Capella App Services es un backend como servicio (BaaS) totalmente gestionado, que se adapta específicamente a las aplicaciones móviles, IoT y edge. Permite a los desarrolladores y organizaciones integrarse a la perfección con Couchbase Capella y sincronizar datos entre varias aplicaciones de borde utilizando Couchbase Lite.
Aunque Capella App Services es un entorno gestionado, la monitorización proporciona información valiosa y control. Le permite realizar un seguimiento de las métricas clave sobre la utilización de recursos, el rendimiento, las tasas de error y muchos más, ayudando así en la identificación de cuellos de botella de rendimiento y problemas de escalabilidad.
Además, la detección proactiva de problemas mediante alertas minimiza el tiempo de inactividad de las aplicaciones de extremo a extremo y garantiza un funcionamiento continuo. La planificación de la capacidad también se hace más eficaz con la supervisión, ya que se analizan los patrones de uso de los recursos y se toman decisiones informadas sobre el escalado de la infraestructura y la optimización de los costes.
En esta entrada de blog, exploraremos cómo puede supervisar fácilmente Capella App Services utilizando Prometeo métricas y Grafana. Le guiaremos a través del proceso de configuración de Prometheus para recopilar y almacenar métricas de Capella App Services. Además, demostraremos cómo aprovechar Grafana para crear cuadros de mando atractivos que proporcionen información en tiempo real sobre el rendimiento del comportamiento de sus aplicaciones.
Requisitos previos
Antes de sumergirse en el tutorial, asegúrese de que dispone de los siguientes requisitos previos:
-
- Una Capella desplegada Servicio de aplicaciones y una configuración Punto final de la aplicación.
- Docker instalado en su máquina local.
Fondo
Métricas de la interfaz de usuario web de Capella App Services
Capella App Services ofrece funciones de supervisión desde el primer momento a través de su interfaz de usuario web. Documentos sobre la supervisión de los puntos finales de las aplicaciones. La pestaña Supervisión de la interfaz Web proporciona una interfaz intuitiva para representar gráficamente diversas métricas relacionadas con el volumen y el rendimiento de los documentos que se sincronizan a través de App Services y para un determinado App Endpoint. Estas métricas incluyen:
-
- App Services Nivel de nodo:
- Bytes enviados y recibidos por nodo
- Utilización de la CPU y la memoria
- App Endpoint level:
- Total de fallos y aciertos de autenticación
- Sincronizaciones delta solicitadas y enviadas
- Total de documentos importados, leídos, escritos y rechazados
- Número de activos réplicas pull-only
- App Services Nivel de nodo:
API de métricas de Capella App Services
Aunque la interfaz de usuario web proporciona un conjunto completo de métricas, es posible que necesite información más detallada y personalizable para satisfacer sus necesidades específicas de supervisión. En tales casos, se puede utilizar la API de métricas de App Services. Esta API proporciona datos en formato Prometheus, lo que le permite obtener una amplia gama de métricas mediante programación.
En API de métricas de App Services ofrece una forma de acceder a métricas en tiempo real relacionadas con Capella App Services. Proporciona un amplio conjunto de métricas a diferentes niveles para supervisar y analizar el rendimiento del sistema.
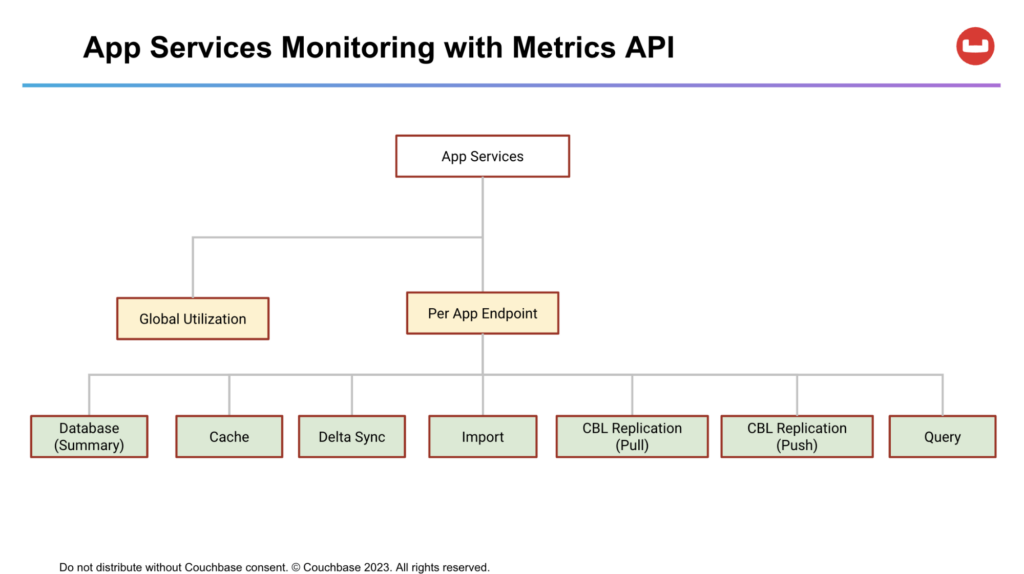
Estas métricas incluyen estadísticas globales de utilización del clúster, que ofrecen información sobre el consumo general de recursos de un nodo de App Services. Una instancia de App Service consta de varios nodos.
Para cada nodo, la API también ofrece métricas por App Endpoint, permitiendo a los usuarios examinar las características específicas de rendimiento y patrones de utilización de endpoints individuales dentro de un nodo. Estas métricas incluyen utilización de Caché, Delta Sync, Importación, Replicación de Couchbase Lite (Push y Pull) y métricas relacionadas con Consultas.
Prometeo
Prometeo es una plataforma de alerta y supervisión de sistemas de código abierto alojada en Fundación para la Computación Nativa en la Nube. Su núcleo es la Servidor Prometheus que se encarga de sondear los "objetivos de Prometheus" en busca de métricas y almacenarlas como datos de series temporales. Los objetivos de Prometheus se configuran estáticamente o pueden ser descubiertos por Prometheus.
Grafana
Grafana es una plataforma de alerta y visualización de datos de código abierto. Admite Prometheus como fuente de datos y puede utilizarse para crear cuadros de mando completos.
Arquitectura de implantación
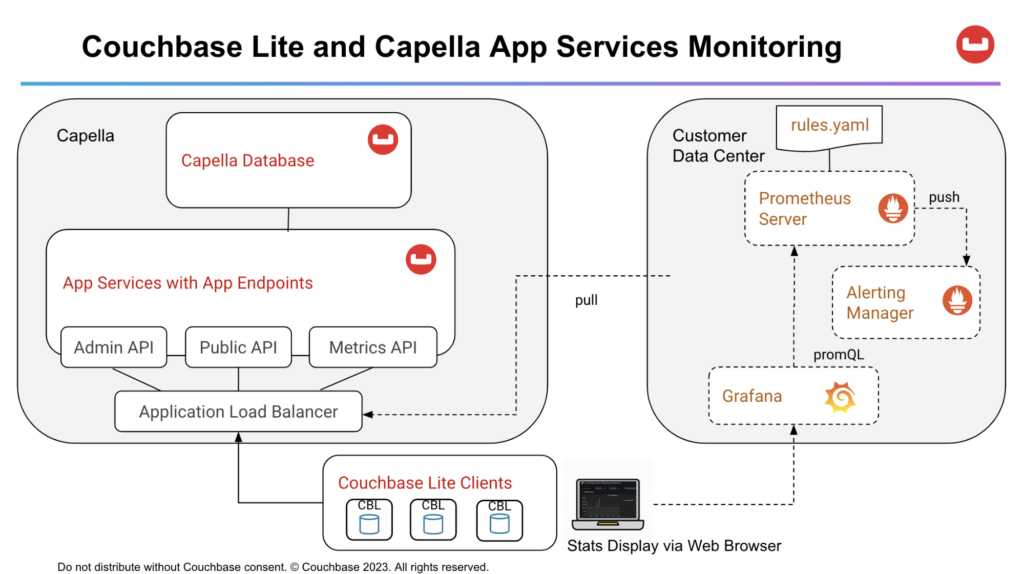
-
- Servidor Prometheus sondea continuamente la API de métricas que devuelve el formato Prometheus para las métricas. El servidor utiliza las reglas definidas en el rules.yaml para enviar alertas al Gestor de alertas.
- Grafana sondea el servidor Prometheus en busca de métricas y las representa gráficamente en un panel basado en web al que se puede acceder a través del navegador web.
Configurar Capella App Services para acceso a métricas
Antes de proceder con este paso, es importante asegurarse de que tiene Capella App Services configurado y funcionando. Si aún no lo ha hecho, puede seguir la detallada tutoriales proporcionado por Capella para configurar una base de datos de muestra, importar datos relevantes y crear un punto final de App. Esto asegurará que usted tiene la base necesaria en su lugar para seguir con eficacia a lo largo de este tutorial.
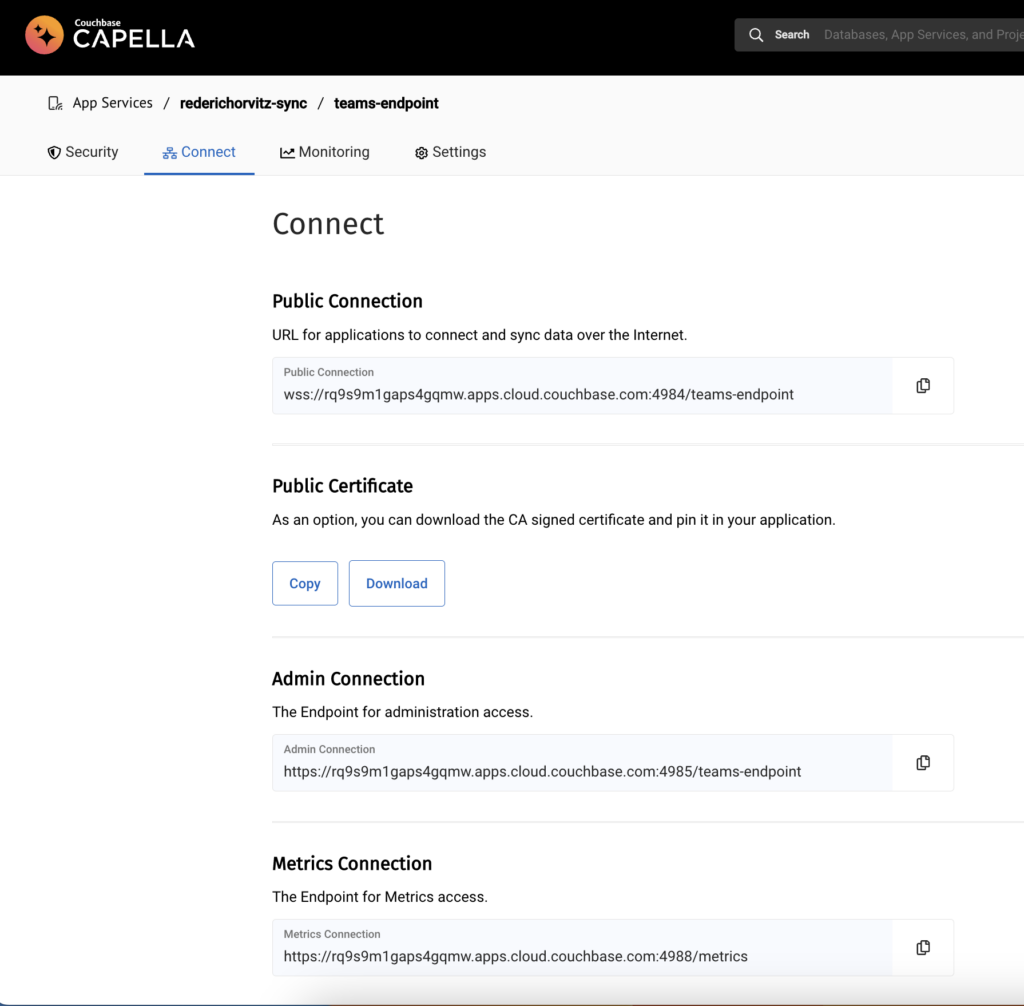
En primer lugar, vaya a la página Conectar pantalla de un App Endpoint:
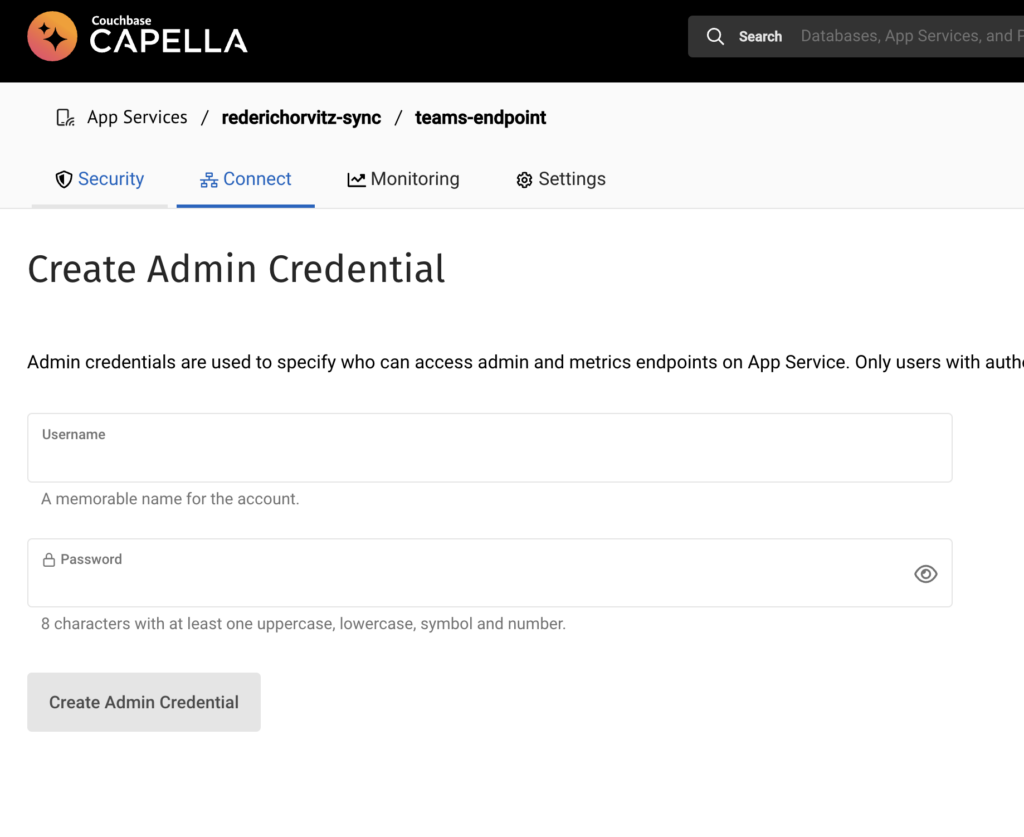
Configuración de las credenciales de administrador: Configure las credenciales de administrador para el punto final de su aplicación. Esto garantiza que sólo los usuarios autenticados con privilegios de administrador puedan acceder a los puntos finales de administración y métricas. Se recomienda encarecidamente implementar la autenticación, ya que mejora la seguridad del acceso a los datos a través de la API de métricas.
Configure las direcciones IP permitidas: Para permitir que el host extraiga métricas de la API de métricas de Capella App Services, debe añadir su dirección IP a la configuración "Permitir direcciones IP". Asegúrese de proporcionar la dirección IP en formato CIDR. Este paso garantiza que se permita al host designado acceder y recuperar métricas de la API.
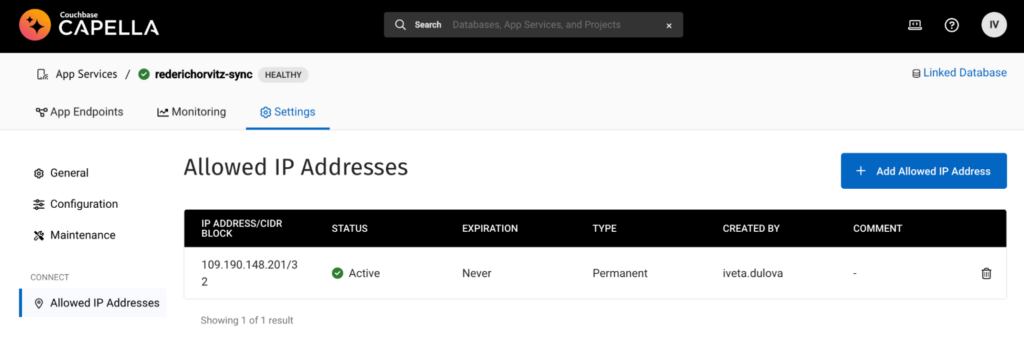
Validar acceso a URL de métricas: Pruebe el punto final de la API de métricas localmente utilizando cURL para verificar que tiene acceso a las métricas con el nombre de usuario y la contraseña suministrados, por ejemplo. curl -u usuario:contraseña metricsEndpointUrl.

En el resultado anterior, podemos observar métricas por punto final que ofrecen información sobre puntos finales específicos de App Services. Una de estas métricas, sgw_database_dcp_received_timemide el tiempo que tarda un documento en ser recibido por Sync Gateway a través de DCP tras una operación de escritura. Estas métricas por punto final llevan el prefijo base_de_datos_sgw y tener entradas separadas para cada uno de los nodos y endpoints de App Services.
Además, la API de métricas de formato de Prometheus proporciona métricas por nodo que permiten supervisar la utilización global de los nodos. Estas métricas abarcan varios aspectos como el uso de la memoria, la utilización de la CPU y las estadísticas de montón y pila. Con el prefijo nodoEstas métricas ofrecen información específica de cada nodo. Por ejemplo, una métrica como bytes de memoria libres indica la cantidad de memoria disponible en un nodo concreto.
Arriba se pueden ver ejemplos de métricas por punto final, tales como sgw_database_dcp_received_timeque indica el tiempo transcurrido entre la escritura de un documento y su recepción por Sync Gateway a través de DCP. Las métricas por punto final llevan el prefijo base_de_datos_sgw y tienen entradas separadas para cada uno de los nodos de App Services. También hay métricas por nodo, como las métricas de utilización global de los nodos, por ejemplo, estadísticas relacionadas con la memoria, la CPU, el montón y la pila. Éstas llevan el prefijo nodo, como el bytes de memoria libres ejemplo de la captura de pantalla.
Los consumidores pueden agregar y transformar estas métricas para que sean por App Endpoint en función de su caso de uso.
Establecimiento de un marco de supervisión
En un escenario del mundo real, un marco de monitorización se configuraría normalmente en su centro de datos o en la nube. Sin embargo, para esta discusión, vamos a utilizar una máquina de desarrollo local. Esto sirve como entorno controlado para comprender la configuración antes de implementarla a mayor escala. Para obtener una guía práctica, consulte la integración de Prometheus de Amazon CloudWatch para EC2: Agente de CloudWatch PrometheusEC2.
Creación de una red Docker
Cuando se utiliza Docker, se recomienda ejecutar todos los componentes en la misma red Docker. Cree una red Docker denominada control: docker network create monitoring
Configuración de Prometheus
-
- Saca el último Imagen Docker de Prometheus: docker pull prom/prometheus
- Crear un local prometheus.yml y modifíquelo para que contenga lo siguiente:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
global: scrape_interval: 5s evaluation_interval: 5s scrape_configs: job_name: app-services metrics_path: /metrics scheme: https basic_auth: username: {{admin_username}} password: {{admin_password}} static_configs: - targets: ['{{target_app_services_metrics_url}}'] |
Sustituir los marcadores de posición {{admin_username}} y {{contraseña_admin}} con las credenciales de administrador que creó en el Configurar la API de métricas de Capella App Services sección.
En {{target_app_services_metrics_url}} se refiere al Métricas que se encuentra en la sección Conectar de su punto final de aplicación. Al añadir esta URL a la matriz de objetivos de configuración de Prometheus, asegúrese de eliminar el protocolo (https://), puesto que ya está especificado en el esquema: https campo. Además, elimine /métricas de la URL tal y como se especifica en metrics_path.
Opcional: Si desea utilizar las métricas de Prometheus App Services para definir alertas de eventos como fallos de autenticación o acceso a documentos, puede crear una métrica local de rules.yml dentro de un archivo /reglas y utilizar algunos de nuestros ejemplos como punto de partida, pero puede personalizar el archivo y añadir más alertas basadas en las métricas de App Services de la API de métricas.
Además, debe incluir rule_files en su archivo prometheus.yml véase el ejemplo siguiente. La ruta /etc/prometheus/rules/* indica la ubicación de los archivos de reglas dentro del contenedor Prometheus y es relativa al sistema de archivos del contenedor.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
rule_files: - '/etc/prometheus/rules/*' groups: - name: app-service.rules rules: - record: sgw::gsi::total_queries expr: sum by (instance, database, job) ({__name__=~"sgw_gsi_views_.*_count"}) - alert: TooManyDocumentAccessFailuresInLastHour expr: deriv(sgw_security_num_access_errors[1h]) > 1000 for: 1m labels: severity: warning annotations: summary: Too many Document Access Failures in Last Hour - alert: TooManyDocumentRejectionFailuresInLastHour expr: deriv(sgw_security_num_docs_rejected[1h]) > 1000 for: 1m labels: severity: warning annotations: summary: Too many Document Rejection Failures in Last Hour - alert: GlobalErrorCount expr: increase(sgw_resource_utilization_error_count[1h]) > 1 for: 1m labels: severity: warning annotations: summary: An error occurred in the last hour - alert: WarnXattrSizeCount expr: increase(sgw_database_warn_xattr_size_count[1h]) > 0 for: 1m labels: severity: warning annotations: summary: A document had larger sync data than the maximum allowed by xattrs in the last hour |
Estas reglas servirán como desencadenantes de las alertas de Prometheus. Para obtener información detallada sobre la redacción de alertas en Prometheus, consulte la sección Reglas de alerta de Prometheus documentación.
Inicie el contenedor Docker Prometheus utilizando el siguiente comando. Modifíquelo para adaptarlo a su contexto:
|
1 |
docker run -p 9090:9090 --name prometheus -d -v `pwd`/prometheus.yml:/etc/prometheus/prometheus.yml --network=monitoring prom/prometheus |
-
- -nombre prometheus: Este parámetro establece un nombre personalizado para el contenedor. En este caso, el contenedor se llama prometheus. Puede hacer referencia a este nombre cuando interactúe con el contenedor más adelante.
- -d: Este parámetro ejecuta el contenedor en modo separado, lo que significa que se ejecuta en segundo plano y no se conecta al terminal.
- -v
pwd/prometheus.yml:/etc/prometheus/prometheus.yml: Este parámetro especifica un montaje de volumen, lo que le permite asignar un archivo o directorio en la máquina host a una ubicación dentro del contenedor. Esto le permite proporcionar un archivo de configuración personalizado para Prometheus. - (Opcional) -v pwd/rules:/etc/prometheus/rules: Este parámetro especifica otro montaje de volumen, mapeando el directorio rules desde el directorio rules en la máquina anfitriona a la ruta /etc/prometheus/rules dentro del contenedor. Esto le permite proporcionar archivos de reglas personalizados para Prometheus.
- -vigilancia de la red: Especificando que Prometheus debe conectarse a la red de "monitorización".
- prom/prometheus: Este es el nombre de la imagen Docker que se utilizará para crear el contenedor. En este caso, se utiliza el prom/prometheus de Docker Hub.
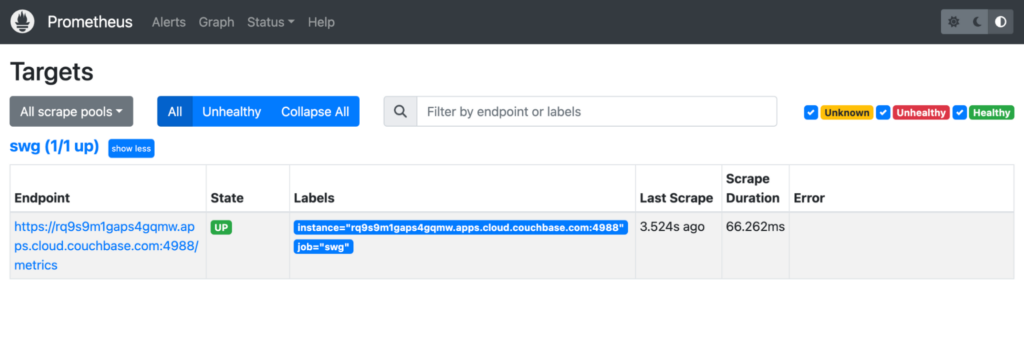
Ahora debería poder abrir el panel de Prometheus en https://localhost:9090 y compruebe que el objetivo responde con Estado=UP. Los objetivos de Prometheus son los puntos finales o servicios que Prometheus rastrea en busca de métricas. Cuando un objetivo se etiqueta como estado: arriba en Prometheus, significa que Prometheus alcanzó y raspó con éxito el objetivo, y se considera sano y disponible.
Visualización de métricas
Uso de la interfaz web de Prometheus
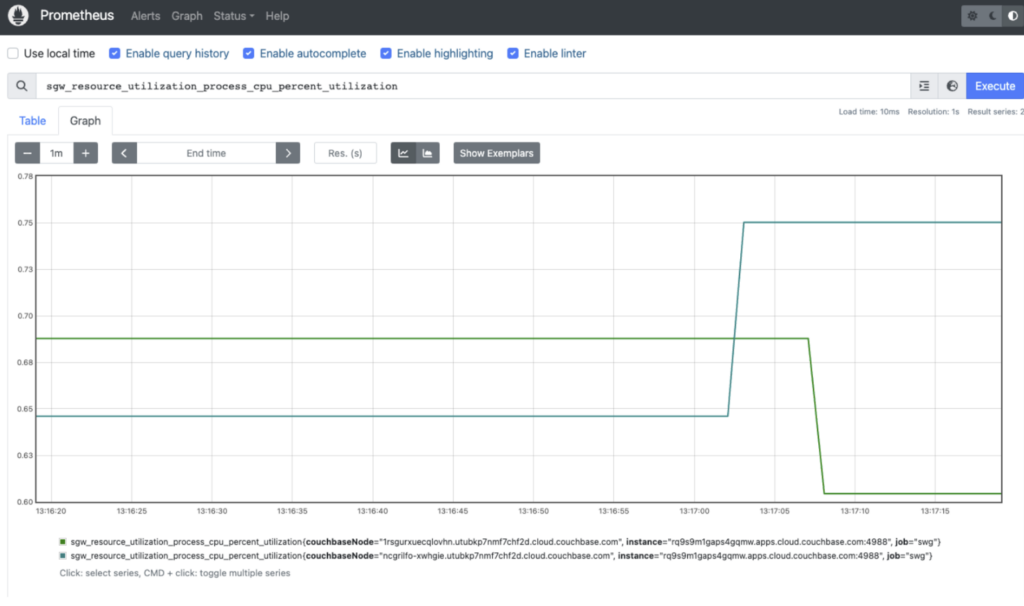
Ahora puede visualizar los datos de la API de métricas de su punto final de aplicación mediante la interfaz de usuario web de Prometheus en localhost. La API de métricas proporciona una amplia gama de métricas disponibles que pueden explorarse utilizando el Explorador de métricas de Prometheus. Puede hacer clic en la pestaña Graph y, a continuación, seleccionar uno de los atributos del menú desplegable, por ejemplo sgw_resource_utilization_process_cpu_percent_utilization y haga clic en Ejecutar.
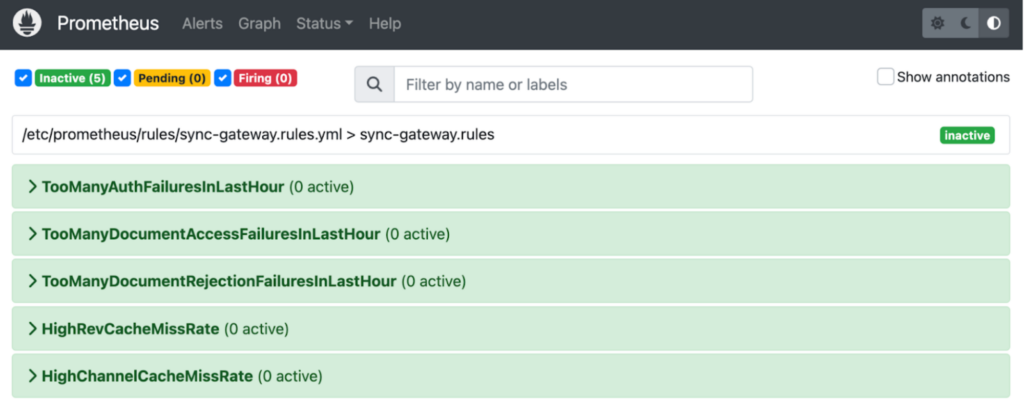
Opcional: Si ha optado por crear un rules.yml con reglas de alerta, las reglas de alerta personalizadas se incluyen en la imagen Docker y se montan en /rules:/etc/prometheus/rules. Como resultado, estas alertas pueden observarse ahora fácilmente en la interfaz de usuario web de Prometheus.
Uso de Grafana
En lugar de utilizar la interfaz web de Prometheus para visualizar las estadísticas, utilizaremos Grafana, ya que ofrece la posibilidad de crear cuadros de mando cautivadores y se integra a la perfección con Prometheus. Para iniciar Grafana y consumir métricas de su servidor Prometheus en contenedores, puede seguir estos pasos:
Tirar último Imagen Docker de Grafana:
|
1 |
docker pull grafana/grafana |
Inicie el contenedor Grafana Prometheus utilizando el siguiente comando y modifíquelo para adaptarlo a su contexto:
|
1 |
docker run -d -p 3000:3000 --name grafana --network monitoring grafana/grafana |
Por defecto, cuando el contenedor Grafana se mata o se detiene, los datos almacenados dentro del contenedor se perderán. Puede utilizar una base de datos para persistir los cuadros de mando y otros metadatos esenciales. Para obtener más información, consulte la Documentación de Grafana.
Abrir la URL https://localhost:3000 en un navegador web. Debería ver el icono Iniciar sesión pantalla. Inicie sesión con las credenciales predeterminadas de admin y contraseña de admin. Puede cambiarlo después del inicio de sesión inicial.

Añade Prometheus como fuente de datos: En la interfaz de usuario de Grafana, vaya a la sección Configuración y seleccione Fuentes de datos. Haga clic en Añadir fuente de datos y elija Prometeo como tipo de fuente de datos. Configure el origen de datos Prometheus: Proporcione los detalles necesarios para configurar la fuente de datos de Prometheus.
Establezca la URL en https://{{containerIPAddress}}:9090 (suponiendo que su servidor Prometheus en contenedor se ejecuta en el puerto 9090), donde {{dirección IP del contenedor}} puede obtenerse mediante el siguiente comando:
|
1 |
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' <container_id_or_name> |
Configure los demás ajustes necesarios y haga clic en Guardar y probar para verificar la conexión con Prometheus.
Una vez establecida la conexión con la fuente de datos de Prometheus, podemos proceder a construir dashboards de Grafana. Para importar un dashboard desde la UI de Grafana, dirígete a la sección Dashboards y haz clic en Gestione para acceder a la página de gestión del cuadro de mandos. Haga clic en Importar para importar un nuevo cuadro de mandos. He aquí un ejemplo ejemplo dashboard.json para empezar, que incluye paneles para la mayoría de las estadísticas principales de la API de métricas.
Una vez finalizado el proceso de importación, podrá ver e interactuar con los cuadros de mando importados en Grafana. Estos cuadros de mando están conectados a su servidor Prometheus en contenedor, que está configurado como fuente de datos en Grafana. Para acceder a las métricas, navegue a la sección Cuadros de mando y seleccione el cuadro de mando importado recientemente. En algunos casos, es posible que tenga que volver a ejecutar inicialmente las consultas asociadas al cuadro de mando para obtener las últimas métricas.
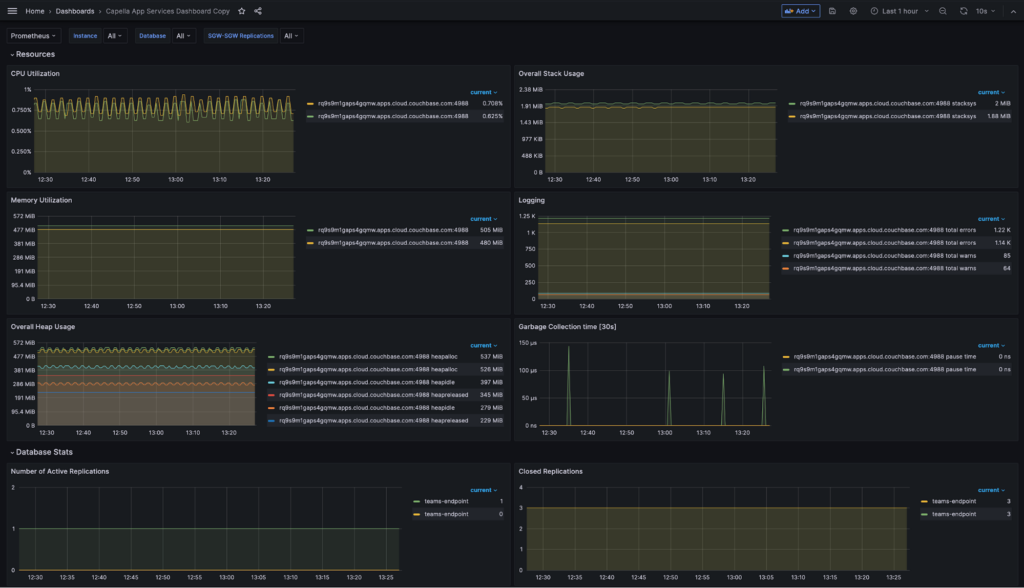
Ya está. Ha configurado correctamente la monitorización con Prometheus y Grafana para Capella App Services. Ahora puede impulsar las réplicas con clientes Couchbase Lite y monitorizarlas. El panel de control predeterminado de Sync Gateway es un punto de partida. Puede personalizar el tablero de instrumentos, ya sea mediante la edición de la dashboard.json o directamente a través de la interfaz de usuario de Grafana.
Conclusión
En conclusión, la utilización de la API de métricas, junto con el despliegue de Prometheus y Grafana, permite una supervisión potente y en tiempo real de las métricas de Capella App Services. Esta integración le dota de la capacidad de detectar y abordar rápidamente las anomalías a través de reglas de alerta personalizadas, lo que conduce a una mayor capacidad de recuperación de la aplicación. Al aprovechar estas tecnologías, puede optimizar el rendimiento y obtener información significativa para sus aplicaciones Couchbase.
Si tiene alguna pregunta o sugerencia, deje un comentario a continuación o póngase en contacto conmigo en iveta.dulova@couchbase.com. En Foros de Couchbase son otro lugar donde puede llegar a nosotros. Valoramos su opinión y esperamos sus noticias.
