En la anterior entrada del blog, hablamos de por qué la búsqueda de texto completo es una solución mejor a escala para implementar una búsqueda bien diseñada en su aplicación. En esta segunda parte, vamos a profundizar en el Índice Invertido y explorar cómo los analizadores, tokenizadores y filtros pueden dar forma al resultado de tus búsquedas.
La búsqueda de texto completo consiste en buscar en el texto; por lo tanto, no importa si está indexando y buscando registros, genes en un ADN, su propia estructura de datos y, por supuesto, el lenguaje. En esencia, todos funcionarán casi de la misma manera.
Para darte un ejemplo de cómo puedes usar FTS incluso cuando tienes tu propia estructura personalizada, aprovechemos el hecho de que Apple finalmente compró Shazam y construyamos una aplicación imaginaria parecida a Shazam. Sin embargo, en lugar de escuchar un pequeño fragmento de música como hace Shazam, pediremos al usuario que lo silbe.
Espera... ¿por qué necesito la búsqueda de texto completo?
Como el usuario puede silbar erróneamente algunas partes de la canción, tendremos que dividirla en "pequeños bloques de melodía" y luego intentar cotejarlos con nuestra biblioteca. Suponiendo que nuestra biblioteca tenga miles o incluso millones de canciones (las bibliotecas de Apple y Spotify tienen más de 30 millones de canciones), un simple LIKE "%melody%" no tiene ninguna posibilidad de obtener resultados en un tiempo razonable.
Un índice invertido parece ser la herramienta adecuada para este trabajo, ya que podemos encontrar fácilmente todas las canciones que contienen un bloque determinado de melodía. Si aún no estás familiarizado con este concepto, consulta mi anterior entrada en el blog al respecto.
El Código Parsons
Lo primero que tenemos que hacer es convertir nuestra biblioteca de canciones en texto. Podemos conseguirlo utilizando la función Código Parsons, que es una notación utilizada para identificar una pieza musical según los movimientos del paso arriba y abajo:
- * = primer tono como referencia,
- u = "arriba", para cuando la nota es más alta que la nota anterior,
- d = "abajo", para cuando la nota es más grave que la nota anterior,
- r = "repetir", para cuando la nota tiene la misma altura tonal que la nota anterior.
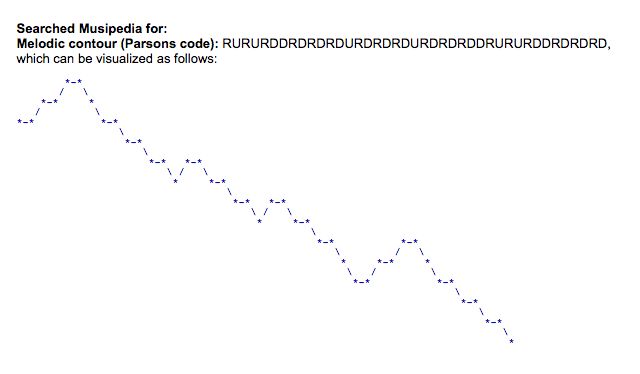
Usando el código parsons, una canción como "Twinkle Twinkle Little Star"se convertirá en *rururddrdrdrdurdrdrdrdrdrdrdrdrdrdrdrdrdrdrdrdrdrdrd.
Aquí está la canción completa:
y aquí está su visualización utilizando el código de Parsons:
Analizadores
Para crear nuestro índice invertido, primero tenemos que preparar nuestro texto, como dividirlo en partes más pequeñas, convertirlo a minúsculas, eliminar palabras irrelevantes, etc. La fase de preparación/análisis suele ejecutarse durante el creación de índices y antes de ejecutar la consulta. De este modo, podemos garantizar que tanto el texto de destino como el término que se busca han sufrido exactamente las mismas transformaciones.
El código responsable de esta transformación se denomina analizador y, a grandes rasgos, agrupamos los analizadores en dos categorías principales: tokenizadores y filtros.
Tokenizadores
Cuando se trata de un idioma, el tokenizador estándar dividirá un texto en palabras. La estrategia de tokenización cambiará ligeramente según el idioma, ya que también debemos tener en cuenta otros caracteres además de los espacios en blanco, como l'amour en francés o "I'm" en inglés.
En Couchbase FTS, el tokenizador estándar funciona la mayor parte del tiempo, pero también proporcionamos tokenizadores para HTML y algunas otras estructuras de datos. Por lo tanto, siempre vale la pena comprobar que me está utilizando el más adecuado.
Idealmente, en nuestra aplicación tipo Shazam, deberíamos crear un tokenizador de n-gramas personalizado, pero para simplificar las cosas, vamos a intentar aprovechar el que viene por defecto. Para ello, tendremos que cambiar ligeramente el código de Parsons insertando un espacio en blanco después de cada 5 letras. La razón es que estoy asumiendo que si el usuario puede silbar correctamente al menos 5 notas seguidas, consideraré eso un "bloque de melodía" e intentaré compararlo con nuestro índice invertido.
Por ello, nuestro "Twinkle Twinkle Little Star"se almacenará como *rurur ddrdr drdur drdrd urdrd rddru rurdd rdrdr d.
Filtros
Couchbase FTS también incluye una variedad de filtros, los tres más populares son potencialmente el hacia_abajo, stop_tokensy stemmer:
- hacia_abajo: Convierte todos los caracteres a minúsculas. Por ejemplo, HTML se convierte en html.
- stop_tokens: Elimina del flujo los tokens considerados innecesarios para una búsqueda de texto completo: por ejemplo, y, es, y el.
- Stemmer: Utiliza libstemmerpara reducir los tokens a tallos de palabras. Por ejemplo, palabras como pesca, pescadoy pescador se reducen a pescado.
Lo ideal es disponer de varios índices para los mismos datos, en los que cada índice utilice una composición de filtros centrados en resaltar una característica específica. Hablaremos más de ello en los próximos artículos.
Para nuestra aplicación tipo Shazam, los filtros podrían no ser necesarios, pero si queremos mejorar nuestros resultados, también podríamos añadir algún tipo de stop_tokens o un filtro de caracteres personalizado.
Por ejemplo, en la mayoría de las canciones pop, el cantante puede gritar durante unos segundos un "Ahhhhhhh" o "Ohhhhhh". Utilizando Parsons Code, se traducirá a una serie de r ("repetir", para cuando la nota tiene la misma altura tonal que la nota anterior). Así, nuestro filtro stop_tokens/custom character podría eliminar cualquier secuencia de diez | veinte "r".
Ex: *rururddrdrdrdurdrdrdrdurdrdrdrddrururrdrdrdrdrrrrrrrrr se convierte en *rururddrdrdrdurdrdrdrdrdrdrdrdrdrdrdrdrdrdrdrdrdrdrd
De este modo, la canción se identificará por su melodía central en lugar de intentar encontrarla por una secuencia de notas repetidas, lo que potencialmente arrojaría resultados erróneos.
Consulta de datos
Ahora que tenemos nuestra biblioteca de canciones debidamente indexada, todo lo que tenemos que hacer es grabar el silbido del usuario, convertirlo en código Parsons y, por último, consultar la base de datos. FTS transformará automáticamente nuestro término de consulta utilizando los mismos tokenizadores y analizadores que hemos empleado para indexar los datos.
Por ahora, vamos a suponer que la consulta simplemente traerá resultados ordenados por el total de coincidencias.
Ex:
Una consulta del tipo rurur ddrdr traerá potencialmente el "Twinkle Twinkle Little Star" ya que tenemos 4 partidos en ella:
*rururddrdrdrdurdrdrdrdrdrddrururddrdrdrd
¿Dónde está la demo?
Vamos a construir otro tipo de aplicación durante esta serie de blogs, pero si usted está interesado en probar una aplicación real que implementa algo similar a lo que he descrito aquí, echa un vistazo a Midemi.
Conclusión
El objetivo de este artículo era mostrar la importancia de los tokenizadores y filtros incluso cuando estamos tratando con otros tipos de estructuras. Recomiendo encarecidamente leer la documentación oficial al respecto para entender cuál es el mejor caso de uso para cada uno de ellos.
Si ya tienes un buen conocimiento de FTS, puede que te hayas dado cuenta de algunos problemas potenciales con nuestra aplicación similar a Shazam: Como el usuario no suele empezar a silbar la canción desde el principio, podríamos tokenizar el silbido desde un punto diferente al que hemos tokenizado la canción original. Como estamos agrupando la canción en tokens de 5 notas, la probabilidad de tokenizar tanto la música como la consulta del término en el punto correcto es de 1 entre 5.
Ex:
“Twinkle Twinkle Little Star“: rururddrdrdrdurdrdrdrdrdrd
Tokenizado "Twinkle Twinkle Little Star“: rurur ddrdr drdur drdrd urdrd rddru rurdd rdrdr d
Silbato de usuario: rdrdrdurdrdrdurdrd (una parte aleatoria en medio de la canción)
Silbato de usuario tokenizado: rdrdr durdr drdur drd
En el ejemplo anterior, teníamos 2 coincidencias (rdrdr y drdur) por casualidad, pero como están fuera de orden, la puntuación de esta canción se verá seriamente comprometida, lo que puede dar lugar a resultados inesperados.
Serie de búsqueda de texto completo
- Por qué deberías evitar el LIKE % - Parte 2
- Emparejamiento difuso - Parte 3
Veremos cómo resolver este problema y algunos otros en los próximos artículos de esta serie. Mientras tanto, si tienes alguna pregunta, envíame un tweet a @deniswsrosa