El premise es muy simple: en el mundo de las tecnologías dispares donde una no funciona o no se integra bien junta, Couchbase & Confluent Kafka son productos increíbles y son extremadamente complementarios entre sí. Couchbase es una base de datos NoSQL JSON linealmente escalable y distribuida. Su caso de uso principal es para cualquier aplicación/servicio web que requiera un solo dígito. ms latencia de lectura/escritura/actualización. Se puede utilizar como sistema de registro (SoR) o capa de almacenamiento en caché para la rápida mutación de datos transitorios o la descarga de Db2/Oracle/SQL Server, etc. para que los servicios posteriores puedan consumir datos de Couchbase.
Confluent Kafka es una plataforma de flujo distribuido completa que también es linealmente escalable y capaz de gestionar billones de eventos en un día. Confluent Platform facilita la creación de canalizaciones de datos en tiempo real y aplicaciones de streaming mediante la integración de datos de múltiples fuentes y ubicaciones en una única plataforma central de streaming de eventos para su empresa.
En esta entrada del blog vamos a cubrir cómo sin problemas podemos mover los datos fuera Couchbase y empujar en un tema kafka Confluent como evento de replicación.
El conector Kafka de Couchbase transfiere documentos desde Couchbase de forma eficiente y fiable utilizando el protocolo de replicación interno de Couchbase, DCP. Cada cambio o eliminación del documento genera un evento de replicación, que se envía al tema Kafka configurado.
El conector Kafka se puede utilizar para mover datos fuera de Couchbase y mover datos de kafka a Couchbase utilizando el conector sink. Para el propósito de este blog vamos a configurar y utilizar el conector de origen.
A alto nivel, el diagrama de arquitectura tiene el siguiente aspecto
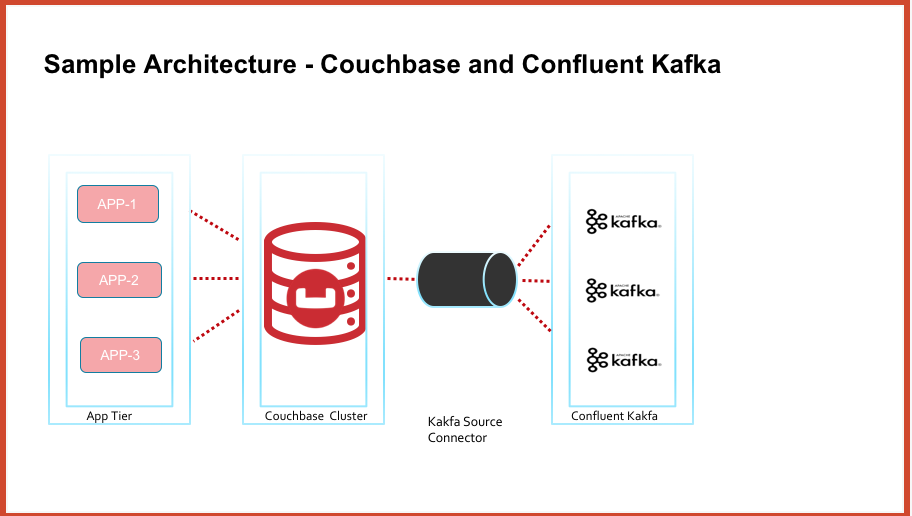
Requisitos previos
Couchbase Cluster con la versión 5.X o superior. Descargar Couchbase aquí
Conector kafka de Couchbase. Descargar el conector kafka de Couchbase aquí
Confluent Kafka. Descargar Confluent Kafka aquí
Configurar el cluster de Couchbase está fuera del alcance de esta entrada de blog. Sin embargo, vamos a discutir la configuración de Confluent kafka y el conector kafka Couchbase para mover datos fuera de Couchbase.
Configuración de Confluent Kafka
Untar el paquete descargado anteriormente en una VM/pod. Para el propósito de este blog, he desplegado un Ubuntu Pod en kubernetes clúster que se ejecuta en GKE.
Asegúrese antes de instalar confluent kafka máquinas necesita tener java 8 versión.
Instalar/arrancar kafka
kafka tiene los siguientes procesos, que deberían estar todos activos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<em class="markup--em markup--p-em">zookeeper is [UP]</em> <em class="markup--em markup--p-em">kafka is [UP]</em> <em class="markup--em markup--p-em">schema-registry is [UP]</em> <em class="markup--em markup--p-em">kafka-rest is [UP]</em> <em class="markup--em markup--p-em">connect is [UP]</em> <em class="markup--em markup--p-em">ksql-server is [UP]</em> <em class="markup--em markup--p-em">control-center is [UP]</em> |
Pod ejecutando confluent kafka puede ser expuesto a través del servicio NodePort a la máquina local/portátil. El archivo pod de la aplicación es aquí. El archivo yaml del servicio es aquí
|
1 2 3 4 5 |
<em class="markup--em markup--p-em">$ kubectl get svc -n mynamespace</em> <em class="markup--em markup--p-em">NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE</em> <em class="markup--em markup--p-em">app-service ClusterIP 10.51.248.154 <none> 9021/TCP,8083/TCP 115s</em> |
Reenviar el servicio al puerto local 9021
|
1 2 3 4 5 |
<em class="markup--em markup--p-em">$ kubectl port-forward service/app-service 9021:9021 -- namespace cbdb</em> <em class="markup--em markup--p-em">Forwarding from 127.0.0.1:9021 -> 9021</em> <em class="markup--em markup--p-em">Forwarding from [::1]:9021 -> 9021</em> |
Pulsa la URL: https://localhost:9021
Configuración del conector Kafka de Couchbase
Descomprima el paquete descargado anteriormente
|
1 |
<em class="markup--em markup--p-em">$ unzip kafka-connect-couchbase-3.4.5.zip</em> |
|
1 |
<em class="markup--em markup--p-em">$ cd kafka-connect-couchbase-3.4.5/</em>config |
Editar archivo quickstart-couchbase-source.properties con (al menos) la siguiente información
Cluster Cadena de conexión
|
1 |
<em class="markup--em markup--p-em">connection.cluster_address=cb-demo-0000.cb-demo.default.svc.cluster.local</em> |
nombre del cubo y credenciales de acceso al cubo
|
1 2 3 |
<em class="markup--em markup--p-em">connection.bucket=travel-sample connection.username=Administrator connection.password=pa$$word</em> |
Nota: Introduzca las credenciales del cubo al que desea mover los datos. En mi ejemplo, utilizo el bucket travel-sample, con las credenciales de usuario del bucket.
Exportar la variable CONFLUENT_HOME
|
1 |
<em class="markup--em markup--p-em">export CONFLUENT_HOME=/root/confluent-5.2.1</em> |
Iniciar el conector kafka
|
1 |
<em class="markup--em markup--p-em">env CLASSPATH=./* connect-standalone $CONFLUENT_HOME/etc/schema-registry/connect-avro-standalone.properties config/quickstart-couchbase-source.properties</em> |
Cuando se inicia el conector se crea un tema kafka con el nombre cb-topic y podemos ver todos los documentos de Couchbase viaje-muestra bucket get transferred to kafka topic cb-topic como eventos

Conclusión
En cuestión de minutos se puede integrar Couchbase y Confluent Kafka. La facilidad de uso, despliegue y soporte son factores clave en el uso de la tecnología. En esta entrada del blog vimos que uno puede mover sin problemas los datos de Couchbase a un tema kafka. Una vez que los datos están en un tema kafka, entonces usando KSQL uno puede crear aplicaciones de procesamiento de flujo en tiempo real que coincidan con las necesidades del negocio.
Referencias:
- https://docs.confluent.io/current/quickstart/ce-quickstart.html#ce-quickstart
- https://docs.couchbase.com/kafka-connector/3.4/quickstart.html
- https://docs.couchbase.com/kafka-connector/3.4/source-configuration-options.html