¿Cuándo fue la última vez que utilizó una base de datos? La mayoría de nosotros estamos tan acostumbrados a interfaces fáciles de usar como TikTok, aplicaciones bancarias y programas de trabajo que no nos damos cuenta de que estamos interactuando con bases de datos todo el tiempo. Incluso somos menos propensos a pensar en lo que ocurre entre bastidores, que puede dividirse en dos tipos de actividad: transaccional y analítica. Una transacción puede ser subir un vídeo o hacer una compra. El análisis de datos puede ser tan sencillo como hacer números en una hoja de cálculo.
En un base de datos relacionalLos datos de cualquier tipo de actividad se organizan en filas y columnas que forman una tabla (o tablas) para mostrar la relación entre los puntos de datos. Los datos pueden almacenarse de dos formas distintas: En una base de datos por columnas (column store), todos los datos se agrupan por columnas. En una base de datos por filas, todos los datos se agrupan por filas.
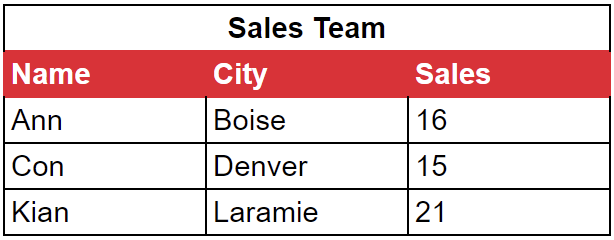
Las bases de datos columnares son excelentes cargas de trabajo analíticasLas bases de datos orientadas a filas son más adecuadas para cargas de trabajo transaccionales. Para explicar las diferencias y discutir los pros y los contras relativos, utilizaremos los datos de esta tabla que hace el seguimiento de un equipo de ventas:
¿Qué es una base de datos columnar?
Una base de datos columnar almacena los datos agrupados por columnas en lugar de por filas, lo que optimiza el rendimiento de las consultas analíticas. Cada columna contiene datos del mismo tipo, lo que permite una compresión eficaz. Y como una consulta sólo necesita acceder a las columnas relevantes, el diseño mejora la velocidad de recuperación de los datos.
Mientras que una base de datos columnar es un tipo de base de datos relacional, Couchbase Capella™ es un NoSQL DBaaS que también utiliza la agrupación de columnas para realizar análisis ultrarrápidos. Lo hace ingiriendo rápidamente JSON y otras fuentes de datos y convirtiéndolos en almacenamiento en columnas.
Escritura en bases de datos de columnas
En una base de datos columnar, los datos se escriben en el disco por columnas. Eso significa que los datos de nuestro equipo de ventas se agruparían y almacenarían así:
|
1 |
Ann Con Kian | Boise Denver Laramie | 16 15 21 |
Vamos a añadir el siguiente registro para un nuevo empleado, Gene:

Para añadir los datos de Gene, los añadimos al final de las columnas respectivas de la siguiente manera:
|
1 |
Ann Con Kian Gene | Boise Denver Laramie Hanford | 16 15 21 0 |
Lectura de bases de datos de columnas
En una base de datos columnar, los datos se leen accediendo a columnas específicas en lugar de a filas enteras. Cuando se ejecuta una consulta, la base de datos recupera sólo las columnas necesarias para cumplir las condiciones de la consulta. Este proceso implica acceder directamente a los datos de las columnas relevantes, lo que puede reducir significativamente la sobrecarga de E/S y mejorar el rendimiento de las consultas, especialmente para cargas de trabajo analíticas que suelen implicar agregaciones, filtrados y proyecciones selectivas.
Al leer sólo las columnas necesarias, las bases de datos columnares minimizan la transferencia de datos y maximizan la utilización de la caché de la CPU. Para las consultas analíticas, esto se traduce en tiempos de ejecución de consultas más rápidos en comparación con las bases de datos orientadas a filas.
Por ejemplo, si quisiéramos calcular el número medio de ventas de todo el equipo de ventas, una base de datos en columnas sólo tendría que acceder a la columna con las cifras de ventas. Esto sería mucho más rápido y eficiente que una base de datos orientada a filas, que tendría que acceder a todos los datos fila por fila para extraer los datos de ventas relevantes.
¿Qué es una base de datos de almacenamiento por filas?
Una base de datos orientada a filas organiza los datos por filas, y cada fila contiene información sobre una única entidad o registro. Este diseño es adecuado para cargas de trabajo transaccionales en las que se accede o se modifican con frecuencia filas enteras. Las bases de datos orientadas a filas destacan en los sistemas de procesamiento de transacciones, donde pueden garantizar inserciones, actualizaciones y eliminaciones rápidas almacenando los datos de forma contigua en el disco para minimizar la sobrecarga de las operaciones a nivel de fila.
Escritura en bases de datos de almacenamiento por filas
En una base de datos de almacenamiento por filas, los datos se escriben en el disco por filas en lugar de por columnas.
Los datos de nuestro equipo de ventas se almacenarían así:
|
1 |
Ann Boise 16 | Con Denver 15 | Kian Laramie 21 |
Para añadir el registro de Gene, lo anexaríamos en su totalidad al final de los datos existentes de la siguiente manera:
|
1 |
Ann Boise 16 | Con Denver 15 | Kian Laramie 21 | Gene Hanford 0 |
Este enfoque garantiza que todos los atributos de los registros se almacenen juntos, lo que facilita la recuperación y actualización rápidas de filas enteras. Además, las bases de datos orientadas a filas suelen utilizar mecanismos de registro y almacenamiento en búfer para optimizar las operaciones de escritura.
Lectura de bases de datos de almacenamiento por filas
En una base de datos de almacenamiento por filas, los datos se leen accediendo a filas enteras de forma secuencial o mediante búsquedas en índices. Cuando se ejecuta una consulta, la base de datos recupera las filas pertinentes que contienen los datos solicitados. Este proceso de recuperación implica escanear las filas en el disco y obtener registros completos que coincidan con los criterios de la consulta. Aunque las bases de datos orientadas a filas son excelentes a la hora de recuperar registros completos con rapidez, pueden incurrir en sobrecarga cuando sólo se necesitan columnas específicas. Dado que las filas deben recuperarse en su totalidad, esto puede dar lugar a transferencias y procesamientos de datos innecesarios.
Base de datos en columnas frente a base de datos en filas
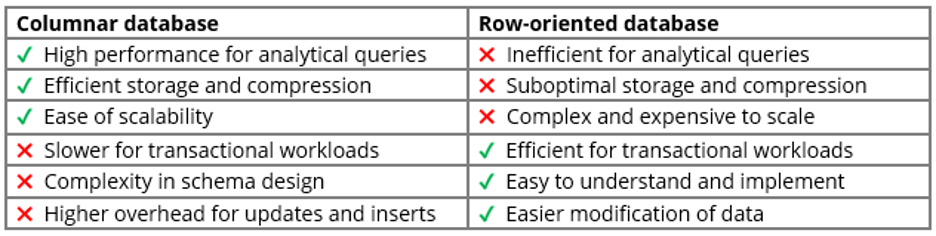
Las bases de datos columnares y las orientadas a filas presentan ventajas e inconvenientes relacionados con la organización de los datos. Las bases de datos columnares destacan en las consultas analíticas y proporcionan un almacenamiento eficiente, pero pueden tener problemas con las cargas de trabajo transaccionales y son más difíciles de actualizar. Por el contrario, las bases de datos orientadas a filas son eficientes para cargas de trabajo transaccionales y más fáciles de implementar y modificar, pero son ineficientes para consultas analíticas y ofrecen un almacenamiento subóptimo. Aquí tienes un desglose más detallado de sus pros y sus contras:
Ventajas de las bases de datos en columnas
-
- Alto rendimiento para consultas analíticas - Las bases de datos columnares destacan en las cargas de trabajo analíticas de lectura intensiva, ya que ofrecen tiempos de procesamiento de consultas rápidos gracias a su capacidad para leer sólo las columnas necesarias. Esto maximiza la utilización de la caché de la CPU y minimiza la sobrecarga de E/S.
- Almacenamiento y compresión eficientes - Los datos se organizan por columnas, lo que permite aplicar técnicas de compresión eficaces. Los tipos de datos y propiedades similares dentro de las columnas permiten elevados ratios de compresión para reducir los costes de almacenamiento y mejorar el rendimiento de las consultas.
- Facilidad de ampliación - Las bases de datos columnares son ventajosas para la escalabilidad. Dado que los datos se almacenan en columnas, añadir nodos o servidores adicionales puede resultar sencillo, ya que cada nodo gestiona un subconjunto de columnas. Esta escalabilidad es especialmente beneficiosa para las cargas de trabajo analíticas, en las que los conjuntos de datos suelen ser grandes y crecer constantemente.
Contras de las bases de datos en columnas
-
- Más lenta para cargas de trabajo transaccionales. Aunque las bases de datos columnares destacan en las consultas analíticas, su rendimiento puede ser más lento en las cargas de trabajo transaccionales de escritura pesada que implican actualizaciones, inserciones y eliminaciones frecuentes.
- Complejidad en el diseño de esquemas - El diseño de un esquema para una base de datos columnar puede requerir una cuidadosa consideración de la organización de las columnas y los tipos de datos para optimizar el rendimiento de las consultas y la eficiencia del almacenamiento.
- Mayor sobrecarga para actualizaciones e inserciones - La actualización o inserción de datos en una base de datos en columnas puede ser más compleja y consumir más recursos que en las bases de datos en filas. Las bases de datos en columnas pueden requerir un procesamiento adicional para mantener la coherencia de los datos y garantizar un almacenamiento eficiente.
Ventajas de las bases de datos por filas
-
- Eficaz para cargas de trabajo transaccionales - Las bases de datos orientadas a filas son idóneas para cargas de trabajo transaccionales en las que es necesario recuperar, actualizar o insertar registros completos de forma rápida y eficaz. La estructura de almacenamiento basada en filas simplifica estas operaciones y garantiza un procesamiento rápido de las transacciones.
- Fácil de entender y aplicar - El modelo de almacenamiento orientado a filas se alinea con la comprensión intuitiva de la organización de datos, lo que facilita el diseño, la implementación y el mantenimiento de bases de datos que utilizan este enfoque. Los desarrolladores familiarizados con las bases de datos relacionales encuentran sencillo trabajar con bases de datos orientadas a filas.
- Modificación más fácil de los datos - Las bases de datos orientadas a filas facilitan la modificación de los datos, ya que permiten actualizaciones, inserciones y eliminaciones directas sin una sobrecarga significativa. Esto las hace adecuadas para escenarios con frecuentes operaciones de escritura o requisitos de datos cambiantes.
Contras de las bases de datos por filas
-
- Ineficiente para consultas analíticas - Las bases de datos orientadas a filas pueden mostrar un rendimiento más lento en las consultas analíticas de lectura pesada que implican agregaciones, proyecciones y filtrado. Recuperar filas enteras para este tipo de consultas puede suponer una transferencia de datos y una sobrecarga de procesamiento innecesarias, lo que reduce el rendimiento de las consultas en comparación con las bases de datos columnares.
- Almacenamiento y compresión subóptimos - El almacenamiento de datos en filas puede dar lugar a ratios de compresión subóptimos en comparación con las bases de datos en columnas. En las bases de datos orientadas a filas, éstas suelen contener diversos tipos de datos y propiedades, lo que dificulta la consecución de altos niveles de compresión y un almacenamiento eficiente.
- Complejos y caros de ampliar - Dado que las bases de datos orientadas a filas deben almacenar los datos en filas, puede resultar más complicado distribuir los datos eficazmente entre varios servidores y nodos. La solución suele pasar por añadir hardware más potente, como aumentar los recursos de CPU o memoria en los servidores existentes, lo que puede resultar prohibitivo a medida que crece el conjunto de datos.
Ejemplos de bases de datos en columnas
Algunas bases de datos columnares muy conocidas son:
-
- Amazon Redshift
- Apache Cassandra
- Almacén de columnas MariaDB
- Copo de nieve
Ejemplos de bases de datos por filas
Dos de las bases de datos orientadas a filas más comunes son:
-
- PostgreSQL
- MySQL
Por qué las bases de datos en columnas son mejores para el análisis
Las bases de datos columnares superan a las orientadas a filas en el análisis, principalmente por su eficacia en el almacenamiento y la recuperación de datos. He aquí cuatro formas en las que son mejores:
Estructura de almacenamiento en columnas - Como los datos se almacenan por columnas y no por filas, cada columna puede almacenarse por separado en el disco. Esta estructura permite aplicar mejores técnicas de compresión y codificación a cada columna por separado. Dado que las columnas suelen contener tipos de datos, valores o propiedades similares, los algoritmos de compresión pueden alcanzar mayores ratios de compresión en comparación con las bases de datos orientadas a filas, en las que éstas pueden contener datos diversos.
Recuperación selectiva - Las consultas analíticas suelen implicar la agregación o el análisis de un subconjunto de columnas en lugar de filas enteras. Las bases de datos columnares destacan en este tipo de situaciones porque pueden recuperar selectivamente sólo las columnas necesarias para la consulta. Esta recuperación selectiva minimiza las operaciones de E/S en disco y maximiza la utilización de la caché de la CPU. Por el contrario, las bases de datos orientadas a filas recuperan filas enteras incluso para consultas que sólo necesitan unas pocas columnas, lo que supone una transferencia de datos y una sobrecarga de procesamiento innecesarias.
Eficacia del tratamiento de datos - Al ejecutar consultas analíticas, las bases de datos columnares operan directamente sobre datos columnares comprimidos, lo que permite un procesamiento eficiente de funciones analíticas como agregaciones, filtrados y proyecciones. Dado que los tipos de datos similares se almacenan de forma contigua, las bases de datos en columnas pueden explotar el paralelismo SIMD (instrucción única, datos múltiples) y otras técnicas de procesamiento vectorial, lo que permite tiempos de ejecución de consultas más rápidos. En cambio, las bases de datos orientadas a filas pueden tener que descomprimir filas enteras antes de realizar operaciones analíticas, lo que puede suponer una mayor sobrecarga computacional.
Optimización de consultas - Las bases de datos columnares se optimizan para el análisis mediante estrategias de ejecución de consultas adaptadas a su formato de almacenamiento. Estas optimizaciones incluyen poda de columnas, pushdown de predicados y técnicas de procesamiento vectorial. La poda de columnas elimina las lecturas de columnas innecesarias durante la ejecución de la consulta, mientras que el pushdown de predicados filtra las filas al principio del proceso de consulta, reduciendo la cantidad de datos que hay que procesar. Las técnicas de procesamiento vectorial operan sobre lotes de datos, aprovechando el paralelismo de la CPU para mejorar el rendimiento de las consultas.
Conclusión
Mientras que las bases de datos orientadas a filas son mejores para el procesamiento transaccional, las bases de datos columnares son superiores para el procesamiento analítico. Las ventajas de una base de datos orientada a filas residen en su capacidad para realizar inserciones, actualizaciones y eliminaciones rápidas. Por otro lado, las principales ventajas de una base de datos columnar son la compresión eficiente y el procesamiento rápido de consultas. Al organizar los datos por columnas y emplear estrategias de ejecución de consultas especializadas, las bases de datos columnares pueden gestionar grandes cargas de trabajo analíticas y consultas complejas con tiempos de respuesta de consulta más rápidos y un mejor rendimiento general.
Recursos relacionados
Obtenga más información sobre cómo elegir la base de datos adecuada para sus cargas de trabajo analíticas:
-
- Tipos de bases de datos
- ¿Qué es el análisis de macrodatos?
- Comparación entre bases de datos documentales y bases de datos relacionales
- Comparación NoSQL: MongoDB vs. DynamoDB vs. Couchbase
- Couchbase Analytics añade un servicio de datos en tiempo real
- Comparación entre Couchbase Capella y Cosmos DB
- Base de datos frente a almacén de datos: Diferencias, casos de uso, ejemplos
- Pruebe gratis Couchbase Capella DBaaS
