Nos complace anunciar el lanzamiento de Couchbase Autonomous Operator 1.2. Se trata de una versión histórica que incluye varias características solicitadas por los clientes, principalmente
- Actualización automatizada de clusters Couchbase
- Validación integrada de recursos CouchbaseCluster a través de Adminission Controller
- Soporte de timón
- Conectividad pública para clientes Couchbase
- Actualización continua de clústeres Kubernetes
- Rotación de certificados TLS x509
- Experiencia unificada de recopilación de registros para implantaciones con y sin estado
-
Soporte para Servicios Públicos de Kubernetes en GKE, AKS y EKS. Kubernetes funcionando en la nube pública ya estaba funcionando desde el día 1, pero con Autonomous Operator 1.2, lo estamos soportando de manera oficial. Desde la perspectiva de este blog, utilizaremos GKE para configurar el clúster de Kubernetes en GKE con la versión 1.12, luego desplegaremos Autonomous Operator y finalmente desplegaremos Couchbase Cluster con Server Groups, con volúmenes persistentes y con certificados x509 TLS.
Los pasos generales que daremos en este blog son los siguientes:
-
Inicializar gcloud utils
-
Despliegue un clúster kubernetes (v1.12+) con 2 nodos en cada zona de disponibilidad
-
Despliegue del Operador Autónomo 1.2
-
Despliegue del clúster Couchbase
-
Realizar Autofailover de Grupo de Servidores
Requisitos previos
- kubectl (gcloud components install kubectl)
- Cuenta GCP con las credenciales correctas
Inicializar gcloud utils
Descargar gcloud sdk para la versión del sistema operativo de su elección de este URL.
Se necesitarían credenciales de google cloud para inicializar el gcloud cli
|
1 2 3 |
cd google-cloud-sdk ./install.sh ./bin/gcloud init |
Despliegue el clúster kubernetes (v1.12) con 2 nodos en cada zona de disponibilidad
El despliegue de clústeres kubernetes en GKE es un trabajo bastante sencillo. Para desplegar clústeres kubernetes resistentes, es buena idea desplegar nodos en todas las zonas disponibles dentro de una región determinada. Hacerlo de tal manera que podamos hacer uso de los grupos de servidores o Zona Rack o Zona de Disponibilidad (AZ) dentro del servidor Couchbase, significa que si perdemos toda AZ, couchbase puede conmutar por error toda AZ y la aplicación estará activa, ya que todavía tiene el conjunto de datos de trabajo.
|
1 |
gcloud container clusters create rd-k8s-gke --region us-east1 --machine-type n1-standard-16 --num-nodes 2 |
|
1 2 3 4 |
Details about above command K8s cluster name : rd-k8s-gke machine-type: n1-standard-16 (16 vCPUs and 60GB RAM) num-nodes/AZ : 2 |
Más tipos de máquinas pueden ser aquí
En este punto, el cluster k8s con el número requerido de nodos debería estar en funcionamiento
|
1 2 3 |
$ gcloud container clusters list NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION <strong>NUM_NODES</strong> STATUS rd-k8s-gke us-east1 1.12.6-gke.10 35.229.24.36 n1-standard-16 1.12.6-gke.10 <strong>6</strong> RUNNING |
Los detalles del clúster k8s se encuentran a continuación
|
1 2 3 4 5 6 |
$ kubectl cluster-info Kubernetes master is running at https://55.229.24.36 GLBCDefaultBackend is running at https://55.229.24.36/api/v1/namespaces/kube-system/services/default-http-backend:http/proxy Heapster is running at https://55.229.24.36/api/v1/namespaces/kube-system/services/heapster/proxy KubeDNS is running at https://55.229.24.36/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy Metrics-server is running at https://55.229.24.36/api/v1/namespaces/kube-system/services/https:metrics-server:/proxy |
Despliegue del Operador Autónomo 1.2
GKE soporta RBAC para limitar los permisos. Dado que el Operador Couchbase crea recursos en nuestro clúster GKE, tendremos que concederle el permiso para hacerlo.
|
1 |
$ kubectl create clusterrolebinding cluster-admin-binding --clusterrole cluster-admin --user $(gcloud config get-value account) |
Descargar el paquete adecuado para desplegar kubernetes en su entorno. Descomprima el paquete y despliegue el controlador de admisión.
|
1 |
$ kubectl create -f admission.yaml |
Comprobar el estado del controlador de admisión
|
1 2 3 |
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE couchbase-operator-admission 1 1 1 1 7s |
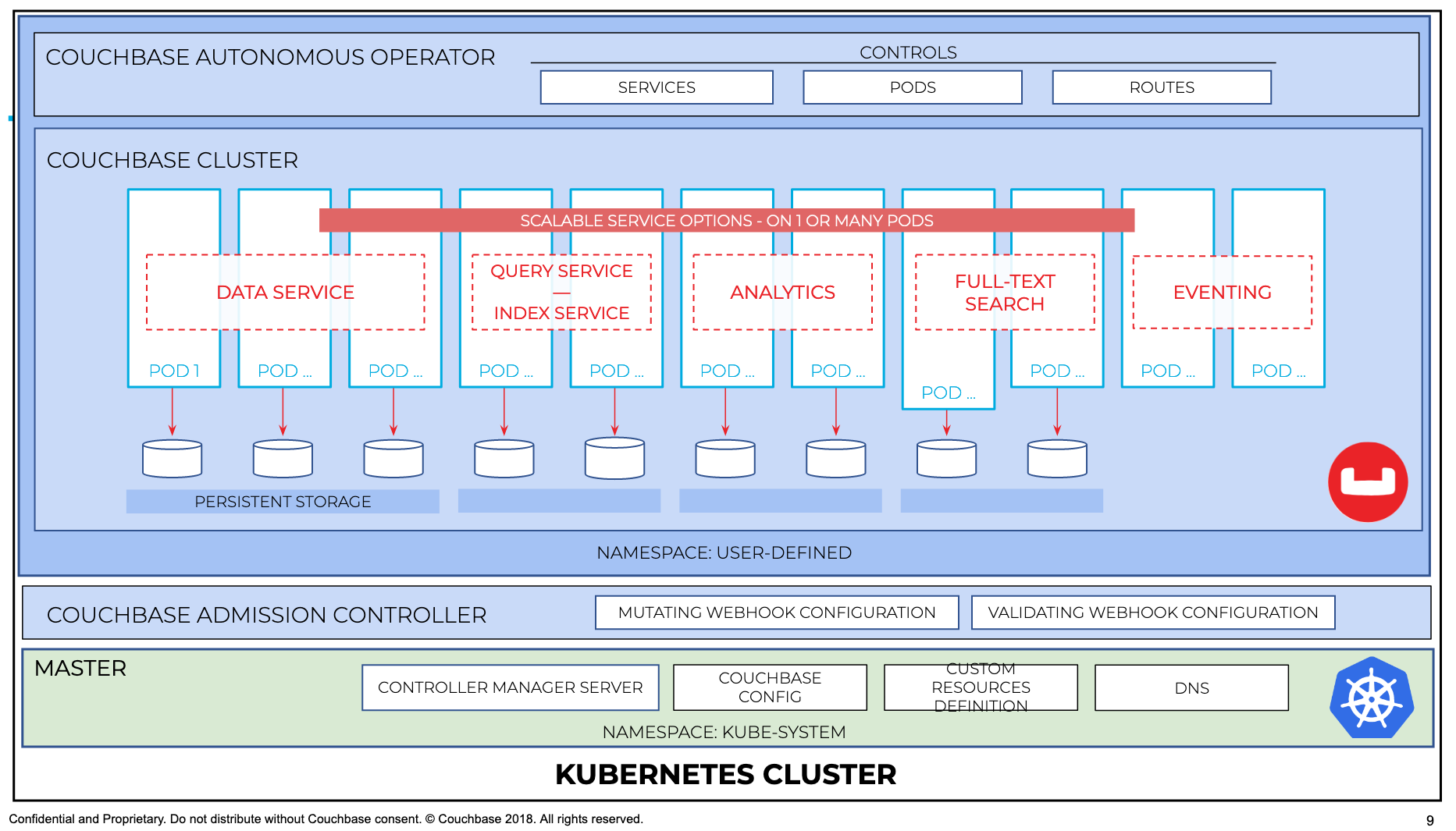
Para visualizar cómo funciona el controlador de admisión en sincronía con el operador y el cluster couchbase, se puede ilustrar mejor con el siguiente diagrama
Los siguientes pasos son crear crd, rol de operador y operador 1.2
|
1 2 3 |
$ kubectl create -f crd.yaml $ kubectl create -f operator-role.yaml $ kubectl create -f operator-deployment.yaml |
Una vez desplegado, el operador está listo y disponible en cuestión de segundos.
|
1 2 3 4 |
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE couchbase-operator-admission 1 1 1 1 11m couchbase-operator 1 1 1 1 25s |
Despliegue del clúster Couchbase
El clúster Couchbase se desplegará con las siguientes características
-
Certificados TLS
-
Grupos de servidores (cada grupo de servidores en una AZ)
-
Volúmenes persistentes (que son conscientes de AZ)
-
Recuperación automática de grupos de servidores
Certificados TLS
Es bastante fácil de generar certificados tls, los pasos detallados se encuentran aquí
Una vez desplegados, los secretos tls se pueden encontrar con el comando kubectl secret de la siguiente manera
|
1 2 3 4 |
$ kubectl get secrets NAME TYPE DATA AGE couchbase-operator-tls Opaque 1 1d couchbase-server-tls Opaque 2 1d |
Grupos de servidores
Configurar grupos de servidores también es sencillo, lo que se discutirá en las siguientes secciones cuando despleguemos el archivo yaml del clúster couchbase.
Volúmenes persistentes
Los volúmenes persistentes ofrecen una forma fiable de ejecutar aplicaciones con estado. Su creación en la nube pública se realiza con un solo clic.
Primero podemos comprobar qué storageclass está disponible para su uso
|
1 2 3 |
$ kubectl get storageclass NAME PROVISIONER AGE standard (default) kubernetes.io/gce-pd 1d |
Todos los nodos trabajadores disponibles en el cluster k8s deben tener etiquetas de dominio de fallo como las siguientes
|
1 2 3 4 5 6 7 |
$ kubectl get nodes -o yaml | grep zone failure-domain.beta.kubernetes.io/zone: us-east1-b failure-domain.beta.kubernetes.io/zone: us-east1-b failure-domain.beta.kubernetes.io/zone: us-east1-d failure-domain.beta.kubernetes.io/zone: us-east1-d failure-domain.beta.kubernetes.io/zone: us-east1-c failure-domain.beta.kubernetes.io/zone: us-east1-c |
NOTA: No tengo que añadir ninguna etiqueta de dominio de fallo, GKE añade automáticamente.
Crear PV para cada AZ
|
1 |
$ kubectl apply -f svrgp-pv.yaml |
El archivo yaml svrgp-pv.yaml, se puede encontrar aquí.
Crear secreto para acceder a la interfaz de usuario de couchbase
|
1 |
$ kubectl apply -f secret.yaml |
Por último, despliegue el clúster couchbase con soporte TLS, junto con grupos de servidores (que son conscientes de Az) y en volúmenes persistentes (que también son conscientes de AZ).
|
1 |
$ kubectl apply -f couchbase-persistent-tls-svrgps.yaml |
El archivo yaml couchbase-persistent-tls-svrgps.yaml, se puede encontrar aquí
Dale unos minutos, y el cluster de couchbase aparecerá, y debería verse así
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ kubectl get pods NAME READY STATUS RESTARTS AGE cb-gke-demo-0000 1/1 Running 0 1d cb-gke-demo-0001 1/1 Running 0 1d cb-gke-demo-0002 1/1 Running 0 1d cb-gke-demo-0003 1/1 Running 0 1d cb-gke-demo-0004 1/1 Running 0 1d cb-gke-demo-0005 1/1 Running 0 1d cb-gke-demo-0006 1/1 Running 0 1d cb-gke-demo-0007 1/1 Running 0 1d couchbase-operator-6cbc476d4d-mjhx5 1/1 Running 0 1d couchbase-operator-admission-6f97998f8c-cp2mp 1/1 Running 0 1d |
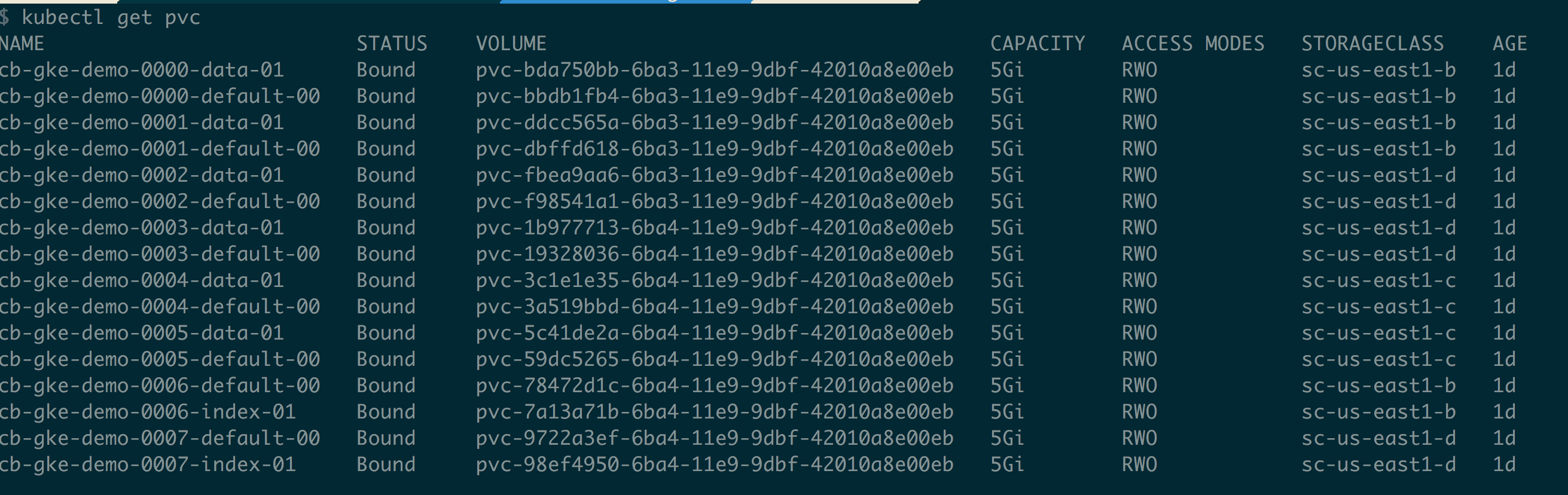
La comprobación rápida de las reclamaciones de volúmenes persistentes puede hacerse como se indica a continuación
|
1 |
$ kubectl get pvc |
Para acceder a la interfaz de usuario de Couchbase Cluster, podemos hacer un port-foward al puerto 8091 de cualquier pod o servicio en sí, en el portátil local, o máquina local, o puede ser expuesto a través de lb.
|
1 |
$ kubectl port-forward service/cb-gke-demo-ui 8091:8091 |
port-forward cualquier pod como el siguiente
|
1 |
$ kubectl port-forward cb-gke-demo-0002 8091:8091 |
En este punto el servidor couchbase está funcionando y tenemos forma de acceder a él.
Realizar Autofailover de Grupo de Servidores
Recuperación automática de grupos de servidores
Cuando un nodo del cluster couchbase falla, entonces puede auto-failover y sin ninguna intervención del usuario TODO el conjunto de trabajo está disponible, no es necesaria la intervención del usuario y la aplicación no verá el tiempo de inactividad.
Si Couchbase cluster está configurado para ser Server Group(SG) o AZ o Rack Zone(RZ) aware, entonces incluso si perdemos todo SG entonces todo el grupo de servidores falla y el conjunto de trabajo está disponible, no es necesaria la intervención del usuario y la aplicación no verá el tiempo de inactividad.
Con el fin de tener la recuperación de desastres, XDCR se puede utilizar para replicar los datos Couchbase a otro clúster Couchbase. Esto ayuda en el caso de que se pierda todo el centro de datos o región de origen, las aplicaciones se pueden transferir al sitio remoto y la aplicación no sufrirá tiempo de inactividad.
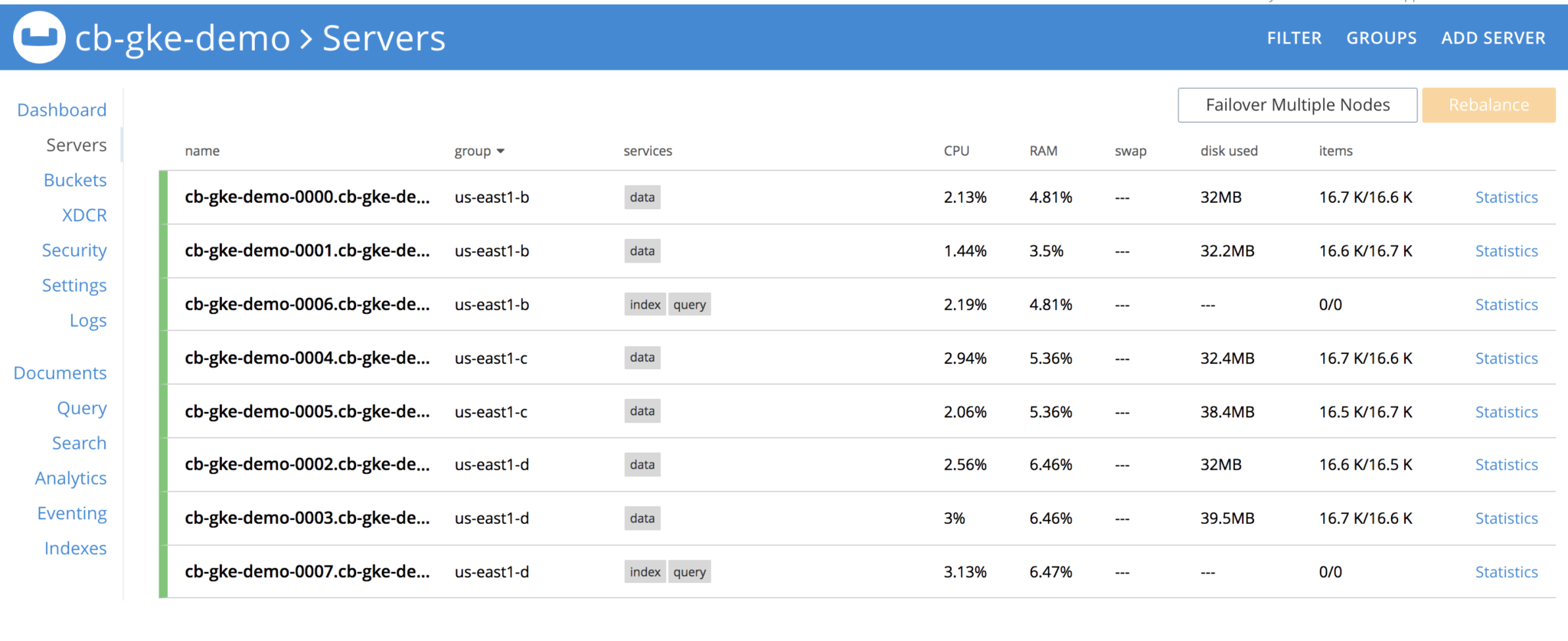
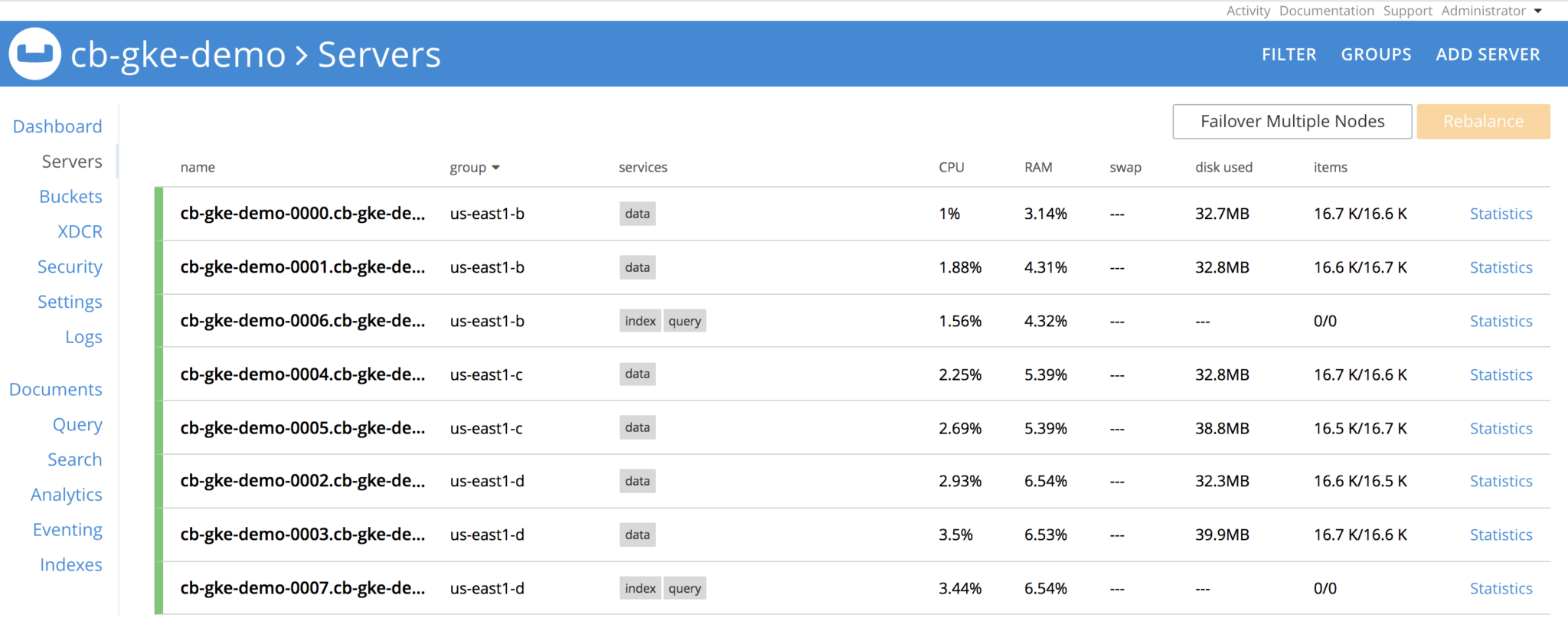
Vamos a desmontar el Grupo de Servidores. Antes de eso, vamos a ver cómo se ve el clúster
Borrar todos los pods del grupo us-east1-b, una vez borrados los pods, el cluster Couchbase verá que los nodos están 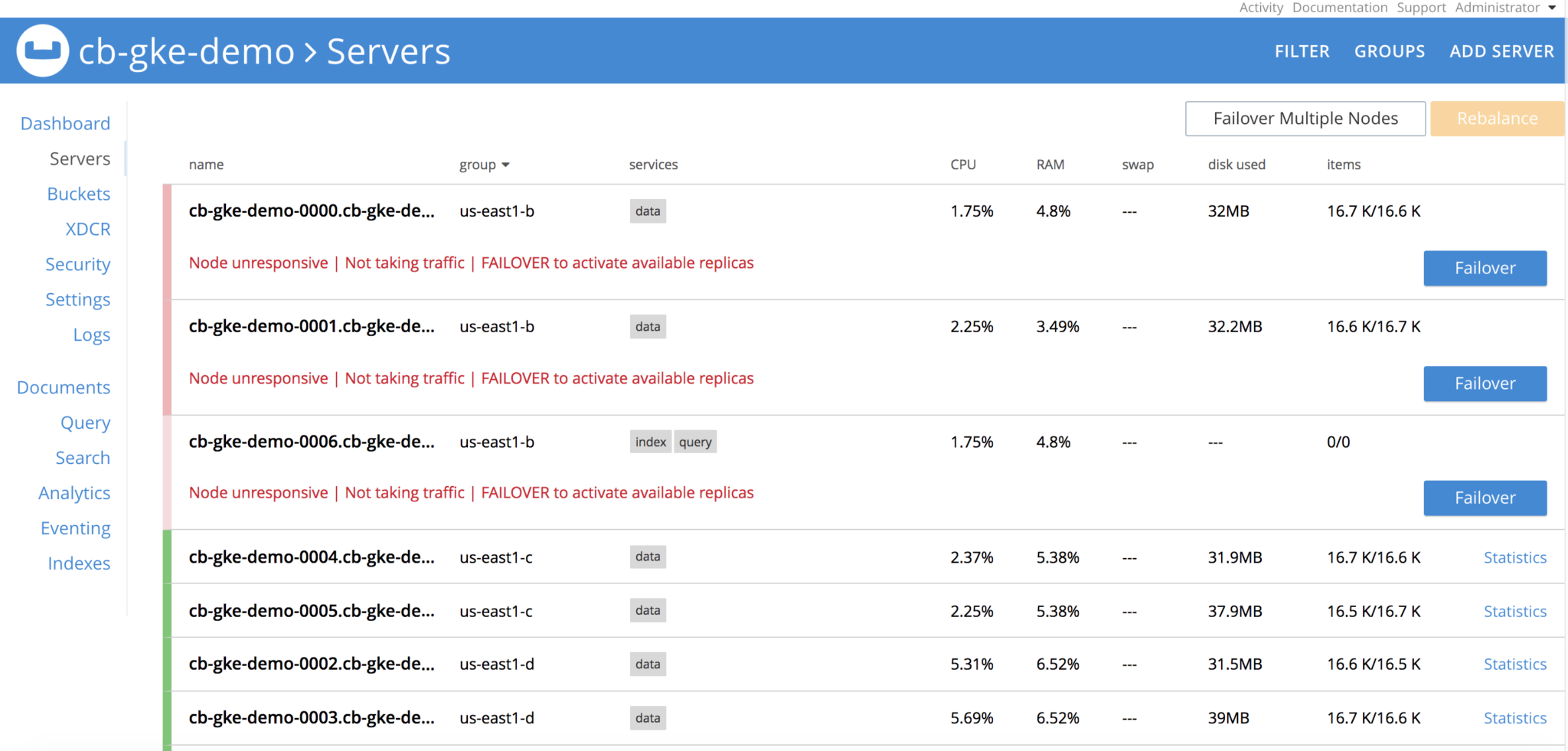
El operador está constantemente observando la definición del cluster y verá que el grupo de servidores se ha perdido, y hace girar los 3 pods, restablece las reclamaciones en los PVs y realiza la recuperación del nodo delta, y finalmente realiza la operación de reequilibrio y el cluster vuelve a estar sano. Todo ello sin intervención del usuario.
Después de algún tiempo, el clúster está de vuelta y en funcionamiento.
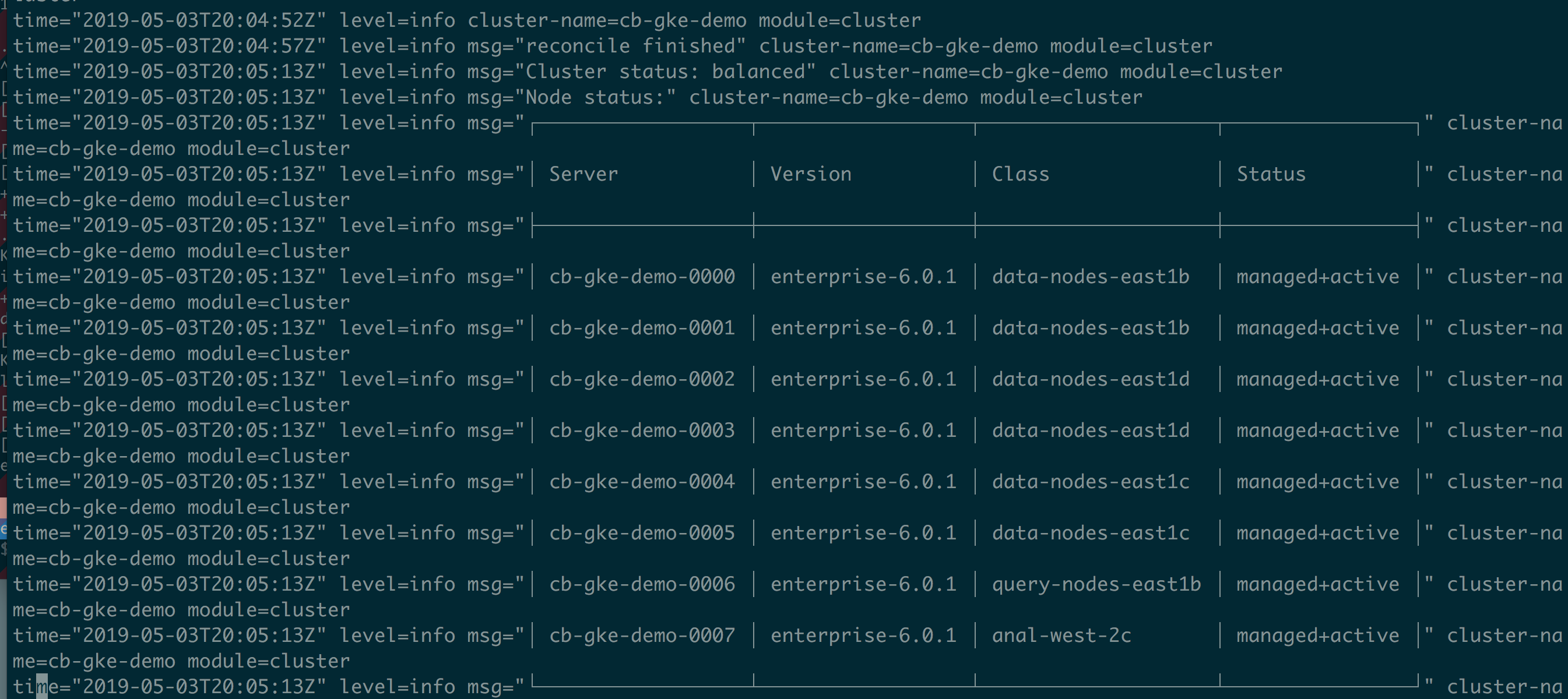
De los registros del operador,
|
1 |
$ kubectl logs -f couchbase-operator-6cbc476d4d-mjhx5 |
podemos ver que el clúster se reequilibra automáticamente.
Epílogo
La diferenciación sostenida es clave para nuestra tecnología. Hemos añadido un buen número de nuevas características de soporte. Con todas estas características de soporte de grado empresarial, permiten al usuario final encontrar los problemas más rápido y ayudar a poner en funcionamiento el Operador Couchbase en sus entornos de una manera más rápida y eficiente. Estamos muy entusiasmados con esta versión, ¡pruébala!
Referencias:
https://docs.couchbase.com/operator/1.2/whats-new.html
https://www.couchbase.com/downloads
https://docs.couchbase.com/server/6.0/manage/manage-groups/manage-groups.html
Libro del Operador Autónomo K8s de @AnilKumar
https://info.couchbase.com/rs/302-GJY-034/images/Kubernetes_ebook.pdf
https://docs.couchbase.com/operator/1.2/tls.html
Todos los archivos yaml y archivos de ayuda utilizados para este blog se pueden encontrar aquí