Temos o prazer de anunciar o lançamento do Couchbase Autonomous Operator 1.2. Este é um lançamento histórico que marca vários recursos solicitados pelos clientes, principalmente
- Upgrade automatizado de clusters do Couchbase
- Validação integrada de recursos do CouchbaseCluster por meio do controlador de administração
- Suporte do leme
- Conectividade pública para clientes do Couchbase
- Atualização contínua de clusters do Kubernetes
- Rotação de certificados TLS x509
- Experiência unificada de coleta de registros para implementações com e sem estado
-
Suporte para serviços públicos do Kubernetes no GKE, AKS e EKS. O Kubernetes em execução na nuvem pública já estava funcionando desde o primeiro dia, mas com o Autonomous Operator 1.2, estamos oferecendo suporte oficial a ele. Para a perspectiva deste blog, usaremos o GKE para configurar o cluster do Kubernetes no GKE com a versão 1.12, depois implantaremos o Autonomous Operator e, por fim, implantaremos o Couchbase Cluster com Server Groups, com volumes persistentes e com certificados x509 TLS.
As etapas gerais que faremos neste blog são as seguintes:
-
Inicializar os utilitários do gcloud
-
Implante o cluster do Kubernetes (v1.12+) com 2 nós em cada zona de disponibilidade
-
Implante o Operador Autônomo 1.2
-
Implantar o cluster do Couchbase
-
Executar o Autofailover do grupo de servidores
Pré-requisitos
- kubectl (Os componentes do gcloud instalam o kubectl)
- Conta GCP com as credenciais corretas
Inicializar os utilitários do gcloud
Faça o download do sdk do gcloud para a versão do sistema operacional de sua escolha a partir deste URL.
É preciso ter credenciais do Google Cloud para inicializar o cli do gcloud
|
1 2 3 |
cd google-cloud-sdk ./install.sh ./bin/gcloud init |
Implante o cluster do Kubernetes (v1.12) com 2 nós em cada zona de disponibilidade
Implantar o cluster do Kubernetes no GKE é uma tarefa bastante simples. Para implantar clusters kubernetes resilientes, é uma boa ideia implantar nós em todas as zonas disponíveis em uma determinada região. Fazendo isso dessa forma, podemos usar o recurso de reconhecimento de Grupos de servidores ou Zona de rack ou Zona de disponibilidade (AZ) no servidor Couchbase, o que significa que, se perdermos toda a AZ, o couchbase poderá fazer failover de toda a AZ e o aplicativo ficará ativo, pois ainda tem o conjunto de dados em funcionamento.
|
1 |
gcloud container clusters create rd-k8s-gke --region us-east1 --machine-type n1-standard-16 --num-nodes 2 |
|
1 2 3 4 |
Details about above command K8s cluster name : rd-k8s-gke machine-type: n1-standard-16 (16 vCPUs and 60GB RAM) num-nodes/AZ : 2 |
Mais tipos de máquinas podem ser aqui
Nesse momento, o cluster do k8s com o número necessário de nós deve estar em funcionamento
|
1 2 3 |
$ gcloud container clusters list NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION <strong>NUM_NODES</strong> STATUS rd-k8s-gke us-east1 1.12.6-gke.10 35.229.24.36 n1-standard-16 1.12.6-gke.10 <strong>6</strong> RUNNING |
Os detalhes do cluster k8s podem ser encontrados abaixo
|
1 2 3 4 5 6 |
$ kubectl cluster-info Kubernetes master is running at https://55.229.24.36 GLBCDefaultBackend is running at https://55.229.24.36/api/v1/namespaces/kube-system/services/default-http-backend:http/proxy Heapster is running at https://55.229.24.36/api/v1/namespaces/kube-system/services/heapster/proxy KubeDNS is running at https://55.229.24.36/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy Metrics-server is running at https://55.229.24.36/api/v1/namespaces/kube-system/services/https:metrics-server:/proxy |
Implante o Operador Autônomo 1.2
O GKE é compatível com o RBAC para limitar as permissões. Como o Couchbase Operator cria recursos em nosso cluster do GKE, precisaremos conceder a ele a permissão para fazer isso.
|
1 |
$ kubectl create clusterrolebinding cluster-admin-binding --clusterrole cluster-admin --user $(gcloud config get-value account) |
Baixar o pacote apropriado para a implantação do kubernetes em seu ambiente. Descompacte o pacote e implemente o controlador de admissão.
|
1 |
$ kubectl create -f admission.yaml |
Verificar o status do controlador de admissão
|
1 2 3 |
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE couchbase-operator-admission 1 1 1 1 7s |
Para visualizar como o controlador de admissão funciona em sincronia com o operador e o cluster do couchbase, ele pode ser melhor ilustrado com o diagrama a seguir
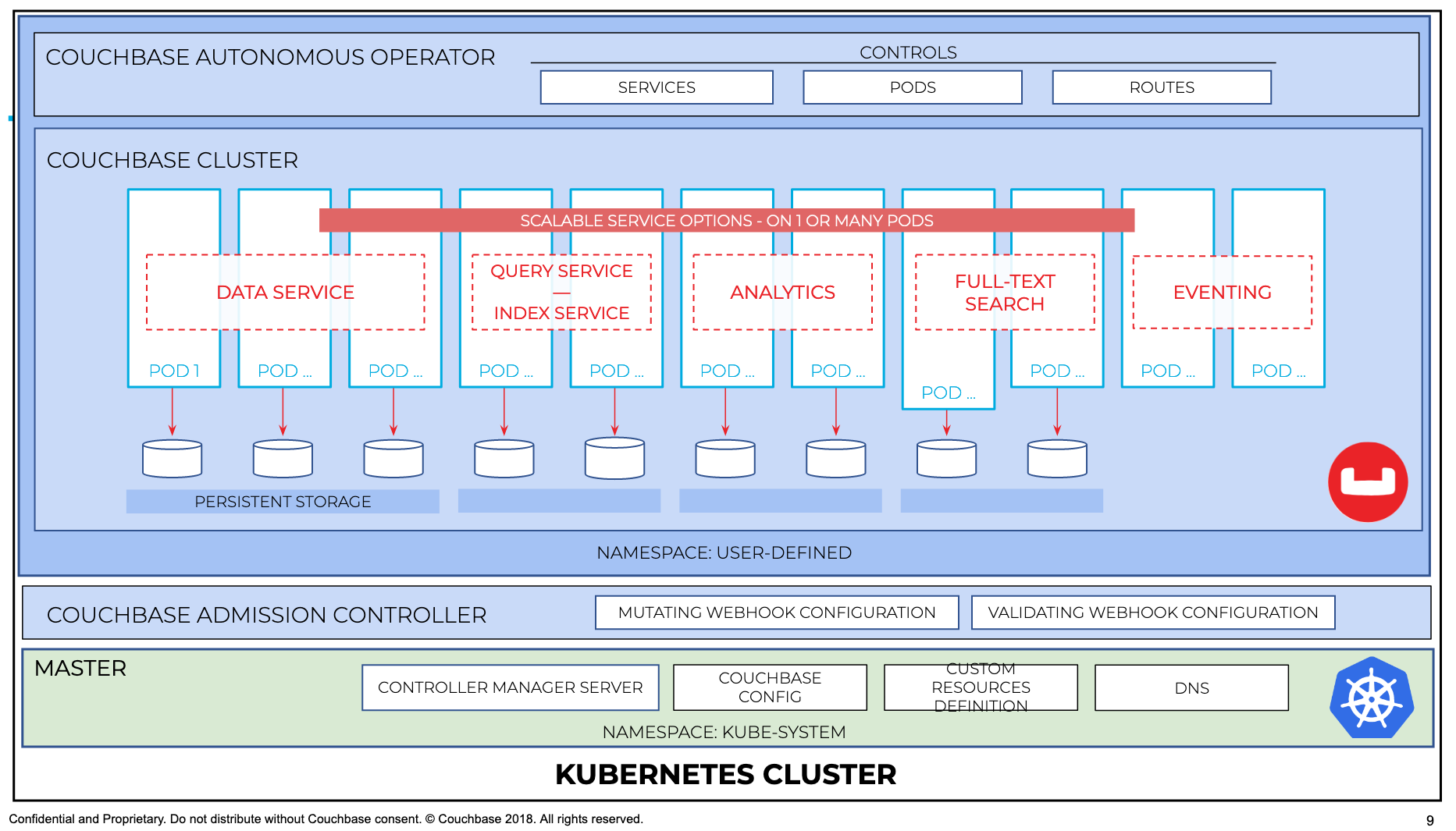
As próximas etapas são criar o crd, a função de operador e o operador 1.2
|
1 2 3 |
$ kubectl create -f crd.yaml $ kubectl create -f operator-role.yaml $ kubectl create -f operator-deployment.yaml |
Quando o operador é implantado, ele fica pronto e disponível em segundos
|
1 2 3 4 |
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE couchbase-operator-admission 1 1 1 1 11m couchbase-operator 1 1 1 1 25s |
Implantar o cluster do Couchbase
O cluster do Couchbase será implantado com os seguintes recursos
-
Certificados TLS
-
Grupos de servidores (cada grupo de servidores em uma AZ)
-
Volumes persistentes (que são compatíveis com AZ)
-
Auto-failover do grupo de servidores
Certificados TLS
É bastante fácil gerar certificados tls; as etapas detalhadas podem ser encontradas em aqui
Depois de implantados, os segredos tls podem ser encontrados com o comando kubectl secret, como abaixo
|
1 2 3 4 |
$ kubectl get secrets NAME TYPE DATA AGE couchbase-operator-tls Opaque 1 1d couchbase-server-tls Opaque 2 1d |
Grupos de servidores
A configuração de grupos de servidores também é simples, o que será discutido nas seções a seguir quando implantarmos o arquivo yaml do cluster do couchbase.
Volumes persistentes
Os volumes persistentes oferecem uma maneira confiável de executar aplicativos com estado. Criá-los na nuvem pública é uma operação de um clique.
Primeiro, podemos verificar qual classe de armazenamento está disponível para uso
|
1 2 3 |
$ kubectl get storageclass NAME PROVISIONER AGE standard (default) kubernetes.io/gce-pd 1d |
Todos os nós de trabalho disponíveis no cluster do k8s devem ter rótulos de domínio de falha, como abaixo
|
1 2 3 4 5 6 7 |
$ kubectl get nodes -o yaml | grep zone failure-domain.beta.kubernetes.io/zone: us-east1-b failure-domain.beta.kubernetes.io/zone: us-east1-b failure-domain.beta.kubernetes.io/zone: us-east1-d failure-domain.beta.kubernetes.io/zone: us-east1-d failure-domain.beta.kubernetes.io/zone: us-east1-c failure-domain.beta.kubernetes.io/zone: us-east1-c |
OBSERVAÇÃO: não preciso adicionar nenhum rótulo de domínio de falha, o GKE adicionou automaticamente.
Criar PV para cada AZ
|
1 |
$ kubectl apply -f svrgp-pv.yaml |
O arquivo yaml svrgp-pv.yaml pode ser encontrado aqui.
Criar segredo para acessar a interface do usuário do couchbase
|
1 |
$ kubectl apply -f secret.yaml |
Por fim, implemente o cluster do Couchbase com suporte a TLS, juntamente com os Grupos de Servidores (que são compatíveis com o AZ) e em volumes persistentes (que também são compatíveis com o AZ).
|
1 |
$ kubectl apply -f couchbase-persistent-tls-svrgps.yaml |
O arquivo yaml couchbase-persistent-tls-svrgps.yaml pode ser encontrado aqui
Aguarde alguns minutos e o cluster do couchbase será ativado e deverá ter a seguinte aparência
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ kubectl get pods NAME READY STATUS RESTARTS AGE cb-gke-demo-0000 1/1 Running 0 1d cb-gke-demo-0001 1/1 Running 0 1d cb-gke-demo-0002 1/1 Running 0 1d cb-gke-demo-0003 1/1 Running 0 1d cb-gke-demo-0004 1/1 Running 0 1d cb-gke-demo-0005 1/1 Running 0 1d cb-gke-demo-0006 1/1 Running 0 1d cb-gke-demo-0007 1/1 Running 0 1d couchbase-operator-6cbc476d4d-mjhx5 1/1 Running 0 1d couchbase-operator-admission-6f97998f8c-cp2mp 1/1 Running 0 1d |
Uma verificação rápida das reivindicações de volumes persistentes pode ser feita da seguinte forma
|
1 |
$ kubectl get pvc |
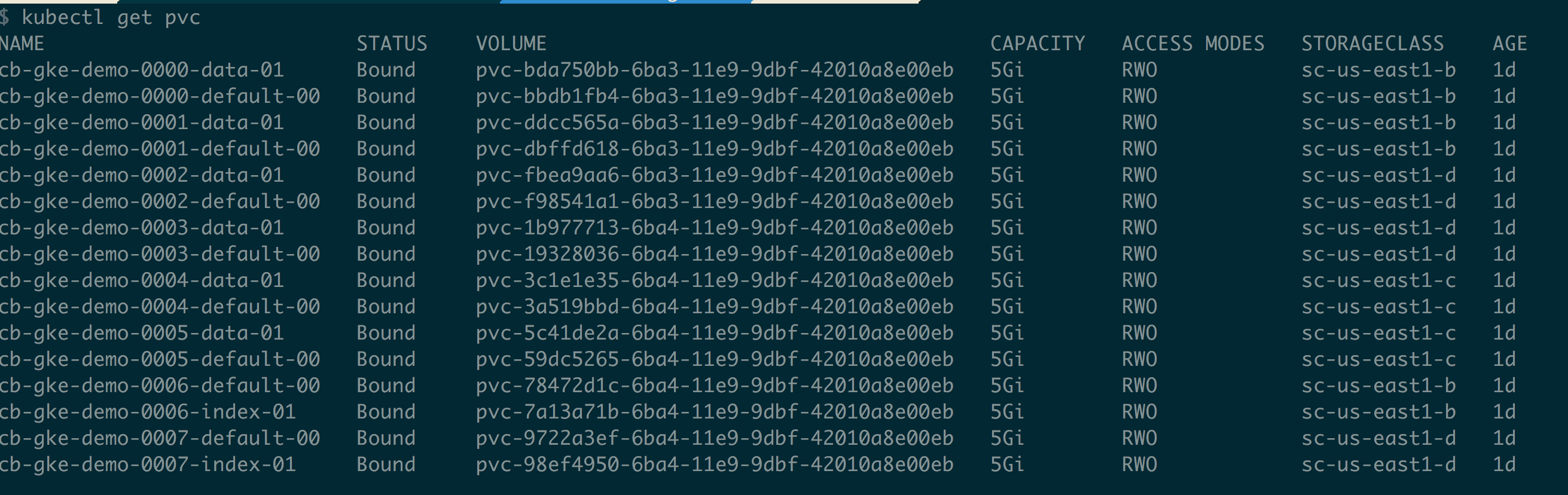
Para acessar a interface do usuário do cluster do Couchbase, podemos fazer o port-foward da porta 8091 de qualquer pod ou serviço em si, no laptop local ou na máquina local, ou ela pode ser exposta via lb.
|
1 |
$ kubectl port-forward service/cb-gke-demo-ui 8091:8091 |
encaminhamento de porta para qualquer pod, como abaixo
|
1 |
$ kubectl port-forward cb-gke-demo-0002 8091:8091 |
Nesse ponto, o servidor couchbase está em funcionamento e temos como acessá-lo.
Executar o Autofailover do grupo de servidores
Auto-failover do grupo de servidores
Quando um nó do cluster do couchbase falha, ele pode fazer o failover automático e, sem nenhuma intervenção do usuário, TODO o conjunto de trabalho está disponível, não é necessária nenhuma intervenção do usuário e o aplicativo não sofrerá tempo de inatividade.
Se o cluster do Couchbase estiver configurado para ser compatível com o Server Group (SG) ou AZ ou Rack Zone (RZ), mesmo que percamos todo o SG, os grupos de servidores inteiros sofrerão falha e o conjunto de trabalho estará disponível, não será necessária nenhuma intervenção do usuário e o aplicativo não sofrerá tempo de inatividade.
Para ter uma recuperação de desastres, o XDCR pode ser usado para replicar os dados do Couchbase para outro cluster do Couchbase. Isso ajuda no caso de perda de todo o data center ou região de origem, os aplicativos podem ser transferidos para o site remoto e não haverá tempo de inatividade.
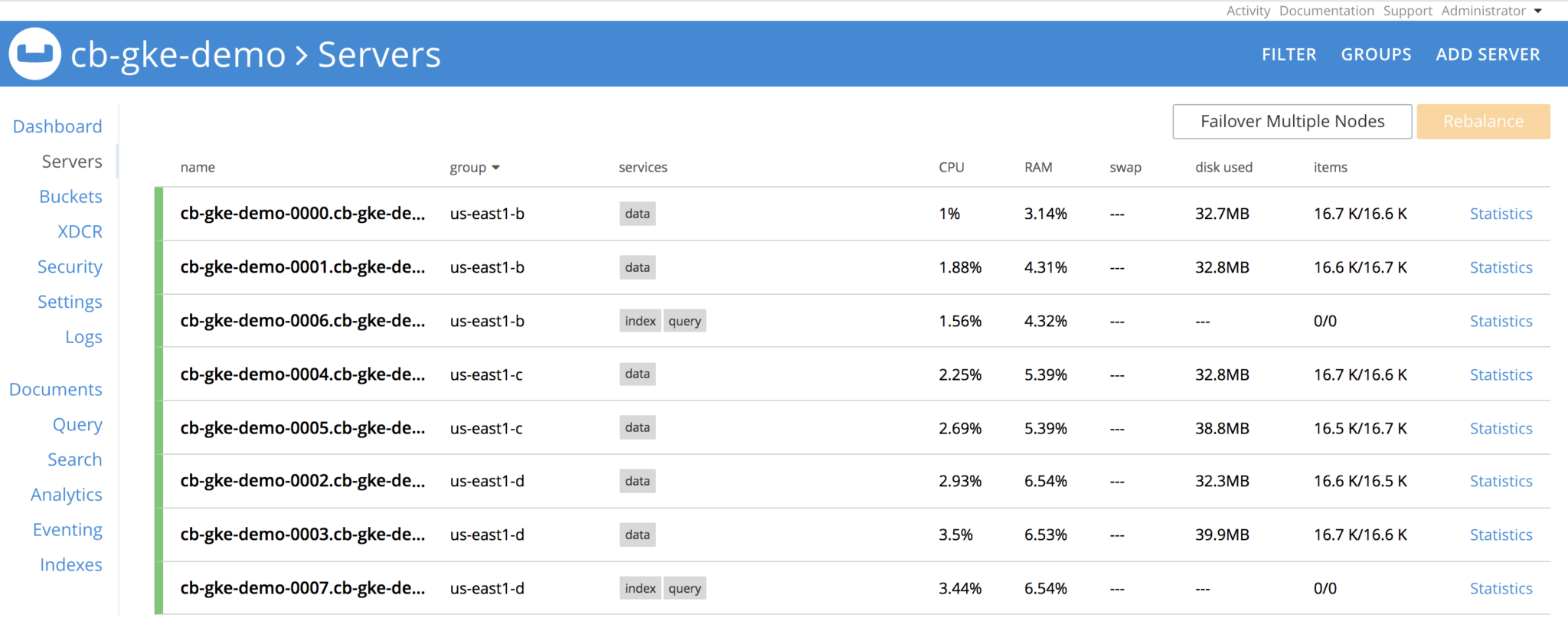
Vamos remover o grupo de servidores. Antes disso, vamos ver como é o cluster
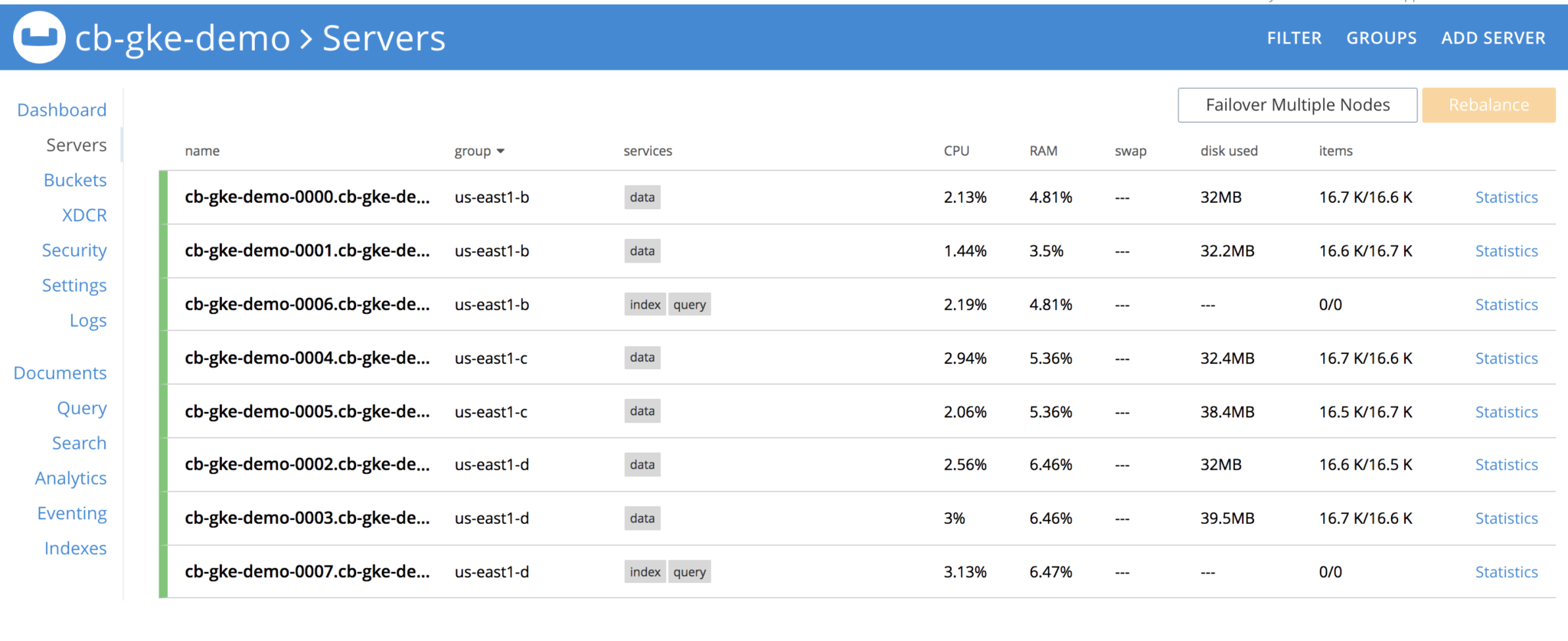
Exclua todos os pods no grupo us-east1-b. Depois que os pods forem excluídos, o cluster do Couchbase verá que os nós são 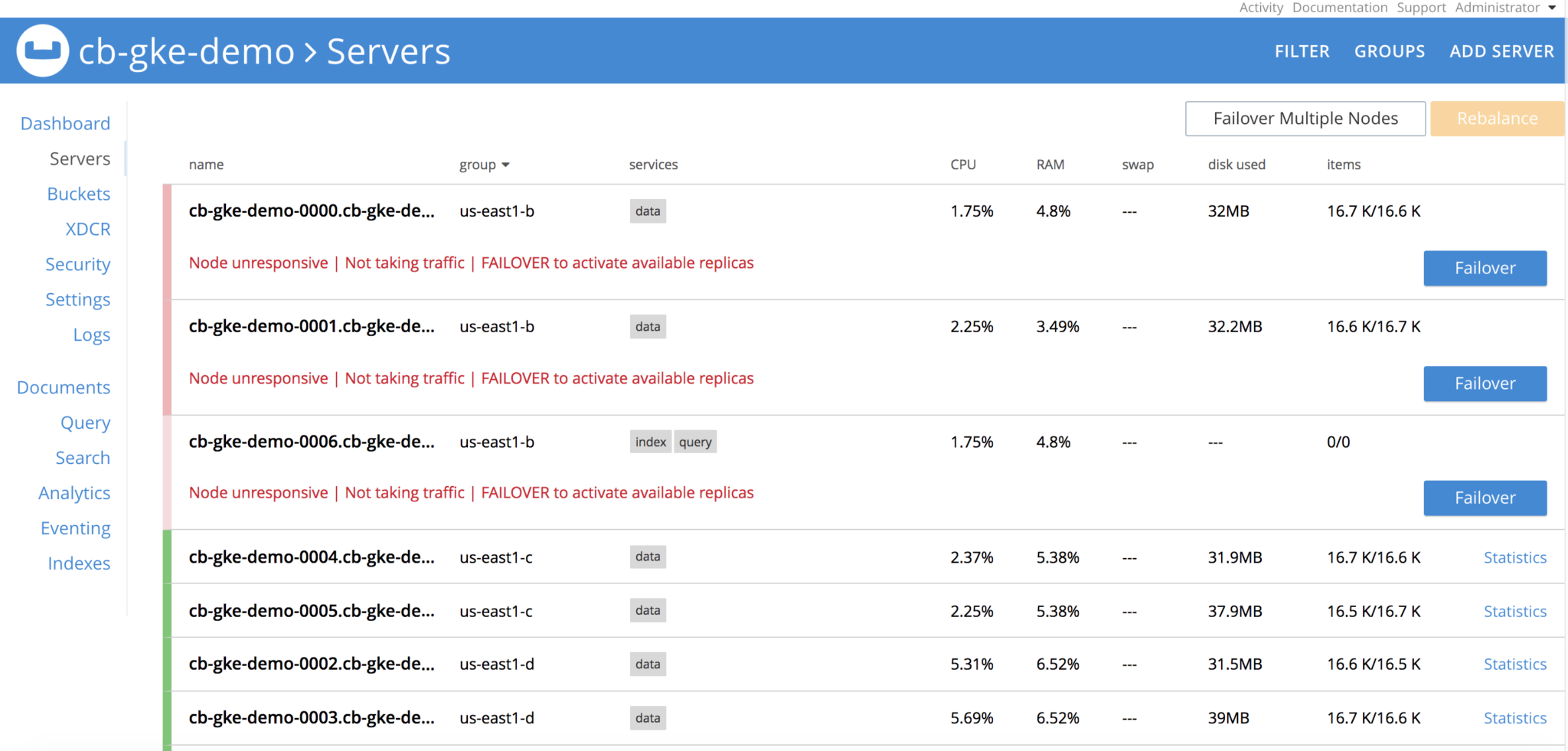
O operador está constantemente observando a definição do cluster e verá que o grupo de servidores foi perdido, girará os 3 pods, restabelecerá as reivindicações nos PVs e executará a recuperação do nó delta e, por fim, executará a operação de rebalanceamento e o cluster estará saudável novamente. Tudo isso sem nenhuma intervenção do usuário.
Depois de algum tempo, o cluster está de volta e funcionando.
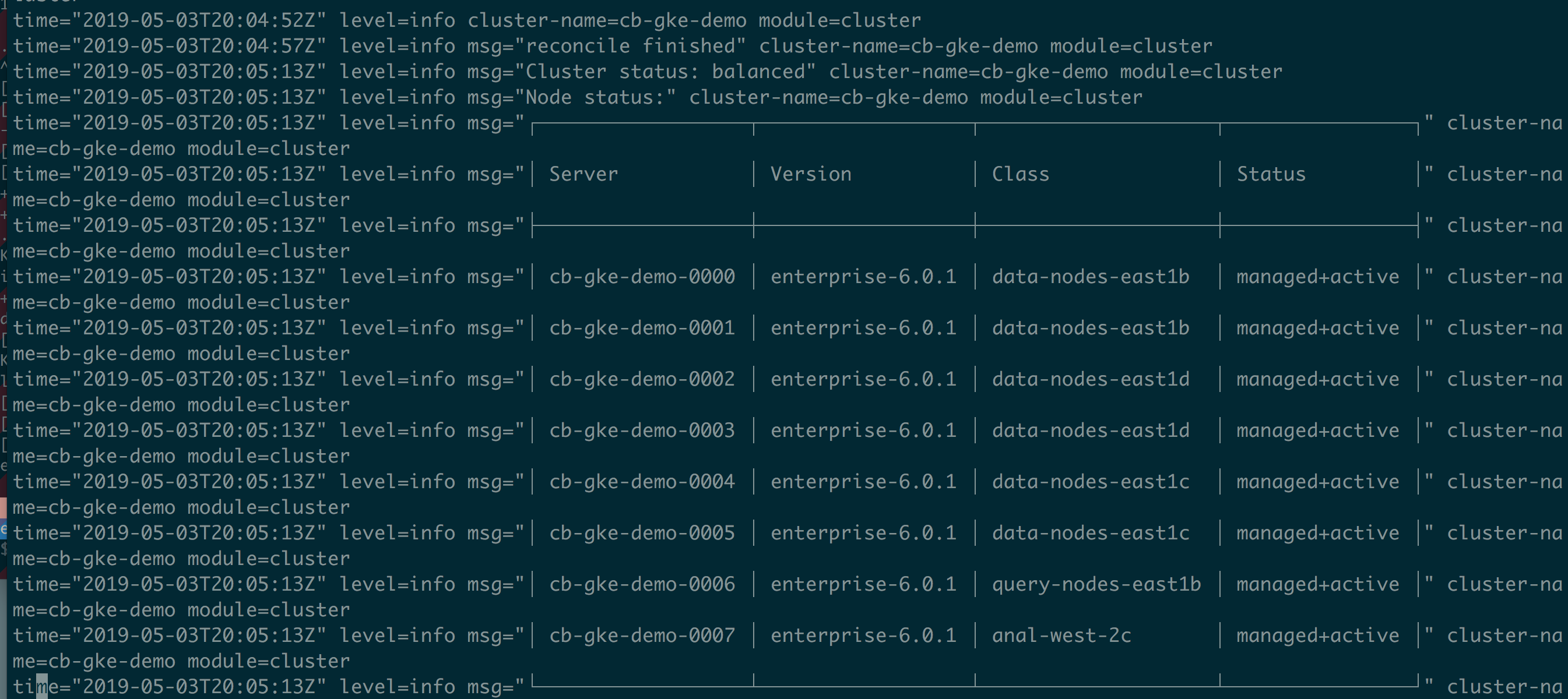
Nos registros do operador,
|
1 |
$ kubectl logs -f couchbase-operator-6cbc476d4d-mjhx5 |
podemos ver que o cluster é automaticamente reequilibrado.
Epílogo
A diferenciação sustentada é fundamental para nossa tecnologia. Adicionamos um grande número de recursos novos e de suporte. Com todos esses recursos de suporte de nível empresarial, eles permitem que o usuário final encontre os problemas mais rapidamente e ajudam a operacionalizar o Couchbase Operator em seus ambientes de maneira mais rápida e eficiente. Estamos muito animados com o lançamento, sinta-se à vontade para experimentar!
Referências:
https://docs.couchbase.com/operator/1.2/whats-new.html
https://www.couchbase.com/downloads
https://docs.couchbase.com/server/6.0/manage/manage-groups/manage-groups.html
Livro do operador autônomo do K8s de @AnilKumar
https://info.couchbase.com/rs/302-GJY-034/images/Kubernetes_ebook.pdf
https://docs.couchbase.com/operator/1.2/tls.html
Todos os arquivos yaml e arquivos de ajuda usados para este blog podem ser encontrados aqui