
Whether on-premises or on the public cloud, Couchbase customers have a distinct set of needs: ACID transactions, high durable writes, high availability and high performance. Couchbase’s architecture helps meet these needs while also reducing pain for DevOps and DBAs (perhaps to have a coffee break or a relaxing night off!). In particular, the event-driven and asynchronous design supports one active copy and up to three replicas and automatic failover within a region. Likewise, Server Groups is a built-in feature that can be broadly used at the rack level or even the availability zone level in a public cloud to provide high availability, persistent writes and high performance. All of these features combine to give flexibility and resilience out of the box.
How to combine clusters and leverage server groups
This blog shows you how to use server groups to combine clusters into one auto-sharded database for a region split into availability zones. Combining clusters into three distinct server groups within a cluster has several advantages:
- Distributing workloads across more nodes helps handle more traffic and larger data capacity.
- Allows you to meet the availability zone model of failover redundancy and prevents split-brain issues.
- Leveraging Couchbase’s built-in auto-failover capability, offline server groups or availability zones will be failed over automatically.
- Combining clusters means one active copy of data or documents with multi-document transactions. If there are multiple writes and reads to the same document/documents from multiple clients, there’s no need for conflict resolution. If necessary, writes and reads can be consistent with the replica and the persistent layer and ensure ACID transactions.
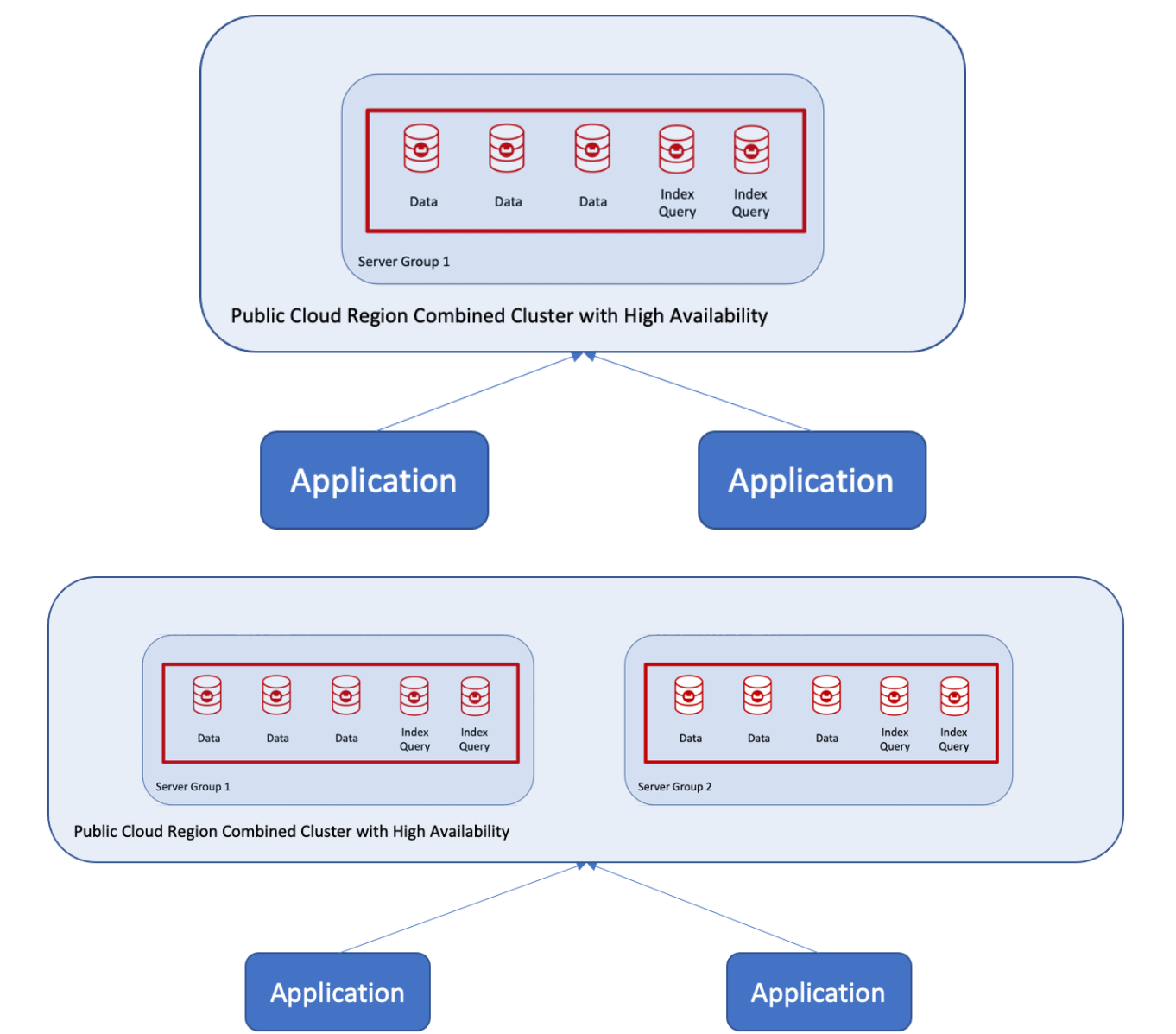
I recently had the opportunity to help a customer move from two clusters with two applications interacting with separate clusters into one highly available but with durable writes to both replica and disk. The challenge was that each application wrote to one active copy within the cluster with write guarantees, illustrated below. 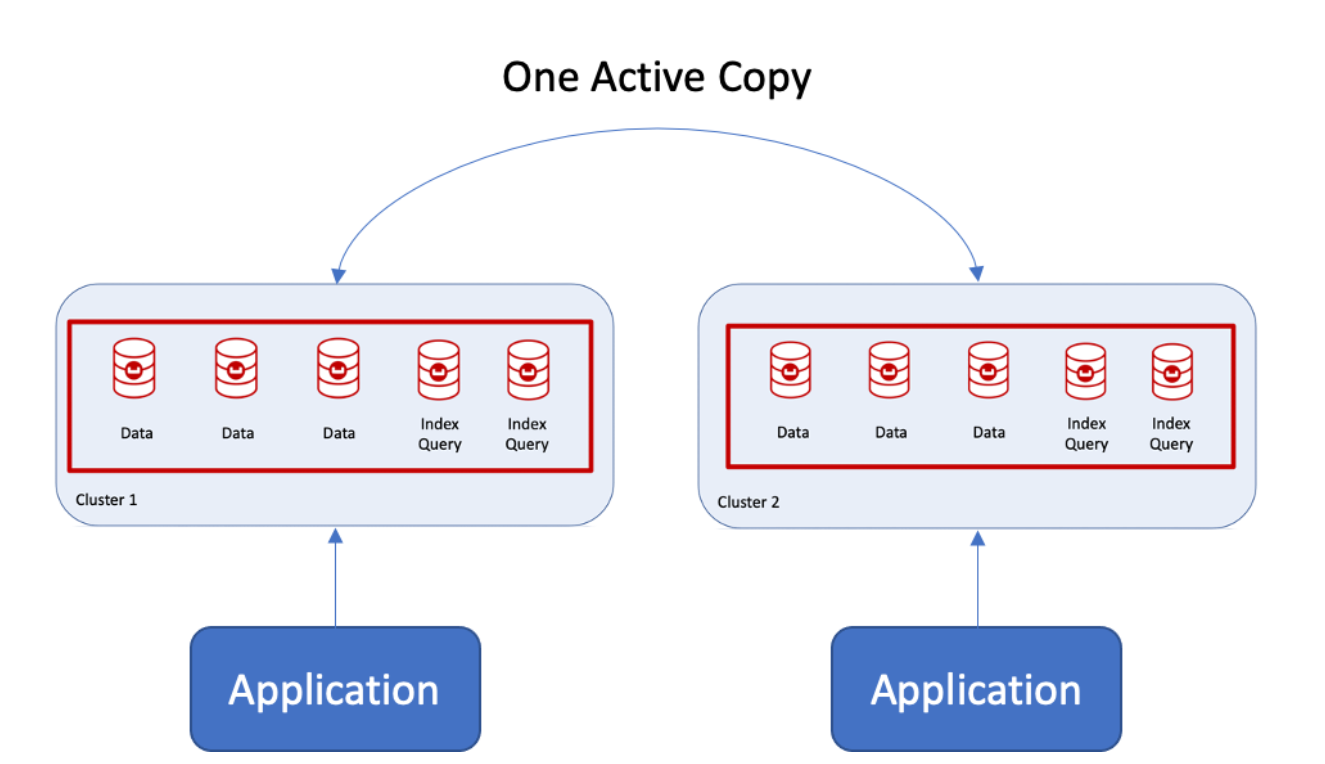
By write guarantees, I mean each application would write to the active copy, lock the data and wait for the replica and disk to be written before the other application could read/write data. Does that sound complicated? It isn’t really when using Couchbase and server groups.
The customer wanted a single cluster with auto-failover using the public cloud in one region and with three availability zones, as shown here:
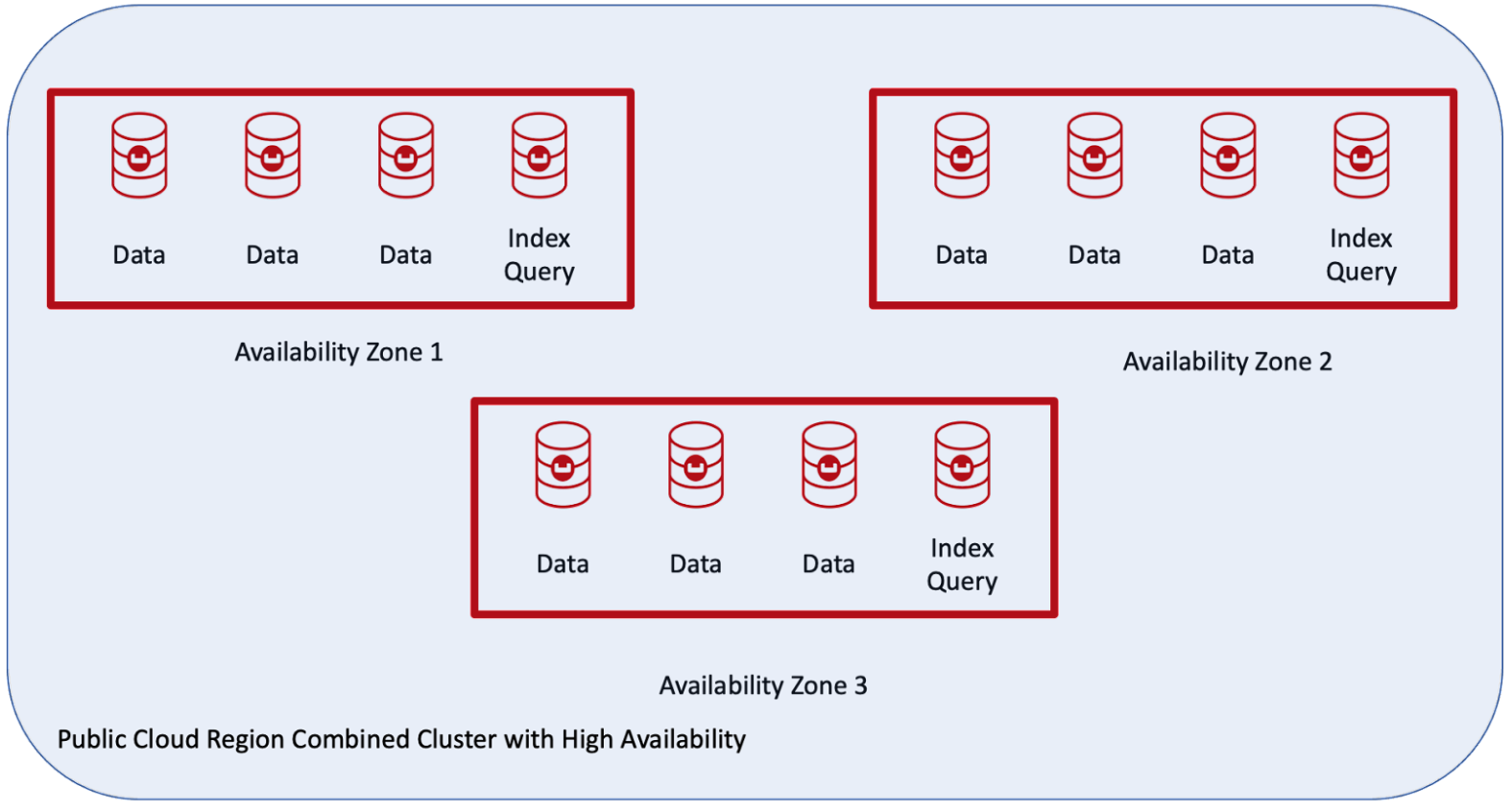
Benefits of Couchbase Server Groups
The topology above has the following supported features:
- Auto-Failover capability is available.
- One active copy of data and up to three replicas is possible depending on the number of nodes in the cluster.
- Balanced, automatic distribution of active and replica copies across the entire cluster.
- Indexes and replica indexes are balanced across availability zones.
Let’s see how each of these features is supported by Couchbase.
Public cloud regions (or even on-premises deployments) require auto-failover. Typically, with on-premises deployments, customers want to spread their machines across multiple racks to prevent data loss from a rack failure such as a power supply failure.
Couchbase server groups is a feature in which active and replica copies of data are evenly distributed across server groups. But the active data doesn’t reside solely in one server group/availability zone but spans all the server groups. The replica is guaranteed to reside in a different group for each active document and index.
There’s no need to plan and sort data; Couchbase’s architecture does the work for you! But why three groups? This is to avoid any split-brain scenarios if a group/availability zone should go down.
How to create high availability, high-performance clusters
What is the recommended procedure for combining two clusters and adding a third server group? It’s actually not that complicated with Couchbase because of auto sharding, index replica management and server groups. As shown in the following figure, you use the cross datacenter replication (XDCR) capabilities from one cluster to another (e.g., Cluster 2) and then create a new Server Group.
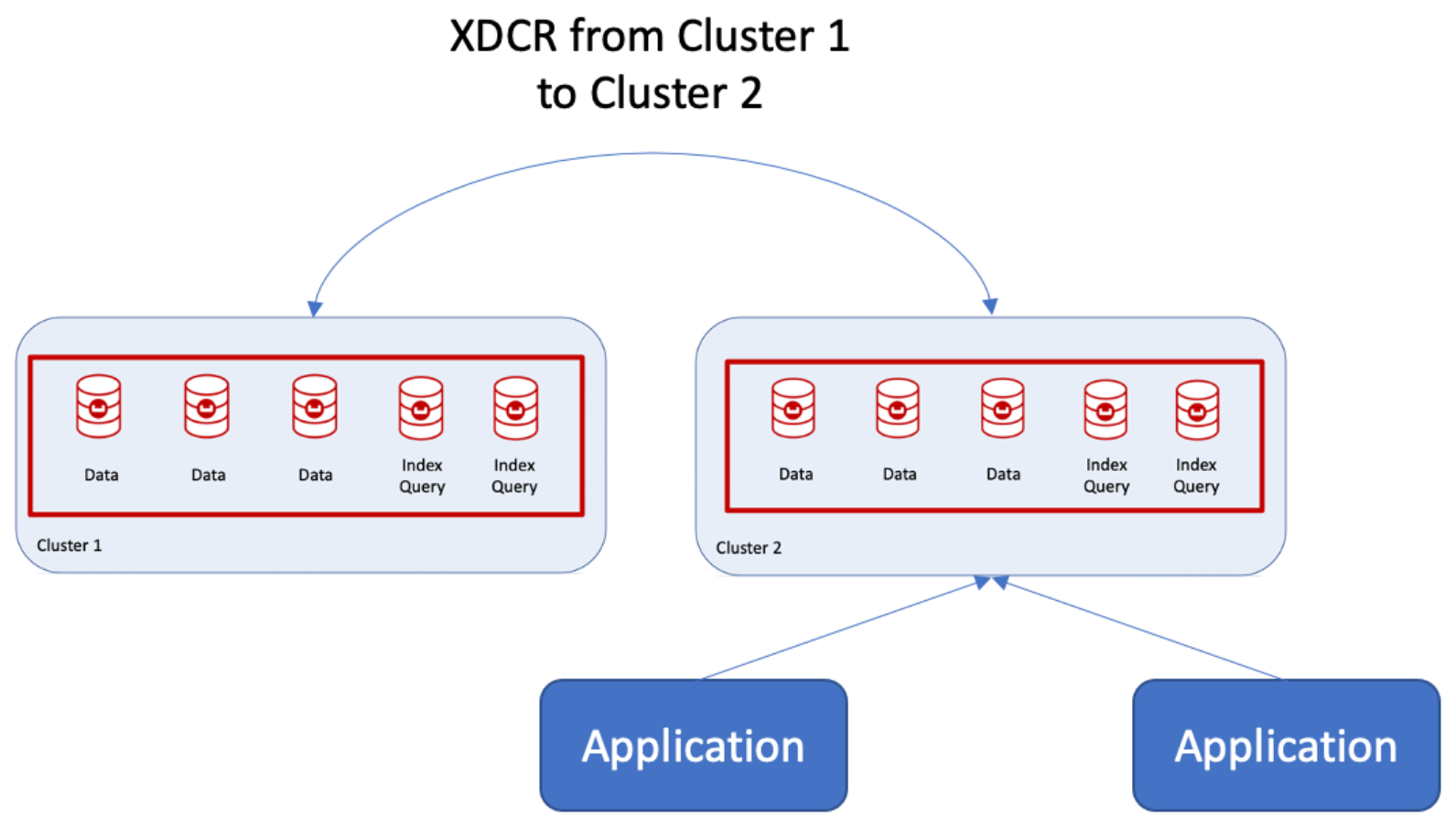
Cluster 2 becomes the main cluster, and those nodes are declared as Server Group 1, which Couchbase can do at run time! 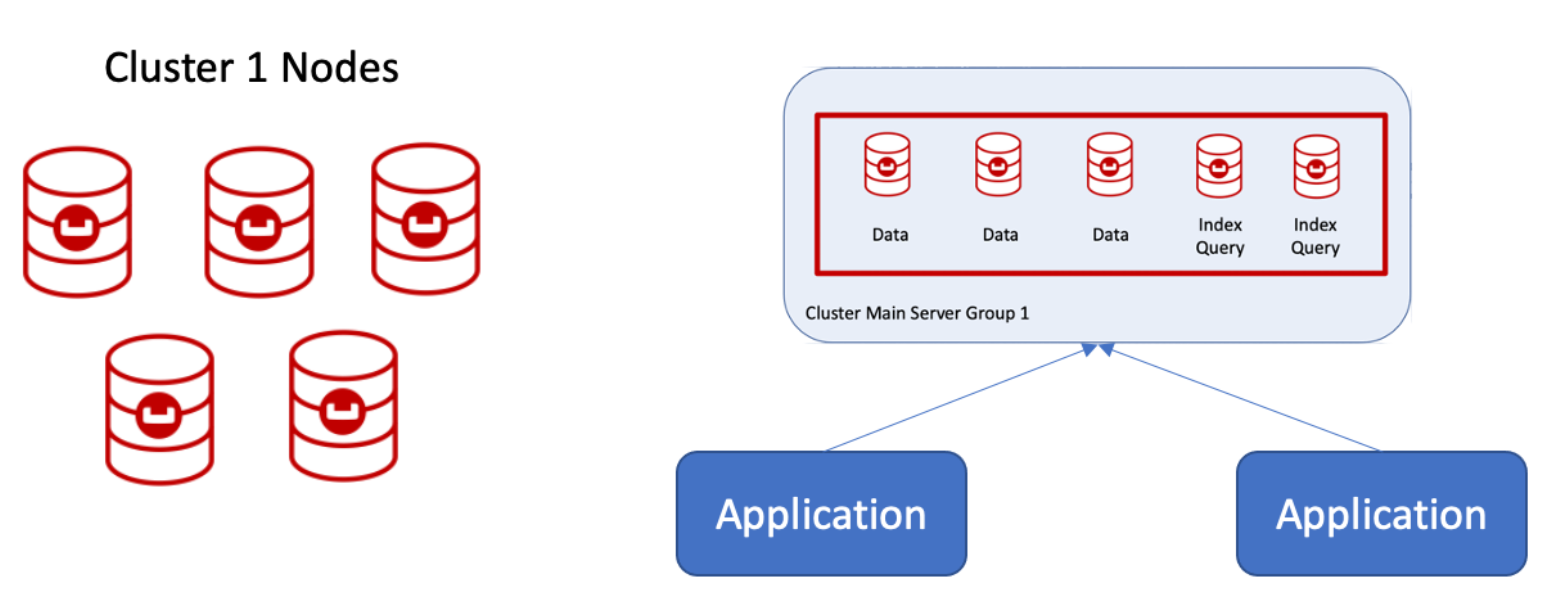 Nodes can then be added, one at a time, to create Server Group 2. If this is a public cloud deployment, they can also be declared as Availability Group 2.
Nodes can then be added, one at a time, to create Server Group 2. If this is a public cloud deployment, they can also be declared as Availability Group 2.
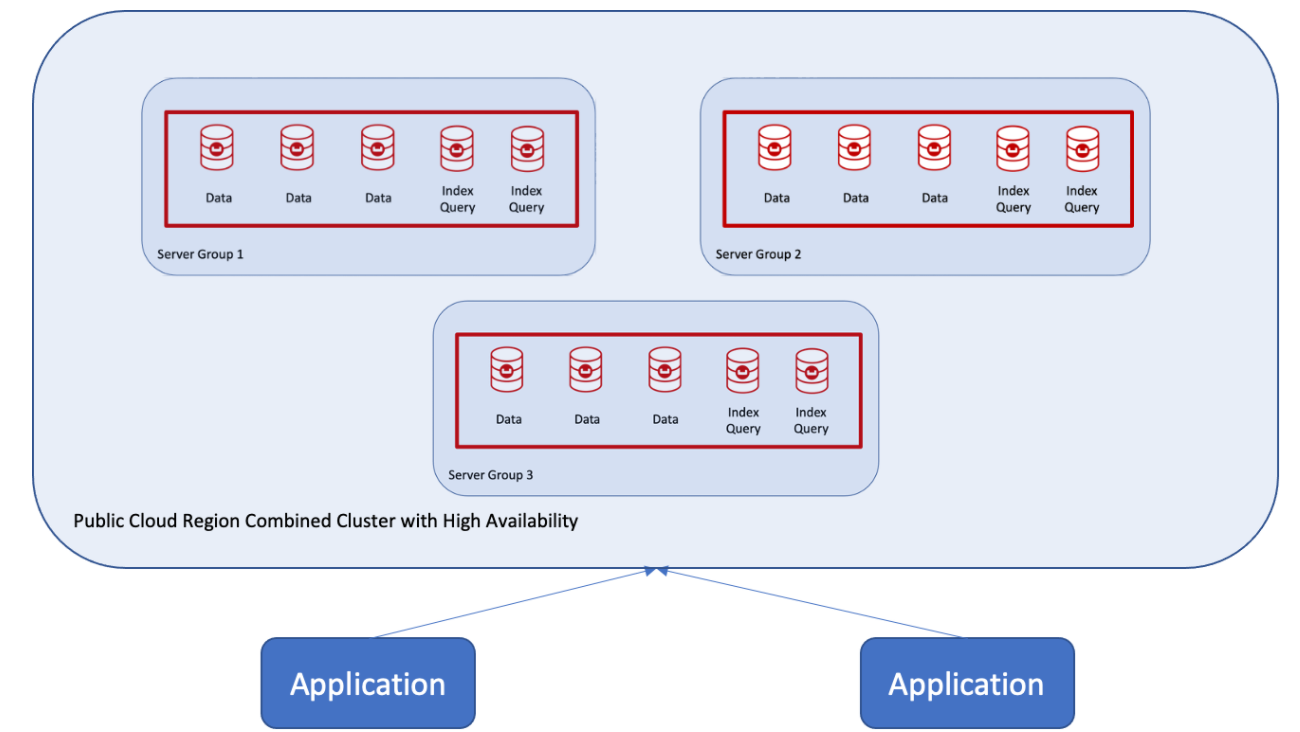 Finally, add Server Group 3 nodes into the cluster in Availability Zone 3 if in a public cloud deployment.
Finally, add Server Group 3 nodes into the cluster in Availability Zone 3 if in a public cloud deployment.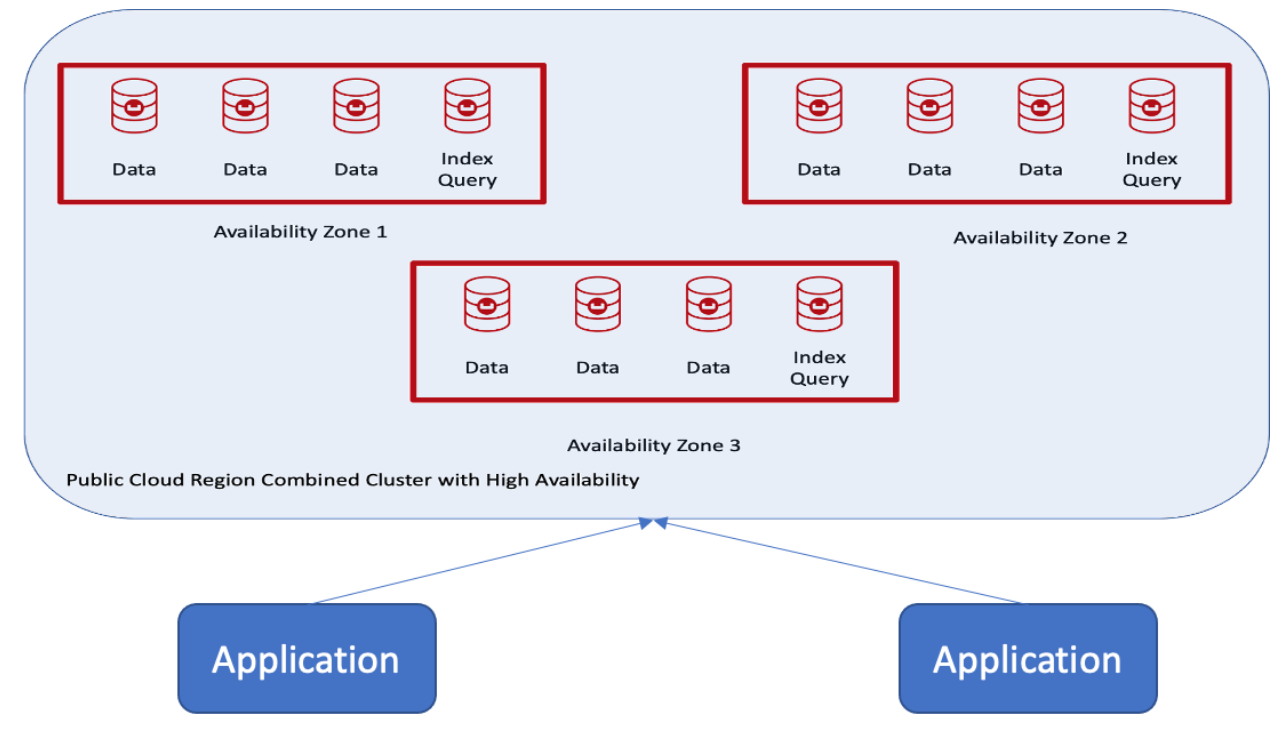
This can be done two ways, node by node with one at a time rebalancing after each additional node. Or using rebalancing after adding all nodes.
If you add one node to the cluster and remove a node during the same rebalance, Couchbase Server will do a “swap rebalance,” which can be a resource-intensive operation with data and indexes moving during this process. See the rebalancing and upgrading docs for more info on this. It should be done with caution in a light traffic period. This can take some time, so plan accordingly.
But do we need all two index and query nodes in every region? Actually, that depends on the query traffic. But if the query traffic is not heavy, it is possible to use one index query node per server group.
Couchbase goals for high availability
- Couchbase is designed to be operational 100% of the time, i.e., no downtime.
- Couchbase is a true auto-sharded database; this means that data distribution across the cluster during the operational transition is not intensive work for DevOps or Database Administrators.
- The Server Groups feature was meant for Availability Zones–Couchbase guarantees that active and replica copies of data and indexes are not in the same server group.
- Three server groups in three availability zones enables Couchbase’s feature of auto-failover based on a preset timer. Auto-failover will declare a node or server group as failed and take the appropriate steps to create replicas and push the cluster map to the clients.
Next steps and resources
Couchbase has autonomy built into the architecture; thus movement of data and indexes is simplified and automatic. We looked at why combining clusters is a good idea and how to make them 100% fault-tolerant. Couchbase is powerful because there is no interruption of operations–the cluster is operational the entire time. Applications do not need any code changes to interact with the cluster. Cluster changes are handled by the SDK’s internal cluster map, with any changes being transparent to the application itself.
Couchbase’s design team and architecture are forward-thinking to include operational autonomy and auto sharding to create the optimal fault-tolerant database for almost any use case.
The next evolution of automation is Couchbase’s Autonomous Operator for Kubernetes and OpenShift. Imagine a self-healing and self-administering cluster with the help of an operator doing the work. This is the Couchbase Autonomous Operator. The process described above can all be executed with the operator and a YAML file of the new final cluster. It really is that simple.
Resources
Read up on the following docs and pages to learn more about high availability clusters, rebalancing and more:
Leave a comment
You must be logged in to post a comment.