Hace un mes, Kubernetes lanzó una versión beta para Volúmenes Persistentes Locales. En resumen, significa que si un Pod que utiliza un disco local muere, no se perderá ningún dato (ignoremos los casos extremos). El secreto es que un nuevo Pod será reprogramado para ejecutarse en el mismo nodo, aprovechando el disco que ya existe allí.
Por supuesto, su desventaja es que estamos atando nuestro Pod a un nodo específico, pero si tenemos en cuenta el tiempo y el esfuerzo invertidos en cargar una copia de los datos en otro lugar, poder aprovechar el mismo disco se convierte en una gran ventaja.
Las bases de datos nativas de la nube, como Couchbase, están diseñadas para manejar con gracia los fallos de nodos o Pods. Normalmente, esos nodos están configurados para tener al menos 3 réplicas de los datos. Por lo tanto, incluso si pierdes uno, otro tomará el relevo, y el gestor de clúster o un DBA activará un proceso de reequilibrio para garantizar que sigue teniendo las mismas 3 copias.
Cuando reunimos el Patrón de reparación automática de Kubernetes, los volúmenes persistentes locales y el proceso de recuperación de las bases de datos nativas de la nube, acabamos con un mecanismo de autorreparación muy coherente. Esta combinación es ideal para casos de uso que exigen alta disponibilidad, es por eso que la ejecución de bases de datos en Kubernetes se está convirtiendo en un tema tan candente hoy en día. He mencionado en un entrada anterior algunas de sus ventajas, pero hoy me gustaría demostrárselo en acción para mostrarle por qué es una de las próximas grandes cosas.
Veamos lo fácil que es desplegar, recuperarse de fallos de pods y escalar hacia arriba y hacia abajo una base de datos para Kubernetes:
Transcripción de vídeos
Configuración de su clúster Kubernetes
Empecemos por configurar tu clúster Kubernetes. Para esta demostración, hago no recomendamos utilizar MiniKube. Si no dispone de un clúster para realizar pruebas, puede crear uno rápidamente utilizando herramientas como Stackpoint.
Archivos YAML
Todos los archivos utilizados en el vídeo están disponibles aquí:
|
1 |
https://github.com/deniswsrosa/microservices-on-kubernetes/tree/master/kubernetes |
Despliegue del operador Kubernetes de Couchbase
Un Operador en Kubernetes, desde una visión general de 10000 pies, es un conjunto de controladores personalizados para un propósito determinado. En esta demostración, el operador es responsable de unir nuevos nodos al clúster, activar el reequilibrio de datos y escalar correctamente la base de datos en Kubernetes:
- Configurar los permisos:
|
1 |
./rbac/create_role.sh |
- Despliegue del operador:
|
1 |
kubeclt create -f operator.yaml |

Puede consultar la documentación oficial aquí.
Despliegue de una base de datos en Kubernetes
- Vamos a crear el nombre de usuario y la contraseña que vamos a utilizar para iniciar sesión en la consola web:
|
1 |
kubeclt create -f secret.yaml |
- Por último, vamos a desplegar nuestra base de datos en Kubernetes simplemente ejecutando el siguiente comando:
|
1 |
kubeclt create -f couchbase-cluster.yaml |
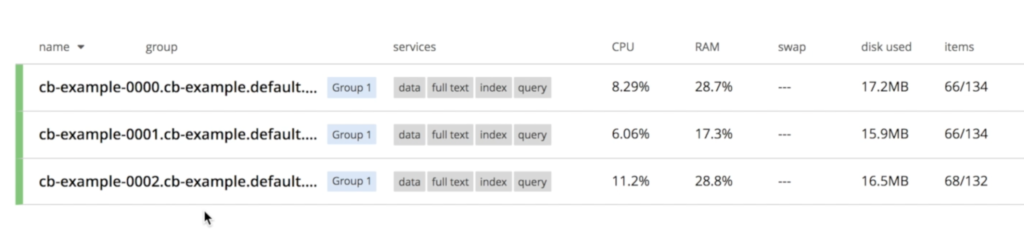
Después de unos minutos, notará que su base de datos con 3 nodos está funcionando:
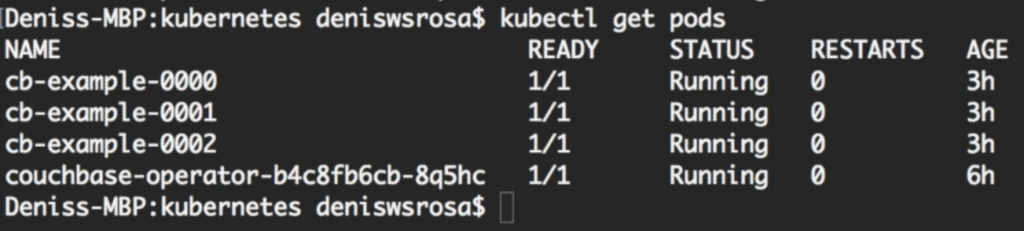
No voy a entrar en demasiados detalles sobre cómo couchbase-cluster.yaml obras (doc oficial aquí). Pero me gustaría destacar dos sesiones importantes de este expediente:
- La siguiente sesión especifica el nombre del bucket y el número de réplicas de los datos:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... buckets: - name: couchbase-sample type: couchbase memoryQuota: 128 replicas: 3 ioPriority: high evictionPolicy: fullEviction conflictResolution: seqno enableFlush: true enableIndexReplica: false ... |
- La siguiente sesión especifica el número de servidores (3) y qué servicios deben ejecutarse en cada nodo.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... servers: - size: 3 name: all_services services: - data - index - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data ... |
Acceso a su base de datos en Kubernetes
Hay muchas maneras de exponer la consola web al mundo externo. Entradapor ejemplo, es uno de ellos. Sin embargo, para el propósito de esta demostración, vamos simplemente a reenviar el puerto 8091 del pod cb-example-0000 a nuestra máquina local
|
1 |
kubectl port-forward cb-example-0000 8091:8091 |
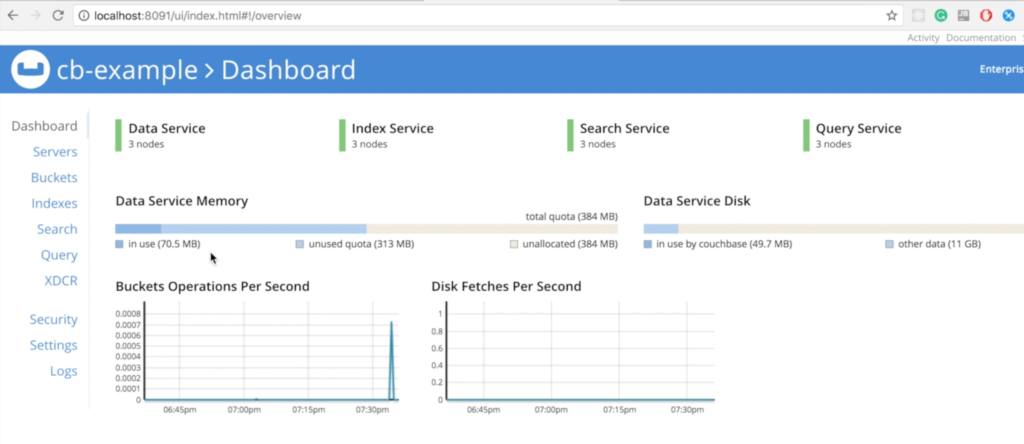
Ahora, debería poder acceder a la consola web de Couchbase en su máquina local en https://localhost:8091:
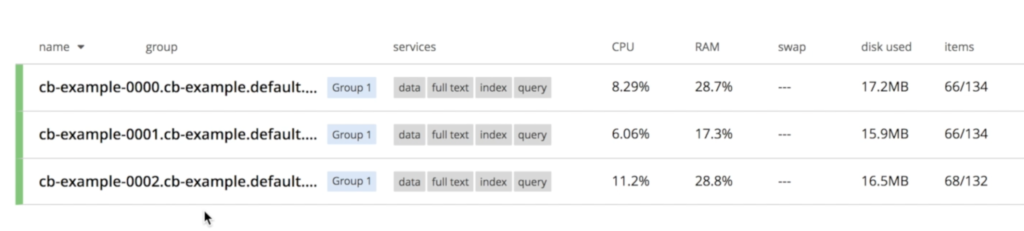
Observa que los tres nodos ya están hablando entre sí:
Recuperación de un fallo de nodo de base de datos en Kubernetes
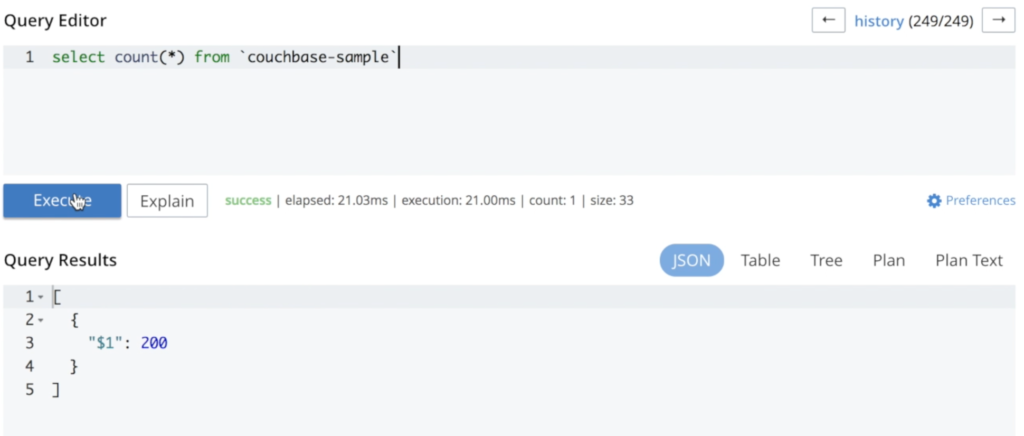
He añadido algunos datos para ilustrar que no se pierde nada durante todo el proceso:
Ahora, podemos eliminar un pod para ver cómo se comporta el cluster:
|
1 |
kubectl delete pod cb-example-0002 |

Couchbase se dará cuenta inmediatamente de que un nodo "desapareció" y se iniciará el proceso de recuperación. Como especificamos en couchbase-cluster.yaml que siempre queremos 3 servidores funcionando, Kubernetes iniciará una nueva instancia llamado cb-ejemplo-0003:
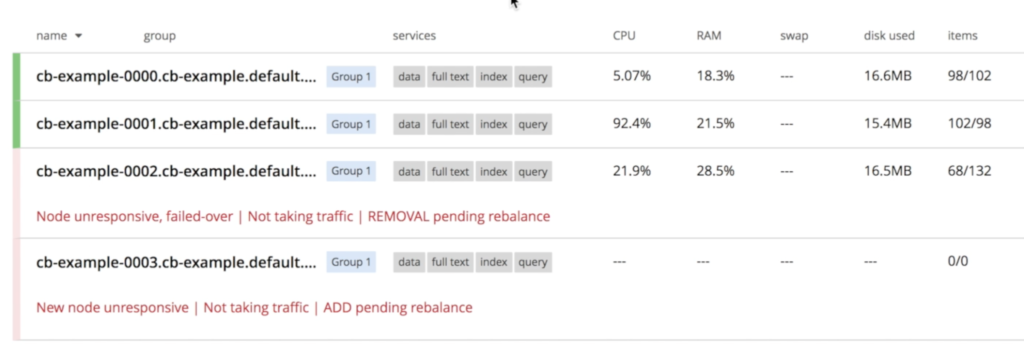
Una vez cb-ejemplo-003 el operador se encarga de unir el nodo recién creado al clúster y, a continuación, activa el reequilibrio de datos.
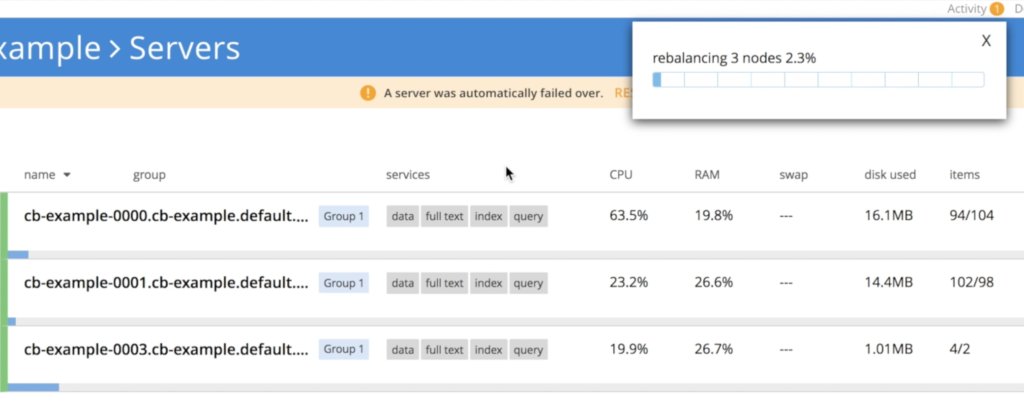
Como puede ver, no se ha perdido ningún dato durante este proceso. Si se vuelve a ejecutar la misma consulta, se obtiene el mismo número de documentos:
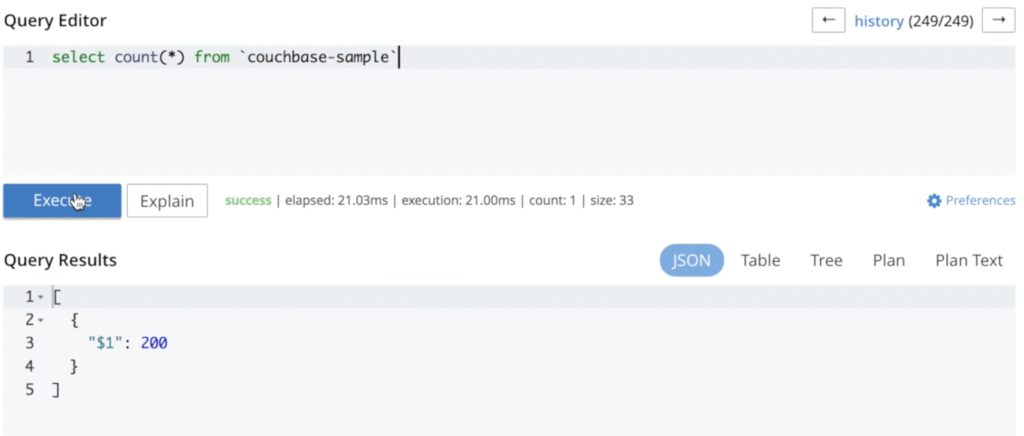
Ampliación de una base de datos en Kubernetes
Aumentemos la escala de 3 a 6 nodos; todo lo que tenemos que hacer es cambiar el parámetro talla parámetro en couchbase-cluster.yaml:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... servers: - size: 6 name: all_services services: - data - index - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data ... |
A continuación, actualizamos nuestra configuración ejecutando:
|
1 |
kubectl replace -f couchbase-cluster.yaml |
Después de unos minutos verás que se han creado los 3 nodos adicionales:
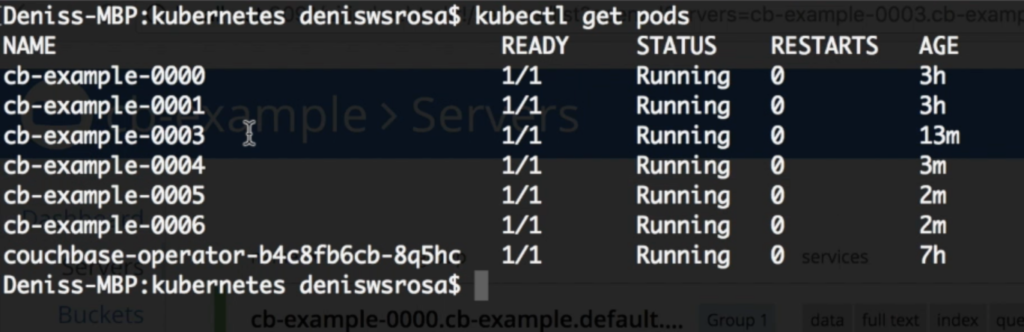
Y de nuevo, el operador reequilibrará automáticamente los datos:
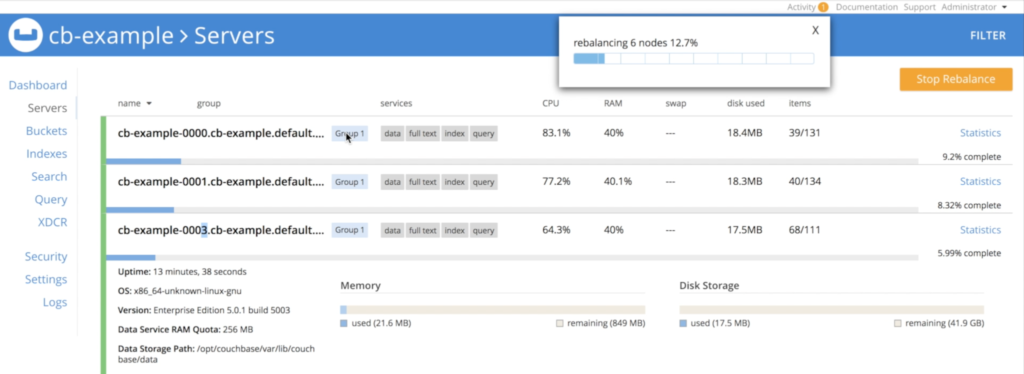
Reducción de una base de datos en Kubernetes
El proceso de reducción es muy similar al de ampliación. Todo lo que tenemos que hacer es cambiar el talla de 6 a 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... servers: - size: 3 name: all_services services: - data - index - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data ... |
Y luego, ejecutamos de nuevo el comando replace para actualizar la configuración:
|
1 |
kubectl replace -f couchbase-cluster.yaml |
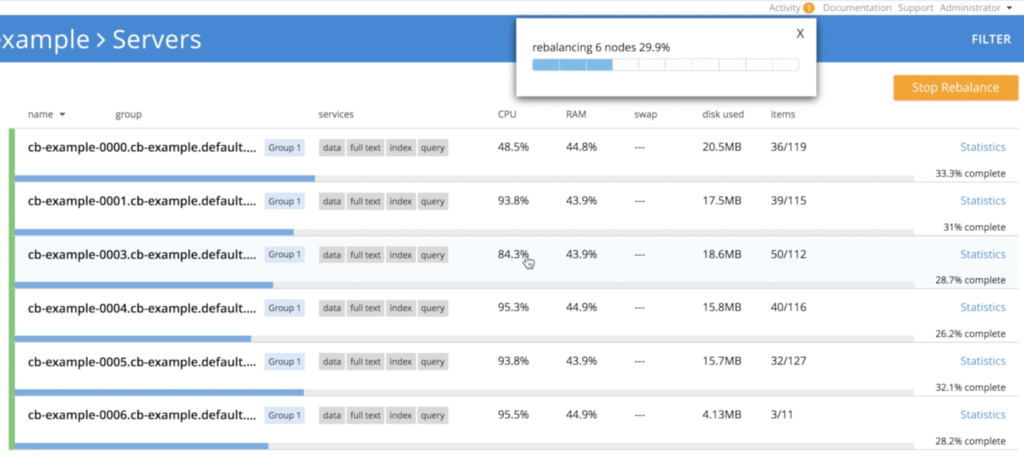
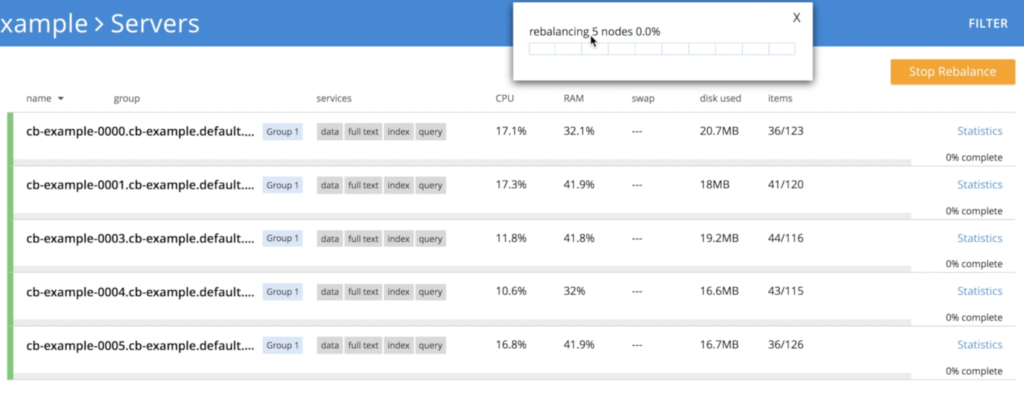
Sin embargo, aquí hay un pequeño detalle, ya que no podemos matar 3 nodos al mismo tiempo sin correr cierto riesgo de pérdida de datos. Para evitar este problema, el operador reduce el clúster gradualmente, una instancia cada vez, activando el reequilibrio para garantizar que se conservan las 3 réplicas de los datos:
- Operador apagando nodo cb-example-0006:
- Operador apagando nodo cb-example-0005
- Apagando nodo cb-example-0004
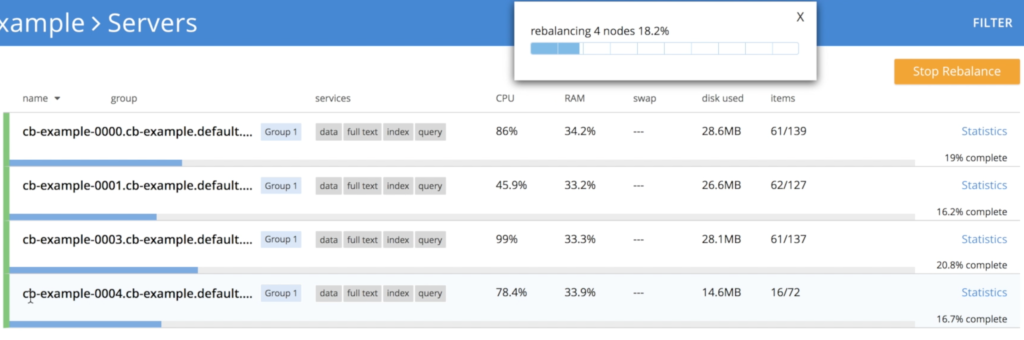
- Finalmente, volvemos a tener 3 nodos
Escala multidimensional
También puede aprovechar escalado multidimensional especificando los servicios que desea ejecutar en cada nodo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
... servers: - size: 3 name: data_and_index services: - data - index dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data - size: 2 name: query_and_search services: - query - search ... |
¿Qué ocurre con otras bases de datos en Kubernetes?
Sí! ya se pueden ejecutar algunos de ellos en Kubernetes, como MySQL y Postgres como ejemplos notables. También están tratando de automatizar la mayoría de las operaciones de infraestructura que hemos discutido aquí. Por desgracia, aún no cuentan con soporte oficial, por lo que su despliegue podría no ser tan sencillo como este.
Si quieres leer más sobre ello, consulta esas dos increíbles charlas en Kubecon:
Conclusión
Actualmente, las bases de datos utilizan Almacenamientos Locales Efímeros para almacenar sus datos (Couchbase incluida). La razón es simple: Es la opción que proporciona el mejor rendimiento. Algunas bases de datos también están ofreciendo soporte para Almacenamientos Persistentes Remotos a pesar del enorme impacto de latencia. Estamos deseando que el Almacenamiento Persistente Local se convierta en GA, ya que resolverá la mayoría de los temores de los desarrolladores con esta nueva tendencia.
Hasta ahora, las bases de datos totalmente gestionadas eran la única opción que tenías si querías librarte de la carga de gestionar tu base de datos. El precio de esta libertad, por supuesto, viene en forma de algunos ceros extra en tu factura y un control muy limitado del rendimiento/arquitectura. Aprovechar Kubernetes para el escalado y la autogestión de bases de datos se perfila como una tercera opción, a medio camino entre gestionarlo todo uno mismo y confiar en que alguien lo haga por uno.
Si tienes alguna pregunta, déjala en los comentarios o tuitéame en @deniswsrosa. Escribiré la segunda parte de este artículo para responder a todas ellas.
Un post absolutamente fantástico. Gracias por esto Denis ..
Hola Denis,
¿Cómo podemos exponer el servicio de datos cuando se ejecuta esto en aws? Puedo acceder a la consola de administración utilizando el DNS público del nodo. He abierto todos los puertos requeridos en el grupo de seguridad de aws. Pero la muestra basada en Java SDK no puede conectarse. ¿Existe una aplicación web de muestra rápida disponible como contenedor que pueda utilizar para probar desde dentro del clúster kubernetes?
Estimado Denis ,
¿Pueden ayudarme con la configuración de MDS en la versión CB 6.0 EE con Kubernetes?
servidores:
- tamaño: 3
nombre: dataservices
servicios:
- datos
vaina:
recursos:
límites:
cpu: "10"
memoria: 30Gi
peticiones:
cpu: "5"
memoria: 20Gi
volumeMounts:
datos: couchbase
por defecto: couchbase
- tamaño: 1
nombre: indexservices
servicios:
- índice
vaina:
recursos:
límites:
cpu: "40"
memoria: 75Gi
peticiones:
cpu: "30"
memoria: 50Gi
volumeMounts:
datos: couchbase
por defecto: couchbase
- tamaño: 1
nombre: queryservices
servicios:
- consulta
vaina:
recursos:
límites:
cpu: "10"
memoria: 10Gi
peticiones:
cpu: "5"
memoria: 5Gi
volumeMounts:
datos: couchbase
por defecto: couchbase
- tamaño: 2
nombre: otros servicios
servicios:
- búsqueda
- eventos
- análisis
vaina:
recursos:
límites:
cpu: "5"
memoria: 10Gi
peticiones:
cpu: "2"
memoria: 5Gi
volumeMounts:
datos: couchbase
por defecto: couchbase
Se acaba de lanzar a continuación problema de las plantillas :
Advertencia: Fusionando mapa de destino para tabla 'couchbase-cluster'. No se puede sobrescribir el elemento de tabla 'servidores', con un valor que no es de tabla: map[all_services:map[pod:map serverGroups: services:[data index query search eventing analytics] size:5]].
REVISIÓN: 1
Cuando quiero continuar con la instalación arroja el siguiente error :
Error: release filled-beetle failed: admission webhook "couchbase-admission-controller-couchbase-admission-controller.default.svc" denied the request: validation failure list:
se requieren datos en spec.servers[1].services
se requieren datos en spec.servers[2].services
se requieren datos en spec.servers[3].services
Estoy bastante seguro de que me falta en alguna parte la condición de bucle en ...\templates\couchbase-cluster.yaml ya que no está gustando múltiples entradas para MDS :
Y esta sección parece ser la culpable :
servidores:
{{- range $server, $config := .Values.couchbaseCluster.servers }}
nombre: {{ $server }}
{{ toYaml $config | indent 4 }}
{{- fin }}
{{- if .Values.couchbaseTLS.create }}
¿ Alguna pista de lo que me falta para que mi instalación de MDS vaya bien ?
gracias por su ayuda.