OpenShift es una plataforma como servicio (PaaS) de Red Hat basada en contenedores Docker y Kubernetes. Se trata de una plataforma de aplicaciones en contenedores de código abierto de Red Hat basada en contenedores Docker y el gestor de clústeres de contenedores Kubernetes para el desarrollo y la implantación de aplicaciones empresariales.
Couchbase's Operator también es compatible con OpenShift. Ahora, vamos a ver cómo se puede escalar rápidamente hacia arriba y hacia abajo, recuperarse de fallos, o incluso cambiar la arquitectura de su clúster con sólo unos pocos comandos de línea:
Transcripción del vídeo:
Código:
|
1 |
https://github.com/couchbaselabs/kubernetes-starter-kit |
Requisitos previos
Inicio de Minishift
Para iniciar su minishift, sólo tiene que escribir el siguiente comando:
|
1 |
minishift start |
Una vez que se haya iniciado, ejecute el siguiente comando para añadir oc a su Classpath:
|
1 |
eval $(minishift oc-env) |
Además, también puede incluir el siguiente complemento para poder acceder a su clúster como administrador:
|
1 |
minishift addon apply admin-user |
Ahora, para acceder a OpenShift, puede utilizar el siguiente comando:
|
1 |
oc login -u admin |
Configuración de Minishift
Hay algunas cosas que deben ser creadas antes de empezar. Me limitaré a enumerar todos los comandos necesarios, pero puedes consultar la documentación oficial aquí.
1 - Crear un proyecto Openshift
|
1 2 3 |
oc login -u developer oc new-project operator-example oc logout |
2 - Crear una nueva Definición de Recurso Personalizada y Rol de Cluster
|
1 2 3 4 |
oc login -u admin oc create -f https://packages.couchbase.com/kubernetes/0.8.1-beta2/openshift/crd.yaml oc create -f https://packages.couchbase.com/kubernetes/0.8.1-beta2/openshift/cluster-role-sa.yaml oc create -f https://packages.couchbase.com/kubernetes/0.8.1-beta2/openshift/cluster-role-user.yaml |
3- Configuración de RBAC para un proyecto OpenShift
|
1 2 3 4 5 |
oc create serviceaccount couchbase-operator --namespace operator-example oc create rolebinding couchbase-operator --clusterrole couchbase-operator --serviceaccount operator-example:couchbase-operator oc adm policy add-scc-to-user anyuid system:serviceaccount:operator-example:couchbase-operator oc create rolebinding couchbasecluster --clusterrole couchbasecluster --user developer --namespace operator-example oc create clusterrolebinding couchbasecluster --clusterrole couchbasecluster --user developer |
Despliegue del operador de Couchbase en OpenShift
Ahora que hemos configurado todo, vamos a desplegar el Operador de Couchbase. Como he mencionado en un entrada anteriorEl Operador es responsable de automatizar parte del trabajo del DBA, como unir un nuevo nodo al cluster, reequilibrar datos, consolidar logs, etc.
Puede desplegar el operador ejecutando el siguiente comando:
|
1 |
oc create -f https://packages.couchbase.com/kubernetes/0.8.1-beta2/openshift/operator.yaml |
Ejecute el siguiente comando para verificar que su despliegue se ha ejecutado correctamente:
|
1 |
oc get pods: |

Despliegue de Couchbase en OpenShift
Desplegar Couchbase en OpenShift es casi lo mismo que despliegue en Kubernetessólo tienes que ejecutar el siguiente comando dentro del directorio "kubernetes":
|
1 2 |
oc create -f secret.yaml // create the user and password we are going to use to log-in to the web console oc create -f couchbase-cluster.yaml |
Nuestro archivo yaml contiene la especificación del clúster, como el nombre del bucket, el número de servidores, servicios, etc:
secret.yaml
|
1 2 3 4 5 6 7 8 |
apiVersion: v1 kind: Secret metadata: name: cb-example-auth type: Opaque data: username: QWRtaW5pc3RyYXRvcg== #base64 for Administrator password: cGFzc3dvcmQ= #base64 for password |
couchbase-cluster.yaml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
apiVersion: couchbase.database.couchbase.com/v1beta1 kind: CouchbaseCluster metadata: name: cb-example spec: baseImage: couchbase/server version: enterprise-5.0.1 authSecret: cb-example-auth exposeAdminConsole: true cluster: dataServiceMemoryQuota: 256 indexServiceMemoryQuota: 256 searchServiceMemoryQuota: 256 indexStorageSetting: memory_optimized autoFailoverTimeout: 30 buckets: - name: couchbase-sample type: couchbase memoryQuota: 128 replicas: 3 ioPriority: high evictionPolicy: fullEviction conflictResolution: seqno enableFlush: true enableIndexReplica: false servers: - size: 3 name: all_services services: - data - index - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data |
Consulte el documentación oficial para comprender la función de cada propiedad.
En el archivo anterior, hemos especificado que queremos 3 nodos, lo que significa que deberíamos tener 3 nodos ejecutando Couchbase:
|
1 |
oc get pods |

Acceso a su base de datos en OpenShift
Hay muchas maneras de exponer la consola web al mundo externo. En este artículo, vamos a simplemente reenviar el puerto a la máquina local con el siguiente comando:
|
1 |
oc port-forward cb-example-0000 8091:8091 |
Ahora, debería poder acceder a la consola web de Couchbase en su máquina local en https://localhost:8091:
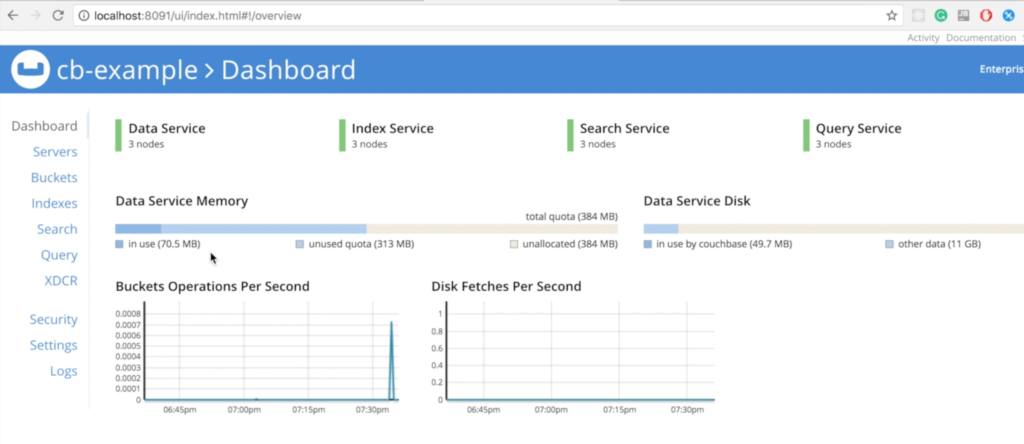
Observa que todos los nodos creados ya forman parte de un cluster. Todo fue hecho automáticamente por el Operador de Couchbase.
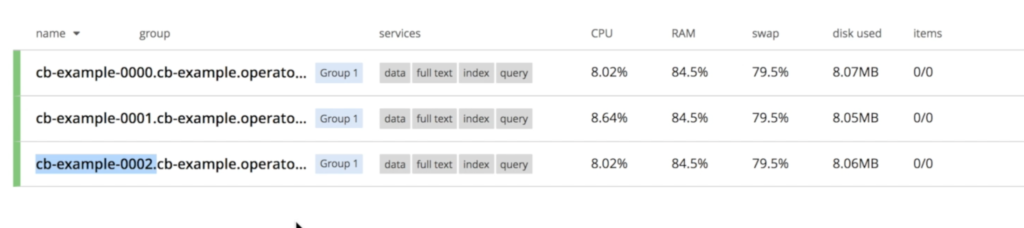
Cómo recuperarse de un fallo de nodo de base de datos en OpenShift
Matemos una de nuestras instancias para ver cómo se comporta el clúster:
|
1 |
oc delete pod cb-example-0001 |

Couchbase se dará cuenta inmediatamente de que un nodo "desapareció" y se iniciará el proceso de recuperación. Como especificamos en couchbase-cluster.yaml que siempre queremos 3 servidores funcionando, Kubernetes iniciará una nueva instancia llamado cb-example-0004:
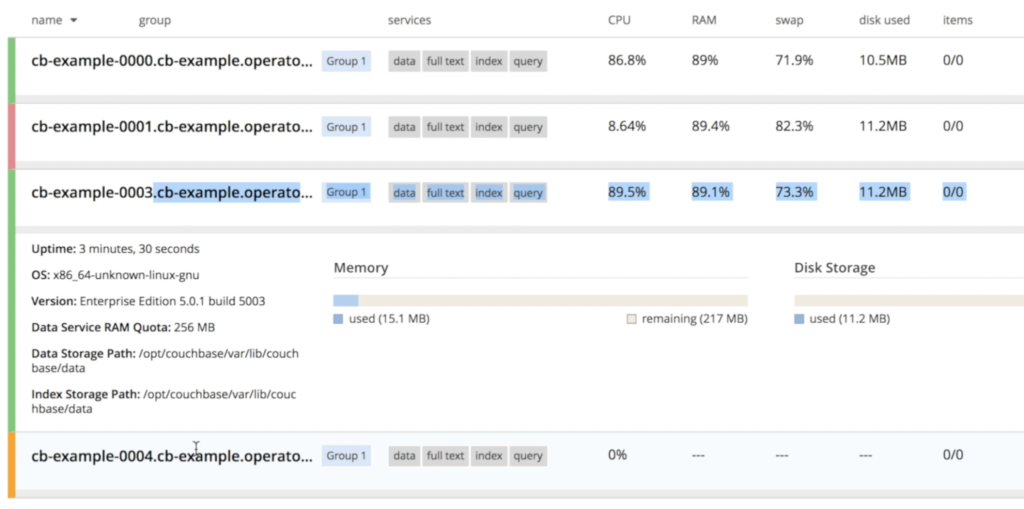
Una vez cb-ejemplo-004 el operador se encarga de unir el nodo recién creado al clúster y, a continuación, activa el reequilibrio de datos.

Reducción de Couchbase en Open Shift
Si crees que escalar una base de datos es difícil, deberías intentar escalarla a la baja. Por suerte, es algo realmente sencillo con Couchbase y OpenShift. Todo lo que necesitas es cambiar la configuración de tu clúster:
couchbase-cluster.yaml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
apiVersion: couchbase.database.couchbase.com/v1beta1 kind: CouchbaseCluster metadata: name: cb-example spec: baseImage: couchbase/server version: enterprise-5.0.1 authSecret: cb-example-auth exposeAdminConsole: true cluster: dataServiceMemoryQuota: 256 indexServiceMemoryQuota: 256 searchServiceMemoryQuota: 256 indexStorageSetting: memory_optimized autoFailoverTimeout: 30 buckets: - name: couchbase-sample type: couchbase memoryQuota: 128 replicas: 3 ioPriority: high evictionPolicy: fullEviction conflictResolution: seqno enableFlush: true enableIndexReplica: false servers: - size: 1 //changed name: all_services services: - data - index - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data |
Y luego ejecute el siguiente comando para empujar su cambio a OpenShift:
|
1 |
oc replace -f couchbase-cluster.yaml |
Sin embargo, aquí hay un pequeño detalle, ya que no podemos matar 2 nodos al mismo tiempo sin correr cierto riesgo de pérdida de datos. Para evitar este problema, el operador reduce el clúster gradualmente, una instancia cada vez, activando el reequilibrio para garantizar que no se pierden datos durante el proceso:

Ampliación de Couchbase en OpenShift
Volvamos a escalarlo a 3 nodos. Como habrás adivinado, todo lo que tenemos que hacer es cambiar la directiva talla parámetro en couchbase-cluster.yaml volver a 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
apiVersion: couchbase.database.couchbase.com/v1beta1 kind: CouchbaseCluster metadata: name: cb-example spec: baseImage: couchbase/server version: enterprise-5.0.1 authSecret: cb-example-auth exposeAdminConsole: true cluster: dataServiceMemoryQuota: 256 indexServiceMemoryQuota: 256 searchServiceMemoryQuota: 256 indexStorageSetting: memory_optimized autoFailoverTimeout: 30 buckets: - name: couchbase-sample type: couchbase memoryQuota: 128 replicas: 3 ioPriority: high evictionPolicy: fullEviction conflictResolution: seqno enableFlush: true enableIndexReplica: false servers: - size: 3 //back to 3 servers name: all_services services: - data - index - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data |
A continuación, actualizamos nuestra configuración ejecutando
|
1 |
oc replace -f Couchbase-cluster.yaml |
Después de unos minutos, verá que ahora tenemos 3 nodos de nuevo:
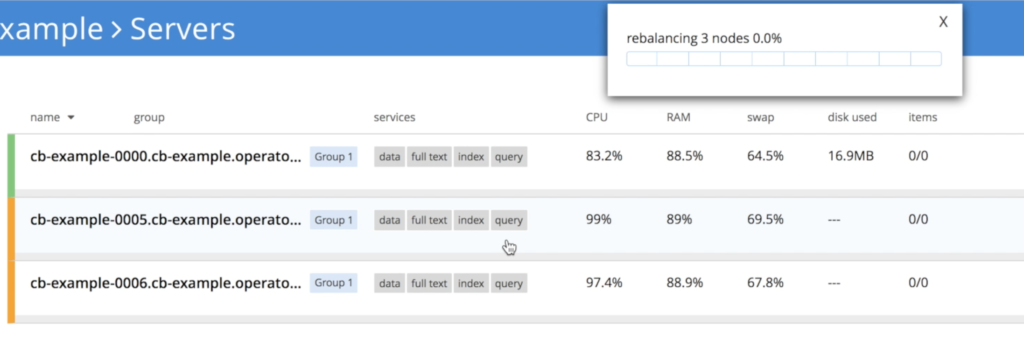
Escala multidimensional
También puede aprovechar el escalado multidimensional especificando los servicios que desea ejecutar en cada nodo:
couchbase-cluster.yaml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
apiVersion: couchbase.database.couchbase.com/v1beta1 kind: CouchbaseCluster metadata: name: cb-example spec: baseImage: couchbase/server version: enterprise-5.0.1 authSecret: cb-example-auth exposeAdminConsole: true cluster: dataServiceMemoryQuota: 256 indexServiceMemoryQuota: 256 searchServiceMemoryQuota: 256 indexStorageSetting: memory_optimized autoFailoverTimeout: 30 buckets: - name: couchbase-sample type: couchbase memoryQuota: 128 replicas: 3 ioPriority: high evictionPolicy: fullEviction conflictResolution: seqno enableFlush: true enableIndexReplica: false servers: - size: 2 name: data_and_index services: - data - index dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data - size: 1 name: query_and_search services: - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data |
Una vez más, tenemos que empujar nuestros cambios a OpenShift con el siguiente comando:
|
1 |
oc replace -f couchbase-cluster.yaml |

En este caso, se crearán tres nuevos nodos: dos de datos e índice y uno de búsqueda y consulta de texto completo.

Conectando su aplicación a Couchbase en OpenShift
Desplegar una aplicación en OpenShift es muy similar a desplegarla en Kubernetes. La principal diferencia es que debe utilizar oc en lugar de utilizar kubectl. Este artículo muestra paso a paso cómo hacerlo.
Si tienes alguna pregunta, envíame un tweet a @deniswsrosa o deje un comentario a continuación.
Lea también:
Un blog muy bien escrito. Es bueno para mostrar cómo escalar hacia arriba / abajo, mostrar la capacidad multidimensional, todo en el mismo blog.
muchas gracias!, si tiene alguna pregunta, no dude en preguntar.
Hola Denis
Gracias por este artículo, parece fantástico, pero parece que el enlace ya no funciona es decir https://packages.couchbase.com/kubernetes/0.8.1-beta2/openshift/crd.yaml
¿Puede indicarme dónde viven ahora?
Muchas gracias, Adrian