Si desea migrar sus datos de una base de datos relacional a NoSQL, entonces ahora es mejor momento que nunca.
El reciente lanzamiento de Couchbase 7.0 introdujo Ámbitos y Colecciones - una nueva forma de organizar su Datos JSON. Más que cualquier otra cosa, Scopes y Collections simplifican y facilitan la migración de tu actual modelo de datos relacional al modelo de datos de documentos de Couchbase. Como resultado, tu empresa se beneficia de la arquitectura distribuida "shared-nothing", la alta disponibilidad y la escalabilidad horizontal de Couchbase.
Y si eres cliente o usuario de Couchbase desde hace tiempo... Los ámbitos y las colecciones tienen mucho que ofrecer en términos de gestión y organización de datos.
Pero tanto si eres nuevo en NoSQL como si eres un veterano de Couchbase, tus consultas a bases de datos - utilizando el lenguaje de consulta N1QL - beneficiarse del nuevo modelo de datos Scopes y Collections. Si quieres simplificar tus consultas N1QL, tendrás que migrar tus datos de Couchbase del antiguo modelo Bucket al nuevo modelo Collections. Afortunadamente, la migración es un proceso sencillo de cinco pasos.
Empecemos con un repaso de Ámbitos y Colecciones. (O pase directamente a la guía de migración si está preparado.)
Espera, ¿qué son los ámbitos y las colecciones?
Un Scope es equivalente a un esquema en una base de datos relacional (RDBMS). Es un contenedor lógico para las colecciones de Couchbase. Cada Couchbase Bucket contiene un Scope por defecto. Puedes usar estos contenedores por defecto directamente - o definir los tuyos propios.
Una Colección es análoga a una tabla en un RDBMS. Cada ámbito tiene una colección por defecto. Mientras que una colección puede utilizarse para almacenar tipos similares de registros (como una tabla RDBMS), no hay restricciones de esquema sobre lo que se puede almacenar en una colección. Todo depende de ti.
A continuación se ilustra cómo varios conceptos de bases de datos relacionales se corresponden con estas nuevas características de Servidor Couchbase 7.0:
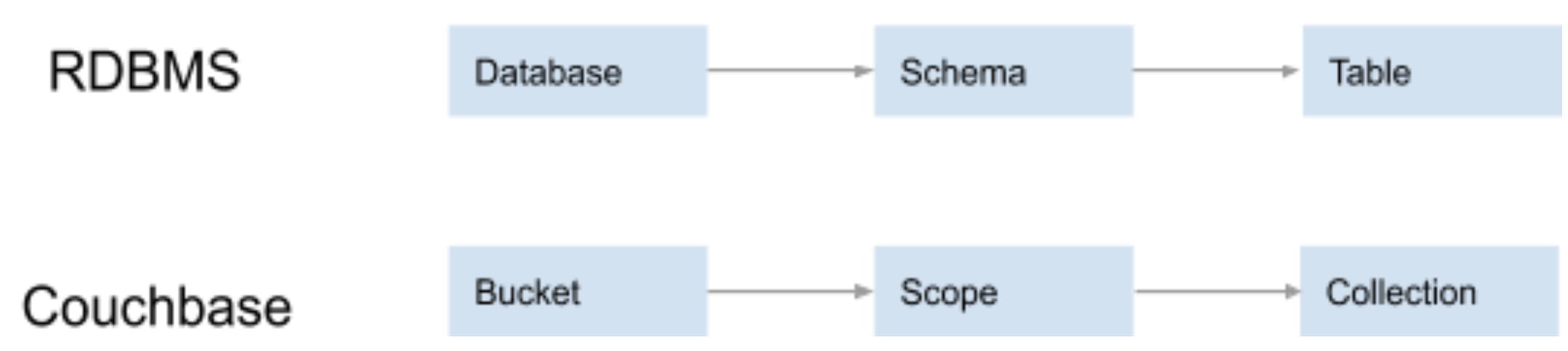
Como puede ver, ahora hay un mapeo uno a uno entre los sistemas relacional y Modelos de datos NoSQL al utilizar ámbitos y colecciones en Couchbase.
Espacios de claves del sistema en Ámbitos y colecciones
| Espacio clave | Descripción |
sistema:todos_los_ámbitos |
Una lista de todos los ámbitos, incluidos los objetos del sistema, como los ámbitos por defecto |
sistema:ámbitos |
Todos los ámbitos disponibles excepto los ámbitos del sistema |
sistema:todas_las_colecciones |
Una lista de todas las Colecciones, incluidos los objetos del sistema, como las Colecciones por defecto |
sistema:colecciones |
Todas las colecciones disponibles excepto las del sistema |
Cómo los ámbitos y las colecciones agilizan sus consultas N1QL
Una consecuencia importante de Scopes y Collections es que el lenguaje de consulta N1QL es ahora más simple. Esto se debe a que un tipo ya no es necesario en todos los documentos. Como resultado, tanto el Lenguaje de Definición de Datos (DDL) como el Lenguaje de Manipulación de Datos (DML) de las sentencias N1QL son más fáciles de escribir y entender.
Las consultas N1QL son ahora más sencillas e intuitivas
Couchbase Collections te proporciona el equivalente de una tabla relacional. La fuerza de esta similitud -sin ninguna de sus debilidades- tiende un puente entre el mundo lógico y el relacional. modelo físico de datos al que están acostumbrados muchos RDBMS.
Eche un vistazo a estas consultas N1QL en paralelo utilizando la función viaje-muestra conjunto de datos.
| Modelo de cubo | Modelo de recogida | ||||
|
|
La consulta de los saltos de la izquierda ilustra cómo había que especificar el documento tipo en el antiguo modelo Bucket. La consulta de la derecha es más sencilla porque el documento tipo ya no es necesario en el nuevo modelo Collection introducido en Couchbase 7.0.
Las condiciones JOIN de N1QL también son más sencillas
Los JOINs en N1QL también se han vuelto más fáciles. Eche un vistazo a esta comparación de consultas antiguas y nuevas a continuación.
| Modelo de cubo | Modelo de recogida | ||||
|
|
En el nuevo modelo Collection, la sintaxis JOIN no requiere el uso de la función tipo para restringir su consulta a una tabla específica de documentos dentro del Bucket.
Las consultas N1QL mantienen la retrocompatibilidad con el modelo de cubo
La introducción del nuevo modelo Collection no significa el fin de Buckets. El Servicio de Consultas N1QL sigue soportando el modelo Bucket como hasta ahora.
El único cambio es que ahora sus datos de Bucket se almacenan en el Scope por defecto que a su vez contiene una Collection por defecto.
| Modelo de cubo | Modelo de recogida | ||||||
|
Puedes usar:
o
|
Tenga en cuenta que el prefijo del espacio de nombres es obligatorio y debe tener el valor por defecto: para todas las referencias al ámbito o la colección por defecto.
Un cambio importante en las consultas N1QL con colecciones
Con el modelo Collection, el motor de consulta debe conocer la ruta completa del nombre de la colección. Esto se debe a que el nombre de una colección no tiene que ser único dentro de un cubo, sino sólo dentro de su propio ámbito.
Un nombre de colección completo tiene el siguiente formato:
Formato:
|
1 |
espacio de nombres:cubo.alcance.colección |
Por ejemplo:
|
1 |
espacio de nombres:`viaje-muestra`.reserva.hotel |
Sin embargo, puede hacer referencia a una colección con su ruta relativa estableciendo el parámetro contexto_de_consulta
En Interfaz del Query Workbench permite establecer el contexto de la consulta seleccionando el Cubo y el Ámbito en el cuadro desplegable (en la parte superior derecha de la captura de pantalla siguiente).

El contexto de consulta también se admite en SDK de Couchbase, la API REST y concha cbq.
¿Tengo que migrar a Colecciones?
No, no tienes que migrar al modelo de Colecciones si no quieres.
Esto es lo que no cambia si decide no migrar:
-
- Datos: Todos los datos existentes permanecen en el mismo Bucket. Puede hacer referencia a sus documentos mediante la sintaxis de consulta de Bucket o utilizando el nuevo Ámbito y Colección predeterminados.
- Consultas: La sintaxis de consulta N1QL para el DDL y el DML sigue soportando el modelo Bucket.
- Índices: Sus índices existentes permanecerán en el nivel Bucket y seguirán estando disponibles para todas sus consultas como antes.
Migración de Bucket a Collections en Couchbase 7.0
Si estás listo para migrar del antiguo modelo Bucket al nuevo modelo Scopes and Collections ahora disponible en Couchbase 7.0, aquí están los cinco pasos principales que necesitas completar.
Para esta guía de migración, utilizaré el archivo viaje-muestra Bucket como conjunto de datos de ejemplo.
Paso 1: Migración de datos
Si sus documentos ya tienen un campo para identificar sus grupos, utilice esas agrupaciones para crear sus Colecciones.
Para el viaje-muestra de datos, utilicemos los respectivos tipo como nombres de la colección. Además, también crearemos un inventario Alcance para todas las colecciones del conjunto de datos.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREAR ALCANCE `viaje-muestra`.inventario; CREAR COLECCIÓN `viaje-muestra`.inventario.ruta; CREAR COLECCIÓN `viaje-muestra.inventario.hito; CREAR COLECCIÓN `viaje-muestra`.inventario.aerolínea; CREAR COLECCIÓN `viaje-muestra`.inventario.hotel; CREAR COLECCIÓN `viaje-muestra`.inventario.aeropuerto; |
En el ejemplo anterior, creamos un inventario Ámbito y añadido nuevas Colecciones dentro del mismo viaje-muestra Cubo.
Paso 2: Garantizar claves de documento únicas
Las claves de los documentos deben ser únicas.
La clave de documento que tiene actualmente para su(s) Bucket(s) existente(s) ya debería ser única porque todos sus documentos existen dentro del mismo Bucket. Por ese motivo, la clave de documento existente debería ser adecuada para utilizarla como clave de documento de la nueva colección.
Paso 3: Copie sus datos
En el siguiente ejemplo de código, utilizaremos INSERTAR SELECCIONAR para copiar los datos del Cubo en cada Colección individual. También utilizamos el META().id Clave de cubo para la clave de recogida.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
INSERTAR EN `viaje-muestra`.inventario.hito (CLAVE k, VALOR val) SELECCIONE META().id k, t val DESDE `viaje-muestra` t DONDE t.tipo="hito ; INSERTAR EN `viaje-muestra`.inventario.aerolínea (CLAVE k, VALOR val) SELECCIONE META().id k, t val DESDE `viaje-muestra` t DONDE t.tipo=aerolínea ; INSERTAR EN `viaje-muestra`.inventario.hotel (CLAVE k, VALOR val) ELIGE META().id k, t val DESDE `viaje-muestra` t DONDE t.tipo=hotel ; INSERTAR EN `viaje-muestra`.inventario.aeropuerto (CLAVE k, VALOR val) SELECCIONE META().id k, t val DESDE `viaje-muestra` t DONDE t.tipo=aeropuerto ; INSERTAR EN `viaje-muestra`.inventario.ruta (CLAVE k, VALOR val) SELECCIONE META().id k, t val DESDE `viaje-muestra` t DONDE t.tipo=ruta ; |
Paso 4: Conversión de índices
Es muy probable que tenga que modificar sus índices de cubo existentes para que sean efectivos con el nuevo modelo de colección.
En las tres subsecciones siguientes se enumeran los patrones más comunes para los índices de cubos y se muestran los pasos para convertirlos en un índice basado en colecciones.
Conversión de índices: Índice de cubos con un predicado de tipo
Para un índice Bucket con un tipo (es decir, un índice parcial), puede simplemente volver a crear el nuevo índice en la colección específica para el tipo.
Compare los dos ejemplos siguientes:
| Modelo de cubo | Modelo de colección | ||||
|
|
Conversión de índices: Índice de cubos sin predicado de tipo
Puede crear un índice secundario global (GSI) para campos que pueden existir o no en el documento.
Por ejemplo, un índice puede incluir icao pero no todos los documentos pueden tener el campo icao campo. En un índice de este tipo, el indizador sólo incluye los documentos que tienen el campo icao en ellas. Si utiliza este tipo de índice, es posible que deba ser más específico y crear un índice para la colección en la que se utiliza ese campo.
De nuevo, contraste los dos ejemplos de código siguientes entre los modelos antiguo y nuevo:
| Modelo de cubo | Modelo de colección | ||||
|
|
Conversión de índices: Índice de cubeta para un campo común
También puede crear un índice Bucket sin especificar el tipo concreto, aunque el campo exista en varios tipos de documento.
Consideremos el ejemplo en el que el campo ciudad existe en varios tipos de documentos: por ejemplo, documentos de aeropuertos, monumentos y hoteles. El modelo Bucket sólo tiene un def_ciudad que puede abarcar los tres tipos de documentos. Sin embargo, con el nuevo modelo de colecciones, tendrá que crear un índice independiente para cada colección para este tipo de índice.
Puede ver las diferencias en los siguientes ejemplos de código:
| Modelo de cubo | Modelo de colección | ||||
|
|
Paso 5: Conversión de consultas
Debido a que el modelo de datos subyacente ha cambiado de un Cubo compartido a una Colección individual, tendrá que modificar sus consultas N1QL existentes.
Además, una vez modificadas las consultas, es necesario volver a comprobar que dichas consultas utilizan los nuevos índices basados en colecciones.
Puede ver las consultas antiguas y actualizadas en los ejemplos de código que figuran a continuación:
| Modelo de cubo | Modelo de colección | ||||||
|
La consulta reescrita sin los filtros de tipo:
|
Conclusión
Ya está. Has terminado de migrar del antiguo modelo Bucket al nuevo modelo Scopes and Collections de Couchbase 7.0.
Espero que el nuevo modelo de datos Colecciones te resulte más potente e intuitivo, y que tus consultas N1QL se simplifiquen y agilicen como resultado.
Si desea obtener más información sobre la versión 7.0 de Couchbase Server, Novedades y/o las notas de la versión 7.0.