Nadie duda de que indexar y consultar con big data es todo un reto. Los macrodatos llegan rápidamente, a gran velocidad, variedad y volumen. 100.000 actualizaciones por segundo y TB de datos para escanear: ¡no se puede hacer esto en tiempo real a menos que se disponga de una indexación sólida! Imagine estas aplicaciones:
- La aplicación de viajes que calcula y registra todos los vuelos y hoteles que has consultado.
- ¡El juego viral en línea que tiene que mostrar el marcador exacto para los mejores jugadores!
- La aplicación de detección de fraudes que necesita ver tu actividad reciente para decidir si la transacción activa con tarjeta de crédito es legítima.
Se trata de casos de uso para consultas que deben hacer frente a una gran cantidad de datos, pero que no pueden comprometerse con los milisegundos como tiempo de respuesta. Si no puede renderizar el itinerarios de viaje, los marcadores o responder a un fraude en tiempo realTodas las apuestas están canceladas. ¡Vale! Esto suena imposible y tú preguntas: "¿Cómo se indexa y consulta este tipo de datos en tiempo real?".
Indexación en sistemas de bases de datos distribuidas
Los sistemas distribuidos ofrecen 2 tipos de indexación;
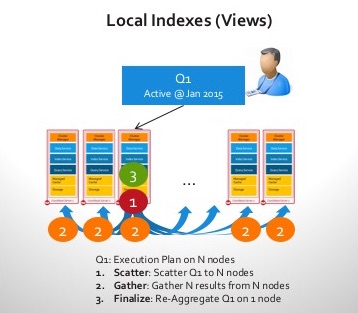
- Índices locales: En el clúster, cada nodo indexa los datos que posee localmente. Esto optimiza la rapidez de indexación. Sin embargo, a medida que aumenta la ingesta de datos, el mantenimiento de los índices a nivel local compite con la carga de trabajo entrante y, a medida que el clúster se hace más grande (más nodos), la dispersión se acumula y afecta a la latencia de la consulta. Imagine esta consulta "Los 10 usuarios más activos del mes de agosto“
|
1 2 3 4 5 6 7 8 9 10 |
#SQL sería algo parecido a esto SELECCIONE nombre_cliente, total_logins.jan_2015 DESDE cesta_cliente DONDE tipo="cliente_perfil" PEDIR POR total_logins.jan_2015 DESC LÍMITE 10; #index para la consulta tendría el siguiente aspecto ÍNDICE EN Cubo_cliente(nombre_cliente, total_logins.jan_2015) DONDE tipo="cliente_perfil"; |
Estos son los pasos a seguir cuando se recibe una consulta en un clúster con un índice local:
- ¡Ningún nodo conoce la respuesta! Así que Scatter tiene que averiguar el "TOP 10" en cada nodo localmente usando el índice local.
- Gather devuelve los "TOP 10″ al nodo coordinador.
- El último paso consiste en volver a clasificar y averiguar los TOP 10 usuarios activos, combinar los resultados de todos los nodos y enviarlos al cliente.
Supongamos que esto se ha hecho sobre 100 nodos y que has añadido tu nodo 101. Nada se vuelve más rápido al ejecutar esta consulta. Todos los nodos siguen haciendo el mismo trabajo, incluido el nuevo nodo. De hecho, ¡el nodo 101 perjudica la latencia de la consulta!
Por cierto, Couchbase Server hace indexación local. Se llama Map/Reduce Views y son fantásticas para aplicaciones complejas de informes interactivos y aplicaciones de cuadros de mando que pueden soportar segundos de latencia. Ver más sobre vistas aquí.
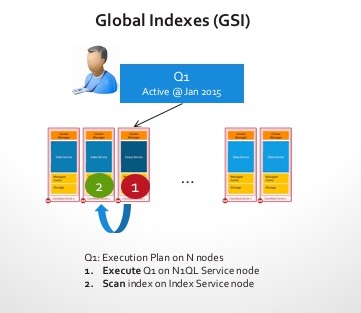
- Índices globales: El índice se particiona independientemente y se coloca lejos de los datos en los nodos. Puede resultar complicado seguir el ritmo de las mutaciones, ya que la indexación de los datos requerirá un acceso a la red. Sin embargo, los índices globales funcionan fantásticamente para las consultas. Imaginemos la misma consulta anterior. El índice se encuentra ahora en uno o dos nodos (tal vez dividido por continentes, como en el ejemplo siguiente).
|
1 2 3 4 5 6 7 8 9 10 |
#index para la consulta tendría el siguiente aspecto ÍNDICE EN Cubo_cliente(nombre_cliente, total_logins.jan_2015) DONDE tipo="cliente_perfil" Y continente="Europa; ÍNDICE EN Cubo_cliente(nombre_cliente, total_logins.jan_2015) DONDE tipo="cliente_perfil" Y continente="America"; ÍNDICE EN Cubo_cliente(nombre_cliente, total_logins.jan_2015) DONDE tipo="cliente_perfil" Y continente="Asia"; |
Estos son los pasos a seguir en cuanto se recibe la consulta en un cluster con un índice global:
- ¡Ahora tenemos un nodo con el índice global que conoce la respuesta! Así que no es necesaria la dispersión. Simplemente recuperamos el recuento de inicio de sesión superior del índice.
- El último paso es enviar los resultados al cliente.
Esos 100 nodos del ejemplo anterior, ¡ahora su nodo 101 puede hacer trabajo de verdad! Las latencias de consulta son mucho más rápidas.
En Couchbase Server, los GSIs también pueden ser desplegados independientemente en una zona separada dentro del cluster usando el servicio de indexación. Esto significa que los nodos de servicio de datos que realizan las operaciones de datos principales (INSERTAR/ACTUALIZAR/ELIMINAR) no tienen que competir con la indexación que se realiza en la otra parte del clúster. Llamamos a esta topología de despliegue MDS y puedes encontrar más información sobre ella aquí.
También puede encontrar un análisis más detallado de las diferencias entre Map/Reduce Views y GSI y sus arquitecturas aquí.
Couchbase Server proporciona GSI (índices secundarios globales) que funcionan de esta manera. Couchbase Server proporciona 2 opciones de almacenamiento para GSIs: GSI estándar y GSI optimizado para memoria. GSI estándar ha estado disponible desde la versión 4.0. Sin embargo GSI optimizado para memoria es nuevo con 4.5. En PARTE II de este postpuede leer más índices globales optimizados para memoria y en qué se diferencian.