Si eres un desarrollador que Si eres nuevo en Couchbase, este artículo te ayudará a empezar.
Esta serie de tutoriales semanales le ayudará a comprender los conceptos básicos de la conexión a Couchbase, le mostrará cómo recuperar y modificar datos en Couchbase Server, cómo utilizar el lenguaje de consulta SQL (antes conocido como N1QL) y más. Esta semana, el código de ejemplo será Java, y usaremos Couchbase Java SDK.
Couchbase es un distribuido, Base de datos de documentos JSON. Expone un almacén de valores clave escalable con caché gestionada para operaciones de datos en submilisegundos, indexadores específicos para consultas eficientes y un potente motor de consulta para ejecutar consultas de tipo SQL.
En este tutorial para desarrolladores, veremos las características básicas de Couchbase, tanto a través de una interfaz JSON no relacional como de una interfaz SQL relacional. Couchbase viene con una base de datos de ejemplo, viaje-muestray utilizaremos este conjunto de datos de muestra para aprender los fundamentos de Couchbase utilizando el SDK de Java.
Comprender el conjunto de datos de muestras de viajes
Para comprender mejor lo que la viaje-muestra de datos, siéntase libre de lea sobre ello en la documentación del SDK de Java: Modelo de datos de la aplicación de viajes.
A continuación se muestra un diagrama entidad-relación de la aplicación viaje-muestra junto con un modelo de datos adjunto:
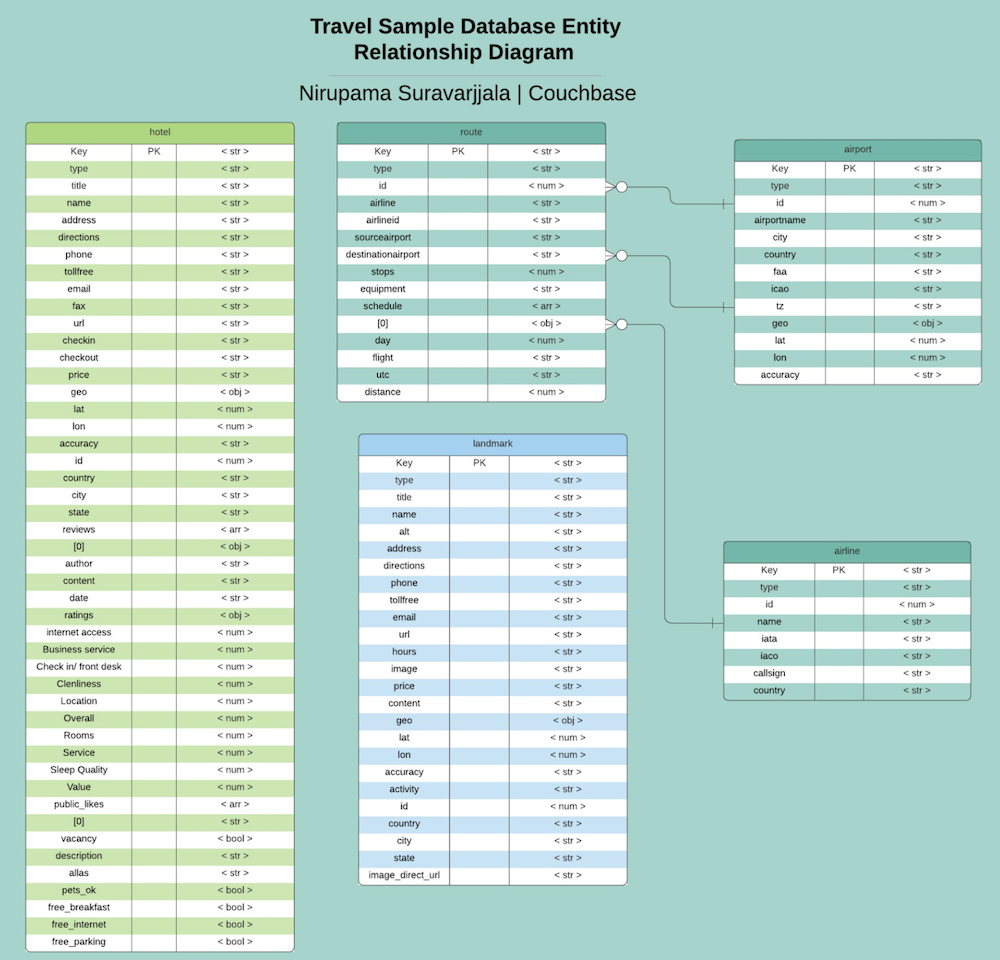

Cómo utilizar la función Get clave-valor para recuperar datos
Clave-valor (también conocido como Couchbase Data Service) ofrece la forma más sencilla de recuperar o mutar datos cuando se conoce la clave. Un almacén de clave-valor es un tipo de Base de datos NoSQL que utiliza un método sencillo para almacenar datos como una colección de pares clave-valor en la que una clave sirve de identificador único.
Servidor Couchbase es un almacén clave-valor que es agnóstico a lo que se almacena. El siguiente ejemplo muestra cómo utilizar el almacén clave-valor consiga para recuperar datos de un backend.
Antes de continuar, asegúrate de que estás familiarizado con los conceptos básicos de autorización y conexión a un clúster Couchbase. Lea la sección "Empezar a utilizar el SDK de Java" de la documentación de Couchbase. si necesitas ponerte al día.
A continuación se indican las tres importaciones que necesita:
|
1 2 3 |
import com.couchbase.client.core.error.DocumentNotFoundException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; |
A continuación, conéctate al cluster que almacena los datos que quieres recuperar. Como estás usando Java, primero asegúrate de declarar una clase y un método principal. A continuación, crea una variable para tu clúster.
En el ejemplo siguiente, grupo es el nombre de la variable de tipo var. Usando una cadena de conexión, haz que tu programa se conecte con los datos del backend. Una cadena de conexión Couchbase es una lista delimitada por comas de direcciones IP y/o nombres de host, opcionalmente seguida de una lista de parámetros. Abajo, couchbase://127.0.0.1 es una simple cadena de conexión con un nodo semilla seguido de un nombre de usuario y una contraseña. Asegúrate de sustituir toda esta información por la relativa a tu programa.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
Una conexión a un cluster de Couchbase Server está representada por un objeto cluster. Un clúster proporciona acceso a los buckets, ámbitos y coleccionesasí como diversos servicios e interfaces de gestión de Couchbase.
Después de proporcionar la cadena de conexión, el nombre de usuario y la contraseña anteriores, estás conectado a un clúster de Couchbase y ahora puedes conectarte a un bucket y una colección de Couchbase:
|
1 2 |
var bucket = cluster.bucket("travel-sample"); var collection = bucket.defaultCollection(); |
El Java consiga le permite recuperar un determinado dato. Dada la clave de un documento, puede utilizar el método colección.get() para recuperar un documento de una colección.
En este ejemplo, se recupera el contenido de la colección denominada "aerolínea_10" en la base de datos. A continuación, para ver el resultado, hay un imprimir que le permite terminar de recuperar los datos.
|
1 2 3 4 |
try { var result = collection.get("airline_10"); System.out.println(result.toString()); } |
Por último, por si acaso el usuario intenta recuperar una información que no existe o no se encuentra dentro de los límites del documento, existe una función captura para asegurarse de que no hay errores en el código.
|
1 2 3 4 5 |
catch (DocumentNotFoundException ex) { System.out.println("Document not found!"); } } } |
Utilizar el método de consulta para recuperar datos
Una consulta se realiza siempre a nivel de cluster, concretamente utilizando la función consulta método. Este método toma la declaración como argumento obligatorio y luego le permite proporcionar opciones adicionales si es necesario.
Una vez que se obtiene un resultado, puede iterar sobre las filas devueltas y/o acceder a la función QueryMetaData asociado a la consulta. Si algo va mal durante la ejecución de la consulta, una derivada de la CouchbaseException que también proporciona contexto adicional sobre la operación.
A continuación figuran las cinco importaciones que necesita:
|
1 2 3 4 5 |
import com.couchbase.client.core.error.DocumentNotFoundException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; import com.couchbase.client.java.json.JsonObject; import com.couchbase.client.java.query.QueryResult; |
A continuación, conéctese al clúster que almacena los datos que desea recuperar, siguiendo pasos similares a los anteriores. Asegúrate de sustituir toda esta información por la relativa a tu programa.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
Como antes, estás conectado a un cluster de Couchbase y ahora puedes conectarte a un bucket de Couchbase:
|
1 |
var bucket = cluster.bucket("travel-sample"); |
Este es un ejemplo de cómo realizar una consulta y manejar los resultados. El resultado que se imprime es "Hotel: " seguido del nombre, la ciudad, el estado y otra información específica del hotel. Sólo se imprimirán hasta cinco filas, ya que ése es el límite numérico representado en el código. Para probar diferentes consultas, pruebe a cambiar el nombre de la ciudad en la línea seis por cualquier otra ciudad.
|
1 2 3 4 5 6 7 8 9 10 11 |
try { var query = "SELECT h.name, h.city, h.state " + "FROM `travel-sample` h " + "WHERE h.type = 'hotel' " + "AND h.city = 'Malibu' LIMIT 5;"; QueryResult result = cluster.query(query); for (JsonObject row : result.rowsAsObject()) { System.out.println("Hotel: " + row); } |
Como antes, el captura asegura que no hay errores en su código. Por ejemplo, si eliges una ciudad que tu base de datos no tiene, esto DocumentNotFoundException la excepción imprimirá "¡Documento no encontrado!".
|
1 2 3 4 5 |
} catch (DocumentNotFoundException ex) { System.out.println("Document not found!"); } } } |
Cómo consultar con parámetros con nombre
Como se ha mencionado anteriormente, los métodos de consulta permiten buscar información específica en una base de datos en función de determinados criterios. Los métodos de consulta pueden tener parámetros nominales o posicionales.
En esta sección, repasaremos qué son los parámetros con nombre y cómo resultan útiles cuando se invocan métodos con un gran número de parámetros. Los parámetros con nombre indican claramente el nombre del parámetro al invocar un método. Permiten a los usuarios invocar el método con un subconjunto aleatorio de ellos, utilizando valores por defecto para el resto de los parámetros.
A continuación figuran las siete importaciones que necesita:
|
1 2 3 4 5 6 7 |
import com.couchbase.client.core.error.CouchbaseException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; import com.couchbase.client.java.json.JsonObject; import com.couchbase.client.java.query.QueryResult; import com.couchbase.client.java.query.QueryOptions; import static com.couchbase.client.java.query.QueryOptions.queryOptions; |
A continuación, conéctese al clúster que almacena los datos que desea recuperar, siguiendo pasos similares a los anteriores. Asegúrate de sustituir toda esta información por la relativa a tu programa.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
Como antes, estás conectado a un cluster de Couchbase y ahora puedes conectarte a un bucket de Couchbase:
|
1 |
var bucket = cluster.bucket("travel-sample"); |
El código procede a acceder al viaje-muestra y, en concreto, los buckets de nombre, ciudad y estado. La dirección queryOptions() permite personalizar varias opciones de consulta SQL++.
En el código siguiente, el resultado devuelve datos de tipos: hotel y ciudad: Malibú. Como el límite es cinco, sólo se imprimen hasta cinco filas. El resultado que se imprime es "Hotel: " seguido de información como el nombre y la ciudad.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
try { var query = "SELECT h.name, h.city, h.state " + "FROM `travel-sample` h " + "WHERE h.type = $type " + "AND h.city = $city LIMIT 5;"; QueryResult result = cluster.query(query, queryOptions().parameters( JsonObject.create() .put("type", "hotel") .put("city", "Malibu") )); |
El resultado se extrae del viaje-muestra base de datos, concretamente de las filas. La dirección .stream se utiliza para calcular los elementos según el método primario sin cambiar el valor original del objeto JSON.
|
1 2 3 4 |
result.rowsAsObject().stream().forEach( e-> System.out.println( "Hotel: " + e.getString("name") + ", " + e.getString("city")) ); |
Como antes, el captura asegura que no hay errores en su código. Por ejemplo, si elige una ciudad o un tipo de lugar que nuestra base de datos no tiene, esto CouchbaseException la excepción imprimirá "Excepción: " junto con la representación en cadena del objeto que está causando el error.
|
1 2 3 4 5 |
} catch (CouchbaseException ex) { System.out.println("Exception: " + ex.toString()); } } } |
Cómo consultar con parámetros posicionales
Como se mencionó anteriormente, los métodos de consulta pueden tener parámetros de nombre o de posición. Ya hemos hablado de los parámetros con nombre.
En esta sección, repasaremos los parámetros posicionales y su utilidad cuando se llaman métodos con un gran número de parámetros. Los parámetros posicionales permiten sustituir el orden de los parámetros del método por marcadores de posición.
Por ejemplo, el primer marcador de posición se sustituye por el primer parámetro del método, el segundo marcador de posición se sustituye por el segundo parámetro del método, etc.
A continuación figuran las siete importaciones que necesita:
|
1 2 3 4 5 6 7 |
import com.couchbase.client.core.error.CouchbaseException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; import com.couchbase.client.java.json.JsonArray; import com.couchbase.client.java.query.QueryResult; import com.couchbase.client.java.query.QueryOptions; import static com.couchbase.client.java.query.QueryOptions.queryOptions; |
A continuación, conéctese al clúster que almacena los datos que desea recuperar, siguiendo pasos similares a los anteriores. Asegúrate de sustituir toda esta información por la relativa a tu programa.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
Como antes, estás conectado a un cluster de Couchbase y ahora puedes conectarte a un bucket de Couchbase:
|
1 |
var bucket = cluster.bucket("travel-sample"); |
La siguiente consulta busca el nombre, la ciudad y el estado a partir del viaje-muestra base de datos teniendo en cuenta específicamente el tipo de lugar y la ciudad. Posteriormente, se revelan como hoteles en Malibú.
|
1 2 3 4 5 6 7 8 9 |
try { var query = "SELECT h.name, h.city, h.state " + "FROM `travel-sample` h " + "WHERE h.type = $1 " + "AND h.city = $2 LIMIT 5;"; QueryResult result = cluster.query(query, queryOptions().parameters(JsonArray.from("hotel", "Malibu")) ); |
Al igual que en el ejemplo anterior de los parámetros con nombre, los parámetros .stream se utiliza para calcular los elementos según el método primario sin cambiar el valor original del objeto JSON.
|
1 2 3 4 |
result.rowsAsObject().stream().forEach( e-> System.out.println( "Hotel: " + e.getString("name") + ", " + e.getString("city")) ); |
Cómo utilizar las operaciones de búsqueda de subdocumentos
Subdocumentos son partes del documento JSON que puedes actualizar y recuperar de forma atómica y eficiente.
Mientras que las recuperaciones de documentos completos recuperan el documento completo y las actualizaciones de documentos completos requieren el envío del documento completo, las recuperaciones de subdocumentos sólo recuperan las partes relevantes de un documento y las actualizaciones de subdocumentos sólo requieren el envío de las partes actualizadas de un documento. Debes utilizar operaciones de subdocumento siempre que vayas a modificar sólo partes de un documento, y operaciones de documento completo sólo cuando el contenido de un documento vaya a cambiar significativamente.
Las operaciones de subdocumento descritas en este artículo son para sólo solicitudes clave-valorno están relacionadas con las consultas SQL++ de subdocumentos. Para utilizar las operaciones de subdocumento es necesario especificar una ruta que indique la ubicación del subdocumento.
En buscarEn consulta el documento en busca de una(s) ruta(s) determinada(s) y devuelve dicha(s) ruta(s). Tiene la opción de recuperar la ruta del documento utilizando la función subdoc consiga o simplemente consultando la existencia de la ruta mediante la función existe subdoc operación de subdocumento. Esta última ahorra aún más ancho de banda al no recuperar el contenido de la ruta si no es necesario.
A continuación figuran las cinco importaciones que necesita:
|
1 2 3 4 5 |
import com.couchbase.client.core.error.DocumentNotFoundException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.LookupInResult; import static com.couchbase.client.java.kv.LookupInSpec.get; import java.util.Collections; |
A continuación, conéctese al clúster que almacena los datos que desea recuperar, siguiendo pasos similares a los anteriores. Asegúrate de sustituir toda esta información por la relativa a tu programa.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
Como antes, estás conectado a un cluster de Couchbase y ahora puedes conectarte a un bucket de Couchbase:
|
1 2 |
var bucket = cluster.bucket("travel-sample"); var collection = bucket.defaultCollection(); |
En el código siguiente, el buscarEnconsulta el aeropuerto_1254 para una ruta determinada, el geo.alt ruta. Este código nos permite recuperar la ruta del documento utilizando la función subdoc get operación de subdocumento: (get("geo.alt")).
|
1 2 3 4 5 6 7 8 |
try { LookupInResult result = collection.lookupIn( "airport_1254", Collections.singletonList(get("geo.alt")) ); var str = result.contentAs(0, String.class); System.out.println("Altitude = " + str); |
Como antes, el captura asegura que no hay errores en su código. Por ejemplo, si elige una ciudad que nuestra base de datos no tiene, esto DocumentNotFoundException la excepción imprimirá "¡Documento no encontrado!".
|
1 2 3 4 5 |
} catch (DocumentNotFoundException ex) { System.out.println("Document not found!"); } } } |
Cómo utilizar las operaciones de mutación de subdocumentos
Las operaciones de mutación de subdocumentos modifican una o varias rutas del documento.
La más sencilla de estas operaciones es subdoc upsert. Al igual que el upsert de nivel fulldoc, el subdoc upsert modifica el valor de una ruta existente o la crea si no existe. Del mismo modo, la operación subdoc insertar sólo añade el nuevo valor a la ruta si no existe.
A continuación figuran las ocho importaciones que necesita:
|
1 2 3 4 5 6 7 8 |
import com.couchbase.client.core.error.subdoc.PathNotFoundException; import com.couchbase.client.core.error.subdoc.PathExistsException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.LookupInResult; import static com.couchbase.client.java.kv.LookupInSpec.get; import static com.couchbase.client.java.kv.MutateInSpec.upsert; import java.util.Collections; import java.util.Arrays; |
A continuación, conéctese al clúster que almacena los datos que desea recuperar, siguiendo pasos similares a los anteriores. Asegúrate de sustituir toda esta información por la relativa a tu programa.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
Como antes, estás conectado a un cluster de Couchbase y ahora puedes conectarte a un bucket de Couchbase:
|
1 2 |
var bucket = cluster.bucket("travel-sample"); var collection = bucket.defaultCollection(); |
En el código siguiente, el mutateIn se utiliza para modificar el "aerolínea_10" utilizando un upsert a nivel de fulldoc que creará el valor de una ruta existente con parámetros ("país", "Canadá").
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
try { LookupInResult result = collection.lookupIn( "airline_10", Collections.singletonList(get("country")) ); var str = result.contentAs(0, String.class); System.out.println("Sub-doc before: "); System.out.println(str); } catch (PathNotFoundException e) { System.out.println("Sub-doc path not found!"); } try { collection.mutateIn("airline_10", Arrays.asList( upsert("country", "Canada") )); } catch (PathExistsException e) { System.out.println("Sub-doc path exists!"); } try { LookupInResult result = collection.lookupIn( "airline_10", Collections.singletonList(get("country")) ); var str = result.contentAs(0, String.class); System.out.println("Sub-doc after: "); System.out.println(str); |
Como antes, el captura asegura que no hay errores en su código. Por ejemplo, si eliges un documento para el que tu ordenador local no tiene acceso, esta excepción PathNotFoundException la excepción imprimirá "¡No se ha encontrado la ruta del subdocumento!".
|
1 2 3 4 5 6 |
} catch (PathNotFoundException e) { System.out.println("Sub-doc path not found!"); } } } |
Cómo utilizar la función Upsert
La función Upsert se utiliza para insertar un nuevo registro o actualizar uno existente. Si el documento no existe, se creará. Upsert es una combinación de insertar y actualización.
Los usuarios que ejecuten el upsert debe tener los privilegios Query Update y Query Insert en el espacio clave de destino. Si la sentencia tiene cláusulas de retorno, también se requiere el privilegio Query Select en los espacios de claves a los que se hace referencia en las cláusulas respectivas. Para más detalles sobre los roles de usuario, consulte la documentación de Autorización sobre el control de acceso basado en roles (RBAC) en Couchbase.
A continuación se muestra un diagrama de la sintaxis básica para todas las operaciones upsert:

A continuación figuran las nueve importaciones que necesita:
|
1 2 3 4 5 6 7 8 9 |
import com.couchbase.client.core.error.subdoc.PathNotFoundException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; import com.couchbase.client.java.kv.MutationResult; import com.couchbase.client.java.json.JsonObject; import com.couchbase.client.java.kv.LookupInResult; import static com.couchbase.client.java.kv.LookupInSpec.get; import static com.couchbase.client.java.kv.MutateInSpec.upsert; import java.util.Collections; |
A continuación, conéctese al clúster que almacena los datos que desea recuperar, siguiendo pasos similares a los anteriores. Asegúrate de sustituir toda esta información por la relativa a tu programa.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
Como antes, estás conectado a un cluster de Couchbase y ahora puedes conectarte a un bucket de Couchbase:
|
1 2 |
var bucket = cluster.bucket("travel-sample"); var collection = bucket.defaultCollection(); |
En .put permite al usuario insertar una asignación en un mapa. Esto significa que puede insertar una clave específica (y el valor al que se asigna) en un mapa concreto. Si se pasa una clave existente, el valor anterior se sustituye por el nuevo valor.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
JsonObject content = JsonObject.create() .put("country", "Iceland") .put("callsign", "ICEAIR") .put("iata", "FI") .put("icao", "ICE") .put("id", 123) .put("name", "Icelandair") .put("type", "airline"); collection.upsert("airline_123", content); try { LookupInResult lookupResult = collection.lookupIn( "airline_123", Collections.singletonList(get("name")) ); var str = lookupResult.contentAs(0, String.class); System.out.println("New Document name = " + str); |
Como antes, el captura asegura que no hay errores en su código. Por ejemplo, si eliges un documento para el que tu ordenador local no tiene acceso, esta excepción PathNotFoundException la excepción imprimirá "¡Documento no encontrado!".
|
1 2 3 4 5 6 |
} catch (PathNotFoundException ex) { System.out.println("Document not found!"); } } } |
Conclusión
Espero que este tutorial introductorio te haya ayudado a entender - y ejecutar - algunas de las funciones más comunes cuando se trabaja con Couchbase y el SDK de Java. Para sumergirte en pasos intermedios y avanzados, consulte la documentación del SDK de Java aquí.
Si necesitas ayuda o necesitas algo de inspiración, consulte los foros de Couchbase y conectar con desarrolladores afines de la comunidad.
Como siguiente paso, te animo a que consultes la guía gratuita en línea Curso de certificación Couchbase Associate Java Developer ofrecido por Academia Couchbase.
Empiece a utilizar Couchbase 7 hoy mismo
