Con Couchbase 7.0 ahora es capaz de permitir la integración de Python UDFs con Couchbase Analytics. En Parte 1 de esta serie de blogsEn este artículo, hemos tratado los aspectos esenciales para configurar Couchbase y Analytics for Machine Learning (ML).
El ML ha transformado radicalmente la forma en que las organizaciones comprenden las necesidades de sus clientes. Los ámbitos del análisis avanzado, como el análisis predictivo (pérdida de clientes, sentimiento de los clientes, etc.) y el modelado financiero, dependen cada vez más del procesamiento de datos a escala, casi en tiempo real, y de la extracción de información valiosa a partir de ellos.
Para ayudar a nuestros clientes a obtener conocimientos analíticos en tiempo real, hemos creado una tubería perfecta de modelos de aprendizaje automático basados en Python a Couchbase Analytics. En este post, voy a recorrer los siguientes pasos para mostrar cómo aplicar algoritmos externos a los datos que residen en Couchbase.
Seis pasos para aplicar modelos ML a sus datos NoSQL:
- Entrenar el modelo
- Codificar el modelo
- Empaquetar e implantar el código
- Importe los datos necesarios para este proyecto
- Escribir la UDF
- Uso de la UDF en su instancia para CB (Modo DP)
Antes de entrar en materia, vamos a buscar un conjunto de datos que sirva de interesante demostración de las capacidades que estamos construyendo. Hay reseñas de películas en varios sitios web, pero para tener una visión holística de las críticas no hay mejor lugar que Rotten Tomatoes. Este sitio web permite comparar las puntuaciones dadas por los usuarios habituales (puntuación del público) y las puntuaciones o reseñas dadas por los críticos (tomatómetro) que son miembros certificados de diversos gremios de escritores o asociaciones de críticos de cine.
Los dos conjuntos de datos utilizados para este blog se encuentran en kaggle.com. Se trata de archivos bastante grandes, por lo que se proporciona un enlace a los mismos para que pueda descargarlos cuando los siga.
En el películas cada registro representa una película disponible en Rotten Tomatoes, con la URL utilizada para obtener el título de la película, la descripción, los géneros, la duración, el director, los actores, las valoraciones de los usuarios y las valoraciones de los críticos. En el críticas_de_películas cada registro representa una crítica publicada en Rotten Tomatoes, con la URL utilizada para obtener el nombre del crítico, la publicación de la crítica, la fecha, la puntuación y el contenido.
Entrenamiento del modelo ML
Antes de empezar a explorar el poder de la integración entre ML y NoSQL, necesitará desarrollar y entrenar un modelo de aprendizaje automático en Python.
Para los fines de este blog, utilizaremos un modelo de regresión logística simple que utiliza la biblioteca scikit-learn. En esencia, el modelo toma los datos y analiza sus sentimientos con respecto a las críticas de películas. Puede seguir los pasos que se describen a continuación o puede descargar todos los archivos necesarios de nuestro Repo de GitHub.
Para este blog, estamos utilizando un algoritmo predictivo de código abierto en el conjunto de datos de críticas de películas para determinar el sentimiento, es decir, para determinar si las críticas son positivas o negativas para una película determinada. En los ejemplos de hoy, ya hemos entrenado el modelo utilizando un subconjunto del archivo descargado anteriormente. Para los fines de este blog utilizamos un archivo CSV (valores separados por comas) para importar nuestros datos.
A continuación se muestra una muestra del código para el modelo en sí:
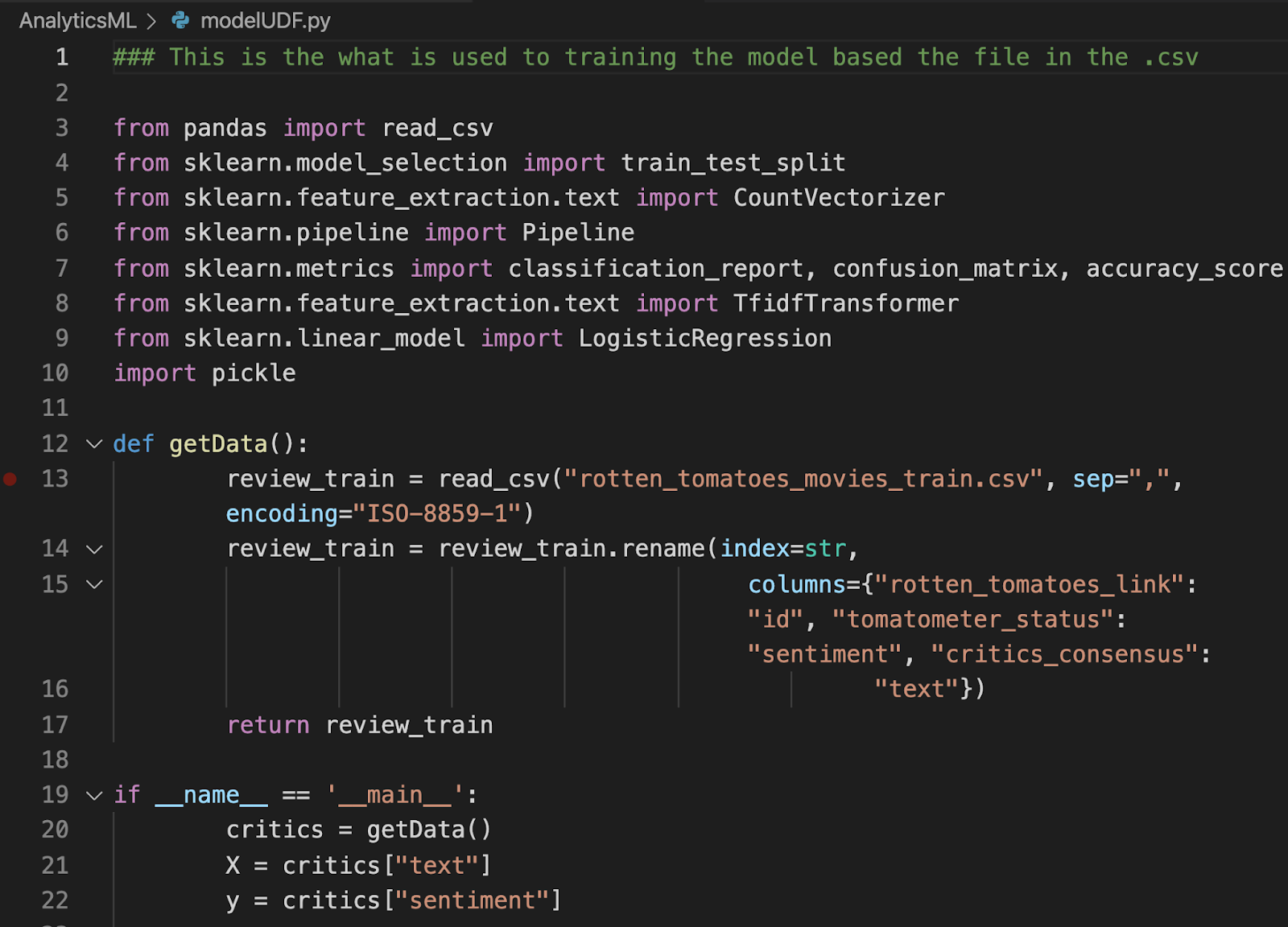
La totalidad del ejemplo de código se encuentra en la página Repositorio GitHub.
Cuando ejecutes el script Python modelo mostrado arriba, deberías obtener el siguiente resultado:

Puede obtener más información sobre las métricas de scikit-learn como precisión, recall, f1-score y support aquí. Ahora tenemos un modelo de aprendizaje automático funcional y de buen rendimiento completamente entrenado en Python.
Creación de una biblioteca Python
Con el fin de hacer referencia al modelo de aprendizaje automático, tendrá que crear una biblioteca de Python. A continuación se muestra la biblioteca para este ejemplo en particular:
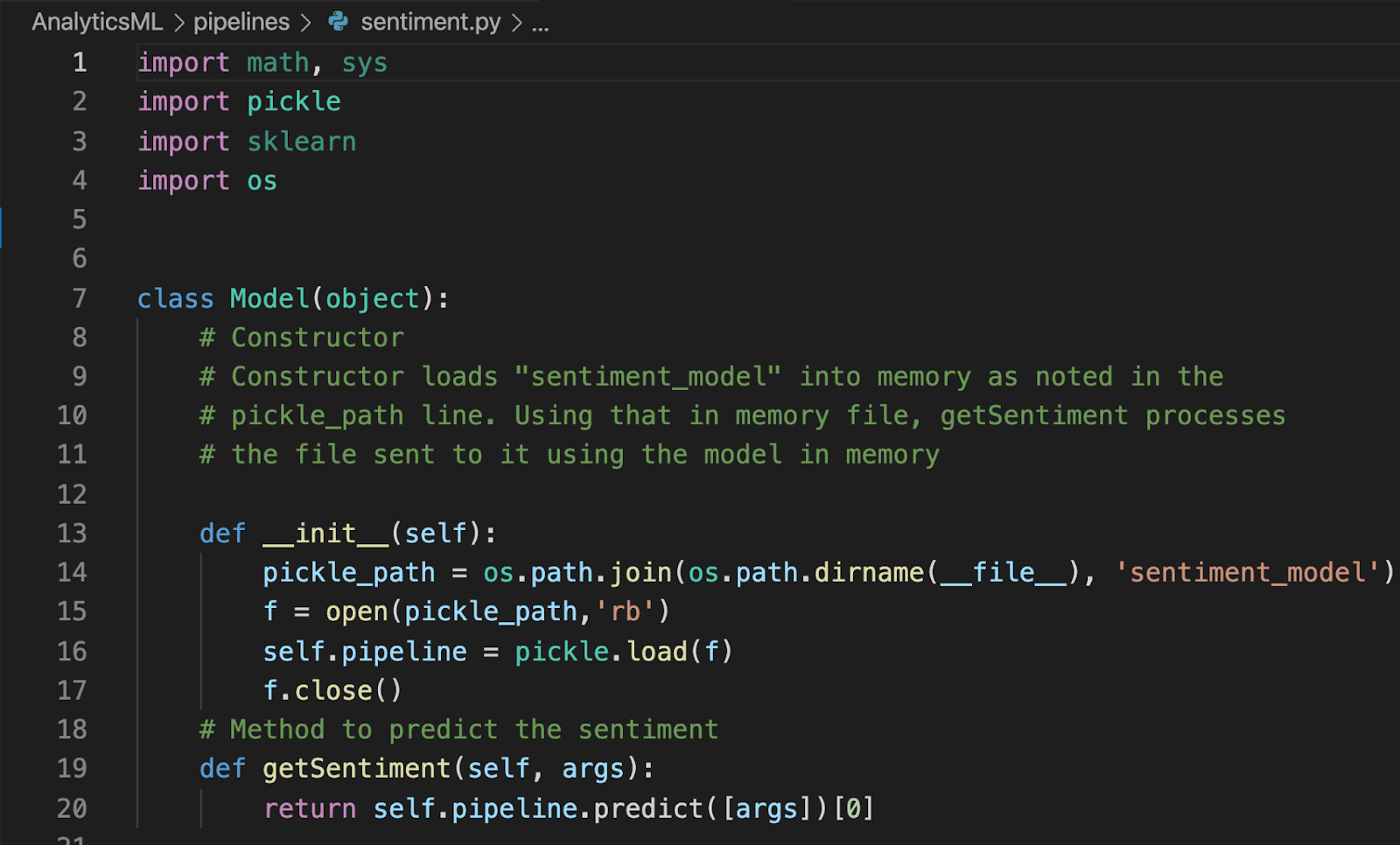
La biblioteca tiene dos componentes principales:
Constructor de modelos-Este constructor crea un fichero llamado modelo_de_sentimiento en el tuberías de nuestro entorno Jupyter.
método getSentiment-Este método predice el sentimiento del cliente asociado al parámetro (o argumento) que se le pasa.
Guarde el archivo como sentimiento.py dentro del tuberías con el archivo modelo_de_sentimiento.
Empaquetado y despliegue de la biblioteca
Este es un paso crítico en lo que vendrá después: ¡desbloquear el poder de las funciones definidas por el usuario de Python! Por favor, presta atención a los detalles ya que depende más de la sintaxis que cualquiera de los otros. Asegúrese de leer atentamente la documentación correspondiente. Siga el enlace para saber más sobre las funciones definidas por el usuario.
Para empaquetar el modelo y la biblioteca que hemos creado en los pasos anteriores, utilizaremos la utilidad shiv. Si shiv no está ya instalado, utilice el comando pip install shiv (o pip3 install shiv dependiendo de su entorno). Además, si estás interesado en leer la documentación de esta utilidad de línea de comandos, puedes encontrarla aquí.
Pasos para empaquetar el modelo:
- En su ordenador portátil, empaquete el modelo de sentimiento y el código del modelo. Esto hace que sea autoejecutable y elimina cualquier dependencia de la biblioteca:
-
- shiv -site-packages pipelines/ -o pipeline.pyz -platform manylinux1_x86_64 -python-version 39 -only-binary=:all: scikit-learn
-plataforma manylinux1_x86_64 sólo es necesario cuando se utiliza una máquina virtual con Linux.
- Copie el paquete Python autónomo con las dependencias necesarias en el servidor de análisis:
- docker cp pipeline.pyz cb-analytics:/tmp/
- Acceder al intérprete de comandos del cb-analytics Contenedor Docker:
- docker exec -it cb-analytics bash
- Desde el shell de Docker, vaya a la carpeta tmp donde se encuentra el archivo zip e importar los datos necesarios para los dos buckets:
- cd /tmp
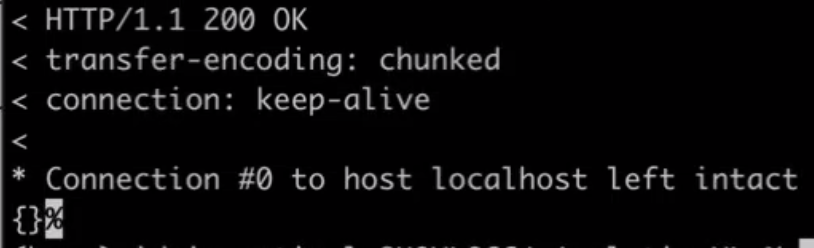
- curl -v -X POST -F "data=@./pipeline.pyz" -F "type=python" "localhost:8095/analytics/library/Default/sentimentlibrary" -u Administrador:contraseña;
- El sistema se actualizará cuando esté completo y tendrá éxito cuando vea esta respuesta HTTP 200:
Importar documento de cubo para que lo analice la UDF
Hay que seguir dos pasos en la máquina local y ejecutar tres comandos en la instancia de Docker.
Máquina local
0. Crear cubos película o críticas_de_películas ya sea en el consola web o a través del couchbase-cli comando
- Corre: docker cp rotten_tomatoes_critic_reviews.csv cb:/tmp/ Este archivo supera el límite de 100 Mb de la utilidad de importación GUI y debe importarse directamente.
Instancia Docker
2. docker exec -it cb bash
3. cbimport csv -infer-tipos -c https://localhost:8091 -u Administrador -p contraseña -d 'file://rotten_tomatoes_critic_reviews.csv' -b 'movie_reviews' -scope-collection-exp "_default._default" -g "%rotten_tomatoes_link%"
4. cbimport csv -infer-tipos -c https://localhost:8091 -u Administrador -p contraseña -d 'file://rotten_tomatoes_movies.csv' -b 'movies' -scope-collection-exp "_default._default" -g "%rotten_tomatoes_link%"
Puede importar el último fichero (rotten_tomatoes_peliculas.csv) desde la línea de comandos, como se muestra más arriba, o desde la opción Consola Web Couchbase > Documento > Importar del portal de Couchbase como se muestra en esta captura de pantalla:
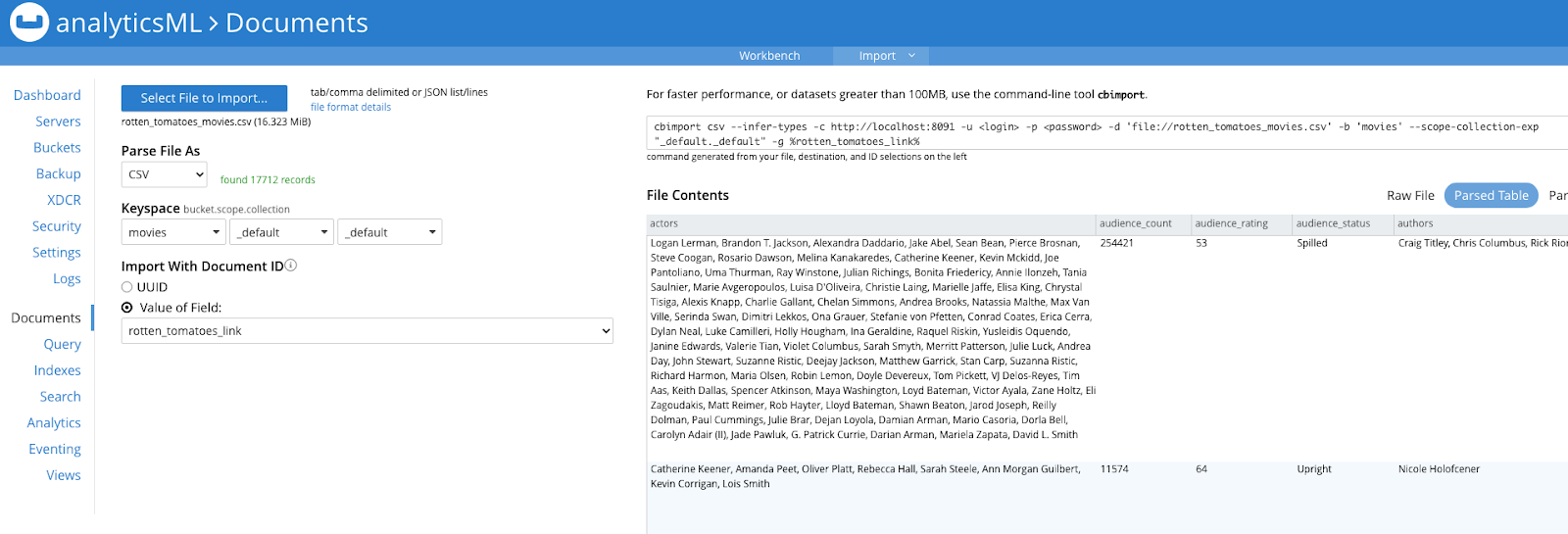
Ahora tienes documentos en los dos buckets y contienen la reseña y los resúmenes de la película en Couchbase para ejecutar tu análisis de sentimiento contra ellos.
Escribir UDFs
Es hora de escribir nuestra propia función definida por el usuario en Couchbase Analytics. Si necesitas un repaso, aquí tienes un enlace a nuestra documentación sobre Funciones definidas por el usuario. Consulte la biblioteca (el Modelo y getSentiment ) que creamos en el paso 2 y que cargamos en el servidor Analytics en el paso 3. Ahora se hace referencia a ellos en la siguiente función definida por el usuario:
|
1 2 |
CREATE ANALYTICS FUNCTION getReviewSentiment(text) AS "sentiment", "Model.getSentiment" AT sentimentlibrary; |
Cree la UDF de análisis en la misma ubicación (sentimentlibrary) como se especifica en el rizo función.
Invocación de las UDF
Aprovechando las capacidades de N1QL, ahora podemos escribir consultas predictivas dentro de Couchbase Analytics para derivar poderosos insights de nuestros UDFs. De forma encubierta, cuando se invoca esta UDF se llama a la subyacente Modelo que itera sobre cada fila para realizar el análisis de sentimiento. El siguiente es un ejemplo básico de este tipo de consulta, pero las posibilidades son realmente infinitas.
|
1 2 3 4 5 6 |
USE Default; SELECT getReviewSentiment(r.review_content) AS sentiment, COUNT(*) AS sentimentCount FROM movie_reviews r, movies m WHERE m.rotten_tomatoes_link = r.rotten_tomatoes_link GROUP BY getReviewSentiment(r.review_content) ORDER BY sentimentCount DESC; |
Con una consulta de este tipo obtendrá resultados como los siguientes:
|
1 2 3 4 5 6 7 8 9 10 |
[ { "sentimentCount": 10105, "sentiment": "Fresh" }, { "sentimentCount": 7601, "sentiment": "Rotten" } ] |
Ahora tenemos un recuento ordenado de sentimientos positivos, neutrales y negativos, tal y como los define nuestro modelo entrenado.
Conclusión
Felicidades, acabas de configurar el entorno necesario de Couchbase Server en Docker y has ejecutado con éxito tu primera User Defined Function en Couchbase Analytics. Como puedes ver, la integración de tus modelos Python ML con UDFs y Couchbase Analytics promete ser una forma efectiva de extraer información valiosa de tus datos sin comprometer el rendimiento o la eficiencia.
No dude en hacernos llegar sus preguntas u opiniones en los comentarios o a través de un mensaje en Foros de Couchbase. Estamos impacientes por ver cómo combinará la potencia de ML y NoSQL para su empresa.
Si desea obtener más información sobre Couchbase Analytics, vea nuestra Connect Session: El aprendizaje automático se une a NoSQL: Python UDFs.
He aquí un resumen de los enlaces y temas mencionados en este post:
- Parte 1 - ML se une a NoSQL: Integración de funciones definidas por el usuario de Python con N1QL para análisis
- Repositorio GitHub de Couchbase AnalyticsML
- Conjunto de datos Kaggle de críticas de Rotten Tomatoes
- Documentación sobre las funciones definidas por el usuario de Couchbase
Agradecimientos
Gracias a Anuj Kothari, un becario de verano de gestión de productos para el servicio Couchbase Analytics, cuyos esfuerzos iniciales hicieron que esto empezara y despegara el verano pasado. Gracias a Idris MotiwalaDirector de producto principal del servicio de análisis de Couchbase, y Ian Maxoningeniero de software de Couchbase Analytics Service, por su trabajo editorial para hacer de éste un blog más funcional.
