Introducción
Hay tres cosas importantes en los sistemas de bases de datos: rendimiento, rendimiento, rendimiento. Para los sistemas de bases de datos NoSQL, hay tres cosas importantes: rendimiento a escala, rendimiento a escala, rendimiento a escala.
Entender las opciones de índice, crear el índice correcto, con las claves correctas, el orden correcto y la expresión correcta es crítico para el rendimiento de las consultas y el rendimiento a escala en Couchbase. Hemos hablado de modelado de datos para JSON y consulta en JSON anterior. En este artículo, discutiremos las opciones de indexación para JSON en Couchbase.
Couchbase 5.0 tiene tres tipos de categorías de índice. Cada clúster de Couchbase solo puede tener una categoría de índice, ya sea índice secundario global estándar o índice secundario global optimizado para memoria.
| Secundaria estándar: versión 4.0 y superior |
|
| Índice de memoria optimizada: 4,5 y superior |
|
| Secundaria estándar: versión 5.0 |
|
El índice secundario estándar (de 4.0 a 4.6.x) almacena utiliza el motor de almacenamiento ForestDB para almacenar el índice B-Tree y mantiene el conjunto óptimo de trabajo de los datos en el buffer. Esto significa que el tamaño total del índice puede ser mucho mayor que la cantidad de memoria disponible en cada nodo de índice.
Un índice optimizado para memoria utiliza una novedosa lista de esquí sin bloqueos para mantener el índice y conserva 100% de los datos del índice en memoria. Un índice optimizado para memoria (MOI) tiene mejor latencia para las exploraciones del índice y también puede procesar las mutaciones de los datos mucho más rápido.
El índice secundario estándar de la versión 5.0 utiliza el motor de almacenamiento plasma de nuestra edición empresarial, que utiliza la lista de exclusión sin bloqueo como MOI, pero admite índices de gran tamaño que no caben en la memoria.
Los tres tipos de índices implementan el control de concurrencia multiversión (MVCC) para proporcionar resultados de escaneo de índices consistentes y un alto rendimiento. Durante la instalación del clúster, elija el tipo de índice.
El objetivo es ofrecerle una visión general de los distintos índices que se crean en cada uno de estos servicios para que sus consultas puedan ejecutarse de forma eficiente. El objetivo de este artículo no es describir o comparar y contrastar estos dos tipos de servicios de índice. No cubre el Índice de Búsqueda de Texto Completo (FTS), lanzado en Couchbase 5.0.
Tomemos el viaje-muestra y probar estos índices.
En la consola web, vaya a Configuración->Cubos de muestra para instalar la muestra de viaje.
Aquí tienes los distintos índices que puedes crear.
- Índice primario
- Índice primario con nombre
- Índice secundario
- Índice compuesto secundario
- Índice funcional
- Índice de matrices
- matriz ALL
- matriz ALL DISTINCT
- Índice parcial
- Índice adaptativo
- Índices duplicados
- Índice de cobertura
Fondo
Couchbase es una base de datos distribuida. Soporta un modelo de datos flexible usando JSON. Cada documento en un bucket tendrá una clave de documento única generada por el usuario. Esta unicidad se aplica durante la inserción de los datos.
He aquí un documento de ejemplo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT meta().id, travel FROM `travel-sample` travel WHERE type = 'airline' limit 1; [ { "id": "airline_10", "travel": { "callsign": "MILE-AIR", "country": "United States", "iata": "Q5", "icao": "MLA", "id": 10, "name": "40-Mile Air", "type": "airline" } } ] |
Tipo de índices
1. Índice primario
crea el índice primario en "viaje-muestra":
El índice primario es simplemente el índice de la clave de documento de todo el bucket. La capa de datos de Couchbase impone la restricción de unicidad en la clave del documento. El índice primario, como cualquier otro índice en Couchbase, se mantiene de forma asíncrona. Se puede establecer la recencia de los datos estableciendo el parámetro nivel de coherencia para su consulta.
Estos son los metadatos de este índice:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT * FROM system:indexes WHERE name = ‘#primary’; "indexes": { "datastore_id": "https://127.0.0.1:8091", "id": "f6e3c75d6f396e7d", "index_key": [], "is_primary": true, "keyspace_id": "travel-sample", "name": "#primary", "namespace_id": "default", "state": "online", "using": "gsi" } |
Los metadatos proporcionan información adicional sobre el índice: Dónde reside el índice (datastore_id), su estado (state) y el método de indexación (using).
El índice primario se utiliza para escaneos de bucket completos (escaneos primarios) cuando la consulta no tiene ningún filtro (predicados) o se puede utilizar otro índice o ruta de acceso. En Couchbase, almacenas múltiples keyspaces (documentos de diferente tipo, clientes, pedidos, inventario, etc) en un único bucket. Entonces, cuando haces el escaneo primario, la consulta usará el índice para obtener las claves de los documentos y buscará todos los documentos en el bucket y luego aplicará el filtro. Esto es MUY CARO.
El diseño de la clave de documento es algo así como un diseño de clave primaria con múltiples partes.
Lastname:firstname:customerid
Example: smith:john:X1A1849
En Couchbase, es una buena práctica prefijar la clave con el tipo de documento. Dado que se trata de un documento de cliente, pongamos el prefijo CX. Ahora, la clave se convierte en:
|
1 |
Example: CX:smith:john:X1A1849 |
Así que, en el mismo cubo, habrá otros tipos de documentos.
|
1 |
ORDERS type: OD:US:CA:294829 |
|
1 |
ITEMS type: IT:KD93823 |
Estas son simplemente las mejores prácticas. No hay restricciones sobre el formato o la estructura de la clave del documento en Couchbase, excepto que tienen que ser únicas dentro de un bucket.
Ahora, si tienes documentos con varias claves y tienes un índice primario, puedes utilizar las siguientes consultas de forma eficiente.
Ejemplo 1: Búsqueda de una clave de documento específica.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT * FROM sales WHERE META().id = “CX:smith:john:X1A1849”; { "#operator": "IndexScan2", "index": "#primary", "index_id": "4c92ab0bcca9690a", "keyspace": "sales", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CX:smith:john:X1A1849\"", "inclusion": 3, "low": "\"CX:smith:john:X1A1849\"" } ] } ], } |
Si conoce la clave completa del documento, puede utilizar la siguiente sentencia y evitar por completo el acceso al índice.
SELECT * FROM sales USE KEYS [“CX:smith:john:X1A1849”]
Puede obtener más de un documento en una declaración.
|
1 |
SELECT * FROM sales USE KEYS [“CX:smith:john:X1A1849”, “CX:smithjr:john:X2A1492”] |
Ejemplo 2: Busque un patrón. Consigue TODOS los documentos del cliente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT * FROM sales WHERE META().id LIKE “CX:%”; { "#operator": "IndexScan2", "index": "#primary", "index_id": "4c92ab0bcca9690a", "keyspace": "sales", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CX;\"", "inclusion": 1, "low": "\"CX:\"" }" ] } ], } |
Ejemplo 3: Consiga todos los clientes con "herrero" como apellido.
La siguiente consulta utiliza el índice primario de forma eficiente, obteniendo únicamente los clientes con un rango determinado. Nota: Este escaneo distingue entre mayúsculas y minúsculas. Para realizar una exploración sin distinguir mayúsculas de minúsculas, puede crear un índice secundario con UPPER() o LOWER() de la clave del documento.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT * FROM sales WHERE META().id LIKE "CX:smith%"; { "#operator": "IndexScan2", "index": "#primary", "index_id": "4c92ab0bcca9690a", "keyspace": "sales", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CX:smiti\"", "inclusion": 1, "low": "\"CX:smith\"" } ] } ], } |
Ejemplo 4: Es habitual que algunas aplicaciones utilicen una dirección de correo electrónico como parte del documento, ya que son valores únicos. En ese caso, necesita averiguar todos los clientes con "@gmail.com". Si este es un requerimiento típico, entonces, almacene el REVERSO de la dirección de correo electrónico como la clave y simplemente haga el escaneo del patrón de cadena líder.
Email:johnsmith@gmail.com; key: reverse("johnsmith@gmail.com") => moc.liamg@htimsnhoj
Email: janesnow@yahoo.com key: reverse("janesnow@yahoo.com") => moc.oohay@wonsenaj
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT * FROM sales WHERE meta().id LIKE (reverse("@yahoo.com") || "%"); { "#operator": "IndexScan2", "index": "#primary", "index_id": "4c92ab0bcca9690a", "keyspace": "sales", "namespace": "default", "spans": [ { "range": [ { "high": "\"moc.oohayA\"", "inclusion": 1, "low": "\"moc.oohay@\"" } ] } ], } |
2. Índice primario con nombre
En Couchbase 5.0, puedes crear múltiples réplicas de cualquier índice con un simple parámetro a CREATE INDEX. Lo siguiente creará 3 copias del índice y tiene que haber un mínimo de 3 nodos de índice en el clúster.
|
1 2 |
CREATE PRIMARY INDEX ON 'travel-sample' WITH {"num_replica":2}; CREATE PRIMARY INDEX `def_primary` ON `travel-sample` ; |
También puede asignar un nombre al índice primario. El resto de las características del índice primario son las mismas, excepto el nombre del índice. Un buen efecto secundario de esto es que puedes tener múltiples índices primarios en versiones de Couchbase anteriores a la 5.0 usando diferentes nombres. Los índices duplicados ayudan a la alta disponibilidad así como a la distribución de la carga de consultas a través de ellos. Esto es cierto tanto para los índices primarios como para los secundarios.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT meta().id as documentkey, `travel-sample` airline FROM `travel-sample` WHERE type = 'airline' limit 1; { "airline": { "callsign": "MILE-AIR", "country": "United States", "iata": "Q5", "icao": "MLA", "id": 10, "name": "40-Mile Air", "type": "airline" }, "documentkey": "airline_10" } |
3. Índice secundario
El índice secundario es un índice sobre cualquier clave-valor o clave-documento. Este índice puede ser cualquier clave dentro del documento. La clave puede ser de cualquier tipo: escalar, objeto o matriz. La consulta tiene que utilizar el mismo tipo de objeto para que el motor de consulta pueda explotar el índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
CREATE INDEX travel_name ON `travel-sample`(name); name is a simple scalar value. { "name": "Air France" } CREATE INDEX travel_geo on `travel-sample`(geo); geo is an object embedded within the document. Example: "geo": { "alt": 12, "lat": 50.962097, "lon": 1.954764 } Creating indexes on keys from nested objects is straightforward. CREATE INDEX travel_geo on `travel-sample`(geo.alt); CREATE INDEX travel_geo on `travel-sample`(geo.lat); |
El campo horario es una matriz de objetos con los detalles del vuelo. Esto indexa el array completo. No es exactamente útil a menos que estés buscando el array completo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CREATE INDEX travel_schedule ON `travel-sample`(schedule); Example: "schedule": [ { "day": 0, "flight": "AF198", "utc": "10:13:00" }, { "day": 0, "flight": "AF547", "utc": "19:14:00" }, { "day": 0, "flight": "AF943", "utc": "01:31:00" }, { "day": 1, "flight": "AF356", "utc": "12:40:00" }, { "day": 1, "flight": "AF480", "utc": "08:58:00" }, { "day": 1, "flight": "AF250", "utc": "12:59:00" } ] |
4. Índice secundario compuesto
Es común tener consultas con múltiples filtros (predicados). Por lo tanto, se desean índices con múltiples claves para que los índices puedan devolver sólo las claves cualificadas de los documentos. Además, si una consulta sólo hace referencia a las claves del índice, el motor de consulta simplemente responderá a la consulta a partir del resultado de la exploración del índice sin ir a los nodos de datos. Se trata de una optimización de rendimiento muy utilizada.
|
1 |
CREATE INDEX idx_stctln ON `travel-sample` (state, city, name.lastname) |
Cada una de las claves puede ser un campo escalar simple, un objeto o una matriz. Para que se pueda aprovechar el filtrado de índices, los filtros tienen que utilizar el tipo de objeto correspondiente en el filtro de consulta. Las claves de los índices secundarios pueden incluir claves de documento (meta().id) explícitamente si es necesario filtrar sobre ellas en el índice.
Veamos las consultas que aprovechan y las que no aprovechan el índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
1.SELECT * FROM `travel-sample` WHERE state = 'CA'; The predicate matches the leading key of the index. So, this query uses the index to fully evaluate the predicate (state = ‘CA’). 2.SELECT * FROM `travel-sample` WHERE state = 'CA' AND city = 'Windsor'; The predicates match the leading two keys. So this is good fit as well. 3.SELECT * FROM `travel-sample` WHERE state = 'CA' AND city = 'Windsor' AND name.lastname = 'smith'; The three predicates in this query matches the three index keys perfectly. So, this is a good match. 4.SELECT * FROM `travel-sample` WHERE city = 'Windsor' AND name.lastname = 'smith'; In this query, although predicates match two of the index keys, the leading key isn’t matched. So, the index cannot and is not used for this query plans. 5.SELECT * FROM `travel-sample` WHERE name.lastname = 'smith'; Similar to previous query, this query has the predicate on the third key of the index. So, this index cannot be used. 6.SELECT * FROM `travel-sample` WHERE state = 'CA' AND name.lastname = 'smith'; This query has predicate on first and the third key. While this index is and can be chosen, we cannot push down the predicate after skipping an index key (second key in this case). So, only the first predicate (state = "CA") will be pushed down to index scan. "#operator": "IndexScan2", "index": "idx_stctln", "index_id": "dadbb12da565ed28", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CA\"", "inclusion": 3, "low": "\"CA\"" } ] } 7.SELECT * FROM `travel-sample` WHERE state IS NOT MISSING AND city = 'Windsor' AND name.lastname = 'smith'; This is a modified version of query 4 above. To use this index, the query needs to have an additional predicate (state IS NOT MISSING) assuming that represents your application requirement. |
5. Índice funcional (expresión)
Es habitual tener nombres en la base de datos con una mezcla de mayúsculas y minúsculas. Cuando necesites buscar "Juan", quieres que busque cualquier combinación de "Juan", "juan", etc. Así es como se hace.
CREATE INDEX travel_cxname ON `travel-sample`(LOWER(name));
Proporcione la cadena de búsqueda en minúsculas y el índice buscará eficazmente los valores ya escritos en minúsculas en el índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
EXPLAIN SELECT * FROM `travel-sample` WHERE LOWER(name) = "john"; { "#operator": "IndexScan", "index": "travel_cxname", "index_id": "2f39d3b7aac6bbfe", "keyspace": "travel-sample", "namespace": "default", "spans": [ { "Range": { "High": [ "\"john\"" ], "Inclusion": 3, "Low": [ "\"john\"" ] } } ] } |
Puede utilizar expresiones complejas en este índice funcional.
CREATE INDEX travel_cx1 ON `travel-sample`(LOWER(name), length*width, round(salary));
También verás que se pueden crear índices de array en una expresión que devuelva un array en la siguiente sección.
6. Índice de matrices
JSON es jerárquico. En el nivel superior, puede tener campos escalares, objetos o matrices. Cada objeto puede anidar otros objetos y matrices. Cada array puede tener otros objetos y arrays. Y así sucesivamente. El anidamiento continúa.
Cuando tienes esta rica estructura, así es como indexas un array particular o un campo dentro del sub-objeto.
Considera la matriz, programa:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
schedule: [ { "day" : 0, "special_flights" : [ { "flight" : "AI111", "utc" : ”1:11:11" }, { "flight" : "AI222", "utc" : ”2:22:22" } ] }, { "day": 1, "flight": "AF552", "utc": "14:41:00” } ] CREATE INDEX travel_sched ON `travel-sample` (ALL DISTINCT ARRAY v.day FOR v IN schedule END) |
v es la variable que hemos declarado implícitamente para hacer referencia a cada elemento/objeto dentro de la matriz: schedule v.day hace referencia al elemento dentro de cada objeto de la matriz schedule.
La siguiente consulta explotará el índice del array.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
EXPLAIN SELECT * FROM `travel-sample` WHERE ANY v IN SCHEDULE SATISFIES v.day = 2 END; { "#operator": "DistinctScan", "scan": { "#operator": "IndexScan", "index": "travel_sched", "index_id": "db7018bff5f10f17", "keyspace": "travel-sample", "namespace": "default", "spans": [ { "Range": { "High": [ "2" ], "Inclusion": 3, "Low": [ "2" ] } } ], "using": "gsi" } |
Dado que la clave es una expresión generalizada, dispone de flexibilidad para aplicar lógica y procesamiento adicionales a los datos antes de indexarlos. Por ejemplo, puede crear una indexación funcional en los elementos de cada matriz. Dado que se está haciendo referencia a campos individuales del objeto o elemento dentro de la matriz, la expresión creación de índices, el tamaño y la búsqueda son eficientes. El índice anterior sólo almacena los valores distintos dentro de una matriz. Para almacenar todos los elementos de una matriz en un índice, utilice el modificador DISTINCT en la expresión.
CREATE INDEX travel_sched ON `travel-sample` (ALL DISTINCT ARRAY v.day FOR v IN schedule END)
El índice de array se puede crear sobre valores estáticos (como arriba) o una expresión que devuelva un array. TOKENS() son una de estas expresiones, devolviendo un array de tokens de un objeto. Puede crear un índice en esta matriz y buscar utilizando el índice.
Couchbase 5.0 hace más sencillo crear y emparejar los índices de array. Proporcionando el prefijo ALL ( o ALL DISTINCT) a la clave la convertirá en una clave de array.
|
1 2 3 4 5 6 7 8 9 |
CREATE INDEX idx_cx6 ON `travel-sample`(ALL TOKENS(public_likes)) WHERE type = ‘hotel’; SELECT t.name, t.country, t.public_likes FROM `travel-sample` t WHERE t.type = 'hotel’ AND ANY p IN TOKENS(public_likes) SATISFIES p = 'Vallie' END; |
Los índices de matrices también pueden crearse en elementos dentro de matrices de matrices. No hay límite en el nivel de anidamiento de la expresión de la matriz. La expresión de la consulta debe coincidir con la expresión del índice.
7. Índice parcial
Hasta ahora, los índices que hemos creado crearán índices sobre todo el bucket. Como el modelo de datos de Couchbase es JSON y los esquemas JSON son flexibles, un índice puede no contener entradas a documentos con claves de índice ausentes. Eso es lo esperado. A diferencia de los sistemas relacionales, donde cada tipo de fila está en una tabla distinta, los buckets de Couchbase pueden tener documentos de varios tipos. Normalmente, los clientes incluyen un campo de tipo para diferenciar los distintos tipos.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "airline": { "callsign": "MILE-AIR", "country": "United States", "iata": "Q5", "icao": "MLA", "id": 10, "name": "40-Mile Air", "type": "airline" }, "documentkey": "airline_10" } |
Si desea crear un índice de documentos de líneas aéreas, sólo tiene que añadir el campo de tipo para la cláusula WHERE del índice.
CREATE INDEX travel_info ON `travel-sample`(name, id, icoo, iata) WHERE type = 'airline';
Esto creará un índice sólo en los documentos que tengan (tipo = 'compañía aérea'). En tus consultas, tendrías que incluir el filtro (tipo = 'compañía aérea') además de otros filtros para que este índice cumpla los requisitos.
Puede utilizar predicados complejos en la cláusula WHERE del índice. Varios casos de uso para explotar los índices parciales son:
- Partición de un índice grande en varios índices mediante la función mod.
- Partición de un índice grande en varios índices y colocación de cada índice en nodos indexadores distintos.
- Partición del índice en función de una lista de valores. Por ejemplo, puede tener un índice para cada estado.
- Simulando la partición del rango del índice a través de un filtro de rango en la cláusula WHERE. Una cosa a recordar es que las consultas N1QL de Couchbase usarán un índice particionado por bloque de consulta. Usa UNION ALL para que una consulta explote múltiples índices particionados en una sola consulta.
8. Índice adaptativo
Un índice adaptativo crea un índice único en todo el documento o conjunto de campos de un documento. Se trata de un índice de forma o matriz que utiliza el par {"clave": valor} como clave única del índice. El propósito es evitar la pesadilla de una consulta que tiene que coincidir con las claves principales del índice en los índices tradicionales.
El índice adaptativo tiene dos ventajas:
- Se pueden evaluar múltiples predicados en el espacio de claves utilizando diferentes secciones del mismo índice.
- Evite crear varios índices sólo para reordenar las claves del índice.
- Evite el orden de las claves de índice.
Por ejemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CREATE INDEX `ai_self` ON `travel-sample`(DISTINCT PAIRS(ai_self)) WHERE type = "airport"; EXPLAIN SELECT * FROM `travel-sample` WHERE faa = "SFO" AND `type` = "airport"; { "#operator": "IntersectScan", "scans": [ { "#operator": "IndexScan2", "index": "ai_self", "index_id": "c564a55225d9244c", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "[\"faa\", \"SFO\"]", "inclusion": 3, "low": "[\"faa\", \"SFO\"]" } ] } ], "using": "gsi" } ... ] } |
El mismo índice puede utilizarse también para consultas con otros predicados. Esto reduce el número de índices que tendrías que crear a medida que crece el documento.
|
1 2 3 4 |
EXPLAIN SELECT * FROM `travel-sample` WHERE city = "Seattle" AND `type` = "airport"; |
Consideraciones sobre su uso:
- Dado que cada campo de atributo tiene una entrada de índice, el tamaño de los índices puede ser enorme.
- El índice adaptativo es un índice de matriz. Está limitado por la restricción de los índices del array.
Consulte la documentación detallada sobre índice adaptativo en la documentación de Couchbase.
9. Índice de duplicados
Esto no es realmente un tipo especial de índice, sino una característica de la indexación de Couchbase. Puedes crear índices duplicados con nombres distintos.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE INDEX i1 ON `travel-sample`(LOWER(name),id, icoo) WHERE type = ‘airline’; CREATE INDEX i2 ON `travel-sample`(LOWER(name),id, icoo) WHERE type = ‘airline’; CREATE INDEX i3 ON `travel-sample`(LOWER(name),id, icoo) WHERE type = ‘airline’; |
Los tres índices tienen claves idénticas, cláusula WHERE idéntica; la única diferencia es el nombre de los índices. Puede elegir su ubicación física mediante la cláusula WITH de CREATE INDEX. Durante la optimización de la consulta, ésta elegirá uno de los nombres. Lo verá en su plan. Durante la ejecución de la consulta, estos índices se utilizan de forma rotatoria para distribuir la carga. Esto proporciona escalabilidad, escalabilidad multidimensional, rendimiento y alta disponibilidad. No está nada mal.
Couchbase 5.0 hace el índice duplicado MÁS SENCILLO. En lugar de crear múltiples índices con nombres distintos, puedes simplemente especificar el número de índices de réplica que necesitas.
|
1 2 3 4 |
CREATE INDEX i1 ON `travel-sample`(LOWER(name),id, icoo) WHERE type = ‘airline’ WITH {"num_replica" : 2 }; |
Esto creará 2 copias adicionales del índice además del índice i1. Las funciones de equilibrio de carga y HA son las mismas que un índice equivalente.
10. Índice de cobertura
La selección del índice para una consulta depende únicamente de los filtros de la cláusula WHERE de la consulta. Una vez hecha la selección del índice, el motor analiza la consulta para ver si puede responderse utilizando sólo los datos del índice. En caso afirmativo, el motor de consulta omite la recuperación del documento completo. Se trata de una optimización del rendimiento que hay que tener en cuenta al diseñar los índices.
¡Todos juntos ya!
Vamos a crear un índice de matriz funcional compuesta particionada.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE INDEX travel_all ON `travel-sample`( iata, LOWER(name), UPPER(callsign), ALL DISTINCT ARRAY p.model FOR p IN jets END), TO_NUMBER(rating), meta().id ) WHERE LOWER(country) = "united states" AND type = "airline" WITH {"num_replica" : 2} |
Reglas para crear los índices.
Hasta ahora, hemos visto los tipos de índices. Veamos ahora cómo diseñar los índices para tu carga de trabajo.
Regla #1: UTILIZAR CLAVES
En Couchbase, cada documento de un bucket tiene una clave única generada por el usuario. Los documentos se distribuyen entre los distintos nodos mediante el hash de esta clave (nosotros utilizamos hashing coherente). Cuando tenga la clave del documento, puede obtener los documentos directamente de las aplicaciones (a través de SDK). Incluso cuando se tienen las claves de los documentos, es posible que se desee hacer la obtención y hacer algún post-procesamiento a través de N1QL. Es entonces cuando se utiliza el método USE KEYS.

Por ejemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
SELECT name, address FROM `travel-sample` h USE KEYS [ "hotel_10025", "hotel_10026", "hotel_10063", "hotel_10064", "hotel_10138", "hotel_10142", "hotel_10158", "hotel_10159", "hotel_10160", "hotel_10161", "hotel_10180", "hotel_10289", "hotel_10290", "hotel_10291", "hotel_1072", "hotel_10848", "hotel_10849", "hotel_10850", "hotel_10851", "hotel_10904" ] WHERE h.country = "United Kingdom" AND ARRAY_LENGTH(public_likes) > 3; |
El método de acceso USE KEYS puede utilizarse incluso cuando se realizan uniones. He aquí un ejemplo:
SELECT * FROM ORDERS o USE KEYS ["ord::382"] INNER JOIN CUSTOMER c ON KEYS o.id;
En Couchbsae 5.0, los índices sólo se utilizan para procesar el primer espacio clave (bucket) de cada cláusula FROM. Los espacios clave posteriores se procesan mediante la obtención directa del documento.
SELECT * FROM ORDERS o INNER JOIN CUSTOMER c ON KEYS o.id WHERE o.state = "CA";
En esta sentencia, procesamos el espacio de claves ORDERS a través de un índice sobre (estado) si está disponible. En caso contrario, utilizamos el índice primario para escanear ORDERS. A continuación, obtenemos los documentos de CLIENTES que coinciden con el identificador del documento de PEDIDOS.
Norma #2: UTILIZAR ÍNDICE DE COBERTURA
Ya hemos hablado de los tipos de índice. El índice correcto sirve para dos cosas:
- Reducir el conjunto de trabajo de la consulta para acelerar su rendimiento
- Almacenar y proporcionar datos adicionales incluso.
Cuando una consulta puede responderse completamente con los datos almacenados en el índice, se dice que la consulta es cubierta por el índice de cobertura. Debe intentar que la mayoría de sus consultas, si no todas, estén cubiertas. Esto reducirá la carga de procesamiento en el servicio de consulta, reducir la obtención adicional del servicio de datos.
La selección del índice se sigue realizando en función de los predicados de la consulta. Una vez realizada la selección del índice, el optimizador evaluará si el índice contiene todos los atributos necesarios para la consulta y creará un acceso cubierto a la ruta del índice.
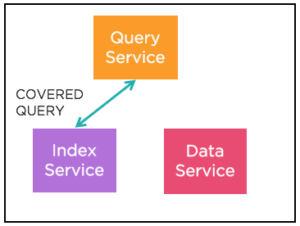
Ejemplos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CREATE INDEX idx_cx3 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium'; /* The query below won’t be covered since you said: SELECT * */ SELECT * FROM CUSTOMER WHERE state = 'CA’ AND status = 'premium'; /* The index has all three fields required by the query. */ /* Query will be covered, as shown in the explain plan. */ SELECT status, state, city FROM CUSTOMER WHERE state = 'CA' AND status = 'premium'; { "#operator": "IndexScan2", "covers": [ "cover ((`CUSTOMER`.`state`))", "cover ((`CUSTOMER`.`city`))", "cover (((`CUSTOMER`.`name`).`lastname`))", "cover ((meta(`CUSTOMER`).`id`))" ], "filter_covers": { "cover ((`CUSTOMER`.`status`))": "premium" }, "index": "idx_cx3", "index_id": "18f8209144215971", "index_projection": { "entry_keys": [ 0, 1 ] } |
Observe que el campo status de la cláusula WHERE del índice (status = 'premium') también está cubierto. Sabemos que todos los documentos del índice tienen un campo llamado estado con el valor "premium". Podemos simplemente proyectar este valor. El campo "Filter_covers" de la explicación muestra esta información.
Mientras el índice tenga el campo, una consulta puede realizar filtrados adicionales, uniones, agregación, paginación después de obtener los datos del indexador sin obtener el documento completo.
Regla #3: UTILIZAR LA REPLICACIÓN DE ÍNDICES
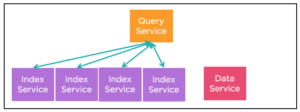
En un cluster de Couchbase, tienes múltiples servicios de índices. Antes de Couchbase 5.0, podías crear manualmente índices de réplica (equivale) para mejorar el rendimiento, el equilibrio de carga y la alta disponibilidad.
Antes de la 5.0:
|
1 2 3 4 5 6 7 8 9 |
CREATE INDEX idx1 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium'; CREATE INDEX idx2 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium'; CREATE INDEX idx3 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium'; |
Reconocemos la equivalencia de estos tres índices porque las expresiones clave y la cláusula WHERE son exactamente lo mismo.
Durante la fase de optimización de la consulta, el motor N1QL elige uno de los tres índices para el escaneo de índices (suponiendo que se cumplan otros requisitos) para crear el plan de consulta. Durante la ejecución de la consulta, ésta prepara el paquete de escaneo y envía una solicitud de escaneo de índice. Durante este proceso, basándonos en las estadísticas de carga, enviamos la petición a uno de ellos. La idea es que, con el tiempo, cada uno de ellos tenga una carga similar.
Este proceso de creación de índices réplica (índices equivalentes) se facilita con un simple parámetro.
|
1 2 3 4 |
CREATE INDEX idx1 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium' WITH { "num_replica":2 }; |
Es lo mismo que crear tres índices distintos pero equivalentes.
Regla #4: INDEXAR POR CARGA DE TRABAJO, NO POR BUCKET/KEYSPACE
Considere toda la carga de trabajo de la aplicación y los acuerdos de nivel de servicio (SLA) para cada una de las consultas. Las consultas que tengan requisitos de latencia de milisegundos con un alto rendimiento requerirán índices personalizados y réplicas, mientras que otras podrían compartir índices.
Puede haber espacios de claves en los que simplemente se realicen operaciones set & get o en los que se puedan realizar consultas con USE KEYS. Estos espacios de claves no necesitarán índices.
Analice las consultas para encontrar los predicados comunes, proyecciones de un espacio de claves. Puede optimizar el número de índices basándose en los predicados comunes. Si una de sus consultas no tiene un predicado en la clave o claves principales, vea si añadir (campo NO FALTA) tiene sentido para que el índice pueda ser compartido.
Está bien tener un índice primario mientras desarrollas tu aplicación o consultas. Pero, antes de realizar pruebas, cree los índices adecuados y elimine el índice primario de su sistema, a menos que su aplicación utilice los casos descritos en la sección "Índice primario". Si tienes un índice primario en producción y las consultas acaban haciendo un escaneo primario completo con un span completo en el índice, te estás buscando problemas. En Couchbase, el índice primario indexa todos los documentos del bucket.
Cada índice secundario en Couchbase debería tener una cláusula WHERE, con al menos una condición sobre el tipo de documento. Esto no lo impone el sistema, pero es un buen diseño.
|
1 2 3 |
CREATE INDEX def_route_src_dst ON `travel-sample` (`sourceairport`, `destinationairport`) WHERE (`type` = "route"); |
Crear los índices adecuados es una de las mejores prácticas para optimizar el rendimiento. Esto no es lo único que hay que hacer para obtener el mejor rendimiento. La configuración del clúster, el ajuste, la configuración del SDK y el uso de sentencias preparadas desempeñan un papel importante.
Regla #5: INDEXAR POR PREDICADO, NO POR PROYECTO
Parece una regla obvia. Pero de vez en cuando me encuentro con gente que comete este error.
Considere la consulta:
|
1 2 3 4 |
SELECT city, state, status FROM CUSTOMER WHERE state = 'CA' AND status = 'premium'; |
La consulta puede utilizar cualquiera de los siguientes índices:
|
1 2 3 4 5 6 |
Create index i1 on CUSTOMER(state); Create index i2 on CUSTOMER(status); Create index i3 on CUSTOMER(state, status); Create index i4 on CUSTOMER(status, state); Create index i5 on CUSTOMER(state) WHERE status = “premium”; Create index i6 on CUSTOMER(status) WHERE status = “CA”; |
Para que el índice cubra completamente la consulta, basta con añadir el campo ciudad al índice 3-6.
Sin embargo, si tiene un índice con la ciudad como clave principal, el optimizador no lo detectará.
|
1 2 3 |
Create index i7 O ON CUSTOMER(city, state) WHERE status = “premium”; |
Consulte el artículo detallado sobre cómo funciona la exploración de índices en varios escenarios para optimizar el índice: https://dzone.com/articles/understanding-index-scans-in-couchbase-50-n1ql-que
Norma #6: AÑADIR ÍNDICES PARA CUMPLIR LOS ANS
Para las bases de datos relacionales, lo más importante eran tres cosas: rendimiento, rendimiento y rendimiento.
Para las bases de datos NoSQL, lo más importante son tres cosas: rendimiento a escala, rendimiento a escala, rendimiento a escala.
Una cosa son tus consultas ejecutando pruebas básicas de rendimiento en tu portátil, y otra cosa es ejecutar las consultas de alto rendimiento y baja latencia en el clúster. Afortunadamente, en Couchbase es fácil identificar y escalar los recursos cuello de botella de forma independiente, gracias al escalado multidimensional. Cada uno de los servicios en Couchbase se abstrae en servicios distintos: datos, índice, consulta. La consola de Couchbase tiene estadísticas de cada uno de los servicios de forma independiente.
Una vez creados los índices para sus consultas y optimizados los índices para la carga de trabajo, puede añadir índices de réplica (equivalentes) adicionales para mejorar la latencia, ya que equilibramos la carga de los escaneos entre los índices de réplica.
Regla #7: ÍNDICE PARA EVITAR LA CLASIFICACIÓN
El índice ya tiene los datos en el orden de las claves del índice. Tras la exploración, el índice devuelve los resultados en el orden de las claves del índice.
|
1 2 3 |
CREATE INDEX idx3 ON `travel-sample`(state, city, name.lastname) WHERE status = 'premium'; |
Los datos se almacenan y devuelven en el orden: estado, ciudad, nombre.apellido. Por lo tanto, si tienes una consulta que espera los datos en el orden estado, ciudad, nombre.apellido, un índice te ayudará a evitar la ordenación.
En este ejemplo, los resultados se ordenan por nombre.apellido, la tercera clave del índice. Por lo tanto, es necesario ordenar el conjunto de resultados por nombre.apellido. Explain le indicará si el plan requiere esta ordenación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
EXPLAIN SELECT state, city, name.lastname FROM `travel-sample` WHERE status = ‘premium’ AND state = ‘CA’ AND city LIKE ‘san%’ ORDER BY name.lastname; { "plan": { "#operator": "Sequence", "~children": [ { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`state`))", "cover ((`travel-sample`.`city`))", "cover (((`travel-sample`.`name`).`lastname`))", "cover ((meta(`travel-sample`).`id`))" ], "filter_covers": { "cover ((`travel-sample`.`status`))": "premium" }, "index": "idx3", "index_id": "19a5aed899d281fe", "index_projection": { "entry_keys": [ 0, 1, 2 ] }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CA\"", "inclusion": 3, "low": "\"CA\"" }, { "high": "\"sao\"", "inclusion": 1, "low": "\"san\"" } ] } ], "using": "gsi" }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "Filter", "condition": "(((cover ((`travel-sample`.`status`)) = \"premium\") and (cover ((`travel-sample`.`state`)) = \"CA\")) and (cover ((`travel-sample`.`city`)) like \"san%\"))" }, { "#operator": "InitialProject", "result_terms": [ { "expr": "cover ((`travel-sample`.`state`))" }, { "expr": "cover ((`travel-sample`.`city`))" }, { "expr": "cover (((`travel-sample`.`name`).`lastname`))" } ] } ] } } ] }, { "#operator": "Order", "sort_terms": [ { "expr": "cover (((`travel-sample`.`name`).`lastname`))" } ] }, { "#operator": "FinalProject" } ] }, "text": "SELECT state, city, name.lastname \nFROM `travel-sample`\nWHERE status = 'premium' AND state = 'CA' AND city LIKE 'san%'\nORDER BY name.lastname;" } |
La consulta siguiente tiene la correspondencia perfecta para las claves del índice. Por lo tanto, la ordenación es innecesaria. En la salida explain, falta el operador de ordenación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
EXPLAIN SELECT state, city, name.lastname FROM `travel-sample` WHERE status = ‘premium’ AND state = ‘CA’ AND city LIKE ‘san%’ ORDER BY state, city, name.lastname; { "plan": { "#operator": "Sequence", "~children": [ { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`state`))", "cover ((`travel-sample`.`city`))", "cover (((`travel-sample`.`name`).`lastname`))", "cover ((meta(`travel-sample`).`id`))" ], "filter_covers": { "cover ((`travel-sample`.`status`))": "premium" }, "index": "idx3", "index_id": "19a5aed899d281fe", "index_projection": { "entry_keys": [ 0, 1, 2 ] }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CA\"", "inclusion": 3, "low": "\"CA\"" }, { "high": "\"sao\"", "inclusion": 1, "low": "\"san\"" } ] } ], "using": "gsi" }, { "#operator": "Parallel", "maxParallelism": 1, "~child": { "#operator": "Sequence", "~children": [ { "#operator": "Filter", "condition": "(((cover ((`travel-sample`.`status`)) = \"premium\") and (cover ((`travel-sample`.`state`)) = \"CA\")) and (cover ((`travel-sample`.`city`)) like \"san%\"))" }, { "#operator": "InitialProject", "result_terms": [ { "expr": "cover ((`travel-sample`.`state`))" }, { "expr": "cover ((`travel-sample`.`city`))" }, { "expr": "cover (((`travel-sample`.`name`).`lastname`))" } ] }, { "#operator": "FinalProject" } ] } } ] } ] }, "text": "SELECT state, city, name.lastname \nFROM `travel-sample`\nWHERE status = 'premium' AND state = 'CA' AND city LIKE 'san%'\nORDER BY state, city, name.lastname;" } |
Explotar el orden de clasificación del índice puede no parecer importante hasta que se ve el caso de uso de la paginación. Cuando la consulta ha especificado OFFSET y LIMIT, se puede utilizar un índice para eliminar de forma eficiente los documentos que a la aplicación no le interesan o no necesita. Véase el artículo sobre paginación para más detalles.
El optimizador N1QL primero selecciona el índice basándose en los predicados de la consulta (filtros) y luego verifica si el índice puede cubrir todas las referencias de la consulta en proyección y orden por. Después, el optimizador intenta eliminar la ordenación y decidir sobre el pushdown de OFFSET y LIMIT. La explicación muestra si el OFFSET y el LIMIT fueron empujados a la exploración del índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
"keyspace": "travel-sample", "limit": "20", "namespace": "default", "offset": "100", "spans": [ { "exact": true, "range": [ { "high": "\"CA\"", "inclusion": 3, "low": "\"CA\"" }, { "high": "\"sao\"", "inclusion": 1, "low": "\"san\"" } ] } ] |
Regla #8: Número de índices
No hay límite artificial en el número de índices que puedes tener en el sistema. Si vas a crear un gran número de índices en un bucket que tiene los datos, utiliza la opción de creación diferida para que la transferencia de datos entre el servicio de datos y el servicio de índices sea eficiente.
Regla #9: Índice durante INSERT, DELETE, UPDATE
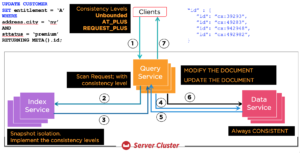
El índice se mantiene de forma asíncrona. Sus actualizaciones de datos a través de la API clave-valor o cualquier sentencia N1QL sólo actualizan los documentos en el bucket. El índice recibe la notificación de los cambios a través del flujo y aplica los cambios al índice. Esta es la secuencia de operaciones para una sentencia UPDATE. La sentencia utiliza el índice para calificar los documentos a actualizar; obtiene los documentos y los actualiza; luego escribe los documentos de vuelta y devuelve cualquier dato solicitado desde la sentencia UPDATE.
Regla #11: ORDEN DE CLAVE DE ÍNDICE Y TIPOS DE PREDICADO
Las peticiones de escaneo del índice creadas por los usuarios de la consulta son las N primeras claves consecutivas del índice. Por tanto, el orden de la clave del índice es importante.
Consideremos una consulta con varios predicados:
|
1 2 3 4 5 |
SELECT cid, address FROM CUSTOMER WHERE state = ‘CA’ AND type = ‘premium’ AND zipcode IN [29482, 29284, 29482, 28472] AND salary < 50000 AND age > 45; |
Se trata de reglas generales para el orden de las claves en el índice. Las claves pueden ser atributos escalares más simples o expresiones que devuelven valores escalares: por ejemplo, UPPER(nombre.apellido).
- La primera prioridad son las claves con predicados de igualdad. En esta consulta, es sobre estado y tipo. Cuando hay varios predicados del mismo tipo, elige cualquier combinación.
- La segunda prioridad son las claves con predicados IN. En esta consulta, se trata del código postal.
- La tercera prioridad es el predicado menor que (<). En este caso, es sobre el salario.
- La cuarta prioridad son los predicados between. Esta consulta no tiene un predicado between.
- La quinta prioridad son los predicados mayor que (>). En esta consulta, es sobre la edad.
- La sexta prioridad son los predicados de array: ANY, o EVERY AND ANY, predicados después de UNNEST.
- Busque añadir campos adicionales para que el índice cubra la consulta.
- Después de hacer este análisis, busque cualquier expresión que se pueda mover a la cláusula WHERE. Por ejemplo, en este caso, type = "premium" se puede mover porque el campo type es designado por los usuarios para identificar el tipo de clientes.
Con esto, llegamos al siguiente índice.
|
1 2 3 4 5 |
CREATE INDEX idx_order ON CUSTOMER ( state, zipcode, salary, age, address, cid ) WHERE type = "premium"; |
Regla #12: Saber leer EXPLAIN y PROFILING
No importa cuántas reglas sigas, tendrás que entender los planes de consulta y el perfil, monitorizar el sistema bajo carga y ajustarlo. La capacidad de comprender y analizar el plan de consulta y la información de perfiles es la clave para ajustar una consulta y una carga de trabajo. Hay dos buenos artículos sobre estos temas. Repásalos y prueba los ejemplos.
- https://dzone.com/articles/understanding-index-scans-in-couchbase-50-n1ql-que
- https://www.couchbase.com/blog/profiling-monitoring-update-2/
Referencias
- Nitro: A Fast, Scalable In-Memory Storage Engine for NoSQL Global Secondary Index: https://vldb2016.persistent.com/industrial_track_papers.php
- Couchbase: https://www.couchbase.com
- Documentación de Couchbase: https://docs.couchbase.com
- N1QL: Guía práctica: https://www.couchbase.com/blog/n1ql-practical-guide-second-edition/
- Asesor de índices: Reglas para la creación de índices: https://www.slideshare.net/journalofinformix/couchbase-n1ql-index-advisor
Hola Keshav,
Soy nuevo en CB, así que disculpen mi falta de comprensión.
Se menciona en este blog
"Así, cuando se hace el escaneo primario, la consulta utilizará el índice para obtener las claves de los documentos y buscará todos los documentos en el bucket y luego aplicará el filtro. Así que esto es MUY CARO".
He leído esto en muchos sitios y es lo mismo que me han dicho, es decir, que hay que evitar un índice primario. No consigo entender por qué. En Oracle o cualquier otro RDBMS, la búsqueda basada en claves primarias/únicas es la más rápida/mejor. Entiendo que si la consulta N1QL no tiene predicado entonces escaneará todo el bucket, es decir, escaneará todas las claves usando el índice primario y eso sería caro. Pero si se especifica la clave en el predicado, ¿no sería lo más rápido?
En el ejemplo 1, la clave específica se menciona en el predicado. Así que debería ser casi tan bueno getid('clave'), ¿no?
Gracias
Hola pccb,
Si tienes la clave del documento (esta es la clave única dentro del bucket), tienes un método de acceso incorporado y es el más eficiente de N1QL.
SELECT * FROM mybucket USE KEYS "cx:482:gn:284";
También puede utilizar el índice primario para esto mediante la emisión:
SELECT * FROM mybucket WHERE meta().id = "cx:482:gn:284";
Puede realizar escaneos de rango inteligentes en meta().id utilizando el índice primario:
SELECT * FROM mybucket WHERE meta().id LIKE "cx:482:gn:%";
Estos son los aspectos que debe tener en cuenta:
1. El bucket de Couchbase puede documentar todos los tipos: cliente, pedido, artículo, etc. Índice primario será a través de todos estos tipos de documentos.
2. Si el desarrollador/usuario construye cuidadosamente la consulta para realizar un escaneo de igualdad o de rango limitado, el uso del índice primario está bien.
3. Pero, si alguien realiza una consulta sin estas directrices o realiza una consulta sin ningún otro índice cualificado en producción, acabamos utilizando el escaneo primario y el escaneo y obtención de todo el índice y todos los documentos del bucket. Típicamente, eso es algo malo en producción.
Hola,
¿Hay alguna forma de evitar un índice, es decir, de hacer que CB NO lo utilice?
Lo que intentamos conseguir es lo siguiente:
Habrá un índice primario para que los desarrolladores puedan probar sus consultas. Sin embargo, una vez que hayan finalizado las consultas, incluido el índice necesario, nos gustaría que las ejecutaran asegurándose de que no están utilizando el índice primario. La razón es que, incluso después de crear el índice secundario adecuado, es posible que la consulta siga utilizando el índice primario y el desarrollador no se haya dado cuenta. Así que si hay una manera de evitar el uso del índice primario, entonces ejecutarían la consulta utilizando esa opción.
Gracias
Gracias por los comentarios. He abierto una mejora para añadir esto: https://issues.couchbase.com/browse/MB-32109
¿Hay algún error tipográfico o me estoy perdiendo algo?
CREAR ÍNDICE travel_sched EN
viaje-muestra(ALL DISTINCT ARRAY v.day FOR v IN schedule END)
¿Es "ALL DISTINCT" una sintaxis válida y qué significa? No la he encontrado en la documentación.
Gracias