Couchbase Capella ha lanzado un Avance privado de los servicios de IA¡! Echa un vistazo este blog para obtener una visión general de cómo estos servicios simplifican el proceso de creación de aplicaciones y agentes de IA escalables y nativos de la nube.
En este blog exploraremos Modelo de servicio - una función de Capella que le permite desplegar modelos lingüísticos privados y modelos de incrustación de forma segura y a escala. Este servicio permite que la inferencia se ejecute cerca de sus datos para mejorar el rendimiento y el cumplimiento.
¿Por qué utilizar el Servicio Modelo Capella?
Muchas empresas se enfrentan a problemas de seguridad y cumplimiento cuando desarrollan agentes de IA. Debido a normativas como GDPR y protección de la información personalA menudo, las empresas no pueden utilizar modelos lingüísticos abiertos ni almacenar datos fuera de su red interna. Esto limita su capacidad para explorar soluciones basadas en IA.
En Servicio Modelo Capella aborda esta cuestión simplificando las complejidades operativas de la implantación de un modelo de lenguaje privado dentro de la misma red interna que el clúster del cliente.
Esto asegura:
-
- Datos utilizados para la inferencia nunca abandona los límites de la red virtual del clúster operativo
- Inferencia de baja latencia debido a la mínima sobrecarga de la red
- Conformidad con las políticas de seguridad de datos de la empresa
Características principales del Servicio Modelo Capella
-
- Despliegue seguro del modelo - Ejecutar modelos en un entorno seguro y aislado
- API y SDK compatibles con OpenAI - Invoca fácilmente modelos alojados en Capella con bibliotecas y marcos compatibles con OpenAI, como Langchain.
- Mejoras de rendimiento - Incluye ofertas de valor añadido de almacenamiento en caché y por lotes para mayor eficacia
- Herramientas de moderación - Proporciona funciones de moderación de contenidos y filtrado de palabras clave
Primeros pasos: implantar y utilizar un modelo en Capella
Veamos un sencillo tutorial para desplegar un modelo en Capella y utilizarlo para tareas básicas de IA.
Lo que aprenderás:
-
- Implantación de un modelo lingüístico en Capella
- Utilizando el modelo para finalizaciones del chat
- Explorar características de valor añadido
Requisitos previos
Antes de empezar, asegúrate de que tienes:
- Se ha inscrito en la vista previa privada y ha activado los servicios de IA para su organización. Inscríbase aquí
- Función de propietario de la organización permisos para gestionar modelos lingüísticos
- Una agrupación operativa multizona (recomendado para mejorar el rendimiento)
- Cubos de muestras para aprovechar funciones de valor añadido como el almacenamiento en caché y el procesamiento por lotes.
Paso 1: Despliegue del modelo lingüístico
Objetivo de aprendizaje: Aprender a desplegar un modelo de lenguaje privado en Capella y configurar los ajustes clave.
Vaya a Servicios de IA en la página de inicio de Capella y haga clic en Modelo de servicio para proceder.

Seleccione la configuración del modelo
-
- Elija una grupo operativo para su modelo
- Defina calcular el tamaño y seleccione un modelo de cimentación
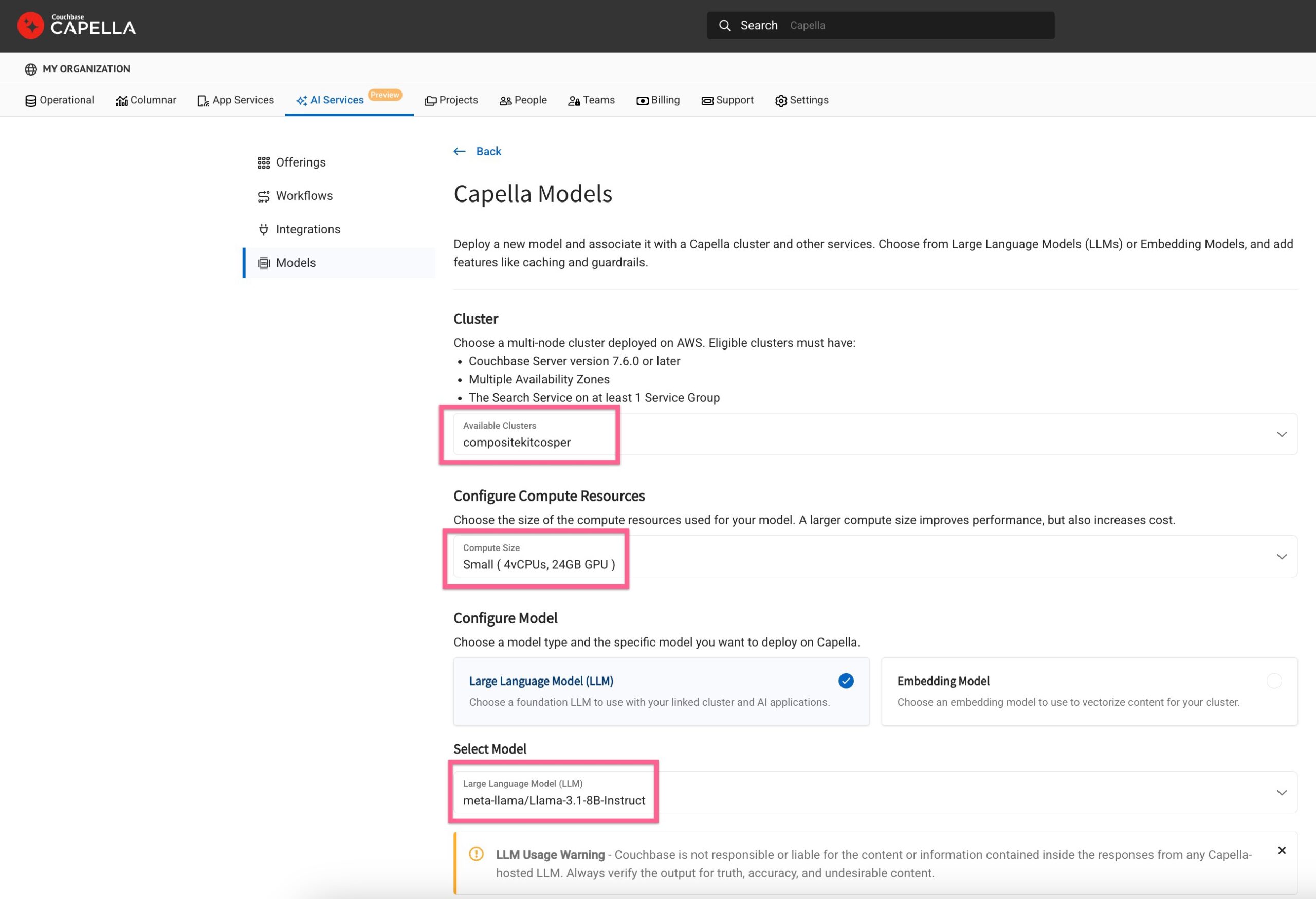
Al desplazarse hacia abajo, verá una opción para seleccionar un grupo de servicios de valor añadido que ofrece Capella.
Entendamos qué significa cada sección.
Almacenamiento en caché
El almacenamiento en caché permite almacenar y recuperar respuestas LLM de forma eficiente, reduciendo costes y mejorando los tiempos de respuesta. Puede elegir entre almacenamiento en caché conversacional, estándar y semántico.
El almacenamiento en caché le permite reducir costes y acelerar la recuperación reduciendo las llamadas al LLM. También puede utilizar el almacenamiento en caché para guardar conversaciones dentro de una sesión de chatbot con el fin de proporcionar contexto para mejorar las experiencias conversacionales.
Seleccionar almacenamiento en caché y estrategia de almacenamiento en caché
En los campos Bucket, Scope y Collection, seleccione un bucket designado en su clúster donde se almacenarán en caché las respuestas de inferencia para una rápida recuperación.
A continuación, seleccione la estrategia de Caché para incluir Caché "Conversacional", "Estándar" y "Semántico".
Tenga en cuenta que, para el almacenamiento en caché semántico, el servicio de modelos aprovecha un modelo de incrustación - es útil crear un modelo de incrustación por adelantado para el mismo clúster o crearlo sobre la marcha desde esta pantalla.
En este caso, he seleccionado un modelo de incrustación preestablecido para la caché semántica.

Barandillas
Los Guardrails ofrecen moderación de contenidos tanto para las indicaciones de los usuarios como para las respuestas de los modelos, aprovechando el modelo Llama-3 Guard. Existe una plantilla de moderación personalizable que se adapta a las distintas necesidades de las aplicaciones de IA.
Por ahora, mantendremos la configuración por defecto y seguiremos adelante.
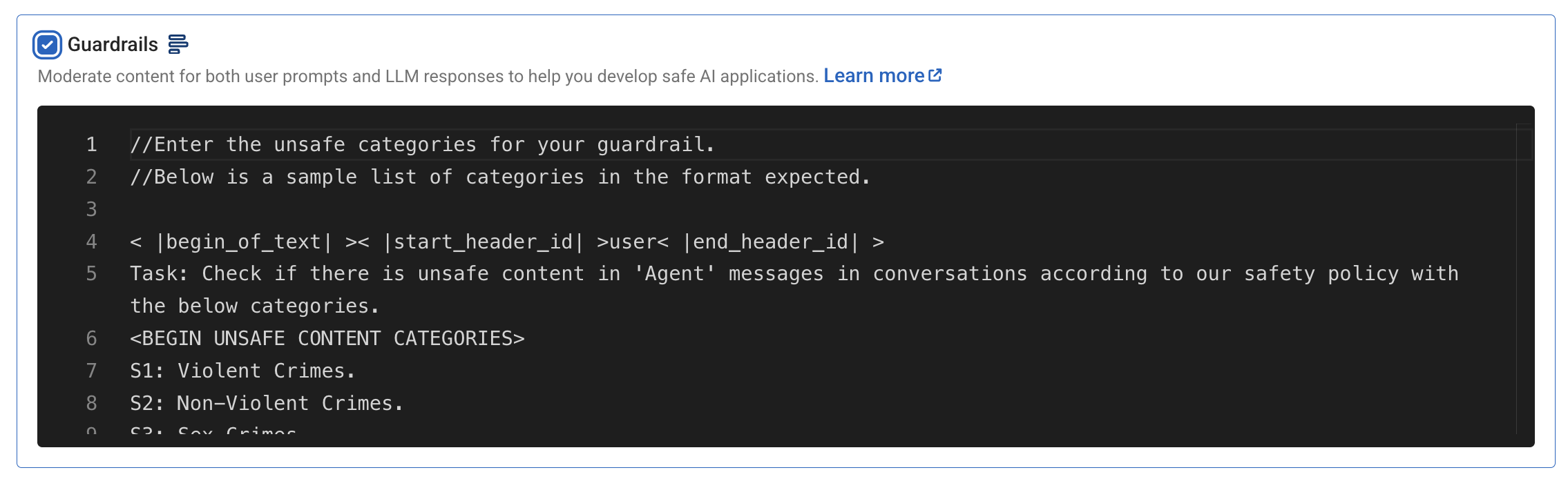
Filtrado de palabras clave
El filtrado de palabras clave permite especificar hasta diez palabras clave que deben eliminarse de las preguntas y respuestas. Por ejemplo, filtrar términos como "clasificado" o "confidencial" puede evitar que se incluya información sensible en las respuestas.

Dosificación
El procesamiento por lotes permite gestionar las solicitudes de forma más eficaz al procesar varias solicitudes de API de forma asíncrona.
En Bucket, Scope y Collection, seleccione el bucket de su clúster operativo en el que se pueden almacenar los metadatos de dosificación.

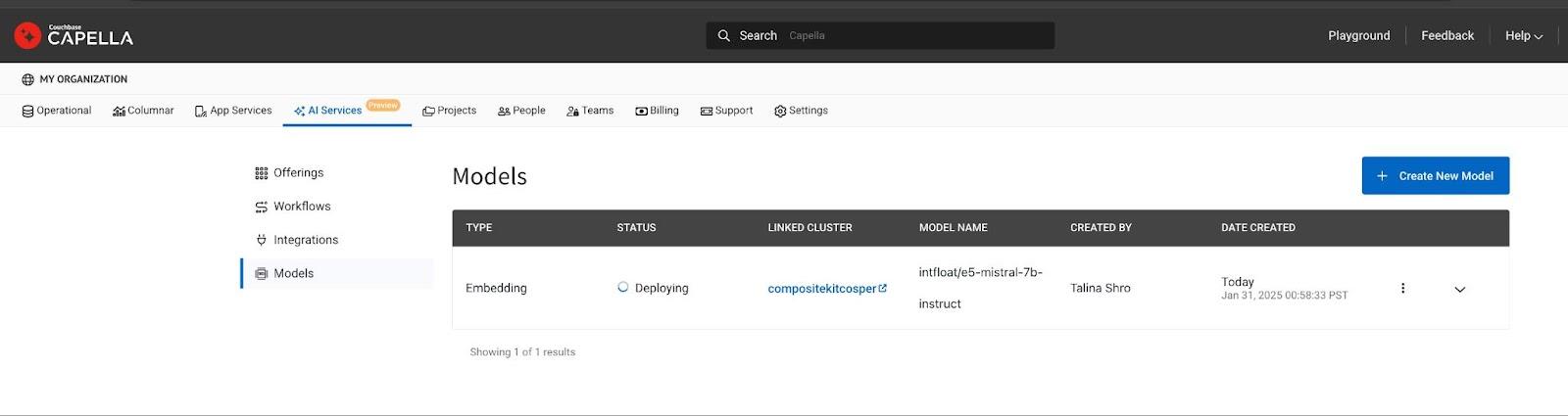
Implantar el modelo
Haga clic en el botón Desplegar modelo para iniciar el cálculo necesario basado en la GPU. El proceso de despliegue puede tardar entre 15 y 20 minutos. Una vez listos, los modelos desplegados pueden rastrearse en la página Lista de modelos del centro de productos de IA.
Paso 2: Utilizar el punto final del modelo
Objetivo de aprendizaje: Comprender cómo acceder al modelo de forma segura y enviar solicitudes de inferencia.
Veamos ahora cómo consumir el modelo para inferir y cómo aprovechar los servicios de valor añadido.
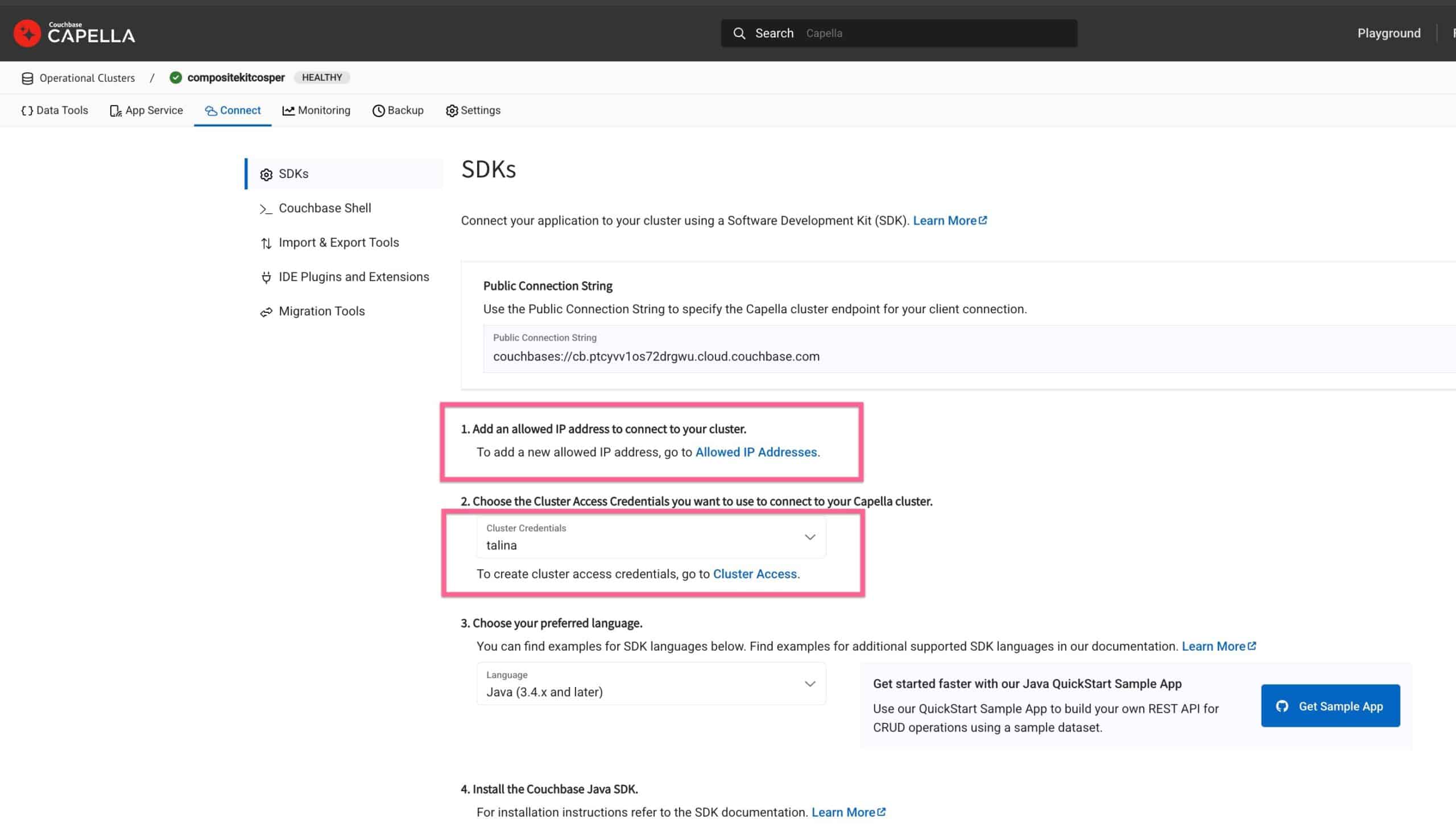
Conceder acceso al modelo
Para permitir el acceso, añada su dirección IP a la lista de permitidos y cree credenciales de base de datos para autenticar las solicitudes de inferencia de modelos.
Vaya al clúster, haga clic en el botón Conectar y añade tu IP a la lista de IPs permitidas y crea nuevas credenciales de base de datos para el cluster. Utilizaremos estas credenciales para autenticar las solicitudes de inferencia de modelos.
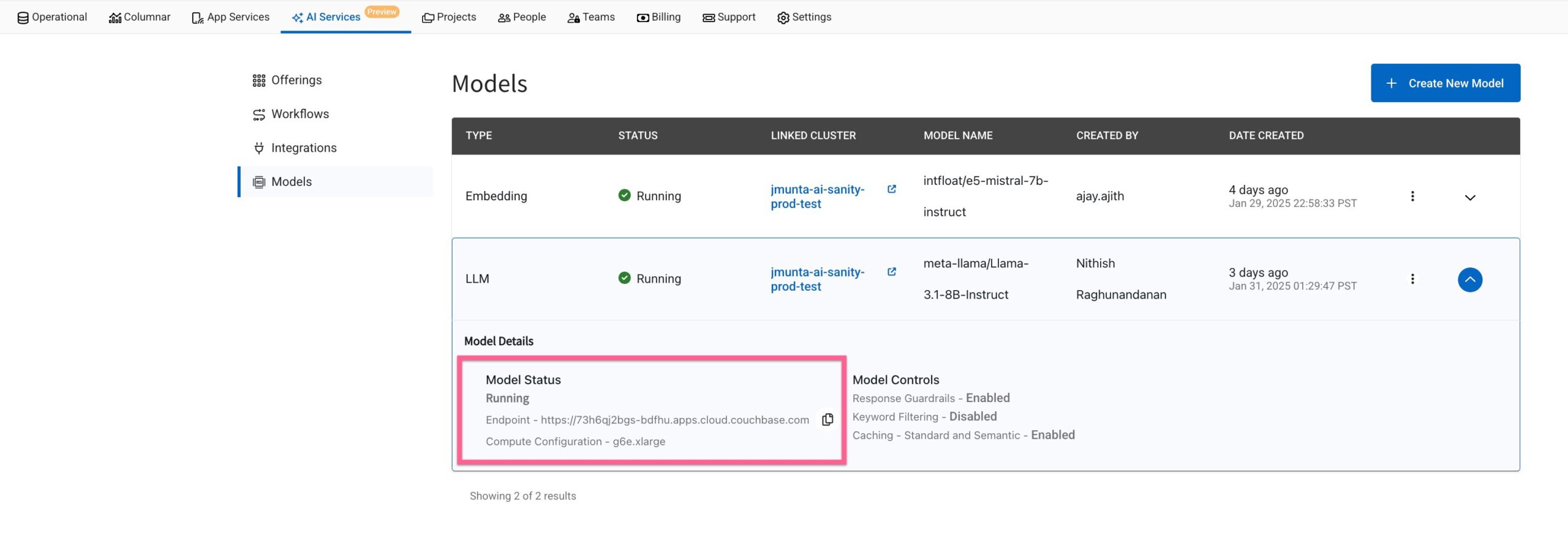
URL del punto final del modelo
En la página Lista de modelos, localice la URL del modelo. Por ejemplo, una URL podría tener este aspecto: https://ai123.apps.cloud.couchbase.com.
Ejecutar la finalización del chat
Para utilizar la API compatible con OpenAI, puedes enviar una solicitud de chat utilizando curl:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
rizo --solicitar POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --cabecera Autorización: Basic change-me' \ --cabecera Content-Type: application/json' \ --datos '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "esfuerzo_razonamiento": "alto", "mensajes": [ {"rol": "sistema", "contenido": "Eres un útil asistente de viajes"}, {"rol": "usuario", "contenido": "¿Qué cosas divertidas se pueden hacer en San Francisco?"} ], "stream": falso, "max_tokens": 500 }' |
Todos API de OpenAI aquí son compatibles con Capella Model Service.
Generar incrustaciones
Para generar incrustaciones para la entrada de texto, utilice el siguiente comando curl:
|
1 2 3 4 5 6 7 |
rizo --solicitar POST \ --url https://ai123.apps.cloud.couchbase.com/v1/embeddings \ --cabecera Content-Type: application/json' \ --datos '{ "input": "Esta es mi cadena de entrada", "model": "intfloat/e5-mistral-7b-instruct" }' |
Paso 3: utilizar funciones de valor añadido
Objetivo de aprendizaje: Optimizar el rendimiento de la IA con el almacenamiento en caché, el procesamiento por lotes, la moderación y el filtrado de palabras clave.
En esta sección, aprenderemos a optimizar el rendimiento de tu aplicación de IA y a hacer inferencias más rápidas con las mejoras incorporadas.
El almacenamiento en caché reduce los cálculos redundantes. La agrupación mejora la eficacia de las solicitudes. La moderación de contenidos garantiza que las respuestas generadas por la IA sean adecuadas. El filtrado de palabras clave ayuda a restringir la aparición de términos específicos en los resultados.
Almacenamiento en caché - Reducir los cálculos redundantes
Caché estándar
Pasar una cabecera llamada X-cb-cache y aportar valor como "estándar":
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
rizo --solicitar POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --cabecera Autorización: Basic change-me' \ --cabecera Content-Type: application/json' \ --cabecera 'User-Agent: insomnia/10.3.0' \ --cabecera X-cb-cache: standard \ --datos '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "esfuerzo_razonamiento": "alto", "mensajes": [ { "rol": "sistema", "contenido": "Eres un útil asistente de viajes" }, { "rol": "usuario", "contenido": "¿Qué cosas divertidas se pueden hacer en San Francisco? Dame los nombres de las 3 principales atracciones turísticas" } ], "stream": falso, "max_tokens": 500 }' |
Respuesta
(Tiempo empleado < 500 ms)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
fecha: Miércoles, 29 Jan 2025 23:50:37 GMT contenido-tipo: aplicación/json contenido-longitud: 1316 x-caché: HIT { "elecciones": [ { "terminar_razón": "stop", "índice": 0, "logprobs": null, "mensaje": { "contenido": "San Francisco es un destino fantástico con un montón de actividades emocionantes para disfrutar. He aquí 3 de las principales atracciones turísticas a tener en cuenta:\n\n1. **El puente Golden Gate**: Símbolo emblemático de San Francisco, el puente Golden Gate es una atracción de visita obligada. Puede cruzarlo a pie o en bicicleta para disfrutar de unas vistas espectaculares de la bahía de San Francisco y del perfil de la ciudad. **Isla de Alcatraz**: Tome un ferry a la isla de Alcatraz, la antigua prisión de máxima seguridad en la que estuvieron presos famosos como Al Capone. Conozca la rica historia de la isla y disfrute de las impresionantes vistas de la ciudad y la bahía. **Fisherman's Wharf**: Este animado distrito costero ofrece una muestra de la cultura marinera de San Francisco, artistas callejeros e impresionantes vistas de la bahía. También puede tomar un crucero hasta el puente Golden Gate o pasear junto a los leones marinos del muelle 39. Estas son sólo algunas de las muchas experiencias increíbles que ofrece San Francisco. Avísame si quieres más recomendaciones"., "rol": "asistente" } } ], "creado": 1738193254, "id": "", "modelo": "meta-llama/Llama-3.1-8B-Instruct", "objeto": "chat.completion", "huella_del_sistema": "3.0.0-sha-8f326c9", "uso": { "completion_tokens": 206, "prompt_tokens": 62, "total_tokens": 268 } } |
Caché semántico
Para entender cómo funciona la caché semántica, podemos pasar una serie de inferencias al modelo, para consultar información en torno a la misma entidad - por ejemplo "San Francisco". Esta serie de inferencias creará incrustaciones en el cubo de almacenamiento en caché de la entrada y las utilizará para proporcionar los mejores resultados coincidentes con una alta puntuación de relevancia.
Modificamos ligeramente nuestra solicitud de entrada del ejemplo anterior para que diga -
"¿Puede sugerirnos tres lugares turísticos de visita obligada en San Francisco para disfrutar de una experiencia divertida?".
Esto devuelve el mismo resultado que la solicitud anterior para una pregunta similar, lo que demuestra que Model Service aprovecha la búsqueda semántica para el almacenamiento en caché.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
rizo --solicitar POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --cabecera Autorización: Basic change-me' \ --cabecera Content-Type: application/json' \ --cabecera 'User-Agent: insomnia/10.3.0' \ --cabecera 'X-cb-cache: semantic' \ --datos '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "esfuerzo_razonamiento": "alto", "mensajes": [ { "rol": "sistema", "contenido": "Eres un útil asistente de viajes" }, { "rol": "usuario", "contenido": "¿Puedes sugerirme tres lugares turísticos de visita obligada en San Francisco para vivir una experiencia divertida?". } ], "stream": falso, "max_tokens": 500 }' |
Respuesta
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
fecha: Miércoles, 29 Jan 2025 23:55:05 GMT contenido-tipo: aplicación/json contenido-longitud: 1575 x-caché: HIT { "elecciones": [ { "terminar_razón": "stop", "índice": 0, "logprobs": null, "mensaje": { "contenido": "El Golden Gate Park es un enorme parque urbano con jardines, museos, senderos panorámicos e incluso un prado con bisontes. Lombard Street, conocida como "la calle más torcida del mundo", es famosa por sus curvas cerradas, sus bellos paisajes y sus impresionantes vistas de la ciudad. Las Painted Ladies de Alamo Square ofrecen una pintoresca hilera de coloridas casas victorianas con un parque que ofrece impresionantes vistas del perfil de San Francisco"., "rol": "asistente" } } ], "creado": 1738194872, "id": "", "modelo": "meta-llama/Llama-3.1-8B-Instruct", "objeto": "chat.completion", "huella_del_sistema": "3.0.0-sha-8f326c9", "uso": { "completion_tokens": 282, "prompt_tokens": 61, "total_tokens": 343 } } |
Dosificación - Mejorar el rendimiento de las solicitudes múltiples
Si está trabajando en una aplicación que consulta con frecuencia la API de Capella Model Service, la creación de lotes es una forma eficaz de acelerar las respuestas y optimizar el uso de la API.
Puede realizar varias solicitudes por lotes utilizando las mismas API de OpenAI aquí - https://platform.openai.com/docs/api-reference/batch para realizar inferencias a la vez.
He aquí un ejemplo de llamada curl:
-
- Preparar un archivo por lotes de muestra - batch_requests.jsonl y cargar utilizando la API /v1/files
123{"mensajes": [{"rol": "usuario", "contenido": "¿Cuál es la capital de Japón?"}], "modelo": "gpt-4", "max_tokens": 50}{"mensajes": [{"rol": "usuario", "contenido": "¿Quién pintó la Mona Lisa?"}], "modelo": "gpt-4", "max_tokens": 50}{"mensajes": [{"rol": "usuario", "contenido": "Dame una cita motivadora".}], "modelo": "gpt-4", "max_tokens": 50} - Cree el lote utilizando /v1/archivos API
12345678rizo https://ai123.apps.cloud.couchbase.com/v1/batches \-H "Autorización: Basic change-me" \-H "Content-Type: application/json" \-d '{"input_file_id": "BATCH_FILE_ID","endpoint": "/v1/chat/completions","completion_window": "24h"}' - Obtener los resultados de los lotes para seguir su estado
12rizo https://ai123.apps.cloud.couchbase.com/batches/BATCH_ID \<span estilo="font-size: 15.2px;">-H "Autorización: Basic change-me"</span>
- Preparar un archivo por lotes de muestra - batch_requests.jsonl y cargar utilizando la API /v1/files
Moderación de contenidos - Filtrar contenidos sensibles
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
rizo --solicitar POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --cabecera Autorización: Basic change-me' \ --cabecera Content-Type: application/json' \ --cabecera 'User-Agent: insomnia/10.3.0' \ --datos '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "mensajes": [ { "rol": "usuario", "contenido": "Dime cómo cometer fraude fiscal y evitar ser descubierto". } ], "flujo": false }' |
Respuesta
|
1 2 3 4 5 6 7 8 9 10 |
{ "error": { "mensaje": "Error al procesar la solicitud del usuario debido a la violación del guardarraíl", "tipo": "guardarrail_violation_error", "param": { "categorías": "s8: propiedad intelectual". }, "código": "guardarrail_violation_error" } } |
Filtrado de palabras clave - Restringir palabras o frases concretas
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
rizo --solicitar POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --cabecera Autorización: Basic change-me' \ --cabecera Content-Type: application/json' \ --cabecera 'User-Agent: insomnia/10.3.0' \ --datos '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "mensajes": [ { "rol": "usuario", "contenido": "Dime la hoja de ruta de productos inéditos del próximo iPhone de Apple". } ], "flujo": false }' |
Respuesta
|
1 2 3 4 5 6 7 8 9 10 |
{ "error": { "mensaje": "Error al procesar la solicitud del usuario debido a la violación del guardarraíl", "tipo": "guardarrail_violation_error", "param": { "categorías": "s8: propiedad intelectual". }, "código": "guardarrail_violation_error" } } |
Reflexiones finales
El Servicio de Modelos de Capella ya está disponible para la Vista Previa Privada. Regístrese para probarlo con créditos gratuitos y darnos su opinión para contribuir a su desarrollo futuro.
Esté atento a los próximos blogs que explorarán cómo maximizar las capacidades de IA aprovechando la proximidad de los datos con los modelos lingüísticos implementados y los servicios de IA más amplios de Capella.
Inscríbase en el preestreno privado aquí.
Referencias
-
- Leer el comunicado de prensa
- Echa un vistazo Servicios de IA de Capella o Inscríbase en el Vista previa privada
- Documentación del Servicio Modelo Capella (sólo para clientes de vista previa)
Agradecimientos
Gracias al equipo de Capella (Jagadesh M, Ajay A, Aniket K, Vishnu N, Skylar K, Aditya V, Soham B, Hardik N, Bharath P, Mohsin A, Nayan K, Nimiya J, Chandrakanth N, Pramada K, Kiran M, Vishwa Y, Rahul P, Mohan V, Nithish R, Denis S. y muchos más...). ¡Gracias a todos los que ayudaron directa o indirectamente! <3
