Este blog es coautoría de Karen Yuan, becaria de Secundaria
En nuestra Artículo anterior, aprendimos a hacer análisis exploratorio de datos usando el servicio Couchbase Query. También aprendimos a leer eficientemente datos de entrenamiento con las APIs de Query en el Couchbase Python SDK y a guardarlos sin problemas en un dataframe pandas adecuado para machine learning (ML). Y finalmente, almacenamos modelos de ML y sus metadatos en Couchbase. En este artículo, aprenderemos a hacer predicciones, almacenarlas en Couchbase y utilizar los gráficos de Query para analizarlas.
Predicción en tiempo real
El científico de datos utiliza el modelo entrenado para generar predicciones.
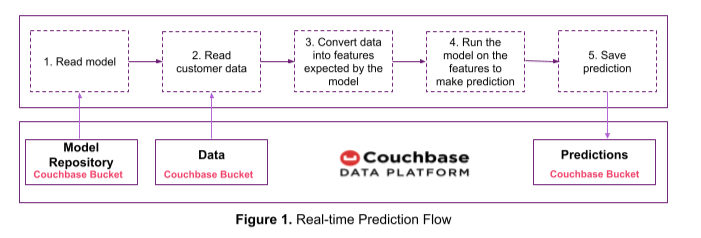
Utilizaremos el flujo de predicción de la Figura 1 para predecir la puntuación del churn en tiempo real y almacenaremos la predicción en Couchbase. Utilizaremos el modelo de predicción de churn que entrenamos en el artículo anterior.
Función para leer el modelo y sus metadatos almacenados en Couchbase:
|
1 2 3 4 5 6 7 |
def read_model_from_couchbase(model_id): bucket = cluster.bucket('model_repository') model_bytes = bucket.get(model_id).value model = pickle.loads(model_bytes) key = model_id + "_metadata" feature_names = bucket.get(key).value['feature_names'] return {'model': model, 'feature_names': set(feature_names)} |
Función para leer datos de clientes almacenados en Couchbase:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# We will use the Query interface in the Couchbase Python SDK to get multiple customer # records that satisfy a condition. Alternatively, the GET interface in the Couchbase Python SDK can # be used to get individual customer records e.g. bucket.get(customer_key).value def read_data_from_couchbase(select_clause = "", where_clause = ""): if select_clause: query_statement = "SELECT customer.*, " + select_clause else: query_statement = "SELECT customer.*" query_statement = query_statement + " FROM `online_streaming` as customer" if where_clause: query_statement = query_statement + " WHERE " + where_clause # Use the Query API to get customer records query_result = cb.query(query_statement) return pd.DataFrame.from_dict(list(query_result)) |
Los siguientes predecir lee el modelo, sus metadatos y los registros de clientes utilizando las funciones anteriores. Convierte los datos del cliente en características utilizando el mismo proceso que el utilizado durante el entrenamiento (es decir, codificación de un solo paso). A continuación, predice la puntuación del churn ejecutando el modelo en las características.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
def predict(model_id, select_clause = "", where_clause = ""): # Step 1: Read the model and its metadata from Couchbase rv = read_model_from_couchbase(model_id) model = rv['model'] feature_names = rv['feature_names'] # Step 2: Read customer records from Couchbase df = read_data_from_couchbase(select_clause, where_clause) customer_prediction = df # Step 3: Convert the raw data into features expected by the model df = pd.get_dummies(df) drop_cols = set(list(df.columns)) - feature_names df.drop(drop_cols, axis = 1, inplace = True) df = df.reindex(columns=feature_names, fill_value=0) # Step 4: Predict prediction = model.predict(df) customer_prediction['Churn Prediction'] = prediction return customer_prediction |
|
1 2 3 |
# Example: Predict churn for a customer with given ID prediction = predict('churn_predictor_model_v1', where_clause = "customer.CustomerID = 100002")[['CustomerID', 'Churn Prediction']] prediction |
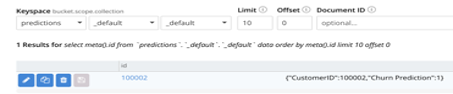
Predicción de rotación para customerID 100002 es 1. Esto indica que es probable que abandonen el servicio de streaming.
![]()
La predicción se guarda en un bucket de Couchbase llamado predictions utilizando el código que se muestra a continuación. Crea el bucket de predicciones en tu clúster de Couchbase antes de continuar.
|
1 2 3 4 |
bucket = cluster.bucket('predictions') to_save = prediction.to_dict(orient="records")[0] key = str(prediction.iloc[0]['CustomerID']) bucket.upsert(key, to_save) |
Comprueba que la predicción se ha guardado correctamente en Couchbase.
También puedes ejecutar el modelo entrenado y generar predicciones en Couchbase Analytics usando la característica Python UDF (actualmente en vista previa para desarrolladores). Consulta el artículo sobre Ejecución de modelos ML con Couchbase Analytics Python UDF para más información.
Análisis hipotético
El científico de datos analizará las predicciones para responder a preguntas que ayuden a tomar decisiones.
El problema que definimos en el artículo anterior era el de un equipo de ventas de una empresa de servicios de streaming en línea que quería saber si el aumento del coste mensual maximizaría los ingresos manteniendo a raya la fuga de clientes.
Para responder a esta pregunta, utilizaremos el siguiente código para predecir las puntuaciones de rotación cuando los costes mensuales aumenten en $1, $2, etc. Los resultados de este análisis se almacenarán en el bucket de predicciones.
Utilizando la interfaz de usuario del clúster Couchbase, cree un ámbito llamado análisis_y_si y la colección denominada aumentar_coste_mensual en el bucket de predicciones. (Los ámbitos y las colecciones están disponibles en Couchbase Server 7.0 y posteriores)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# Connect to predictions bucket on Couchbase and relevant scope and collection bucket = cluster.bucket('predictions') wa_scope = bucket.scope("what_if_analysis") wa_collection = wa_scope.collection("increase_monthly_cost") # Predict the churn rate if the monthly cost of existing customers is increased by # $1, $2 .. $5 for increase_by in range (1, 6): # where_cluase is set to customer.Churn = 0 because we are interested # only in existing customers # The following select_clause will update the MonthlyCost as shown while returning the # query result. In each iteration of this loop the MonthlyCost will increase by $1, $2 ... select_clause = "customer.`MonthlyCost` + " + str(increase_by) + " as `MonthlyCost`" # The updated MonthlyCost is passed as input along with other attributes to the prediction # function. The output tells which of the existing customers are likely to # to churn if the MonthlyCost is increased by the specified amount. rv = predict('churn_predictor_model_v1', select_clause = select_clause, where_clause = "customer.Churn = 0") # Monthly revenues are predicted by adding the monthly cost of the customers not likely to churn. rv['Predicted Monthly Revenue'] = (1 - rv['Churn Prediction']) * rv['MonthlyCost'] predicted_churn_rate = rv['Churn Prediction'].value_counts(normalize=True).mul(100)[1] # Save predictions to Couchbase. to_save = {'Monthly Cost Increase ($)': increase_by, 'Predicted Monthly Revenue': rv['Predicted Monthly Revenue'].sum(), 'Predicted Churn Rate': predicted_churn_rate} key = "increase_by_$" + str(increase_by) wa_collection.upsert(key, to_save) # Use the Query API to calculate current revenue. Store it also on the predictions bucket. This is # used for comparison current = cb.query('SELECT sum(customer.`MonthlyCost`) as CurrentRevenue FROM `online_streaming` customer where customer.Churn = 0') to_save = {'Monthly Cost Increase ($)': 0, 'Predicted Monthly Revenue': list(current)[0]['CurrentRevenue'], 'Predicted Churn Rate': 0} wa_collection.upsert("current", to_save) |
Para analizar los resultados de la predicción mediante Couchbase Query, cree un índice primario en el archivo análisis_y_si tal y como se muestra en la siguiente interfaz de consulta. Tenga en cuenta que el contexto de consulta debe establecerse como se muestra.
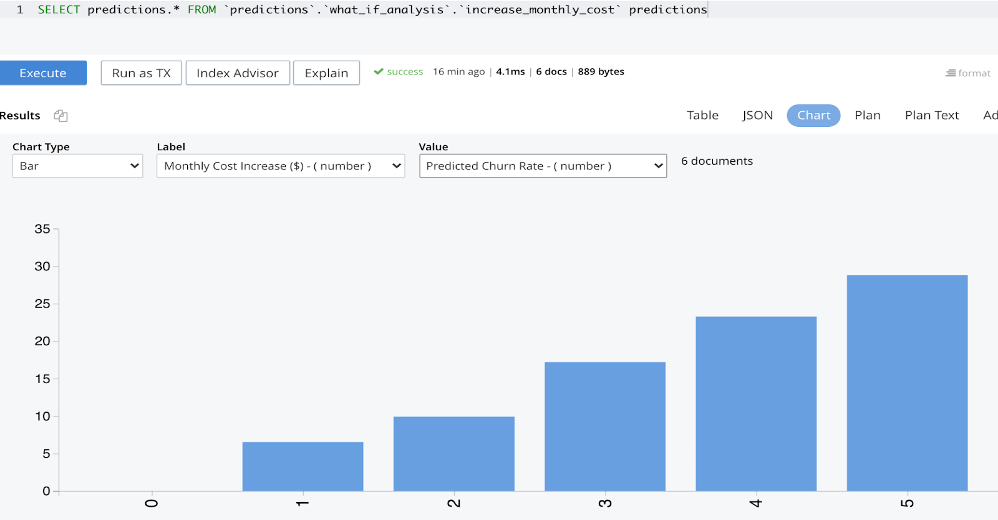
Se pueden utilizar gráficos de consulta para analizar los resultados de la predicción. El gráfico siguiente muestra que se prevé que ~7% de los clientes existentes se darán de baja si su coste mensual aumenta en $1, ~10% probablemente se darán de baja si el coste mensual aumenta en $2, etc.
El gráfico siguiente muestra que los ingresos mensuales actuales son de $3,15 millones. Se prevé que estos ingresos aumenten en ~$50K si el coste mensual de suscripción de los clientes existentes se incrementa en $1 y en ~$230k si el coste mensual se incrementa en $2. Pero se prevé que los ingresos disminuyan si el coste mensual se incrementa en $3 o más debido a la mayor tasa de rotación prevista.
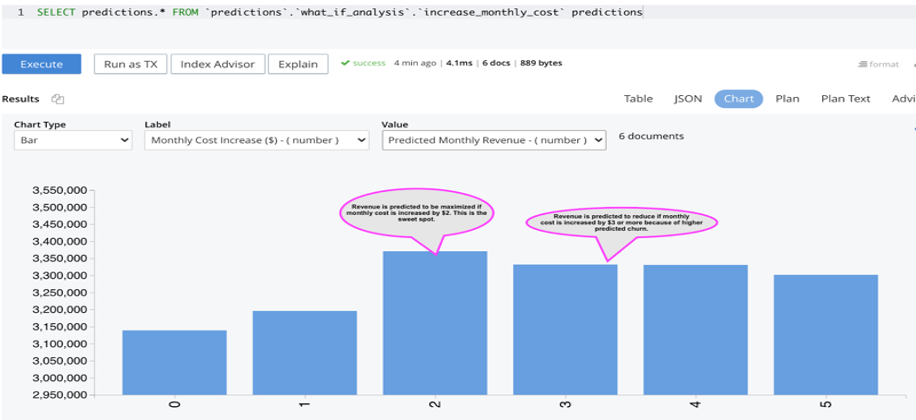
Utilizando este análisis, podemos concluir que el equipo de ventas de la empresa de servicios de streaming online puede aumentar el coste de suscripción mensual en $2 para maximizar los ingresos y mantener a raya la tasa de rotación.
La opción "Descargar gráfico" de la interfaz de consulta permite guardar los gráficos.
Servicio de análisis Couchbase
Hemos utilizado la API de Couchbase Query en el SDK de Python para leer los datos de Couchbase. Si quieres usar la API de Couchbase Analytics en su lugar, aquí tienes un ejemplo para leer los datos de Couchbase y almacenarlos en un dataframe de pandas.
|
1 2 |
analytics_result = cb.analytics_query("SELECT customer.* FROM online_streaming customer") analytics_raw_data = pd.DataFrame(analytics_result) |
El servicio Couchbase Analytics también se puede utilizar para EDA, visualización de datos y para ejecutar modelos ML entrenados (vista previa para desarrolladores). Consulte la Referencia del lenguaje N1QL for Analytics y el artículo sobre Ejecución de modelos ML con Couchbase Analytics Python UDF para más información.
Conclusión
En este artículo y en el anterior, aprendimos cómo Couchbase facilita la ciencia de datos. Usando la predicción de pérdida de clientes como ejemplo, vimos cómo realizar análisis exploratorios usando el servicio Query, cómo leer eficientemente grandes conjuntos de datos de entrenamiento usando el SDK de Python y cómo almacenarlos fácilmente en una estructura de datos adecuada para ML.
También vimos cómo almacenar modelos ML, sus metadatos y predicciones en Couchbase y cómo utilizar los gráficos Query para analizar predicciones.
Couchbase Data Platform se puede utilizar para almacenar datos en bruto, características, modelos ML, sus metadatos y predicciones en el mismo clúster que el que ejecuta los servicios de Query y Analytics. Esto hace que el proceso sea rápido y sencillo al reducir el número de herramientas necesarias para la ciencia de datos.
Próximos pasos
Si estás interesado en aprender más sobre machine learning y Couchbase, aquí tienes algunos pasos a seguir y recursos para empezar:
- Comience su prueba gratuita de Couchbase Cloud - no requiere instalación.
- Couchbase bajo el capó: una visión general de la arquitectura - profundice en los detalles técnicos con este libro blanco.
- Explorar Couchbase Consulta, Búsqueda de texto completo, Eventosy Analítica servicios.
- Consulte estos blogs de ML:
