importación se realice correctamente, pero que no se importe ningún documento o sólo uno (el último).
- No confundas
- Compruebe la clave generada siempre que sea posible cuando utilice la expresión de generación de clave personalizada.
- Preste especial atención al delimitador de campo %
- Por ejemplo, si la omite y especifica la clave personalizada como
clave::iden lugar declave::%id%al final del proceso de importación de datos, verá sólo un documento con la clave comoclave::id
- Asegúrese de que su cubo tiene el tamaño adecuado para contener los documentos importados.
- Si tiene un clúster de tres nodos y especifica 100 MB como tamaño del bucket y decide importar un archivo de 2 GB, con nombres de clave largos (como UUID autogenerados), el bucket se llenará rápidamente de metadatos.
- Recuerde que todos los Couchbase Cloud Buckets son sólo Value Ejection.
- Utilice cURL para importar archivos grandes, normalmente de más de 100 MB.
- Cada vez que quieras subir a través de esto, el cURL puede ser diferente, así que no reutilices el antiguo comando cURL.
- Compruebe el tipo de archivo al importar
Conclusión
Esto ha sido una mirada más cercana a algunos casos de uso y algunos "gotcha "s durante la importación de datos con Couchbase Cloud. Echa un vistazo a este artículo para aprender más acerca de otras nuevas características de Couchbase Cloud 1.6, incluyendo la nueva API pública y más.
Si no ha aprovechado la Prueba gratuita de Couchbase Cloud Pruébalo hoy mismo.