Preludio: ¿Qué es la indexación de bases de datos?
Indexación asíncrona: Los Índices Secundarios Globales en bases de datos - Couchbase, por ejemplo - pueden ser creados, actualizados y borrados sin impactar las lecturas y escrituras en los documentos JSON en los nodos de Datos. Esto significa que las inserciones/actualizaciones/eliminaciones específicas de los índices se producen de forma asíncrona y las cargas de trabajo están aisladas del resto del sistema.
Comprender los SLA de las consultas y crear los índices adecuados: Los índices están directamente relacionados con las consultas N1QL que se ejecutan. N1QL y GSI van de la mano. Los índices están pensados como esteroides para las consultas N1QL, reduciendo los costes de latencia y aumentando el rendimiento. Los índices también exigen su propio almacenamiento, pero el riesgo de perder negocio debido a una experiencia lenta(/de mala calidad) de las consultas es mayor que su coste asociado. Además, en la mayoría de los casos los índices viven fuera de los confines de una aplicación, lo que ayuda a gestionar adecuadamente su ciclo de vida.
Veamos algunas de las mejores prácticas en materia de índices de bases de datos para ofrecer las mejores experiencias a los clientes.
1. Ejecutar Index Service en su propio conjunto de nodos
Aunque todos los servicios (datos, consultas, índices, búsquedas, etc.) de Couchbase pueden ejecutarse en todos los nodos, recomendamos que las cargas de trabajo individuales se ejecuten en su propio conjunto de nodos. Esto permite aislar las cargas de trabajo y escalarlas de forma independiente. Además, el hardware puede repartirse adecuadamente en función de la naturaleza de la carga de trabajo. Por ejemplo, los índices suelen consumir mucha memoria y las consultas mucha CPU. Se puede disponer de hardware diferente para estos distintos servicios. La escalabilidad independiente para obtener la mejor capacidad de cálculo por servicio se consigue gracias a la ventaja arquitectónica que nos ofrece el escalado multidimensional (MDS).
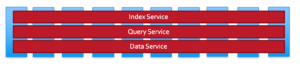
Cuando todos los servicios se ejecutan en todos los nodos disponibles
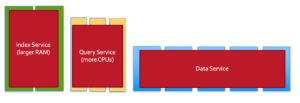
Cuando los Servicios individuales se ejecutan en sus propios nodos dedicados
2. 2. Entender el MOI frente al GSI estándar:
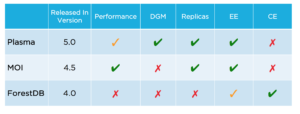
Couchbase 5.0 introdujo Plasma como un nuevo motor de almacenamiento para GSI. Plasma es el motor de almacenamiento subrayado cuando se elige "Secundario global estándar" en el momento de la configuración. Ambos tipos de almacenamiento tienen características diferentes. Cuando el caso de uso exige que todo el índice sea residente en memoria (SLA más estrictos, latencias más bajas y mayor rendimiento), elija MOI. El GSI estándar (Plasma) es extremadamente útil cuando todo el índice no puede ser residente en memoria, lo que denominamos escenario de Datos-Grandes-De-Memoria (DGM); también es útil cuando los costes de memoria son un factor a la hora de decidir el tipo de índice. Mientras que MOI puede entrar en un modo de pausa cuando la memoria está completamente agotada (es decir, las actualizaciones de índices se detienen, aunque las consultas serán atendidas), Plasma se desborda adecuadamente al disco y opera (y los índices en las bases de datos se actualizan) con facilidad. En Couchbase 5.0, Plasma funciona bien hasta escenarios 20% DGM (es decir, 20% de los datos de índice están en memoria); si la consulta accede a claves tanto en memoria como en disco, entonces hay un impacto adecuado en el rendimiento de la consulta debido al obvio acceso al disco mientras se consulta.
Debido a la naturaleza de ser completamente residente en memoria, MOI es generalmente mucho más rápido que Standard GSI (especialmente, el anterior ForestDB). Por el momento, no es posible que ambos tipos de indexación de la base de datos residan en el mismo clúster.
El siguiente esquema explica los diferentes motores de almacenamiento de índices disponibles y sus características de alto nivel
 3. Utilizar réplicas de índices : Las réplicas en GSI son réplicas activas, es decir, sirven al doble propósito de equilibrar la carga de consultas N1QL y también de asumir el tráfico si falla la otra réplica de índice.
3. Utilizar réplicas de índices : Las réplicas en GSI son réplicas activas, es decir, sirven al doble propósito de equilibrar la carga de consultas N1QL y también de asumir el tráfico si falla la otra réplica de índice.
|
1 |
create index idx on bucket(field1) with {“num_replica”: 2} |
(o)
|
1 |
create index idx on bucket(field1) with {“nodes”:[“1.2.3.1:8091”, “1.2.3.2:8091”, “1.2.3.3:8091”]} |
Ambas copias del índice se actualizan automáticamente de forma asíncrona a medida que se producen las actualizaciones de los documentos en los nodos de datos. Tener siempre al menos una réplica, lo que a su vez significa que hay dos nodos de índice como mínimo para dar servicio a las consultas N1QL. Debido al soporte de swap rebalance en 5.0, si un nodo índice cae, y un nuevo nodo es añadido de nuevo, entonces la topología se mantiene. Esto es extremadamente útil para las operaciones de ampliación/reducción debido a estacionalidades en las consultas, cuando se desea moverse entre nodos más grandes y nodos más pequeños.
Si ya utiliza índices equivalentes, pase a las réplicas. Más información sobre este proceso aquí.
4. Índices Variantes
GSI tiene diferentes variantes basadas en diferentes casos de uso. Estas variantes se crearon específicamente para la naturaleza de las consultas y, por tanto, es muy importante comprender el comportamiento de las consultas y aprovechar adecuadamente estas variantes del índice.
| Índice primario | Índice funcional |
| Índice primario con nombre | Índice de matrices |
| Índice compuesto | Índice cubierto |
| Índice parcial | Índice adaptativo |
Consulte este artículo de DZone y esta documentación para más información.
Para un ejemplo de índice de base de datos, veamos el Índice Cubierto: esta variante contiene predicados y todos los atributos indexados en la definición, por lo que se evitan saltos adicionales a los nodos de datos. Las latencias de consulta se reducen considerablemente.
Por ejemplo, si tenemos lo siguiente
|
1 |
CREATE INDEX `idx_ts_type_iata` ON `travel-sample`(`type`,`iata`); |
Y utiliza la consulta:
|
1 |
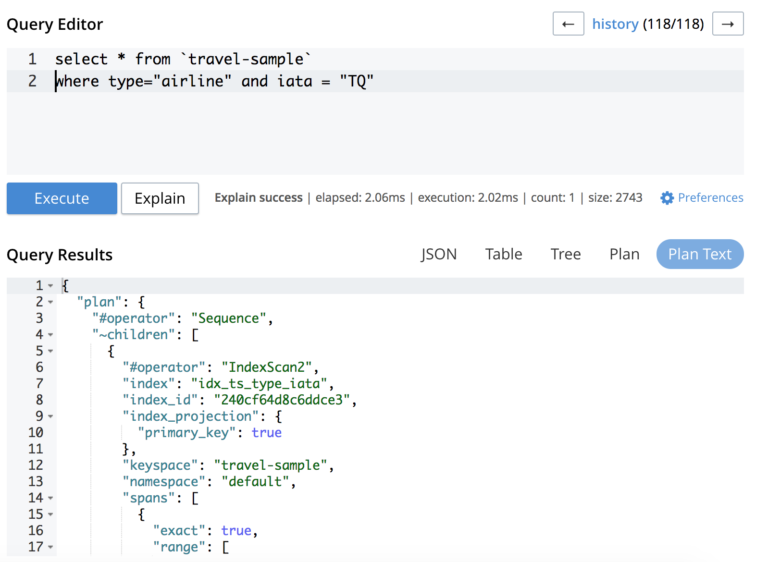
select iata from `travel-sample` where type="airline" and iata = "TQ" |
A continuación, el Plan Explicativo revelará que la consulta está siendo "cubierta" por el índice:
|
1 2 3 4 5 6 7 8 9 |
"~children": [ { "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`type`))", "cover ((`travel-sample`.`iata`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "idx_ts_type_iata", |
Y si intentamos seleccionar 'todos'(usando 'select *') los atributos:
|
1 |
<span style="font-weight: 400">select * from `travel-sample` where type="airline" and iata = "TQ";</span> |
A continuación, el PLAN DE EXPLICACIÓN revela que la consulta no está cubierta (falta el campo "covers"), ya que el servicio de consultas tiene que saltar al servicio de datos para obtener todos los atributos:
|
1 2 3 4 5 6 7 8 |
"~children": [ { "#operator": "IndexScan2", "index": "idx_ts_type_iata", "index_id": "240cf64d8c6ddce3", "index_projection": { "primary_key": true }, |
Del mismo modo, los índices de matrices se crearon principalmente para ayudar a nuestros clientes a consultar datos JSON, en los que las matrices son muy comunes. Pronto publicaremos un post detallado al respecto.
5. Evitar claves primarias en producción
Los escaneos primarios completos inesperados son posibles y cualquier posibilidad de tales ocurrencias debe ser eliminada evitando los índices primarios por completo en Producción. La Selección de Índices N1QL es por ahora un sistema basado en reglas que busca un posible índice que satisfaga la consulta, y si no lo hay, entonces recurre a usar el Índice Primario. El índice primario tiene todas las claves de los documentos - por lo tanto, la consulta obtendrá todas las claves del índice primario y luego saltará al Servicio de Datos para obtener los documentos y luego aplicar filtros. Como puede ver, se trata de una operación muy costosa y debe evitarse a toda costa.
Si no se han creado índices primarios y la consulta no puede encontrar un índice que coincida con la consulta, el servicio de consultas mostrará el siguiente mensaje de error, que debería ayudarle a crear el índice secundario necesario:
"No hay ningún índice disponible en el espacio clave travel-sample que coincida con su consulta. Utilice CREATE INDEX o CREATE PRIMARY INDEX para crear un índice, o compruebe que el índice que espera está en línea.."
También, como una mejor práctica inherente de indexación, la partición de índices primarios no es soportada por Couchbase. A diferencia de muchos RDBMS, las claves primarias son opcionales en Couchbase.
6. Utilizar planes EXPLAIN
Para validar si la consulta N1QL está utilizando realmente los índices creados, compruebe el campo EXPLICAR EL PLAN resultados. En la consola de administración de Couchbase, esto se puede obtener fácilmente pegando la consulta en el editor de código y haciendo clic en el botón "Explicar". Busque el icono "1TP5Operador" y "índice" del resultado para confirmar el uso del índice. Enlace a la documentación.
 7. Índice por predicado
7. Índice por predicado
La cláusula WHERE de una consulta se denomina Predicado y los campos/atributos seleccionados en la cláusula SELECT se denominan Proyección. Los índices deben crearse siempre teniendo en cuenta la cláusula Predicate. Esto se debe a que la Selección de Índices se realiza basándose en la clave principal del índice presente en el Predicado.
Por ejemplo, si tenemos el siguiente índice sobre 4 atributos:
|
1 |
CREATE INDEX `idx_ts_type_iata_name_icao` ON `travel-sample`(`type`,`iata`, `name`,`icao`); |
Y dispara la siguiente consulta que en realidad omite el atributo icao mientras consulta, el motor de consulta es lo suficientemente inteligente como para saber que debe utilizar el índice anterior para obtener el mejor rendimiento de la consulta.
|
1 |
select name from `travel-sample` where icao="MLA" and type="airline"; |
El índice seleccionado puede verse en el plan de explicación siguiente. Nótese que la consulta se convierte en una consulta de Cobertura, ya que 'name' a pesar de no estar en Predicate sí está en Projection, por lo que se evita el salto a Data Service.
|
1 2 3 4 5 6 7 8 9 10 11 |
"~children": [ { "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`type`))", "cover ((`travel-sample`.`iata`))", "cover ((`travel-sample`.`name`))", "cover ((`travel-sample`.`icao`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "idx_ts_type_iata_name_icao", |
8. Utilizar una clave principal para forzar la selección del índice
Un índice no se selecciona automáticamente para una consulta si el predicado utilizado en la consulta no coincide con la clave principal del índice. Si observa que el PLAN EXPLAIN no obliga a seleccionar ningún índice, utilice las cláusulas "IS NOT MISSING" o "IS NOT NULL" para forzar la selección del índice.
For ejemplo, cualquiera de las siguientes consultas:
|
1 2 |
select count(1) from `travel-sample` where type IS NOT NULL; select count(1) from `travel-sample` where type IS NOT MISSING; |
utilizará el siguiente índice, ya que la clave principal del índice es "tipo":
|
1 |
CREATE INDEX `idx_ts_type_iata` ON `travel-sample`(`type`,`iata`); |
Para elegir sólo un ÍNDICE ya creado, utilice la opción UTILIZAR ÍNDICE como parte de la consulta N1QL. Esto es útil en los casos en los que se sabe que el índice mencionado en USE INDEX tiene mejor selectividad que el elegido por N1QL Rule Based Optimizer:
|
1 |
select count(1) from `travel-sample` USE INDEX (idx_ts_type_iata) where type="airline"; |
9. Utilizar índices parciales
A veces, el predicado a indexar puede no caber en un nodo debido a limitaciones de tamaño. Los GSI en Couchbase no se particionan automáticamente por ahora. Esto obliga al administrador a crear Índices Parciales; las consultas N1QL son lo suficientemente inteligentes como para elegir el índice apropiado basándose en el tipo de predicado usado en la consulta cuando los índices parciales están presentes.
Por ejemplo, creamos los dos índices siguientes basándonos en que el nombre está en dos rangos diferentes:
|
1 2 |
CREATE INDEX `idx_ts_name_ak` ON `travel-sample`(`name`) WHERE name BETWEEN "A" AND "K"; CREATE INDEX `idx_ts_name_kz` ON `travel-sample`(`name`) WHERE name BETWEEN "K" AND "Z"; |
Ahora, las siguientes consultas elegirán automáticamente el índice adecuado, tal y como se pone de manifiesto en los respectivos PLANES EXPLAIN:
|
1 2 3 4 5 6 7 |
select * from `travel-sample` where name="Astraeus"; EXPLAIN PLAN : "~children": [ { "#operator": "IndexScan2", "index": "idx_ts_name_ak", |
|
1 2 3 4 5 6 7 |
select * from `travel-sample` where name="Texas Wings"; EXPLAIN PLAN : "~children": [ { "#operator": "IndexScan2", "index": "idx_ts_name_kz", |
Los índices se eligen adecuadamente cuando se utiliza la cláusula LIKE en el predicado. Por ejemplo, supongamos que queremos obtener todos los nombres que suenen como un nombre francés (que empiece por "L'"):
|
1 2 3 4 5 6 |
select * from `travel-sample` where name like "L'%"; EXPLAIN PLAN : "~children": [ { "#operator": "IndexScan2", "index": "idx_ts_name_kz", |
10. Opciones de coherencia
Debido a su naturaleza asíncrona, los GSI en Couchbase son finalmente consistentes por defecto y, como ya se ha mencionado, se actualizan de forma asíncrona. Aunque, usando change feeds(DCP), actualizamos los índices lo más rápidamente posible, es muy posible que ciertas mutaciones de documentos no hayan sido actualizadas en los índices. Si la semántica de la consulta exige una consistencia de datos más estricta, Couchbase ofrece modelos de consistencia ajustables en el momento de la consulta.
Las tres opciones de consistencia disponibles en Couchbase son:
- scan_consistency=not_bounded
- scan_consistency=at_plus
- scan_consistency=petición_plus
Para saber más: Enlace a la documentación
Aunque la semántica request_plus refuerza la integridad de los datos, tiene un impacto en el rendimiento, ya que aumenta la latencia de la consulta, que espera a que el índice relevante se ponga al día con las últimas mutaciones antes de devolver los datos. not_bounded" (la opción de coherencia por defecto) es la más rápida de las tres opciones de coherencia.
11. Monitor Index Catchup
Por lo general, el servicio de índice se pone al día con las mutaciones de documentos muy rápidamente, de modo que el impacto para el usuario es mínimo o nulo. Pero como administrador, si quieres asegurarte de que las mutaciones de documentos (que deben actualizarse en el índice) son las mínimas posibles y no siguen aumentando, entonces fíjate en la métrica "elementos restantes" bajo el nombre del índice.
12. Utilizar construcciones diferidas
Las construcciones diferidas ofrecen un proceso de 2 etapas para crear índices. Se recomienda hacer siempre un uso óptimo de las construcciones diferidas, ya que se utiliza la misma fuente de cambios para crear índices en un nodo. Si no se utilizan las construcciones DEFER, se debe acceder varias veces a la fuente de cambios de los nodos de datos, lo que conlleva una mayor transferencia de datos a través de la red y un ligero aumento de la carga en los nodos de datos.
Por ejemplo:
|
1 2 |
CREATE INDEX `idx_ts_type_iata` ON `travel-sample`(`type`,`iata`) WITH { "defer_build":true }; BUILD INDEX ON `travel-sample`(`idx_ts_type_iata`); |
Para obtener más información sobre la sintaxis de CREATE INDEX, consulte la sección Documentación.
13. Evitar claves grandes para indexar
Antes de la versión 5.0, existía una limitación en el tamaño de las claves de los índices (máximo 4k). Esta limitación se ha eliminado en la versión 5.0. Tenga en cuenta que los índices están pensados para las rutas de acceso a los datos, por lo que el modelo de datos y la consulta (con índices) deben estructurarse para obtener la información necesaria en el menor tiempo posible. Aunque los clientes pueden tener cualquier número de campos en un índice compuesto, el tamaño de la clave del índice también crece proporcionalmente. Los tamaños de clave realmente grandes pueden afectar al rendimiento. Como regla general, es preferible que el tamaño combinado de todos los campos de un índice compuesto sea de 1kB; y si no es posible, refactorice las consultas convenientemente.
14. UTILIZAR CLAVES, evitar índices
No es necesario que todas las consultas N1QL requieran índices. Si tus consultas N1QL pueden funcionar independientemente de los índices, consultando directamente los documentos usando claves, entonces la directiva USE KEYS es útil.
Por ejemplo:
|
1 |
SELECT * FROM `travel-sample` USE KEYS ["landmark_37588"]; |
El plan de explicación resultante mostrará que se está realizando un KeyScan (sin ninguna mención a un IndexScan):
|
1 2 3 4 5 |
"~children": [ { "#operator": "KeyScan", "keys": "[\"landmark_37588\"]" } |
Esto es más una cosa que hay que saber que una práctica recomendada, ya que USE KEYS no utiliza índices para devolver resultados del servicio de consulta. Aunque es muy poco probable que los clientes sólo puedan tener consultas que siempre utilicen USE KEYS, esto puede ser útil en los casos extremos que obliguen a tal comportamiento.
¡Post largo! Pero, espero que esto haya sido útil para entender las bases de datos y los índices y cómo la indexación en las mejores prácticas de DBMS puede ayudarle a ofrecer experiencias superiores al cliente :)
PS: Visión general de GSI y novedades de Couchbase Server 5.0 : https://www.youtube.com/watch?v=OrC2gkm2OFA