Ya sea en las instalaciones o en la nube pública, los clientes de Couchbase tienen un conjunto distinto de necesidades: Transacciones ACID, escrituras de alta durabilidad, alta disponibilidad y alto rendimiento. La arquitectura de Couchbase ayuda a satisfacer estas necesidades a la vez que reduce el dolor para DevOps y DBAs (¡quizás para tomarse un café o una relajante noche libre!). En concreto, el diseño asíncrono y basado en eventos admite una copia activa y hasta tres réplicas, así como la conmutación por error automática dentro de una región. Igualmente, Grupos de servidores es una función integrada que puede utilizarse ampliamente a nivel de bastidor o incluso a nivel de zona de disponibilidad en una nube pública para proporcionar alta disponibilidad, escrituras persistentes y alto rendimiento. Todas estas funciones se combinan para ofrecer flexibilidad y resistencia desde el primer momento.
Cómo combinar clústeres y aprovechar los grupos de servidores
En este blog se muestra cómo utilizar grupos de servidores para combinar clústeres en una base de datos con separación automática para una región dividida en zonas de disponibilidad. Combinar clústeres en tres grupos de servidores distintos dentro de un clúster tiene varias ventajas:
-
- Distribuir las cargas de trabajo entre más nodos ayuda a gestionar más tráfico y una mayor capacidad de datos.
- Permite cumplir el modelo de zona de disponibilidad de la redundancia de conmutación por error y evita los problemas de cerebro dividido.
- Aprovechando la capacidad integrada de auto-failover de Couchbase, los grupos de servidores o zonas de disponibilidad offline serán fallados automáticamente.
- Combinar clusters significa una copia activa de datos o documentos con transacciones multi-documento. Si hay múltiples escrituras y lecturas en el mismo documento/documentos desde múltiples clientes, no hay necesidad de resolución de conflictos. Si es necesario, las escrituras y lecturas pueden ser coherentes con la réplica y la capa persistente y garantizar las transacciones ACID.
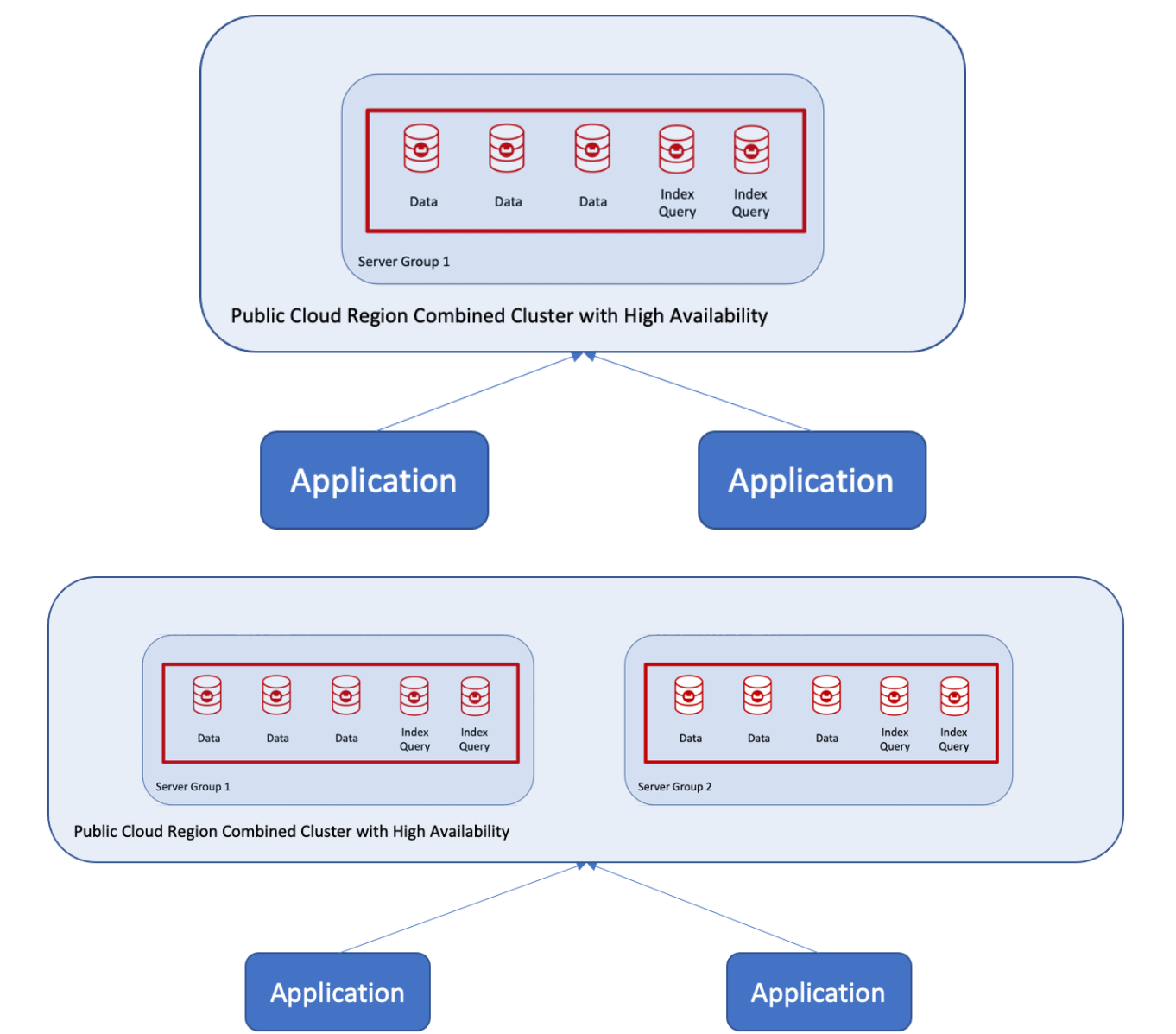
Recientemente tuve la oportunidad de ayudar a un cliente a pasar de dos clústeres con dos aplicaciones interactuando con clústeres separados a uno altamente disponible pero con escrituras duraderas tanto en réplica como en disco. El reto consistía en que cada aplicación escribía en una copia activa dentro del clúster con garantías de escritura, como se ilustra a continuación. 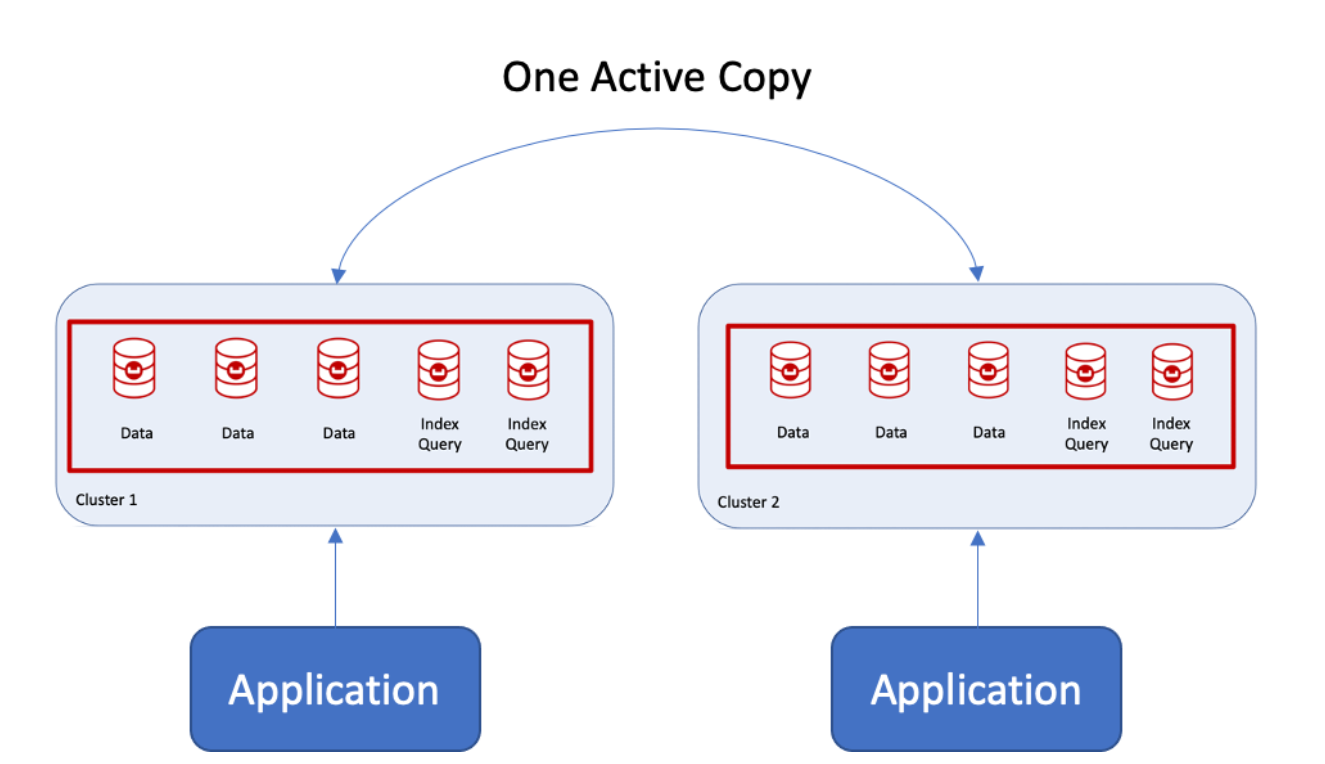
Por garantías de escritura, me refiero a que cada aplicación escribiría en la copia activa, bloquearía los datos y esperaría a que se escribieran en la réplica y en el disco antes de la otra aplicación podría leer/escribir datos. ¿Suena complicado? En realidad no lo es cuando se utiliza Couchbase y grupos de servidores.
El cliente quería un único clúster con auto-failover utilizando la nube pública en una región y con tres zonas de disponibilidad, como se muestra aquí:
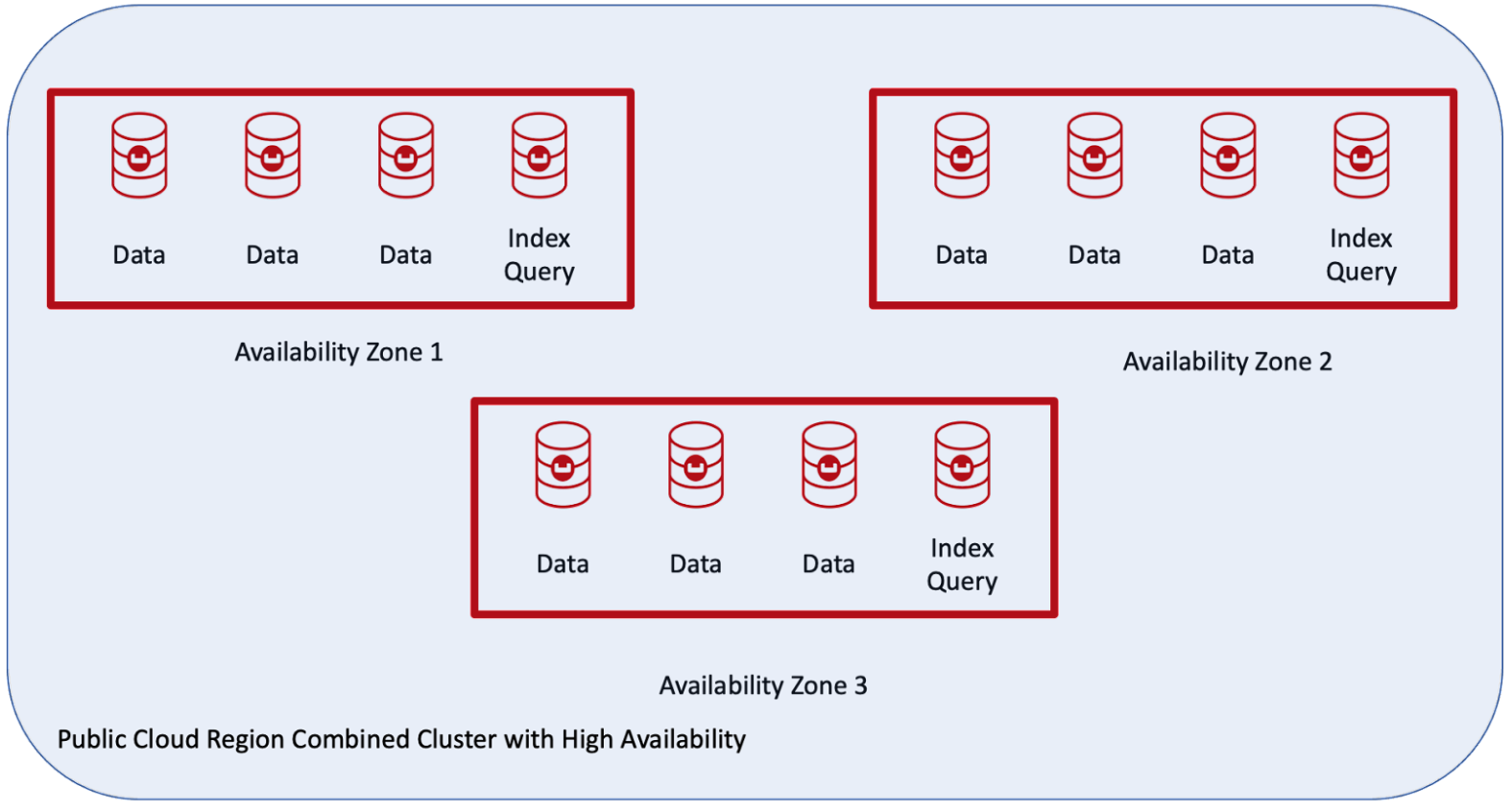
Ventajas de los grupos de servidores Couchbase
La topología anterior tiene las siguientes características compatibles:
-
- Dispone de la función Auto-Failover.
- Es posible una copia activa de los datos y hasta tres réplicas en función del número de nodos del clúster.
- Distribución automática y equilibrada de copias activas y réplicas en todo el clúster.
- Los índices y réplicas de índices se equilibran entre zonas de disponibilidad.
Veamos cómo Couchbase soporta cada una de estas características.
Las regiones de nube pública (o incluso los despliegues locales) requieren auto-failover. Normalmente, en los despliegues locales, los clientes desean distribuir sus máquinas en varios bastidores para evitar la pérdida de datos por un fallo del bastidor, como un fallo de la fuente de alimentación.
Couchbase grupos de servidores es una función en la que las copias activas y réplicas de los datos se distribuyen uniformemente entre los grupos de servidores. Pero los datos activos no residen únicamente en un grupo de servidores/zona de disponibilidad, sino que abarcan todos los grupos de servidores. Se garantiza que la réplica reside en un grupo diferente para cada documento e índice activos.
No hay necesidad de planificar y ordenar los datos; ¡la arquitectura de Couchbase hace el trabajo por ti! ¿Pero por qué tres grupos? Esto es para evitar cualquier escenario de cerebro dividido si un grupo/zona de disponibilidad se cae.
Cómo crear clústeres de alta disponibilidad y alto rendimiento
¿Cuál es el procedimiento recomendado para combinar dos clusters y añadir un tercer grupo de servidores? En realidad no es tan complicado con Couchbase debido al auto sharding, la gestión de réplicas de índices y los grupos de servidores. Como se muestra en la siguiente figura, se utilizan las capacidades de replicación entre centros de datos (XDCR) de un cluster a otro (por ejemplo, Cluster 2) y luego se crea un nuevo Grupo de Servidores.
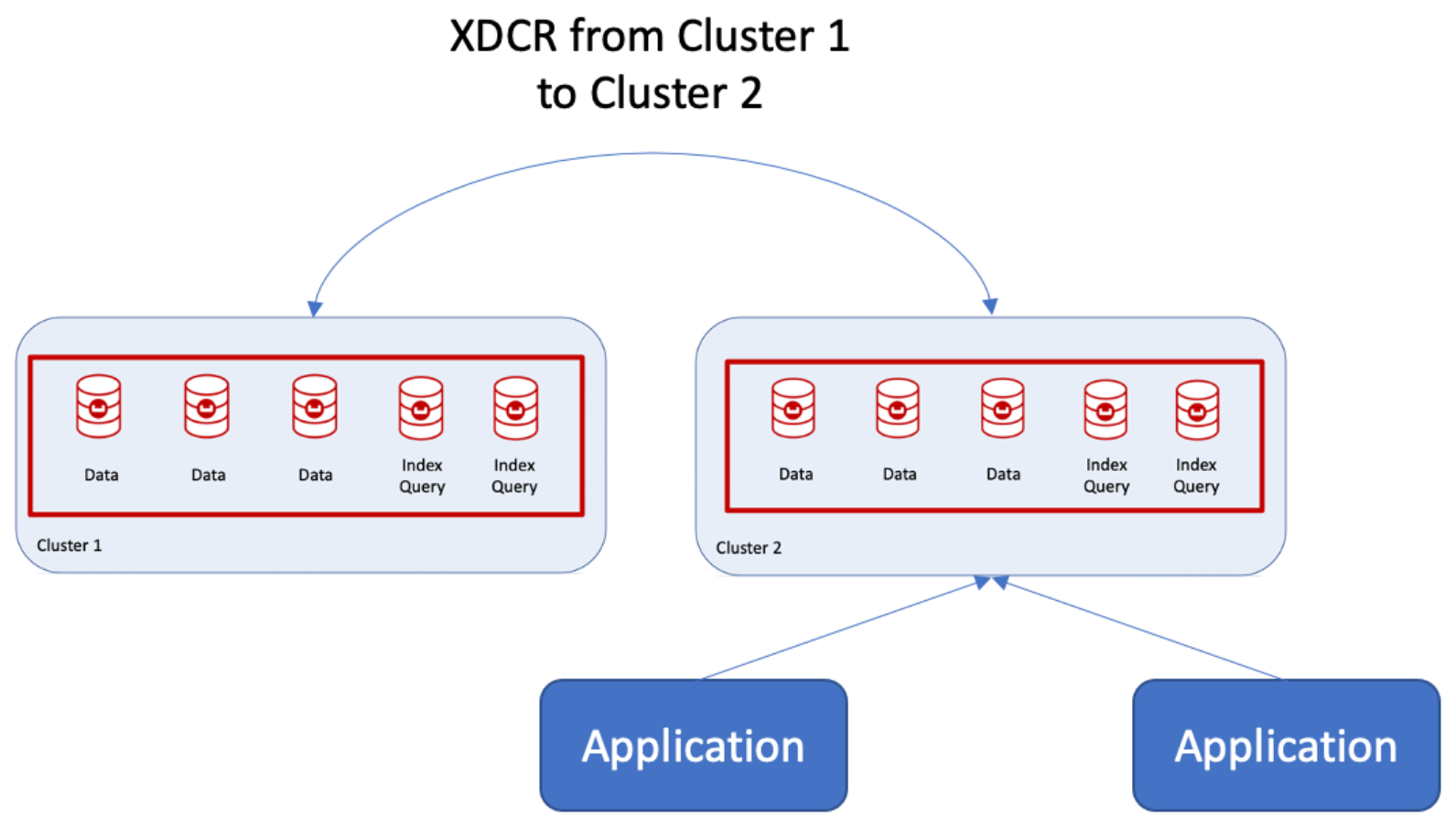
El clúster 2 se convierte en el clúster principal, y esos nodos se declaran como Grupo de servidores 1que Couchbase puede hacer en tiempo de ejecución. 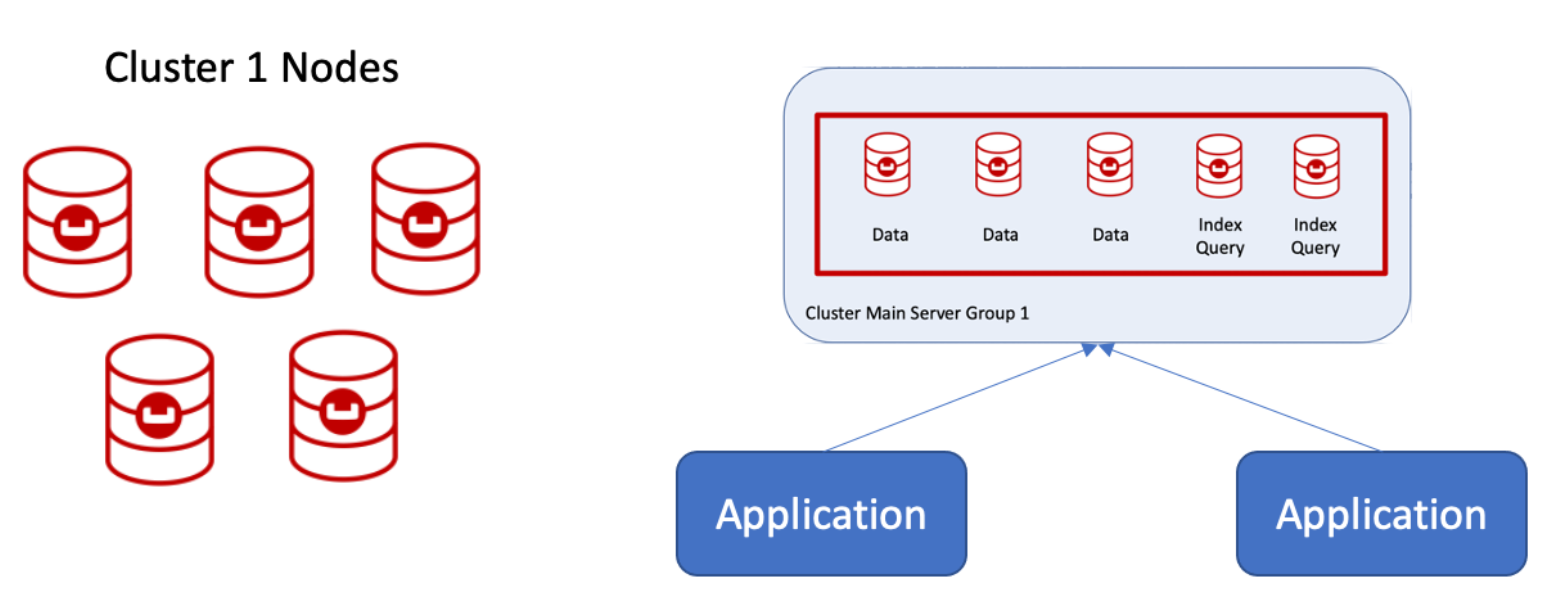 A continuación, pueden añadirse nodos, de uno en uno, para crear el Grupo de servidores 2. Si se trata de un despliegue en una nube pública, también pueden declararse como Grupo de disponibilidad 2.
A continuación, pueden añadirse nodos, de uno en uno, para crear el Grupo de servidores 2. Si se trata de un despliegue en una nube pública, también pueden declararse como Grupo de disponibilidad 2.
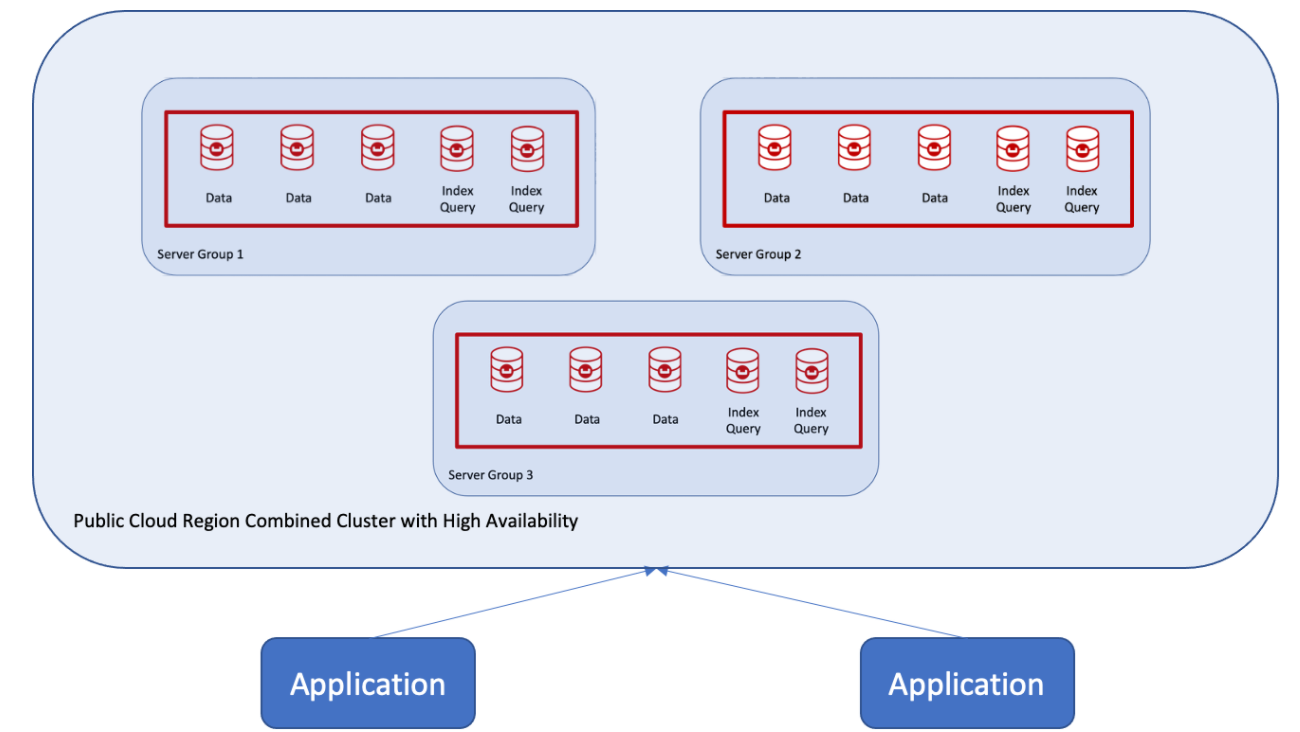 Por último, añada nodos del Grupo de servidores 3 al clúster en la Zona de disponibilidad 3 si se trata de una implantación en una nube pública.
Por último, añada nodos del Grupo de servidores 3 al clúster en la Zona de disponibilidad 3 si se trata de una implantación en una nube pública.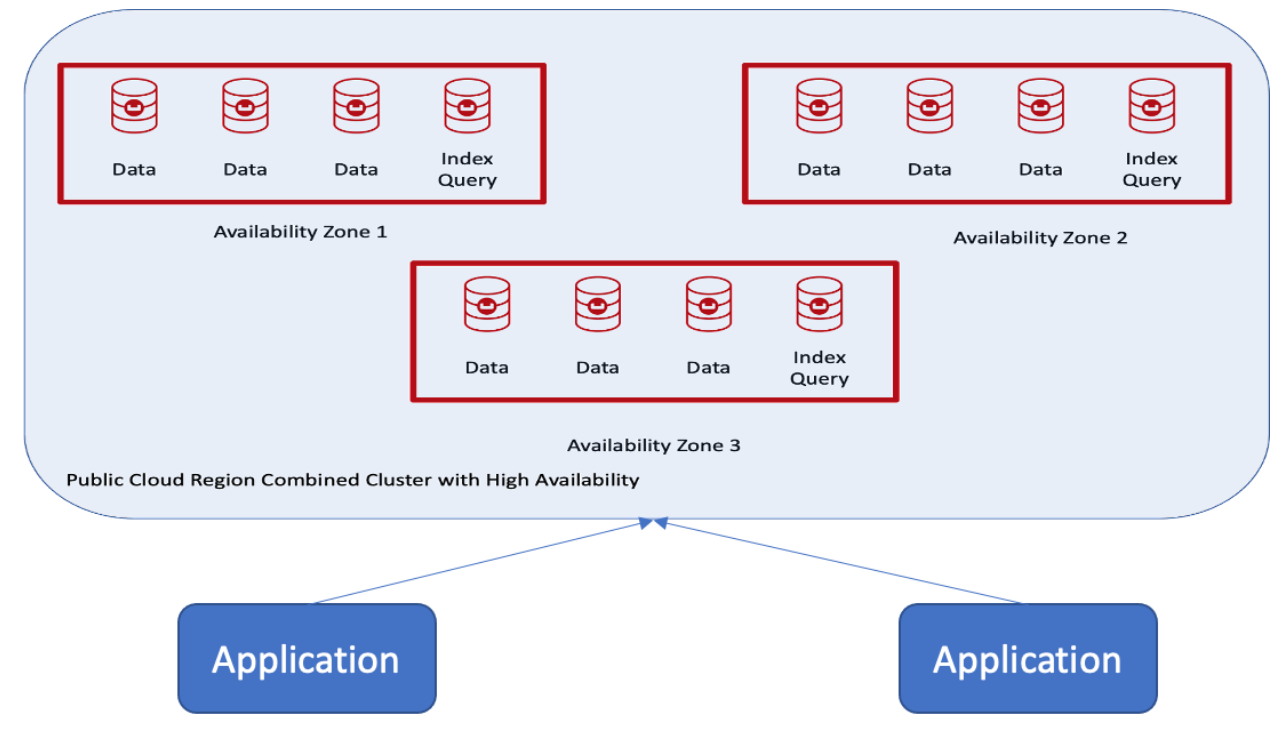
Esto se puede hacer de dos maneras, nodo por nodo con reequilibrio de uno en uno después de cada nodo adicional. O utilizando el reequilibrado después de añadir todos los nodos.
Si añades un nodo al cluster y eliminas un nodo durante el mismo rebalanceo, Couchbase Server hará un "swap rebalance", que puede ser una operación intensiva en recursos con datos e índices moviéndose durante este proceso. Consulte los documentos de reequilibrio y actualización para más información al respecto. Debe hacerse con precaución en un período de tráfico ligero. Esto puede tomar algún tiempo, por lo que planificar en consecuencia.
Pero, ¿necesitamos los dos nodos de índice y consulta en cada región? En realidad, eso depende del tráfico de consultas. Pero si el tráfico de consultas no es intenso, es posible utilizar un nodo de consulta de índices por grupo de servidores.
Objetivos de Couchbase para alta disponibilidad
-
- Couchbase está diseñado para estar operativo el 100% del tiempo, es decir, sin tiempo de inactividad.
- Couchbase es una verdadera base de datos auto-sharded; esto significa que la distribución de datos a través del cluster durante la transición operativa no es un trabajo intensivo para DevOps o Administradores de Base de Datos.
- La función de Grupos de Servidores estaba pensada para Zonas de Disponibilidad-Couchbase garantiza que las copias activas y réplicas de datos e índices no se encuentran en el mismo grupo de servidores.
- Tres grupos de servidores en tres zonas de disponibilidad habilitan la característica de Couchbase de auto-failover basada en un temporizador preestablecido. Auto-failover declarará un nodo o grupo de servidores como fallido y tomará las medidas adecuadas para crear réplicas y enviar el mapa del clúster a los clientes.
Próximos pasos y recursos
Couchbase tiene autonomía incorporada en la arquitectura; así el movimiento de datos e índices es simplificado y automático. Hemos visto por qué combinar clusters es una buena idea y cómo hacerlos 100% tolerantes a fallos. Couchbase es potente porque no hay interrupción de las operaciones: el clúster está operativo todo el tiempo. Las aplicaciones no necesitan ningún cambio de código para interactuar con el clúster. Los cambios en el clúster son gestionados por el mapa de clúster interno del SDK, siendo cualquier cambio transparente para la propia aplicación.
El equipo de diseño y la arquitectura de Couchbase son vanguardistas e incluyen autonomía operativa y auto sharding para crear la base de datos tolerante a fallos óptima para casi cualquier caso de uso.
La siguiente evolución de la automatización es Couchbase Operador autónomo para Kubernetes y OpenShift. Imagina un clúster de autocuración y autoadministración con la ayuda de un operador haciendo el trabajo. Este es el Operador Autónomo de Couchbase. Todo el proceso descrito anteriormente puede ser ejecutado con el operador y un archivo YAML del nuevo cluster final. Realmente es así de simple.
Recursos
Lee los siguientes documentos y páginas para obtener más información sobre clústeres de alta disponibilidad, reequilibrio y mucho más:
-
- Documentos sobre el conocimiento del grupo de servidores Couchbase
- Documentación sobre el reequilibrio de Couchbase
- Uso de la API REST del administrador para reequilibrar un clúster de Couchbase
- Couchbase Operador autónomo para Kubernetes
- Couchbase Cloud NoSQL DBaaS totalmente gestionada (fácil prueba gratuita disponible)
