¿Qué son los modelos de incrustación?
Los modelos de incrustación son un tipo de modelo de aprendizaje automático diseñado para representar datos (como texto, imágenes u otras formas de información) en un espacio vectorial continuo de baja dimensión. Estos incrustaciones captan las similitudes semánticas o contextuales entre los datos, lo que permite a las máquinas realizar tareas de comparación, agrupación o clasificación con mayor eficacia.
Imagina que quieres describir distintas frutas. En lugar de descripciones largas, utiliza números para características como el dulzor, el tamaño y el color. Por ejemplo, una manzana puede ser [8, 5, 7], mientras que un plátano es [9, 7, 4]. Estos números facilitan la comparación o agrupación de frutas similares.
¿Qué hace un modelo de incrustación?
Un modelo de incrustación convierte texto, imágenes y audio en números significativos y los compara para encontrar patrones o conexiones. Este proceso es similar a la forma en que una biblioteca organiza los libros por género o tema, lo que permite a los usuarios encontrar más rápidamente lo que buscan.
He aquí ejemplos de casos de uso cotidiano para la incrustación de modelos:
Búsqueda de texto
Imagine que escribe "mejor comida griega" en un motor de búsqueda. Un modelo de incrustación convierte la consulta en números y recupera documentos con incrustaciones similares. El modelo mostrará entonces resultados que se acerquen a su consulta.
Recomendar películas
Si te ha gustado una película, el sistema utiliza un modelo de incrustación para representarla (por ejemplo, género, reparto, ambiente) en forma de números. Compara estos números con los de otras películas y recomienda otras similares.
Emparejar imágenes y pies de foto
Un modelo de incrustación puede emparejar una imagen de una puesta de sol sobre el océano con el pie de foto "Una serena puesta de sol sobre las tranquilas olas del océano" convirtiendo tanto la imagen como los posibles pies de foto en representaciones numéricas (incrustaciones). El modelo identifica el título con la incrustación más próxima a la de la imagen, lo que garantiza una correspondencia exacta. Esta técnica permite utilizar herramientas como la búsqueda de imágenes y el etiquetado de fotos.
Agrupar artículos similares
Un sitio web de compras utiliza incrustaciones para agrupar productos similares. Por ejemplo, "zapatillas rojas" pueden estar cerca de "zapatillas azules" en el espacio de incrustación, por lo que se muestran como relacionados.
Tipos de modelos de incrustación
Existen varios modelos de incrustación, cada uno diseñado para distintos tipos de datos y tareas. He aquí los principales tipos:
Modelos de incrustación de palabras
Estos modelos convierten las palabras en vectores numéricos que captan los significados semánticos y las relaciones entre las palabras. Algunos ejemplos son:
-
- Palabra2vec: Aprende incrustaciones de palabras mediante la predicción de una palabra basada en su contexto (skip-gram) o la predicción del contexto basada en una palabra (CBOW).
- GloVe (Vectores Globales para la Representación de Palabras): Un modelo que utiliza estadísticas de co-ocurrencia de palabras de un gran corpus para crear incrustaciones.
- fastText: Similar a Word2vec, pero tiene en cuenta la información de las subpalabras, lo que lo hace más eficaz para las lenguas ricas morfológicamente.
Modelos contextualizados de incrustación de palabras
Estos modelos generan incrustaciones de palabras dinámicas basadas en el contexto en el que aparece una palabra. A diferencia de las incrustaciones estáticas, el significado de una palabra puede cambiar en función de su uso.
-
- BERT (Representaciones codificadoras bidireccionales a partir de transformadores): Genera incrustaciones de palabras basadas en el contexto de las palabras circundantes, lo que lo hace muy eficaz para tareas como la respuesta a preguntas y el análisis de sentimientos.
- GPT (Transformador Generativo Preentrenado): Genera incrustaciones contextualizadas para la generación de textos y otras tareas lingüísticas.
- ELMo (incrustación de modelos lingüísticos): Proporciona incrustaciones de palabras basadas en todo el contexto de la frase, lo que le permite captar significados más profundos.
Modelos de incrustación de frases o documentos
Estos modelos crean incrustaciones que representan frases o documentos enteros en lugar de palabras sueltas.
-
- Doc2vec: Extensión de Word2vec que genera incrustaciones para documentos completos teniendo en cuenta el contexto de las palabras del documento.
- InferSent: Un codificador de frases que aprende a mapear frases en incrustaciones para tareas como la similitud de frases y la clasificación.
Modelos de incrustación de imágenes
Estos modelos representan las imágenes como vectores, lo que permite realizar tareas como el reconocimiento y la recuperación de imágenes.
-
- Redes neuronales convolucionales (CNN): Modelos como ResNet y VGG extraen características de las imágenes y generan incrustaciones de clasificación y reconocimiento de imágenes.
- CLIP (preentrenamiento contrastivo lenguaje-imagen): Un modelo que conecta imágenes y descripciones textuales generando incrustaciones para ambas y alineándolas en el mismo espacio vectorial para tareas como la búsqueda imagen-texto.
Modelos de incrustación de audio y voz
Estos modelos convierten los datos de audio o voz en incrustaciones, útiles para tareas como el reconocimiento del habla y la detección de emociones.
-
- VGGish: Un modelo de incrustación para audio, en particular música y voz, basado en CNN.
- Wav2vec: Un modelo de Meta AI que genera incrustaciones para audio de voz sin procesar, lo que resulta eficaz para tareas de conversión de voz a texto.
Cada modelo está diseñado para manejar tipos específicos de datos y tareas, ayudando a capturar y representar relaciones de forma útil para aplicaciones de aprendizaje automático.
¿Cómo se entrenan los modelos de incrustación?
Los modelos de incrustación se entrenan utilizando grandes conjuntos de datos y objetivos de aprendizaje específicos que los guían para crear representaciones numéricas significativas de los datos. El proceso de entrenamiento implica los siguientes pasos:
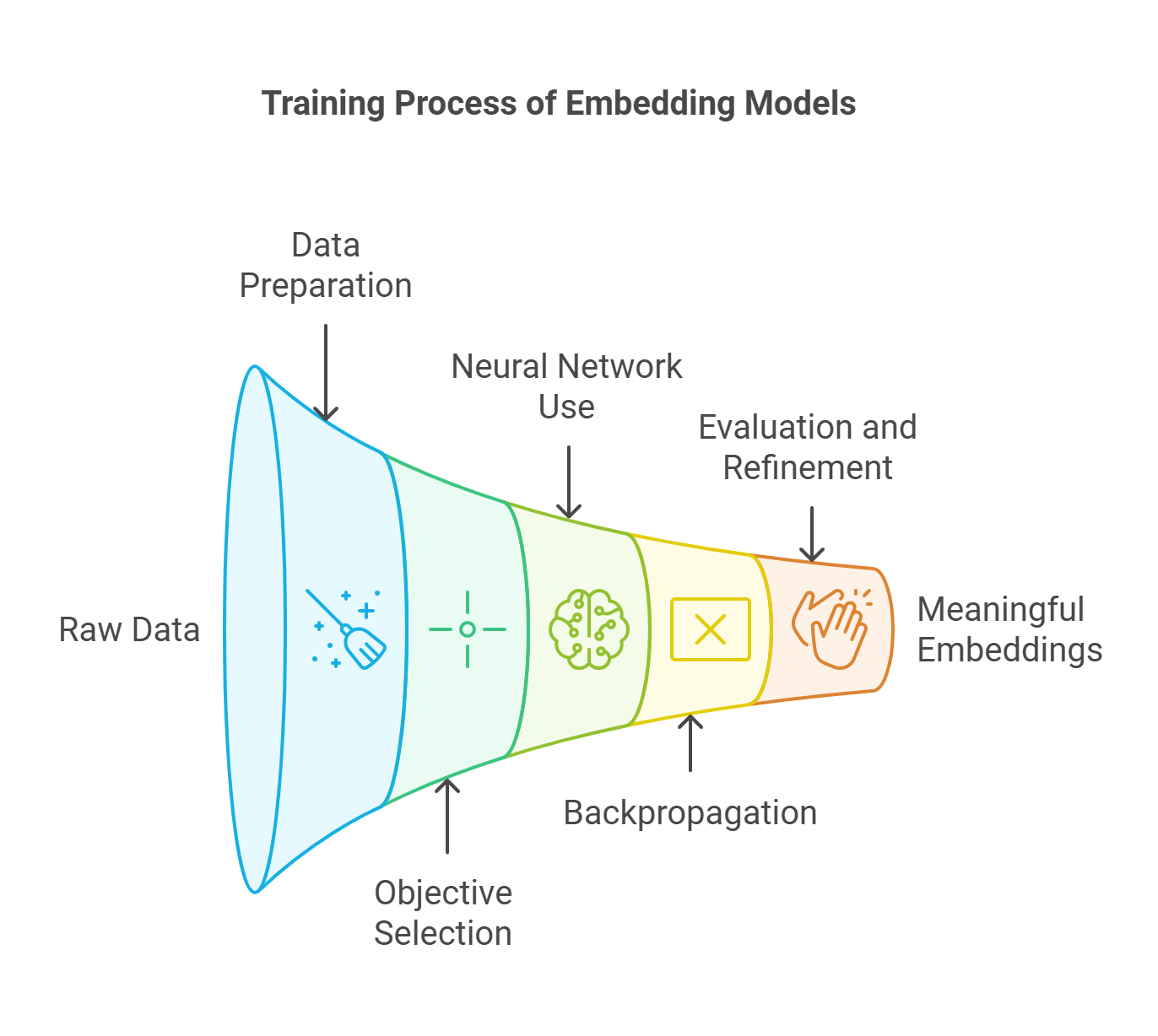
El proceso de formación de los modelos de incrustación
1. Recogida y preparación de datos
-
- Conjuntos de datos: Se necesitan grandes conjuntos de datos (como corpus de texto) para la incrustación lingüística, conjuntos de datos de imágenes etiquetadas para la incrustación visual y conjuntos de datos emparejados (por ejemplo, imágenes y pies de foto) para la incrustación multimodal.
- Preprocesamiento: El texto se tokeniza en palabras o subpalabras, las imágenes se redimensionan y normalizan, y el audio se transforma en espectrogramas u otros formatos.
2. Elegir un objetivo de formación
El modelo aprende a crear incrustaciones optimizando un objetivo específico. Los objetivos más comunes son:
-
- Predicción del contexto (modelos lingüísticos)
-
-
-
- Por ejemplo: El modelo de salto de grama de Word2vec predice las palabras que rodean a una palabra determinada. Si la entrada es "El gato se sentó en el __", el modelo podría predecir "alfombrilla".
-
-
-
- Minimizar las diferencias en los datos relacionados (aprendizaje contrastivo)
-
-
-
- Por ejemplo: En CLIP, una imagen y su pie de foto se acercan en el espacio de incrustación, mientras que las imágenes y los pies de foto no relacionados se alejan.
-
-
-
- Clasificación u objetivos específicos de la tarea
-
-
- Por ejemplo: Un modelo puede predecir si una imagen contiene un perro o un gato. Las incrustaciones se ajustan para facilitar la tarea agrupando imágenes similares.
-
3. Utilización de redes neuronales
-
- Modelos poco profundos: Los primeros modelos, como Word2vec, utilizan redes neuronales sencillas para aprender incrustaciones basadas en patrones de co-ocurrencia.
- Modelos profundos: Los transformadores (por ejemplo, BERT, GPT) y las CNN extraen patrones y relaciones más complejos procesando los datos por capas.
4. Backpropagation y optimización
-
- El modelo hace una predicción, calcula un error (la diferencia entre la predicción y el objetivo) y ajusta sus parámetros mediante retropropagación.
- Un optimizador (como Adam o SGD) actualiza las incrustaciones y los pesos del modelo para minimizar este error.
5. Evaluar y perfeccionar
-
- El modelo se evalúa utilizando datos de validación para garantizar que produce incrustaciones significativas para las tareas previstas.
- Se realizan ajustes como la sintonización de hiperparámetros o el ajuste fino en conjuntos de datos específicos para mejorar el rendimiento.
¿Cómo funcionan los modelos de incrustación?
Veamos ahora cómo funcionan estos modelos:

Proceso de integración del modelo
1. Tratamiento de los datos de entrada
El modelo introduce datos en bruto (por ejemplo, texto, imágenes o audio) y los preprocesa de la siguiente manera:
-
- El texto se tokeniza en unidades más pequeñas, como palabras o subpalabras.
- Las imágenes se dividen en elementos más pequeños, como píxeles o rasgos.
- El audio se convierte en formas de onda o espectrogramas.
2. Extracción de características
El modelo de incrustación analiza la entrada para identificar las características clave:
-
- Con el texto, considera el contexto y el significado de las palabras.
- Con imágenes, detecta patrones visuales, colores o formas.
- Con el audio, identifica tonos, frecuencias o ritmos.
Por ejemplo, Word2vec aprende las relaciones entre palabras basándose en la frecuencia con la que aparecen juntas en un gran conjunto de datos. Por ejemplo, puede darse cuenta de que "rey" y "reina" aparecen con frecuencia en contextos similares y asignarles incrustaciones cercanas en el espacio vectorial.
3. Reducción de la dimensionalidad
Los datos de alta dimensión (por ejemplo, una imagen con millones de píxeles) se comprimen en un vector de menor dimensión. Este vector conserva la información esencial al tiempo que descarta los detalles innecesarios. Por ejemplo, una imagen puede reducirse a un vector de 512 dimensiones, capturando sus características principales sin conservar toda la resolución.
4. Aprendizaje a través de la formación
Los modelos de incrustación se entrenan en grandes conjuntos de datos mediante técnicas de aprendizaje automático para detectar patrones y relaciones. Estas técnicas incluyen:
-
- Aprendizaje no supervisado: El modelo aprende a organizar los datos agrupando palabras o imágenes similares.
- Aprendizaje supervisado: El modelo aprende a alinear incrustaciones con etiquetas específicas o a distinguir entre pares similares y disímiles (por ejemplo, hacer coincidir los pies de foto con las imágenes correctas).
5. Incrustaciones de salida
El modelo genera un vector para cada entrada. Estas incrustaciones pueden ser:
-
- Se comparan utilizando medidas matemáticas como la similitud coseno.
- Agrupados o agrupados para su análisis.
- Se pasa a otros modelos de aprendizaje automático para tareas como la clasificación o la recomendación.
Cómo elegir el modelo de integración adecuado
La elección del modelo de incrustación adecuado depende del tipo de datos con los que trabaje y de la tarea específica que desee realizar. Aquí tienes algunas consideraciones clave que te ayudarán a seleccionar el más adecuado.
Tipo de datos
-
- Texto: Si trabaja con datos de texto, como frases o documentos, elija un modelo en función de si necesita incrustaciones estáticas de palabras o incrustaciones dinámicas basadas en el contexto. (por ejemplo, Word2vec, GloVe, BERT, GPT).
- Imágenes: Si trabaja con imágenes, necesitará un modelo que pueda convertir las características visuales en incrustaciones. (por ejemplo, ResNet, VGG, CLIP).
- Audio: Si trabajas con datos de audio o voz, busca modelos diseñados específicamente para manejar sonido. (por ejemplo, VGGish o Wav2vec).
Requisitos de la tarea
-
- Tareas a nivel de palabras: Si necesita analizar o comparar palabras individuales, modelos como Word2vec o fastText pueden ser adecuados.
- Tareas a nivel de frase o documento: Para tareas que requieren una representación de frases o documentos enteros (por ejemplo, similitud o clasificación), son más adecuados modelos como Doc2vec o BERT.
- Tareas multimodales: Si necesita trabajar con texto e imágenes (u otras combinaciones), los modelos como CLIP o DALL-E son ideales porque alinean incrustaciones de distintos tipos de datos.
Consideraciones sobre el rendimiento
-
- Rapidez y eficacia: Los modelos más sencillos, como Word2vec y GloVe, son más rápidos y consumen menos recursos, por lo que resultan adecuados para conjuntos de datos más pequeños. aplicaciones en tiempo real. Sin embargo, es posible que no capten las relaciones matizadas tan bien como los modelos más complejos.
- Precisión y profundidad: Los modelos más avanzados, como BERT y GPT, proporcionan una gran precisión al captar las relaciones semánticas profundas y el contexto; sin embargo, su entrenamiento es lento y costoso desde el punto de vista informático.
Tamaño del conjunto de datos
-
- Grandes conjuntos de datos: Para grandes conjuntos de datos, modelos como BERT y CLIP, preentrenados con grandes cantidades de datos, pueden ajustarse a tareas específicas.
- Conjuntos de datos más pequeños: Si dispone de datos limitados, modelos como fastText o Word2vec pueden ofrecer mejores resultados, ya que pueden entrenarse con menos puntos de datos.
Modelos preformados frente a formación personalizada
-
- Si está trabajando en una tarea general y no necesita un modelo altamente especializado, el uso de incrustaciones preentrenadas de modelos como BERT, GPT o ResNet suele ser suficiente y ahorra tiempo.
- Si sus datos son muy específicos (por ejemplo, un dominio o un idioma nicho), puede que necesite ajustar un modelo preentrenado o entrenar un modelo personalizado.
Conclusión
En este post, exploramos cómo los modelos de incrustación ayudan a transformar datos complejos, como texto, imágenes o audio, en representaciones numéricas simplificadas que los ordenadores pueden entender y procesar con eficacia. Al aprender las relaciones y los patrones de los datos, estos modelos permiten aplicaciones que van desde el procesamiento del lenguaje natural hasta el reconocimiento de imágenes y las tareas multimodales. Elegir el modelo de incrustación adecuado depende de factores como el tipo de datos, la tarea específica, el tamaño del conjunto de datos y los recursos informáticos disponibles.
Puedes visitar estos recursos de Couchbase para seguir aprendiendo sobre incrustaciones vectoriales y búsqueda: