El concepto de consolidación es sencillo, y aplicar sus principios puede reportar inmensos beneficios a cualquier organización. Pero, ¿qué significa consolidación en el contexto de la tecnología de bases de datos?
Google define consolidación como "Acción o proceso de combinar varias cosas para formar un todo más eficaz o coherente".
Cuando se aplica a las bases de datos, la consolidación puede significar un par de cosas para cualquier organización:
-
- Reducir el número de tecnologías dispares que gestionan los datos.
- Reducir la redundancia innecesaria de datos, es decir, múltiples copias de los mismos datos.
Un ejemplo sencillo del problema podría ser una empresa que almacena exactamente los mismos datos de clientes en tres bases de datos diferentes. Por ejemplo, una operativo base de datos para la gestión de ventas, un análisis base de datos para inteligencia empresarial, y una almacenamiento en caché para agilizar el inicio de sesión de los clientes en una aplicación web corporativa. Dentro de cada una de estas bases de datos, existe una replicación de datos para la conmutación por error y la recuperación en caso de desastre, lo que agrava la inflación general de datos.
Los responsables técnicos de la organización saben que están creando redundancias que complican las cosas, pero optan por vivir con esta complejidad y este coste porque creen que no existe una única base de datos que pueda servir para los tres propósitos. A medida que se hacen estas concesiones una y otra vez para más aplicaciones, la huella de datos se hincha hasta el punto de que muchas organizaciones se encuentran pagando tarifas de almacenamiento exorbitantes y perdiendo la noción de cuántos datos tienen siquiera. Bienvenido al desagradable mundo de dispersión de datos!
El dolor de la dispersión de datos
La dispersión de datos crea un complicado entorno de sistemas poco integrados cuya gestión lleva mucho tiempo, genera elevados costes de almacenamiento, aumenta los riesgos de seguridad y provoca una pérdida general de eficiencia, lo que lleva a muchas organizaciones a hacer de su eliminación una prioridad.
De hecho, Google presenta lo siguiente como un uso correcto de la palabra consolidación en una frase: "consolidación de datos en una empresa". Llama la atención que Google haya optado por utilizar "consolidación de datos" como ejemplo, haciendo hincapié en que es un objetivo común para muchas organizaciones. ¿Por qué es un objetivo atractivo? Porque la consolidación de bases de datos tiene ventajas evidentes. Cuando se reducen las capas dispares de tecnología de bases de datos en la pila, se reduce la complejidad porque hay menos que gestionar y se reducen los costes porque la huella de datos es menor.
Pero con todos los diferentes sistemas, formatos de datos y patrones de acceso existentes para alimentar las aplicaciones empresariales, ¿cómo puede una organización reducir la dispersión de datos sin dejar de ofrecer las funcionalidades específicas que requieren sus aplicaciones? Exploremos esta cuestión con más detalle.
Bueno, ¿cómo hemos llegado hasta aquí?
Hay muchas cosas que provocan una proliferación insostenible de tecnologías de bases de datos en una organización: fusiones y adquisiciones, requisitos de retención de datos heredados, falta de normas tecnológicas corporativas formales y un el mejor de la raza una cultura tecnológica que promueve el uso de las herramientas más adaptadas a cada necesidad, frente a un conjunto consolidado de herramientas polivalentes.
Estas condiciones existen en muchas organizaciones, algunas planificadas, otras no, pero todas contribuyen a crear una confusa pila de bases de datos de un solo uso y copias interminables de los mismos datos que elevan los costes y, en última instancia, ralentizan el negocio.
Examinemos algunos de los tipos de bases de datos, y su funcionalidad específica, que suelen ser necesarios para alimentar las aplicaciones modernas de una empresa.
Tipos de bases de datos
Bases de datos relacionales
Las bases de datos relacionales soportan SQL de forma nativa con uniones, agregaciones y Transacciones ACIDson los pilares de las aplicaciones y sistemas operativos. Destacan por almacenar datos muy estructurados y ofrecer una gran coherencia, pero estas características conllevan rigidez porque el modelo de datos es fijo y está definido por un esquema estático. Por tanto, para cambiar el modelo de datos, los desarrolladores tienen que modificar el esquema, lo que puede ralentizar el desarrollo. Además, las bases de datos relacionales no están diseñadas para funcionar a gran escala, por lo que su rendimiento tiende a degradarse a medida que crecen las aplicaciones. Debido a su ubicuidad en las aplicaciones operativas heredadas, las organizaciones suelen tener muchas bases de datos relacionales en su ecosistema para cumplir funciones como el procesamiento de transacciones.
Bases de datos documentales NoSQL
Las bases de datos de documentos NoSQL no tienen esquema y almacenan los datos como documentos JSON en lugar de tablas de filas y columnas. Las bases de datos documentales NoSQL también están diseñadas para el tratamiento distribuido de datosdonde una única base de datos abarca varios nodos para formar un clúster de procesamiento de datos. Esto hace que las bases de datos NoSQL sean intrínsecamente escalables al permitir que los datos se procesen a través de una arquitectura distribuida: si un nodo se cae, los demás se hacen cargo.
Además, JSON es el estándar de facto para consumir y producir datos para aplicaciones móviles, por lo que es ideal para el desarrollo sin rigidez relacional, porque JSON defiere a las aplicaciones y servicios, y por lo tanto a los desarrolladores en cuanto a cómo deben modelarse los datos. Si el desarrollo de su aplicación sigue el modelo de dominio y desea la flexibilidad necesaria para hacer evolucionar las aplicaciones sin la sobrecarga de la rigidez relacional, una base de datos de documentos NoSQL JSON es una gran opción. Muchas organizaciones adoptan bases de datos de documentos NoSQL como medio para escalar sus aplicaciones.
Este artículo ofrece más detalles sobre las diferencias entre bases de datos relacionales y NoSQL.
Bases de datos clave-valor / en memoria
Una base de datos clave-valor almacena los datos como una colección de pares clave-valor en la que cada clave única está asociada a un valor de datos específico. El formato de los datos es sencillo para facilitar la velocidad, y muchas bases de datos clave-valor también se ejecutan en caché en memoria para maximizar el rendimiento. La velocidad y eficiencia de las bases de datos de valor clave las convierten en una buena opción para necesidades sencillas de almacenamiento y recuperación de datos cuando el objetivo es el alto rendimiento, y muchas organizaciones añaden una base de datos de valor clave a su pila tecnológica de aplicaciones para ofrecer una experiencia más rápida a los usuarios.
Bases de datos de búsqueda de texto completo
Una base de datos de búsqueda de texto completo utiliza un índice de búsqueda para examinar todo el texto de los documentos almacenados que coincida con los criterios de búsqueda (es decir, el texto especificado por un usuario). La búsqueda de texto completo suele centrarse en los campos de texto largo de los documentos, como descripciones, resúmenes o comentarios, utilizando índices preorganizados para que la recuperación sea más rápida que la exploración tradicional de bases de datos por campos. Muchas organizaciones añaden una base de datos de búsqueda de texto completo a su pila tecnológica de aplicaciones para proporcionar características y funcionalidades de búsqueda.
Bases de datos de búsqueda vectorial
Las bases de datos de búsqueda vectorial aprovechan los algoritmos de vecino más próximo para recuperar los registros que más se aproximan a un criterio de búsqueda determinado. En una base de datos de búsqueda vectorial, el texto, las imágenes, el audio y el vídeo se convierten en representaciones matemáticas llamadas vectores, que se indexan y utilizan para búsquedas semánticas. Como tal, una búsqueda vectorial encuentra información relacionada basándose en el significado de la consulta de búsqueda, no sólo en las palabras y frases introducidas, lo que la convierte en la mejor opción para presentar información relevante que conecte con los usuarios.
La búsqueda vectorial también hace que los resultados de la IA generativa sean más precisos y personales al permitir la Generación de Recuperación Aumentada (Retrieval Augmented Generation, RAG), en la que los datos complementarios se pasan junto con las indicaciones para proporcionar una mayor precisión y contexto a las respuestas LLM. Debido a la expectativa de capacidades de IA en las aplicaciones modernas, muchas organizaciones añaden una base de datos de búsqueda vectorial a su pila tecnológica de aplicaciones para potenciar la búsqueda semántica y las características y funcionalidades basadas en IA generativa.
Bases de datos analíticas columnares
Una base de datos analítica columnar está diseñada para recuperar rápidamente los resultados de consultas analíticas complejas. A diferencia de las bases de datos tradicionales basadas en filas, que almacenan y recuperan los datos en filas, las bases de datos columnares organizan los datos verticalmente, agrupando y almacenando juntos los valores de cada columna. Esta arquitectura mejora la compresión de datos y minimiza las operaciones de E/S, lo que se traduce en un rendimiento más rápido de las consultas y una mejora de la analítica de datos. Las bases de datos columnares son especialmente adecuadas para cargas de trabajo analíticas que implican consultas y agregaciones complejas sobre grandes conjuntos de datos. Destacan en situaciones en las que las operaciones de lectura intensiva, como la elaboración de informes y el análisis de datos, son más frecuentes que las operaciones de escritura. Muchas organizaciones añaden una base de datos analítica columnar a su pila tecnológica de aplicaciones para potenciar las aplicaciones de inteligencia empresarial y análisis de datos.
Bases de datos de series temporales
Una base de datos de series temporales almacena y procesa datos en pares asociados de tiempo y valor. Los datos de series temporales son habituales en las aplicaciones IoT, en las que sensores y contadores registran lecturas a intervalos de tiempo regulares y envían la información a la base de datos. La complejidad de los datos de series temporales radica en el procesamiento adecuado de los datos, incluso cuando las lecturas pueden no venir en una secuencia lineal basada en el tiempo. Por ejemplo, en entornos distribuidos con muchos dispositivos IoT en funcionamiento, las lecturas pueden escribirse en la base de datos fuera de orden cronológico, y la funcionalidad de series temporales de la base de datos concilia esto para mantener la coherencia y precisión de los datos. Muchas organizaciones añaden una base de datos de series temporales a su pila tecnológica de aplicaciones para habilitar las aplicaciones IoT.
Bases de datos gráficas
Una base de datos gráfica se construye para almacenar y gestionar datos interconectados, representándolos como nodos (entidades) y aristas (relaciones), formando una estructura gráfica. Cada nodo almacena atributos, mientras que las aristas definen conexiones y propiedades entre nodos. Este diseño hace que las bases de datos de grafos sean ideales para manejar relaciones complejas que implican conexiones, como las redes sociales, los sistemas de recomendación y los grafos de conocimiento. A diferencia de las bases de datos relacionales tradicionales, las bases de datos de grafos son excelentes para recorrer las relaciones, lo que permite realizar consultas más rápidas e intuitivas y obtener resultados más precisos. Además, las bases de datos de gráficos son ideales para la Generación Aumentada de Recuperación (RAG), donde las relaciones de datos se pueden pasar junto con las indicaciones para proporcionar una mejor precisión y contexto para las respuestas generativas de IA/LLM. Muchas organizaciones añaden una base de datos de gráficos a su pila tecnológica de aplicaciones para ayudar a potenciar las funciones de IA en sus aplicaciones.
Bases de datos integradas
Una base de datos incrustada es un sistema de base de datos autónomo integrado directamente en la base de código de una aplicación, lo que elimina la necesidad de un servidor de base de datos independiente. El procesamiento de datos integrado proporciona un acceso más rápido a los datos y elimina la dependencia de Internet para acceder a ellos. Las bases de datos integradas se utilizan habitualmente en aplicaciones móviles y de IoT en las que se espera una falta de conectividad a la red intermitente o prolongada, como en el caso de los servicios de campo u otros casos de uso que operan regularmente fuera del alcance de las redes. Un componente crítico de una base de datos integrada es la capacidad de sincronizar datos con bases de datos centralizadas, así como con otros clientes de bases de datos integradas, lo que es importante para mantener la integridad y coherencia de los datos.
La persistencia políglota no es el enfoque
Si nos fijamos en la lista de los distintos tipos de bases de datos y en los patrones de acceso específicos que permiten, es fácil ver cómo una organización adoptaría múltiples bases de datos.
Supongamos que una empresa tiene una aplicación web de comercio electrónico. Para gestionar los inventarios y alimentar las transacciones, podrían empezar con una base de datos relacional. Pero como las bases de datos relacionales no son escalables, podrían añadir una base de datos en memoria con caché de clave-valor para acelerar el rendimiento. A medida que la aplicación crece, es posible que quieran desplegar una arquitectura distribuida en la nube para escalar, y así añadir una base de datos de documentos NoSQL. A continuación, para potenciar la búsqueda en la aplicación, podrían añadir una base de datos de búsqueda. Y a medida que busquen aprovechar la IA para hacer ofertas y recomendaciones atractivas a los usuarios de la aplicación, podrían adoptar una base de datos de búsqueda vectorial y una base de datos gráfica. A continuación, a medida que despliegan la versión móvil de la aplicación, podrían adoptar una base de datos incrustada. Y, por último, para analizar los datos de sus clientes, podrían añadir una base de datos de análisis columnar. Este enfoque se conoce como persistencia políglota que TechTarget define como:
...término conceptual que hace referencia al uso de diferentes enfoques y tecnologías de almacenamiento de datos para satisfacer las necesidades específicas de almacenamiento de los distintos tipos de datos que contienen las aplicaciones empresariales..
Aunque el planteamiento tiene sentido sobre el papel -utilizar la mejor herramienta para el trabajo-, si se tienen en cuenta las múltiples capas de procesamiento de datos y la replicación para la conmutación por error y la recuperación ante desastres inherentes a cada base de datos, se puede ver cómo la huella de datos crece exponencialmente con cada sistema añadido.
El entorno resultante es caro y difícil de mantener, y puede descontrolarse rápidamente si no se aborda adecuadamente.
Ventajas de la consolidación de bases de datos
Si bien los inconvenientes de la proliferación de bases de datos y la dispersión de los datos resultan obvios al examinarlos, las ventajas de consolidar un entorno de este tipo resultan igual de evidentes.
Al reducir capas dispares de tecnología de bases de datos en su pila, usted:
-
- Reducir la complejidad porque hay menos que gestionar.
- Reduzca costes porque su huella de datos es menor.
- Mejorar la eficiencia, ya que un menor número de fuentes de datos hace que las aplicaciones sean más fáciles de desarrollar y más rápidas de evolucionar.
Pero, ¿cómo consolidar sus bases de datos sin perder su funcionalidad crítica? Con la base de datos adecuada.
Couchbase Capella: la base de datos polivalente
Couchbase Capella es una DBaaS NoSQL moderna y totalmente gestionada que ofrece flexibilidad de documentos JSON, rendimiento en memoria, funciones de nivel empresarial y capacidades móviles offline e IoT probadas, todo ello con el menor coste total de propiedad.
Capella es polivalente y, como tal, muy adecuada para sustituir a las arquitecturas de persistencia políglota gracias a su amplia gama de servicios y funciones que proporcionan todas las capacidades de las bases de datos polivalentes, combinadas en una única plataforma.
Couchbase Capella proporciona:
-
- Almacenamiento distribuido de documentos JSON - Capella distribuye automáticamente los datos entre nodos y clústeres para escalarlos, y los almacena como documentos JSON para mayor flexibilidad de desarrollo. Obtenga más información sobre la arquitectura distribuida de Capella en este artículo.
- Capacidades relacionales - Capella soporta SQL incluyendo uniones y agregaciones, transacciones ACID y taxonomías de esquema a través de ámbitos y colecciones. Más información sobre el soporte de SQL en Capella aquí.
- Clave-valor, caché en memoria - Capella almacena en caché los datos clave-valor en la memoria para una velocidad vertiginosa. Obtenga más información sobre las funciones de valor clave de Capella en la sección docs.
- Búsqueda de texto completo - Capella proporciona capacidades de búsqueda de texto completo para potenciar las funciones de búsqueda de las aplicaciones. Lea sobre las capacidades de búsqueda de texto completo de Capella en este artículo.
- Búsqueda vectorial - Capella incluye búsqueda vectorial para permitir la búsqueda semántica y RAG para IA. Más información sobre la búsqueda vectorial en Capella aquí.
- Análisis columnar – Capella proporciona un almacén columnar y una amplia integración de datos con Capella DBaaS y otras bases de datos a través de Kafka, lo que permite realizar análisis operativos en tiempo real sin ETL. Obtenga más información sobre el servicio Couchbase Analytics en este blog.
- Series temporales - Capella soporta datos de series temporales para aplicaciones IoT. Para obtener más información sobre la compatibilidad de Capella con series temporales, lea esto blog.
- Recorrido de gráficos - Posibilidad de recorrer gráficos para comprender las relaciones entre entidades y proporcionar más contexto a las indicaciones de la IA. Este blog proporciona detalles sobre las capacidades de Couchbase para recorrer grafos.
- Base de datos móvil integrada - Capella App Services incluye una base de datos integrada para aplicaciones móviles y de IoT que se ejecuta en el dispositivo, eliminando las dependencias de Internet. La sincronización integrada con Capella DBaaS garantiza la coherencia y precisión de los datos. Más información sobre Capella App Services aquí.
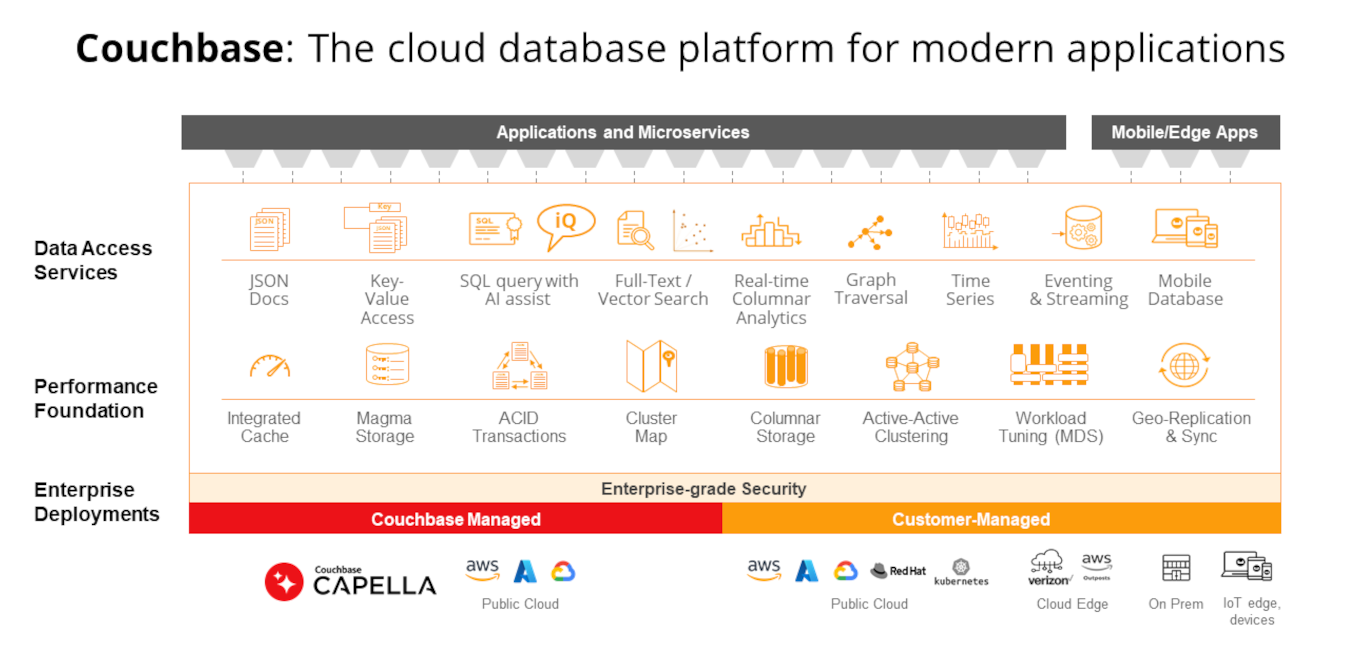
Consolidar en Couchbase Capella
Al proporcionar todas estas capacidades en una sola tecnología de base de datos, Couchbase elimina la necesidad de una multitud de bases de datos de funciones específicas, lo que le permite reducir drásticamente su pila de bases de datos y la huella de datos en general, ahorrándole tiempo, almacenamiento, esfuerzo y dinero.
Viber: ventajas reales de la consolidación de bases de datos
Viber proporciona llamadas de audio y vídeo, mensajería y otros servicios de comunicación a través de su popularísima aplicación, y están creciendo rápidamente. Viber utiliza Couchbase para procesar hasta 15.000 millones de llamadas y mensajes al día. Couchbase actualiza los perfiles de usuario casi en tiempo real, ofreciendo una experiencia de usuario receptiva. Al sustituir MongoDB™ (una Base de datos de documentos NoSQL) y Redis (una base de datos clave-valor en memoria) con un Couchbase, Viber redujo el número de servidores necesarios para alimentar sus aplicaciones de 300 a 120 - un Reducción 60% con ahorro masivo de costes.
Consolide su pila de bases de datos en Couchbase y comience a obtener beneficios en su propia organización. Regístrese para obtener su prueba gratuita de Couchbase Capella aquí.
