En un sistema distribuido, las actualizaciones de una base de datos compartida procedentes de varios clientes deberán sincronizarse. El objetivo del proceso de replicación es asegurar que todos los clientes móviles y el servidor(es) tengan una visión consistente de los datos sincronizando los cambios entre las bases de datos locales y remotas. En Couchbase Mobile, la replicación ocurre entre los clientes que ejecutan Couchbase Lite y el Sync Gateway del servidor.
Couchbase Móvil 2.0 liberar aporta una plétora de nuevas funciones y mejoras. Una mejora clave es el nuevo y mejorado protocolo de replicación. Este post te introducirá a los fundamentos del nuevo protocolo de replicación en Couchbase Mobile 2.0.
Puede descargar Couchbase Mobile 2.0 desde aquí.
Fondo
En Plataforma móvil Couchbase comprende el Couchbase Lite Base de datos incrustada NoSQL que se ejecuta en los clientes; la Pasarela de sincronización responsable de la sincronización de datos, enrutamiento de datos y autenticación/autorización de usuarios; y Servidor Couchbase para la persistencia y gestión de datos.
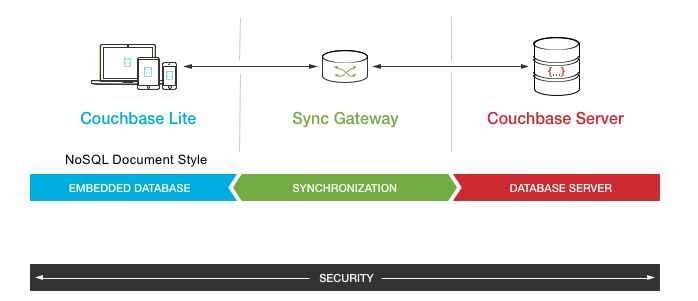
En la versión 1.x de Couchbase Mobile, la replicación se implementó utilizando un protocolo basado en REST. originado por CouchDB a través de HTTP(s). De hecho, la lógica de replicación se implementó como una serie de llamadas a la API a través de HTTP.
Nueva arquitectura por capas
El Protocolo de Replicación 2.0 se implementa como un nuevo protocolo de mensajería en capas sobre WebSockets. Es compatible con todos los compatible Plataformas Couchbase Lite 2.0 y Sync Gateway 2.0.
El protocolo WebSocket permite el paso de mensajes full-duplex entre hosts remotos a través de una única conexión de socket TCP. El protocolo WebSocket comienza como una conexión HTTP(s) y cambia a Websockets si el host remoto lo soporta.
El nuevo protocolo de mensajería, inventado por Jens Alfkeañade multiplexación y soporte de solicitud/respuesta a la capa Websockets. La nueva arquitectura en capas es más limpia y permite separar las preocupaciones entre la lógica de replicación y el transporte de mensajería subyacente. El nuevo protocolo es más rápido y requiere menos ancho de banda y recursos de socket. El ahorro en recursos de socket permitiría aumentar el soporte para conexiones concurrentes en el servidor. Por último, la naturaleza bidireccional del protocolo WebSocket se presta bien a las configuraciones peer-to-peer.

Compatibilidad
El nuevo protocolo de replicación es compatible con los clientes Couchbase Lite 2.0 y Sync Gateway 2.0. Consulte la guía de compatibilidad para más detalles.
Este es el protocolo de replicación por defecto que se utilizará en Couchbase Mobile 2.0. No es necesario habilitarlo específicamente en la configuración de Sync Gateway. En caso de clientes Couchbase Lite 1.x, Sync Gateway cambiará automáticamente al protocolo de replicación anterior.
Terminología
Estos son algunos de los términos que utilizaremos en este debate
- "Cliente" : Cliente Couchbase Lite 2.0
- "Servidor" : Sync Gateway 2.0
- "Base de datos fuente" : La base de datos local desde la que se replican los cambios
- "Base de datos objetivo" : La base de datos remota a la que se replican los cambios
- "Fuente Replicante" : El replicador que está enviando los cambios de la base de datos
- "Objetivo Replicante" : El replicador que recibe los cambios en la base de datos
- "Replicación Push" : Proceso mediante el cual los clientes cargan los cambios de la base de datos de origen local a la base de datos de destino remota (servidor).
- "Replicación Pull" : Proceso mediante el cual los clientes descargan los cambios de la base de datos desde la base de datos de origen remota (servidor) a la base de datos de destino local.
- "Replicador activo" : Replicador Couchbase Lite que automáticamente empuja o tira de los cambios de base de datos.
- "Replicador pasivo" : Replicador de Sync Gateway que responde a las solicitudes push o pull de cambios.
Modos de replicación
El proceso de replicación puede ser "continuo" o "un disparo“.
- En el modo de replicación "Continua", los cambios se sincronizan continuamente entre el cliente y Sync Gateway.
- En el modo "One shot", los cambios se sincronizan una vez y la conexión entre el cliente y el servidor se desconecta. Cuando en el futuro haya que subir o bajar cambios, el cliente debe iniciar una nueva replicación.
Conceptos
Antes de examinar el protocolo, debemos comprender algunos conceptos clave.
Árboles de revisión
Couchbase utiliza un sistema de Control de Concurrencia de Versiones Múltiples (MVCC) para la gestión de documentos. En dicho sistema, cada documento en Couchbase Mobile se almacena como una secuencia de revisiones. Una nueva revisión se crea automáticamente cuando se crea un documento. Cada actualización del documento, ya sea una edición o un borrado, resultará en la creación de una nueva revisión para el documento. La revisión especial que marca un borrado se llama lápida revisión. En revisión actual es la revisión hoja del documento y, en caso de revisiones contradictorias, corresponde a la revisión ganador revisión. Para más detalles sobre los árboles de revisiones y la resolución de conflictos en 2.0, permanezca atento a una próxima entrada del blog sobre este tema.
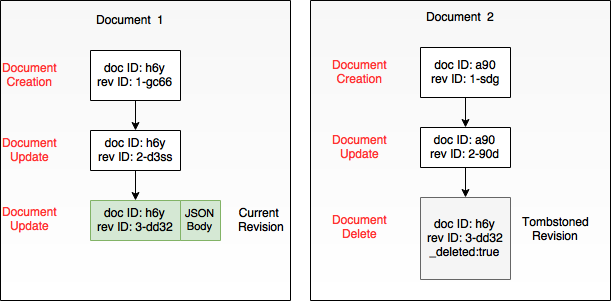
Cambia
La revisión actual que existe en la base de datos de origen pero no en la de destino se denomina cambiar. Así que, efectivamente, el proceso de replicación sincroniza los cambios entre bases de datos remotas.
ID de secuencia
Cada cambio se asocia a un único ID de secuencia en orden cronológico creciente. Es similar a una marca de tiempo de última modificación, salvo que no es una hora de reloj de pared, sino un contador que se incrementa automáticamente. Los identificadores de secuencia son específicos de una base de datos concreta, por lo que cuando un documento se replica no termina con el mismo identificador de secuencia.
Nota: Mientras que los IDs de secuencia de Couchbase Lite son simples enteros, los de Sync Gateway pueden ser largas cadenas base64. Las razones son complejas y tienen que ver con la concurrencia interna entre nodos en un cluster de Couchbase Server. El contenido exacto de un ID de secuencia remoto depende de la implementación y un cliente nunca debe hacer suposiciones sobre ellos.
Punto de control
El punto de control es un registro del último sequenceID replicado por el replicador. Al final de cada ciclo de replicación, el replicador comprobará el punto de origen. sequenceID correspondiente al último cambio enviado al destino. El primer ciclo de replicación no tendrá puntos de control.
¿Qué hace realmente la replicación?
Ahora que ya ha comprendido los conceptos clave, la replicación puede describirse como el proceso por el cual el replicador de origen envía todas las cambiacuyos ID de secuencia sean mayores que el último punto de control, al replicador de destino. Los cuerpos de revisión de los actual revisiones junto con las correspondientes manchas/attachments y el historial de revisiones se replican.
Nota: Es posible que el mismo documento se edite simultáneamente en la base de datos de origen y en la de destino, dando lugar a un conflicto. Hablaremos de conflictos y replicación un poco más adelante.
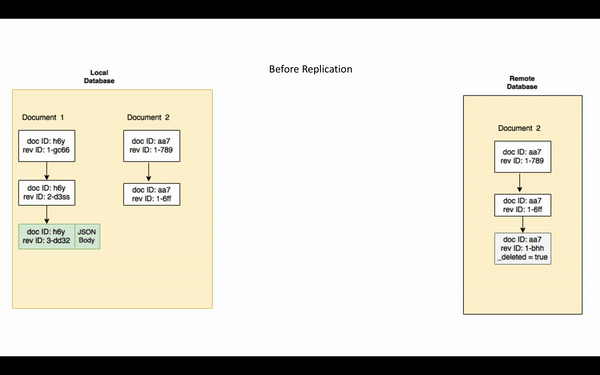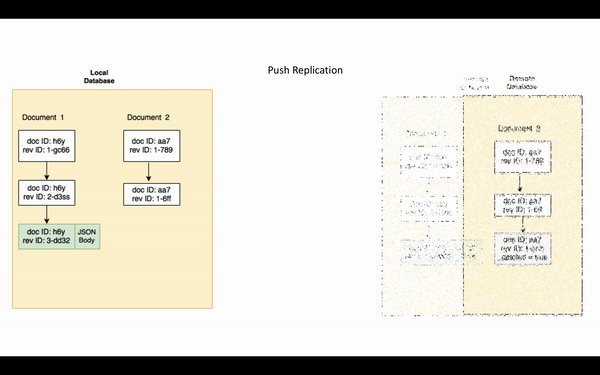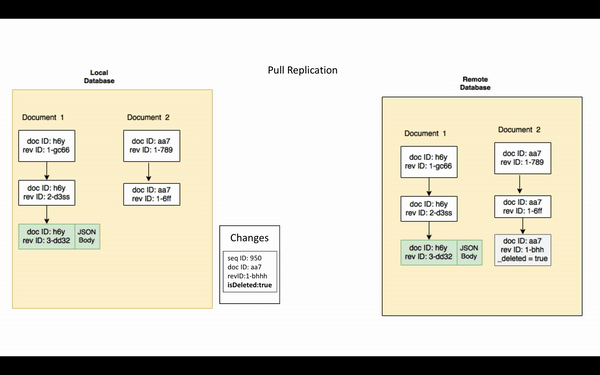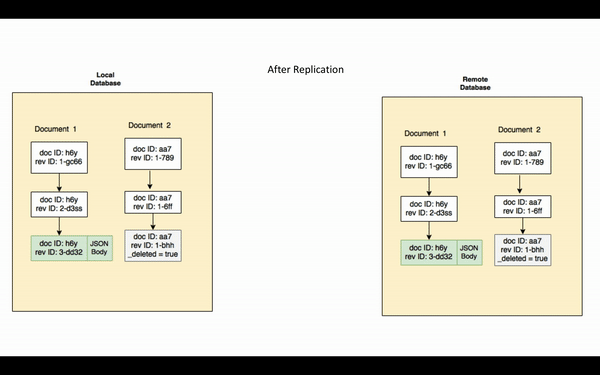
Tenga en cuenta que si un documento purgado de la base de datos, la purga no se replicará. La purga elimina todo rastro del documento de la base de datos.
El esquema URL
Los clientes de Couchbase Lite deben utilizar el ws Esquema de URL para conectarse a la puerta de enlace de sincronización
He aquí algunos ejemplos
|
1 2 3 4 |
ws://sync-gw-address:4984 wss://sync-gw-address:4984 |
El Protocolo
Establecimiento de la conexión
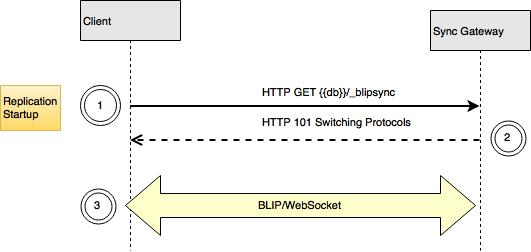
- Cuando se inicia la replicación, el cliente envía una petición WebSocket handshake al servidor a través de HTTP(s) indicando que quiere cambiar a WebSocket. Se trata de una petición HTTP GET, con cabeceras especiales, al recurso
_blipsyncrelativa a la URL de la base de datos. - El servidor responde indicando que está de acuerdo con el cambio de protocolo.
- Una vez que el Handshake de Websockets el socket deja de usarse para HTTP, y toda la comunicación posterior son mensajes WebSocket.
Un único socket puede soportar simultáneamente una replicación push y pull. Ambos tipos almacenan y recuperan puntos de control, y requieren esos puntos de control para continuar, por lo que la gestión de puntos de control se describirá en primer lugar.
Gestión de puntos de control
Tanto las réplicas push como pull almacenan y recuperan puntos de control en el servidor.
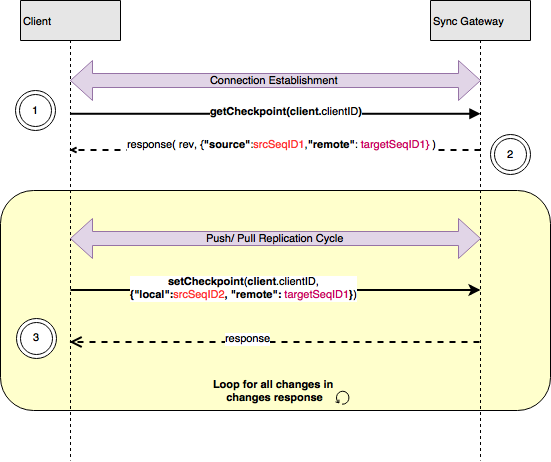
- Tras el establecimiento de la conexión, el cliente envía un
getCheckpointal servidor para determinar el último ID de secuencia de origen conocido en el servidor. La solicitud incluye:- ID de cliente que identifica al cliente
- La respuesta a
getCheckpointincluye el último punto de control registrado por el cliente. El punto de control es un objeto JSON previamente creado y almacenado por el cliente ; puede contener cualquier dato que el cliente desee, pero es actualmente de la forma:- ID de secuencia local que es la última secuencia conocida enviada por el cliente
- ID de secuencia remota que es el último ID de secuencia recibido por el cliente
- A medida que las secuencias se replican con éxito, el cliente envía periódicamente un
setCheckpointpara registrar el último ID de secuencia local enviado y/o el último ID de secuencia remoto recibido.
Replicación Push
Durante la replicación push, una serie de cambios son enviados automáticamente por el replicador activo a la replicador pasivo
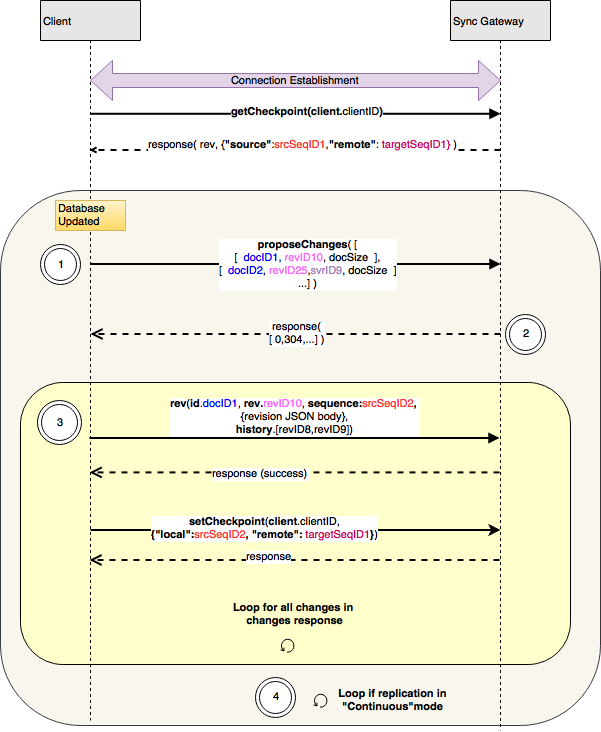
- Una vez recuperado el punto de control, y cuando el replicador del lado del cliente detecta cambios en su base de datos local desde que el ID de secuencia localel cliente envía un
proponerCambiosal servidor con una matriz decambiarcorrespondientes a cada revisión actual que haya cambiado. Esto incluye las revisiones "tombstoned". El cambio en sí se codifica como un array JSON anidado e incluye:- ID del documento del documento asociado a la modificación
- ID de revisión de la revisión actual del documento
- servidor Rev ID de revisión del servidor conocido, si existe . Se omite si no hay servidor Rev ID
- Opcionalmente, tamaño aproximado del cuerpo del documento
- La respuesta del servidor al
proponerCambiosincluye un objeto JSON que contiene:- una matriz de códigos de estado, en la que cada entrada corresponde al ID de revisión especificado en el archivo
proponerCambiossolicitud.- Un valor de 0 indica que el servidor está interesado en la rev
- Un valor de 304 indica que el servidor tiene esta revisión
- Un valor de 409 indica que los cambios causarían un conflicto
- una matriz de códigos de estado, en la que cada entrada corresponde al ID de revisión especificado en el archivo
- El cliente envía un
revmensaje para cada una de las revisiones solicitado en elproponerCambiosrespuesta en el paso 2. La direcciónrevEl cuerpo del mensaje contiene el documento en formato JSON, y las cabeceras del mensaje contienen metadatos:idcuyo valor es el ID del documento cuyo cuerpo se incluyerevcon el valor correspondiente a la revisión incluidasecuenciacon el ID de secuencia del cambiohistoriaque incluye una lista separada por comas de los ID de revisión desde el revisión de antepasados conocidos como se especifica en elcambiarespuesta
- Después de todo
revse han enviado mensajes, en continuo el cliente espera a que cambie la base de datos local y vuelve al paso 1. En un disparo la conexión se desconecta y finaliza la replicación.
Replicación Pull
Durante la replicación pull, una serie de cambios son enviados por el servidor de replicador pasivo en respuesta a una solicitud de pull del cliente replicador activo.
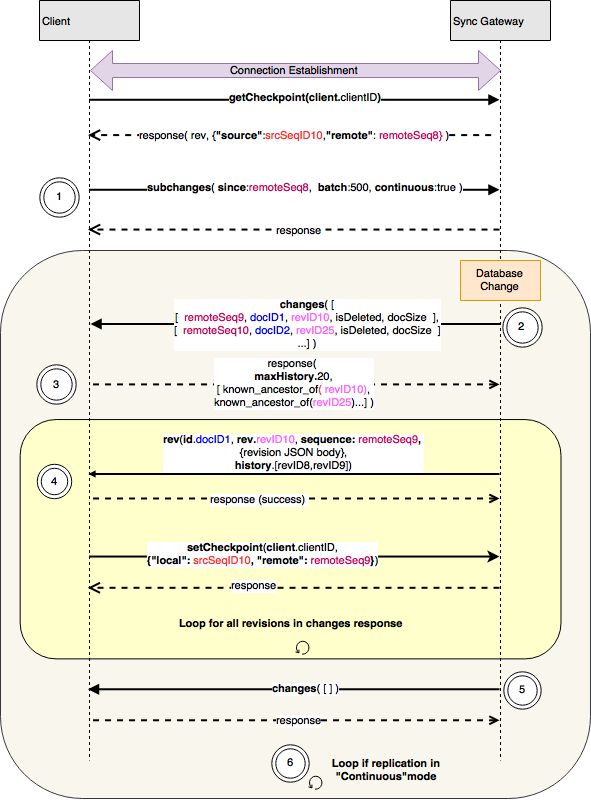
- Una vez recuperado el punto de control, el cliente envía un
subcambiosal servidor que incluye cabeceras:desdecon el valor del campo ID de secuencia remotacontinuopara indicar si está en modo continuo. Un valor deverdaderoindica que el cliente desea que se le notifiquen continuamente los cambios.lotecampo con valor que indica el número máximo de cambios que se enviarán en un solo mensaje
- El servidor envía un
cambiaal cliente con una matriz decambiarcorrespondientes a cada revisión actual que haya cambiado. Esto incluye las revisiones "tombstoned". El cambio en sí se codifica como un array JSON anidado e incluye:- ID de secuencia remota que es el ID de secuencia del cambio en el lado del servidor
- ID del documento del documento asociado a la modificación
- ID de revisión de la revisión actual del documento
- isDeleted para indicar si la revisión es un tombstone o no. Un valor de 1 indica que se trata de una revisión tombstone
- Opcionalmente, tamaño aproximado del cuerpo del documento
- La respuesta del cliente a la
cambiaincluye un objeto JSON que contiene:maxHistorycuyo valor es el tamaño máximo del historial que aceptará el cliente- un conjunto de antepasados conocidosuna entrada por cada ID de revisión especificado en el campo
cambiasolicitud. Un valor nulo para una entrada indica que el cliente no está interesado en la revisión correspondiente.
- El servidor envía un
revmensaje para cada una de las revisiones solicitado en elcambiarespuesta en el paso 3. La direcciónrevEl cuerpo del mensaje contiene el documento en formato JSON, y las cabeceras del mensaje contienen metadatos:idcampo cuyo valor corresponde al ID del documento cuyo cuerpo se incluyerevcon el valor correspondiente a la revisión incluidasecuenciacon el valor correspondiente al ID de secuencia del cambiohistoriaque incluye una lista separada por comas de los Id. de las revisiones desde el revisión de antepasados conocidos como se especifica encambiarespuesta
- Cuando termina de enviar los cambios, el servidor envía un
cambiapara indicar que no tiene más cambios que enviar. - Una vez enviados todos los cambios, en continuo la conexión permanece abierta mientras el servidor espera a que cambie la base de datos y, a continuación, vuelve al paso 2. En un disparo la conexión se desconecta y finaliza la replicación.
Nota que los pasos 2-4 son idénticos a los pasos 1-3 de la replicación push, sólo que con los roles 'cliente' y 'servidor' intercambiados. El protocolo de replicación es bastante simétrico, a diferencia de una API basada en HTTP, en la que los roles de cliente y servidor requieren un código completamente diferente. Esto ayuda a simplificar el diseño y la implementación, especialmente para la replicación peer-to-peer entre clientes.
Gestión de conflictos
Los conflictos se producen cuando hay concurrente actualizaciones del mismo revisión de documentos desde múltiples fuentes. Aquí "concurrente" significa "entre réplicas": si un cliente se desconecta durante una hora y vuelve, cualquier cambio realizado en ese cliente durante esa hora sería efectivamente concurrente con los cambios realizados por todos los demás clientes. En un sistema distribuido de este tipo, la concurrencia no es una rara condición de carrera, sino una realidad.
Couchbase Mobile 2.0 soporta un nuevo libre de conflictos modo. Los detalles sobre cómo se gestionan los conflictos en la versión 2.0 quedan fuera del alcance de esta entrada del blog, pero puedes leer más al respecto aquí. A alto nivel, cuando el cliente encuentra un conflicto al guardar una revisión, se invoca la llamada de retorno de resolución de conflictos asociada al documento y se utiliza la revisión fusionada resultante. Por lo tanto, el documento nunca existe visiblemente en un estado de conflicto. Puede leer más sobre esto en una próxima entrada del blog.
Pérdida de conexión con el servidor
Durante la replicación, si el cliente no puede conectarse al servidor o si se pierde la conexión con el servidor, el cliente intentará volver a conectarse utilizando un algoritmo de backoff exponencial, en el que espera cada vez más tiempo cada vez que vuelve a intentarlo.
- En caso de un disparo replicación, se realizará un máximo de dos intentos de reintento antes de que el cliente se dé por vencido.
- En caso de replicación continuael cliente intentará volver a conectarse indefinidamente, pero el intervalo de reintento no aumentará más allá de 10 minutos.
El replicador cancelará su temporizador y volverá a intentarlo inmediatamente si se le notifica que la conexión de red del dispositivo ha cambiado (se ha conectado a WiFi o a una red móvil), pero, debido a la forma en que funcionan las redes IP, el dispositivo sólo puede detectar cambios en sus propias interfaces de red, no cambios que se produzcan en cualquier otro lugar a lo largo de la ruta al servidor, ni siquiera en el router WiFi local. Así que enchufar el cable o la conexión Ethernet de nuevo en el router será no se detectará inmediatamente. Sin embargo, apagar el router sí se detectará, porque la interfaz de red WiFi del dispositivo se apagará.
Detectar una conexión perdida también puede ser problemático. Cuando una conexión TCP está inactiva no se envían paquetes en ninguna dirección, por lo que ninguno de los dos pares puede saber si el otro se desconecta bruscamente o si se corta una conexión a lo largo de la ruta entre ellos (por ejemplo, si se desenchufa el cable del router o Ethernet.) Para solucionar esto, los participantes envían mensajes periódicos "heartbeat". Si el remitente no recibe un paquete TCP ACK en respuesta a su mensaje en unos segundos, sabe que la conexión se ha interrumpido.
¿Qué sigue?
La arquitectura de replicación 2.0 en Couchbase Mobile 2.0 es más limpia, sencilla y eficiente en recursos que las versiones anteriores basadas en REST API/HTTP.
Si tiene alguna pregunta o sugerencia, deje un comentario a continuación o póngase en contacto conmigo a través de Twitter @rajagp o por correo electrónico. priya.rajagopal@couchbase.com. En Foros de Couchbase son otro buen lugar al que dirigirse con preguntas.
Por último, un agradecimiento especial a Jens Alfke (https://github.com/snej), por sus comentarios.