Este artículo presenta las Estructuras de Datos y cómo funcionan con las características de Scopes y Collections de Couchbase Server 7.0.
¿Qué son las estructuras de datos?
Couchbase Data Structures es una característica de la API que alinea el lenguaje de la interfaz de la base de datos con un lenguaje de programación.
Las estructuras de datos ayudan a simplificar los modelos de datos para los desarrolladores de sistemas NoSQL. Son unidades básicas de gestión de datos para almacenar y recuperar datos de forma rápida y eficiente. Las bases de datos de documentos y otras bases de datos clave-valor suelen soportar la indexación de estos datos para casos de consulta.
Simplificación del desarrollo de aplicaciones NoSQL
No es necesario interactuar con documentos JSON completos. Si todo lo que el desarrollador de software necesita, por ejemplo, es un único elemento de una lista. Después de autenticar la conexión a la base de datos, una simple función get o set debería ser todo lo que se necesita.
Una serie de funciones de estructura de datos proporcionan acceso a estos objetos de programación nativos:
- Documentos - soporte completo de documentos jerárquicos JSON
- Subdocumentos: subconjuntos de objetos dentro de un documento.
- Contadores - un único entero incremental
- Mapas: asignaciones de diccionario clave-valor
- Listas/colecciones - listas indexadas y ordenadas de elementos
- Conjuntos - conjuntos de valores únicos de los elementos de la lista
- Colas: acceso a los elementos de la lista por orden de llegada
Métodos de acceso directo a los datos
Couchbase gestiona sus datos como documentos JSON flexibles que pueden ser expuestos como piezas atómicas de datos a través de funciones simples. Por ejemplo, puede fgrabar un subcomponente del documento, crear un elemento numerado en una lista, o añadir a una lista ordenada. Los documentos de datos pueden llamarse directamente con sus nombres de identificación una vez que se han almacenado y distribuido al clúster.
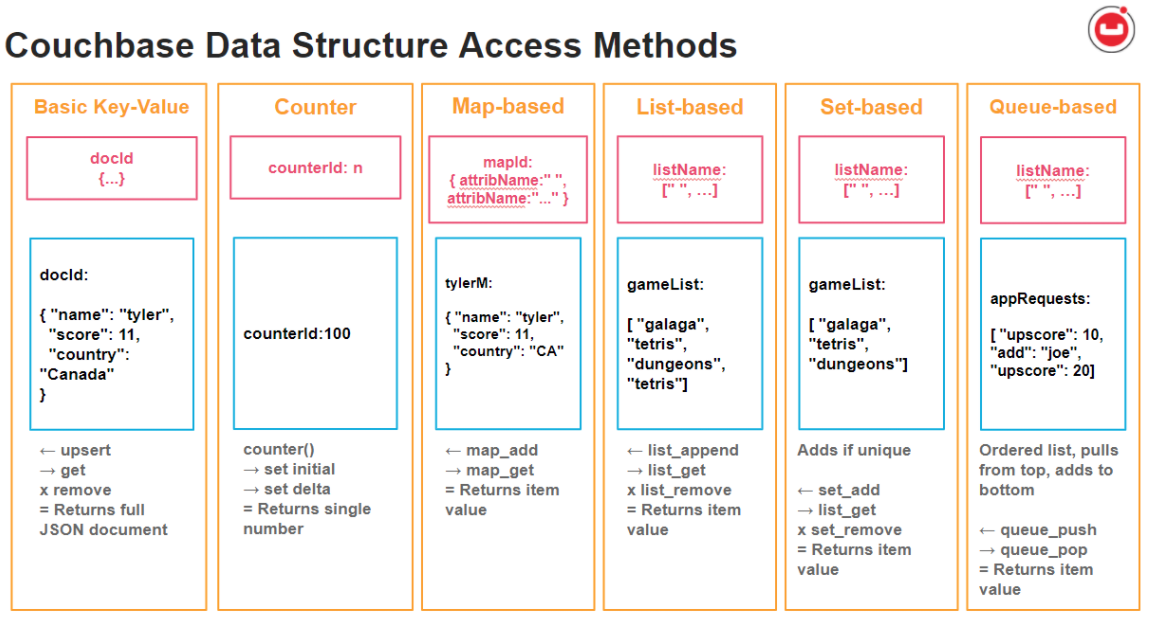
Resumen de tipos de estructuras de datos Couchbase y ejemplos JSON.
Python se utilizan para mostrar el uso básico de estos tipos de estructuras de datos, aunque se admiten todos los lenguajes del SDK. Consulte el ejemplo de código completo al final de este post para ver el código del preámbulo, las importaciones, etc.
Acceso clave-valor
General Operaciones de KV incluir consiga y set/upsert funciones. Los documentos compatibles con JSON se guardan o actualizan con un ID de documento específico.
|
1 2 3 |
>>> db.upsert("docId", { "name": "tyler", "score": 11, "country": "CA" }) >>> sb.get("docId").content '{ "name": "tyler", "score": 11, "country": "CA"}' |
Contadores
Aún más sencillo es un llamado contador objeto que almacena un valor entero único. Cuando se llama al elemento, se define un valor inicial y luego se incrementa. Este sencillo método es perfecto para un número incremental global en todas las aplicaciones.
|
1 2 3 4 5 |
>>> db.counter("currentScore",delta=1,initial=0).value # Creates at 0 0 >>> db.counter("currentScore").value # Adds 1 1 |
Acceso basado en mapas
Los mapas (también conocidos como diccionarios) asignan una clave de objeto con un valor. El valor de la entrada del mapa puede ser cualquier objeto compatible con JSON. Puede crear una nueva combinación de mapa y valor en una llamada y guardarla en su propio documento.
Por ejemplo, un mapa de perfil de usuario puede tener el ID de un nombre de usuario. Ese perfil de usuario también puede tener varias asignaciones con nombres únicos en su interior como el nombre o la dirección. Cada uno puede gestionarse independientemente de los demás.
|
1 2 3 |
>>> db.map_add("tylerM","name","Tyler", create=True) >>> db.map_add("tylerM","country","Canada") |
En este caso, el ID del mapa también es accesible a través de la función básica KV get.
|
1 2 3 |
>>> db.get("tylerM").content {'name': 'Tyler', 'country': 'Canada'} |
También hay funciones específicas del mapa para comprobar si existe y eliminar o recuperar elementos.
Acceso basado en listas
Otros Objetos y valores JSON pueden almacenarse en una simple estructura de lista sin tener que usar JSON en absoluto. Las funciones de lista añaden elementos a una lista y permiten extraerlos utilizando un número de índice.
En un solo paso se proporciona el ID de la lista y el nuevo valor. Para la eliminación o recuperación se necesita el ID de la lista y el número de índice del artículo. También se puede acceder a la lista completa con la función KV consiga función.
|
1 2 3 4 5 6 7 8 9 10 11 |
>>> db.list_append("gameList","galaga",create=True) >>> db.list_append("gameList","tetris") >>> db.list_append("gameList","dungeons") >>> db.list_get("gameList",0) 'galaga' >>> db.get("gameList").content ['galaga', 'tetris', 'dungeons', 'tetris'] |
Tenga en cuenta que los valores duplicados de los elementos de la lista son aceptables y un list_prepend también está disponible.
Acceso basado en conjuntos
"Estructuras de datos "Set facilitan la gestión de valores únicos en una lista. Los nuevos valores sólo se añaden si no existen ya. Esto reduce la necesidad de recuperar y comparar valores con la lista existente, en su lugar, se hace en una sola llamada.
|
1 2 3 4 |
>>> db.set_add("gameList","tetris") # Trying to add tetris twice is ignored >>> db.get("gameList").content ['galaga', 'tetris', 'dungeons', 'horizon'] |
Acceso basado en colas
Estructuras de datos de cola son otro tipo de lista que mantiene los elementos en un orden determinado. Una aplicación puede añadir fácilmente un nuevo elemento, que va al final de la lista. A continuación, un elemento de la lista puede ser retirado de la parte superior de la lista y, posteriormente, se elimina de la lista.
Usted puede ver por qué se llaman colas - por ejemplo, algún tipo de programa de gestión del trabajo puede estar procesando las solicitudes, ya que pueden obtener "en cola" en una lista y la necesidad de operar en un escenario FIFO (primero en entrar, primero en salir) como una aplicación lo llama.
Cada valor puede ser cualquier objeto JSON, por lo que pueden incluir otro mapa, lista, etc.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
>>> db.queue_push("appRequests",{"updatescore":10},create=True) >>> db.queue_push("appRequests",{"adduser":"joe"}) >>> db.queue_push("appRequests",{"updatescore":20}) >>> db.get("appRequests").content [{'updatescore': 20}, {'adduser': 'joe'}, {'updatescore': 10}] >>> db.queue_pop("appRequests") # Value is returned as it is removed from list {'updatescore': 10} >>> db.get("appRequests").content # First value is now removed [{'updatescore': 20}, {'adduser': 'joe'}] |
Es posible que desee utilizar conjuntos o colas para mayor comodidad en algunos casos, pero siempre se puede volver atrás y utilizar funciones de lista o KV para añadir / eliminar y gestionar más directamente con su código según sea necesario.
Un paso más allá - Subdocumentos
¿Qué hacer cuando se desea consultar un subobjeto específico en un documento JSON jerárquico más profundo? Las funciones map y list no pueden realizar extracciones de subobjetos en una única llamada al documento. Por supuesto, puedes solicitar el documento completo y procesarlo en tu aplicación, pero eso sería innecesariamente ineficiente.
El SDK de Couchbase proporciona un subdocumento API para realizar solicitudes únicas de actualización/obtención de valores en niveles más profundos.
Por ejemplo, un perfil de usuario puede tener un dirección con subapartados para calle, ciudady país. No se puede acceder a ellos con las funciones normales del mapa, pero se puede utilizar la API de subdocumentos.
Existen varias potentes funciones de subdocumento, pero aquí sólo se muestra un ejemplo de recuperación rápida mediante la función buscar_en función.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
>>> import couchbase.subdocument as SD >>> db.map_add("tylerM","contact", {"address":{"country":"Canada","city":"Vancouver"}}) >>> country = db.lookup_in("tylerM",[SD.get("contact.address")]) >>> country.content_as[str](0) "{'country': 'Canada', 'city': 'Vancouver'}" >>> country = db.lookup_in("tylerM",[SD.get("contact.address.country")]) >>> country.content_as[str](0) 'Canada' |
Uso de ámbitos y colecciones con estructuras de datos
La introducción de Ámbitos y colecciones en Couchbase 7.0 permite niveles más finos de control sobre todos los aspectos de la gestión de documentos. Los ámbitos son un subconjunto de todos los documentos del bucket y las colecciones son un subconjunto de un ámbito.
Para más información sobre estos temas en general, consulte el blog Presentación de Collections - Developer Preview en Couchbase Server 6.5.
El ámbito y las colecciones ya deben existir: cree otros nuevos mediante las herramientas de la página de definición de cubos de la consola web.
En los ejemplos de código anteriores se utilizó un ámbito por defecto en lugar de un ámbito o colección específicos. Las conexiones a nivel de cubo definen los ámbitos/colecciones que se utilizarán. Al final de este artículo se incluye un enlace a un ejemplo de código completo y comentado para los ámbitos. He aquí un ejemplo de especificación de estos parámetros:
|
1 |
dbscoped = cluster.bucket('travel-sample').scope('scope1').collection('col1') |
En lugar de seleccionar la opción "default_collection" para el cubo, el código utiliza un ámbito y una colección específicos. En lugar de utilizar la opción db utilice la función dbscoped para las operaciones de datos.
|
1 2 3 |
dbscoped.list_append("newlist",1,create=True) dbscoped.list_append("newlist",2) |
Revisa la página de documentos en la consola web y filtra por nombres de colecciones para confirmar cuál estás utilizando:
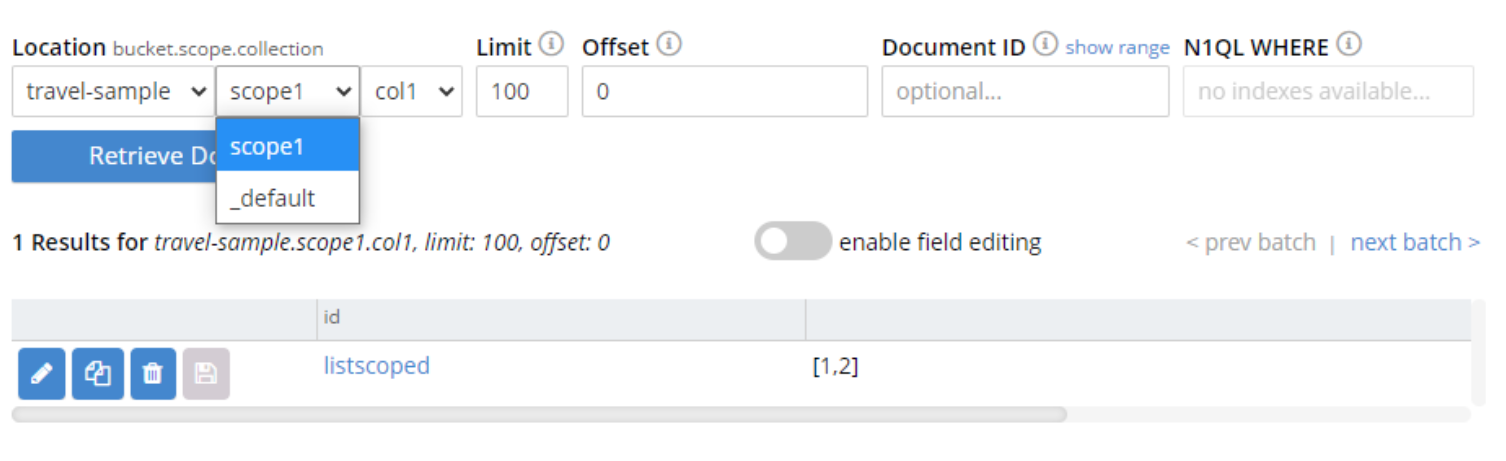
NOTA: En el momento de escribir esto, la API de Python para contadores no soportaba el uso de ámbitos.
Indexación de estructuras de datos para una búsqueda SQL o de texto completo eficaz
Couchbase es mucho más que la gestión de estructuras de datos en bruto a través del motor de clave-valor (KV) o estructuras de datos JSON. Muchas aplicaciones, especialmente las aplicaciones web y móviles NoSQL orientadas al cliente, necesitan más sofisticación para integrarse con otras aplicaciones.
Couchbase lo hace utilizando indexación de datos NoSQL y servicios de consulta basados en SQL, así como búsqueda de texto completo.
¿Qué es la indexación de bases de datos? Significa examinar partes de los datos y comprender cómo volver a encontrar esos elementos dentro de los documentos. La búsqueda se realiza mediante una consulta de tipo SQL o una solicitud de búsqueda de texto completo.
Cubriremos ambos escenarios en posts posteriores centrados en la indexación de colecciones nativas en estructuras de datos Couchbase.
Mientras tanto, consulte este artículo sobre indexación: Mejores prácticas de indexación de bases de datos NoSQL.
Unirlo todo
Como puedes ver, crear documentos, contadores y subcomponentes relacionados es muy sencillo, usando Couchbase. Asimismo, mediante el uso estratégico de índices, existen aún más formas de acceder a la base de datos.
Las consultas N1QL y la búsqueda de texto completo son métodos comunes que también hacen uso de matrices JSON básicas, cadenas, etc. cuando se mapean correctamente.
Como Couchbase es una plataforma todo incluido, la arquitectura de tu sistema puede simplificarse enormemente. Los desarrolladores pueden empezar de inmediato sin mucho trabajo pesado ni gestión de bases de datos.
- Descargar el ejemplo completo de código Python aquí
- Estructuras de datos Documentos API: Java, .NET, Node.js, Vaya a, PHP, Python, C, Rubí, Scala
- Subdocumento operaciones docs (SDK de Python)