Couchbase es una plataforma de datos empresariales que permite el rendimiento a escala mediante la combinación de una arquitectura única que prioriza la memoria con N1QL -que combina la agilidad de SQL con la potencia de JSON-, entre otras funciones integradas como la búsqueda de texto completo, los eventos, el análisis y la indexación secundaria global.
Las empresas que tienen como objetivo proporcionar una experiencia de usuario moderna, fiable y personalizada en toda su oferta tecnológica suelen aprovisionar varios clústeres de nodos Couchbase. Estos diferentes clusters ofrecen el mismo rendimiento a escala en diferentes verticales, casos de uso y sistemas de misión crítica, además de simplemente tener clusters adicionales que sirven como mecanismos de recuperación de desastres/backup. Aunque la intuitiva interfaz de usuario de Couchbase permite una gestión sencilla y sin problemas de los clústeres y los buckets de datos -al ofrecer varias funcionalidades de un solo clic para las distintas tareas de mantenimiento y administración (es decir, reequilibrar, añadir un nodo, conmutación por error, etc)-, cada vez es más importante tener una visión holística de todo el ecosistema de Couchbase. Esto es especialmente cierto en los casos en que una organización determinada despliega varios clústeres para la geolocalización de los datos o para dar soporte a varios microservicios que abarcan diferentes segmentos, centros de coste o verticales.
Primeros pasos: Exportación de métricas de rendimiento
Utilizando Exportador Couchbase (desarrollado por nuestro socio comunitario Laboratorios TOTVS) en combinación con Prometeoy GrafanaAhora es posible exportar las principales métricas de rendimiento de uno o más clústeres y visualizar sus diversos aspectos de rendimiento a través de un panel gráfico. La siguiente captura ilustra un ejemplo de panel de control para 2 clústeres de Couchbase:
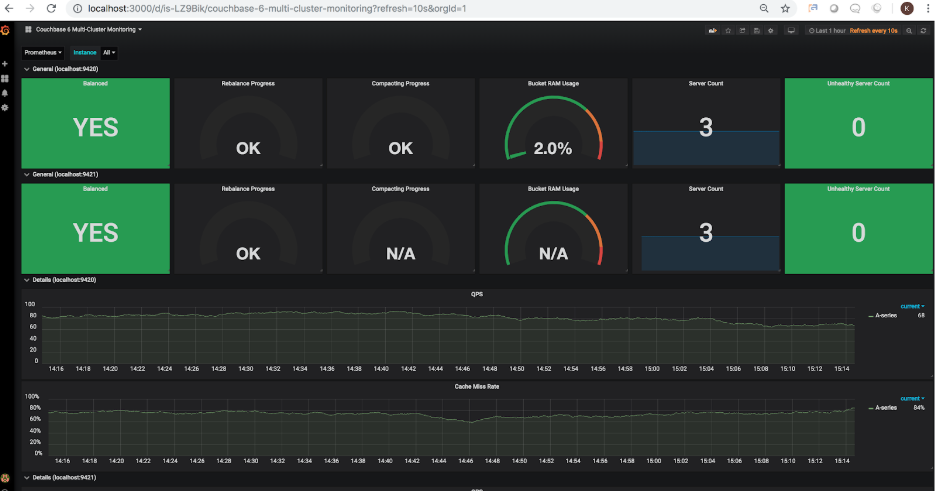
A continuación encontrará instrucciones detalladas sobre cómo instalar y configurar Couchbase Exporter, Prometheus y Grafana:
En primer lugar, empecemos por instalar los componentes de código abierto necesarios para que todo esto funcione.
Exportador Couchbase
Instale Couchbase Exporter clonando el repositorio de GitHub https://github.com/totvslabs/couchbase-exporter y construyendo desde el código fuente, o descargando el binario de la última versión desde https://github.com/totvslabs/couchbase-exporter/releases - Una vez instalado, es necesario ejecutar un proceso Couchbase Exporter independiente para cada clúster de Couchbase Server que se desee monitorizar, utilizando la siguiente sintaxis:
|
1 |
./couchbase-exporter --couchbase.username Administrator --couchbase.password password --web.listen-address=":9420" --couchbase.url="https://52.38.xx.xx:8091" |
Por defecto, Couchbase Exporter se ejecutará en el puerto 9420 e intentará conectarse al servidor Couchbase Server ejecutándose en https://localhost:8091, sin embargo, para la mayoría de los usuarios, es mejor especificar un número de puerto libre así como el Cluster de Couchbase en cuestión explícitamente (la dirección IP de cualquier nodo de un cluster existente será suficiente). Para los propósitos de este tutorial, ejecutaré 2 instancias de Couchbase Exporter contra 2 clusters AWS EC2 Demo localizados en el momento de escribir este artículo en 52.38.xx.xx y 52.40.xx.xx. La segunda instancia de Couchbase Exporter se inicia usando lo siguiente:
|
1 |
$ ./couchbase-exporter --couchbase.username Administrator --couchbase.password password --web.listen-address=":9421" --couchbase.url="https://52.40.xx.xx:8091" |
Aquí están las capturas de pantalla de la ejecución de estas 2 instancias Couchbase Exportador. Nota estas instancias se ejecutan ahora en https://localhost:9420 y https://localhost:9421, respectivamente. Estas 2 URL se utilizarán más adelante para configurar Prometheus.


Prometeo
Instale Prometheus con el método de instalación de su elección siguiendo los pasos descritos en https://prometheus.io/docs/prometheus/latest/installation/ - Una vez instalado, ahora puede editar el archivo prometheus.yml que está disponible en el mismo directorio que el binario de Prometheus. Este archivo YAML necesita ser modificado para especificar los objetivos de Couchbase Exporter que fueron configurados en el paso 1. En este ejemplo, modificaremos la sección scrape_configs del archivo YAML como sigue:
|
1 2 3 4 5 6 7 8 9 |
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'couchbase' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9420', 'localhost:9421'] |
Una vez modificada la sección scrape_configs para que apunte a las instancias de Couchbase Exporter, ya podemos iniciar Prometheus de la siguiente forma:
|
1 |
$. /prometheus --config.file=prometheus.yml |
Ahora Prometheus debe ser iniciado y accesible a través del puerto 9090 (es decir. https://localhost:9090)
Grafana
Instale Grafana con el método de instalación de su elección siguiendo los pasos descritos en https://docs.grafana.org/installation/ - Una vez instalado, debería poder iniciar Grafana (es decir $ sudo service grafana-server start ) y acceder a él por el puerto 3000 (es decir https://localhost:3000) - El nombre de usuario y la contraseña por defecto son admin/adminSin embargo, se recomienda encarecidamente establecer estas credenciales de acuerdo con la política de seguridad de su organización.
Ahora que Grafana ha sido instalado e iniciado, vamos a añadir y configurar la fuente de datos Prometheus de la siguiente manera:
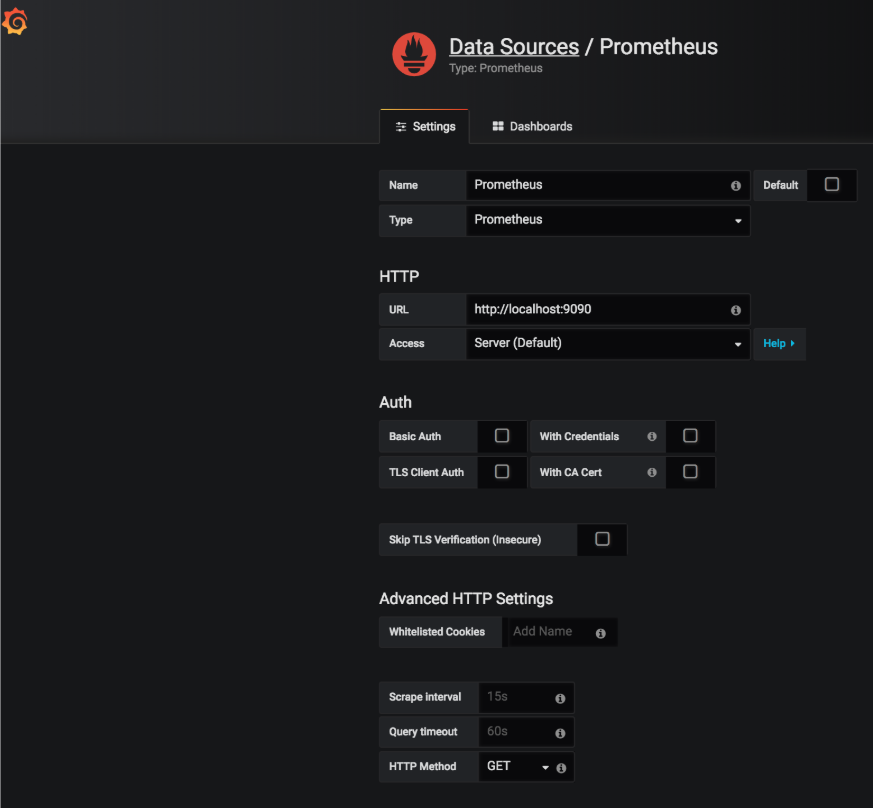
Visualización de las métricas de rendimiento:
Ahora que Couchbase Exporter, Prometheus, y Grafana han sido correctamente instalados y configurados, procederemos a importar un ejemplo de dashboard de Grafana usando este ejemplo JSON. Este es un ejemplo de panel de control con fines ilustrativos y no constituye una recomendación sobre qué métricas monitorizar para su caso de uso particular. Es probable que su organización necesite un panel de control personalizado con métricas específicas de Couchbase relevantes para su caso de uso individual y, por lo tanto, este ejemplo no se ajusta necesariamente a ese propósito particular.
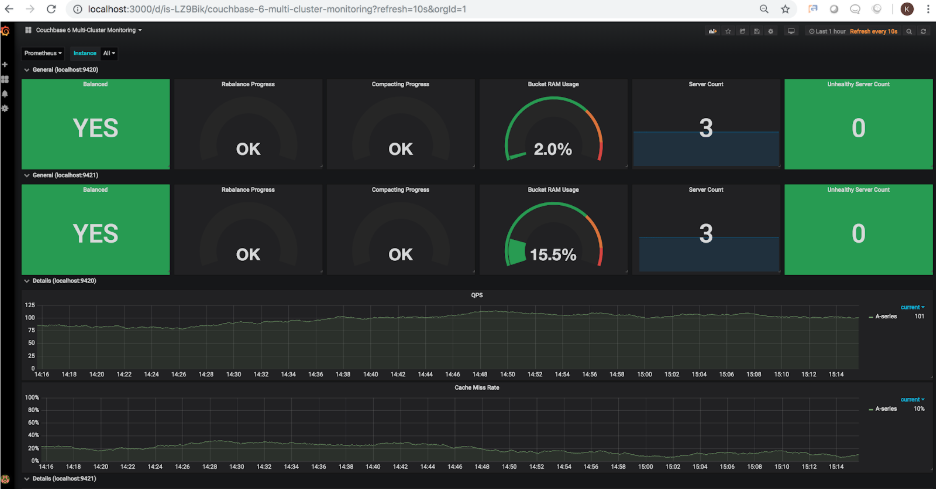
Una vez importado el dashboard, deberías poder cargarlo en Grafana. La siguiente captura de pantalla muestra el estado de los 2 clústeres configurados en el paso 1.
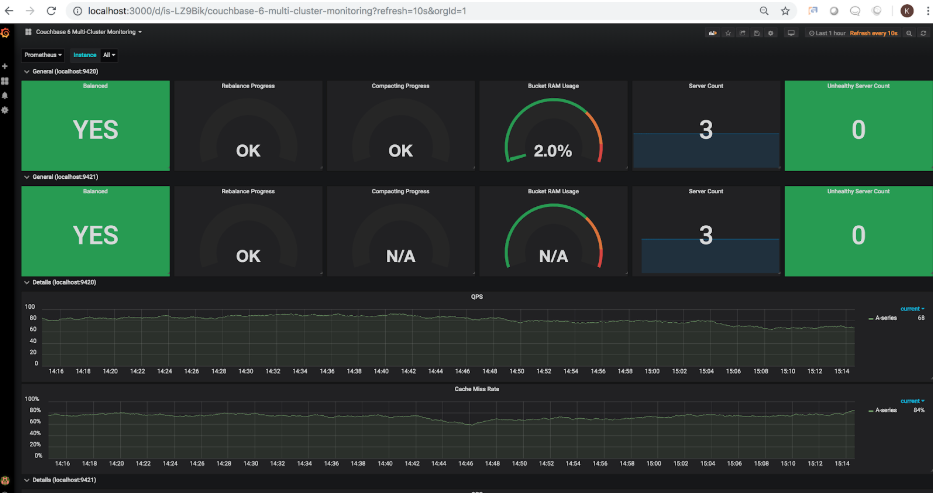
Puede que haya notado que el uso de RAM del segundo cluster muestra N/A. Esto refleja correctamente el hecho de que el segundo cluster no tiene ningún cubo en este momento. Sigamos adelante y añadamos cubos de muestra a ese cluster. Una vez añadidos, el panel de control se actualiza para mostrar el uso actualizado de RAM en 15.5% (este porcentaje variará en función de la RAM asignada al cluster):
Cada cluster fue configurado inicialmente para tener 3 nodos. Vamos a añadir un cuarto nodo al segundo cluster. Una vez añadido un nodo, el panel de control actualizado mostrará lo siguiente:
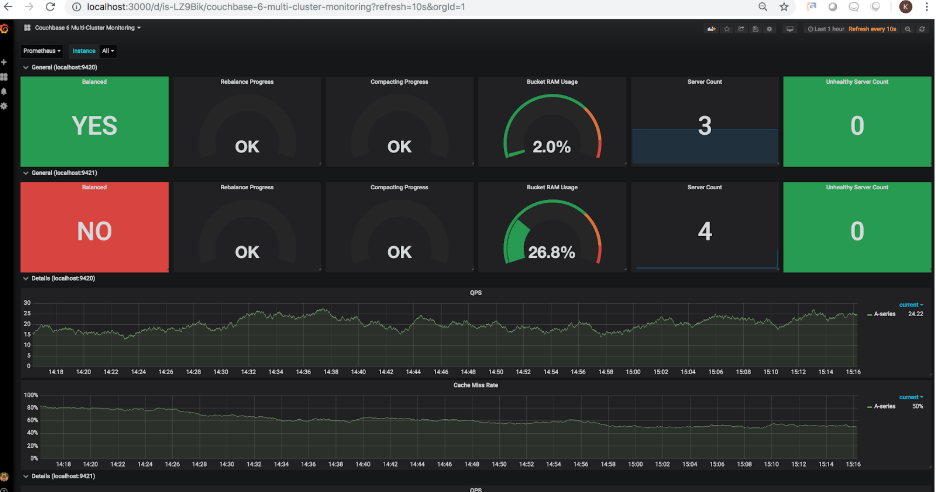
Desde que se añadió el 4º nodo, y no se ha reequilibrado el cluster, el servidor El recuento se ha actualizado para mostrar 4 nodos en total, sin embargo, el estado de reequilibrio es mostrando correctamente que el reequilibrio no se ha completado. Sigamos adelante y lancemos un reequilibrio. Una vez que se activa el reequilibrio a través de la interfaz de usuario de Couchbase, el reequilibrio se actualiza. salpicadero mostrará lo siguiente:
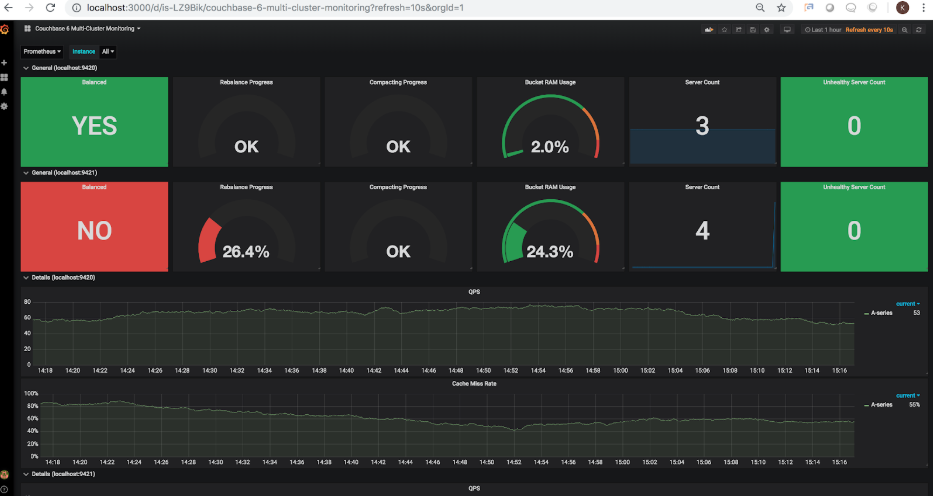
Como puede ver, el indicador de reequilibrio muestra ahora un progreso de 26,4%. Una vez que el Cuando se haya completado el reequilibrio, el panel actualizado mostrará lo siguiente:
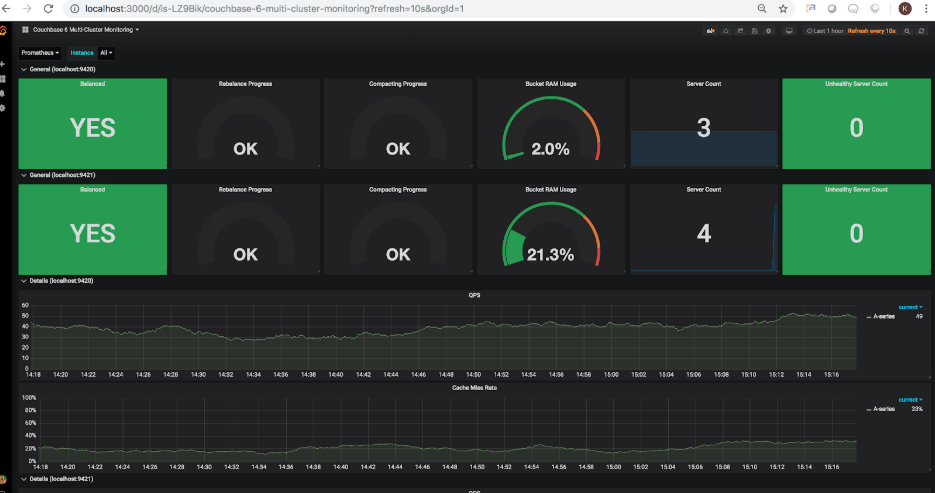
El reequilibrio se ha completado, y ahora puede observar que el uso de RAM del cubo muestra 21.3%, para reflejar la capacidad del nodo adicional que se añade al clúster, reduciendo así el uso total real de los 3 cubos de muestras.
Recapitulemos:
En este blog, hemos instalado Prometheus, Grafana y Couchbase Exporter para monitorizar múltiples clusters de Couchbase. El panel de control de Grafana permite monitorizar visualmente las métricas clave y los indicadores de rendimiento de los clústeres de Couchbase Server en un lugar central. Además, Prometheus permite la configuración de reglas de alerta que enviarían notificaciones a un usuario o lista de correo sobre ciertas condiciones para cuando una métrica determinada cae o supera un determinado umbral.
A continuación figuran los recursos utilizados a lo largo de este blog:
- Fuente de Couchbase Exporter
- Binarios del exportador Couchbase
- Prometeo
- Grafana
- Ejemplo de reglas Couchbase para Prometheus
Gran artículo, ¡gracias!
También escribí un exportador para Couchbase que creo que puede ser de tu interés. Extrae todas las métricas de la API de Couchbase, incluso XDCR y he añadido ejemplos de configuración de Prometheus y Grafana.
El exportador aún necesita algunas mejoras menores, pero ya está listo para usar:
https://github.com/leansys-team/couchbase_exporter
Y la versión Docker:
https://hub.docker.com/r/blakelead/couchbase-exporter
Por favor, compruébelo, creo que vale la pena su tiempo (y el mío, me encantaría recibir comentarios :))
Gran artículo para iniciarse en la monitorización con Prometheus. Gracias por compartirlo.
Este artículo cubrió la parte de integración muy bien, pero se perdió mucho en la escalabilidad, alta disponibilidad, recuperación de fallos, personalizaciones y alcance de la automatización de esta integración, que son aspectos importantes de la creación de soluciones de herramientas de monitoreo.
Que hemos tratado de discutir todos ellos en el siguiente artículo undermentioned.
https://medium.com/@ashishrana160796/dissecting-the-couchbase-monitoring-integration-with-prometheus-and-grafana-55f7d460f37
Por favor, échele un vistazo. Espero que merezca la pena. Además, me encantaría recibir comentarios sobre las soluciones desarrolladas.
#automatización #couchbase #prometheus #grafana #upervisión #alerting #escalabilidad #opensourcedesarrollo
Enlace actualizado para el artículo y nuestro análisis de esta herramienta de integración: https://hackernoon.com/dissecting-the-couchbase-monitoring-integration-with-prometheus-and-grafana-ge1v6263t
El relé del artículo ayuda a obtener más detalles sobre lo que ocurre en el clúster.
He configurado esto en mi cluster. Tenemos un cluster de 3 nodos
1 (Índice) Nodo
2 (Datos, Consulta y Búsqueda) Nodo.
¿Qué métricas debo comprobar por nodo y qué métricas deben comprobarse en todo el clúster?