
Lea los antecedentes de la paginación en mi artículo anterior: https://www.couchbase.com/blog/optimizing-database-pagination-using-couchbase-n1ql/
La paginación es la tarea de dividir el resultado potencial en páginas y recuperar las páginas requeridas, una a una bajo demanda. El uso de OFFSET y LIMIT es la forma más sencilla de escribir la paginación en las consultas a bases de datos. Juntos, OFFSET y LIMIT, forman la cláusula de paginación de la sentencia SELECT. La paginación es un trabajo de aplicación común y su implementación tiene un gran impacto en la experiencia del cliente. Veamos los problemas y soluciones con Couchbase N1QL en detalle.
Markus Winand de http://use-the-index-luke.com/ argumenta que puede no ser lo más eficiente. También sugiere, cuando sea posible, utilizar la paginación por conjuntos de teclas en lugar de la paginación OFFSET. Para este artículo, voy a utilizar las consultas de ejemplo modelado en su artículo, http://use-the-index-luke.com/no-offset para mostrar qué optimizaciones OFFSET hemos hecho, cuándo y cómo explotar la paginación de conjuntos de teclas en N1QL.
Dado que Couchbase incluye un conjunto de datos de muestra de viajes, lo utilizaremos para escribir nuestras consultas de paginación.
- OBTENER LA PRIMERA PÁGINA
|
1 2 3 4 5 6 7 8 9 10 |
SELECCIONE * DESDE Viajar-muestra` DONDE tipo = hotel PEDIR POR país, ciudad OFFSET 0 LÍMITE 10; CREAR ÍNDICE ixtopic EN Viajar-muestra`(tipo); |
Para esta consulta, utilizando el índice ixtopic, el motor de consulta se ejecuta de forma sencilla. El motor de consultas obtiene todas las claves cualificadas del índice, a continuación obtiene todos los documentos, ordena en función de la cláusula ORDER BY y, por último, elimina el número de documentos OFFSET (en este caso cero) y proyecta el número de documentos LIMIT (en este caso 10).
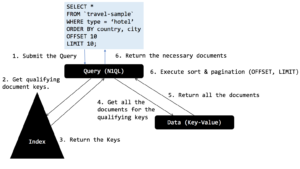
Aquí está el plan que muestra el índice y los vanos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ "índice": "ixtype", "index_id": "8630f5f7e05ee113", "proyección_índice": { "clave_primaria": verdadero }, "espacio clave": "viaje-muestra", "espacio de nombres": "por defecto", "vanos": [ { "exacto": verdadero, "rango": [ { "alto": "\"hotel\"", "inclusión": 3, "bajo": "\"hotel\"" } |
N1QL elige el índice ixtype e introduce el filtro (type = "hotel") en la exploración del índice. Para aplicar la cláusula ORDER BY, recupera todos los documentos. En la fase de ordenación, reconocemos la cláusula LIMIT 10 y hacemos que la ordenación sea eficiente manteniendo sólo los 10 primeros elementos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "#operator": "Pedido", "límite": "10", "sort_terms": [ { "expr": "(`viaje-muestra`.`país`)" }, { "expr": "(`viaje-muestra`.`ciudad`)" } ] }, |
Veamos la eficiencia del operador de escaneo de índices con este índice:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
"#operator": "IndexScan2", "#stats": { "#itemsOut": 917, "#phaseSwitches": 3671, "execTime": "2.646892ms", "kernTime": "31.095431ms", "servTime": "19.781593ms" }, ... "#operator": "Fetch", "#stats": { "#itemsIn": 917, "#itemsOut": 917, "#phaseSwitches": 3787, "execTime": "3.43324ms", "kernTime": "20.847541ms", "servTime": "69.875698ms" }, ... "#operator": "Pedido", "#stats": { "#itemsIn": 917, "#itemsOut": 10, "#phaseSwitches": 1849, "execTime": "6.519061ms", "kernTime": "88.307572ms" }, |
El indizador ha devuelto 917 claves de documento. El motor de consulta obtuvo 917 documentos. A continuación, el operador de clasificación (orden) los ordenó y devolvió los 10 elementos.
2. OBTENER LA SEGUNDA PÁGINA
|
1 2 3 4 5 6 7 8 |
SELECCIONE * DESDE Viajar-muestra` DONDE tipo = hotel PEDIR POR país, ciudad OFFSET 10 LÍMITE 10; |
En este caso, todo es igual que en la consulta1 excepto:
- El operador de ordenación (ORDER BY) devolverá 20 documentos (offset + limit).
- El nuevo operador OFFSET se ejecutará después del operador Order y eliminará las 10 primeras filas.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
"#operator": "Pedido", "#stats": { "#itemsIn": 917, "#itemsOut": 20, "#phaseSwitches": 1859, "execTime": "6.485904ms", "kernTime": "65.92484ms" }, { "#operator": "Offset", "#stats": { "#itemsOut": 10, "#phaseSwitches": 32, "execTime": "5.071503ms", "kernTime": "701ns", "estado": "corriendo" }, "expr": "10", "#ime_normal": "00:00.0050", "#iempo_absoluto": 0.005071503 }, |
A medida que el OFFSET aumenta, el número de documentos escaneados por la clasificación también aumentará, consumiendo más memoria y CPU.
- Mejoremos el rendimiento cubriendo las claves de predicado y ordenación con un único índice.
|
1 2 3 4 5 6 7 8 9 10 |
CREAR ÍNDICE ixtypectcy EN Viajar-muestra`(tipo, país, ciudad); Vamos ejecutar nuestra reciente consulta otra vez: SELECCIONE * DESDE Viajar-muestra` DONDE tipo = hotel PEDIR POR país, ciudad OFFSET 10 LÍMITE 10; |
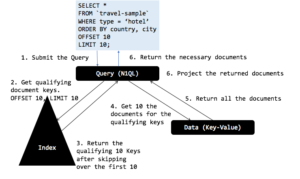
Utiliza el índice adecuado y crea los filtros adecuados (spans) para la exploración del índice.Explain incluye lo siguiente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
{ "#operator": "IndexScan2", "índice": "ixtypectcy", "index_id": "2a2ed6573354e21", "proyección_índice": { "clave_primaria": verdadero }, "espacio clave": "viaje-muestra", "límite": "10", "espacio de nombres": "por defecto", "offset": "10", "vanos": [ { "exacto": verdadero, "rango": [ { "alto": "\"hotel\"", "inclusión": 3, "bajo": "\"hotel\"" } ] } ], |
Veamos la eficiencia del operador de escaneo de índices con este índice:
|
1 2 3 4 5 6 7 8 9 10 |
"#operator": "IndexScan2", "#stats": { "#itemsOut": 10, "#phaseSwitches": 43, "execTime": "41.786µs", "kernTime": "11.15µs", "servTime": "855.759µs" }, |
Sólo se devuelven las 10 claves de documento necesarias a partir de la exploración del índice. El optimizador N1QL evalúa tanto la cláusula WHERE como la cláusula de paginación (OFFSET, LIMIT). El optimizador de consultas decide enviar la cláusula de paginación al indexador basándose en la cláusula order by de la consulta y en el orden de las claves del índice.
En este caso, el predicado de la consulta es: type = 'hotel'
La cláusula Order by es: ORDER BY país, ciudad
El orden de las claves del índice es: (tipo, país, ciudad)
Por simple comparación, el orden por cláusula no es exactamente el mismo que el orden por clave del índice. Sin embargo, la clave principal del índice (tipo) tiene un predicado de igualdad (tipo = 'hotel'). Por lo tanto, el optimizador sabe que las claves proyectadas del documento estarán en el orden de (país y ciudad).
**y la cláusula ORDER BY para ver si puede empujar hacia abajo los parámetros de paginación a la exploración del índice. En este caso, hay una coincidencia perfecta.
El optimizador pasa tanto OFFSET como LIMIT en la paginación al escaneo de índice y el escaneo de índice devuelve sólo las 10 claves de documento requeridas sin importar el OFFSET. Por lo tanto, fetch sólo necesita obtener los 10 documentos. El indexador tiene que pasar por el escaneo del índice para evaluar las claves.
Esta consulta se ejecutó en unos 6,81 milisegundos en mi entorno. Vamos a paginar las páginas siguientes para ver el rendimiento:
| OFFSET | LÍMITE | Tiempo de respuesta |
| 10 | 10 | 6,81 ms |
| 20 | 10 | 7,17 ms |
| 100 | 10 | 7,02 ms |
| 400 | 10 | 9,54 ms |
| 800 | 10 | 9,08 ms |
Si desea paginar en orden descendente, cambie la consulta y el índice por los siguientes. La intercalación de la clave en el índice debe coincidir con la intercalación de la consulta. En este caso, tanto el país como la ciudad están en orden descendente.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DROP ÍNDICE Viajar-muestra`.ixtypectcy; CREAR ÍNDICE ixtypectcy EN Viajar-muestra`(tipo, país DESC, ciudad DESC); SELECCIONE país, ciudad DESDE Viajar-muestra` DONDE tipo = "hotel" PEDIR POR país DESC, ciudad DESC OFFSET 10 LÍMITE 10; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "#operator": "IndexScan2", "tapas": [ "cover ((`viaje-muestra`.`tipo`))", "cover ((`viaje-muestra`.`país`))", "cubrir ((`viaje-muestra`.`ciudad`))", "cover ((meta(`viaje-muestra`).`id`))" ], "índice": "ixtypectcy", "espacio clave": "viaje-muestra", "límite": "10", "espacio de nombres": "por defecto", "offset": "10", "vanos": [ { "exacto": verdadero, "rango": [ { "alto": "\"hotel\"", "inclusión": 3, "bajo": "\"hotel\"" } ] } ], |
Veamos ahora una consulta que no está cubierta por el índice. En la consulta que vimos antes, decidimos recuperar el nombre del hotel junto con el país y la ciudad. El nombre no está en el índice.
|
1 2 3 4 5 6 7 8 9 10 |
CREAR ÍNDICE ixtypectcy EN `viaje-muestra` (tipo, país DESC, ciudad DESC); SELECCIONE país, ciudad, nombre DESDE `viaje-muestra` DONDE tipo = "hotel" PEDIR POR país desc, ciudad desc OFFSET 10 LÍMITE 10; |
En este caso, de nuevo, el índice tiene los datos para cubrir la cláusula WHERE y la cláusula ORDER BY. El escaneo del índice aplicará el predicado. El orden del índice coincide con el orden de la consulta (nota: sólo hay un predicado de igualdad en la clave principal. Por lo tanto, el país y la ciudad se ordenan automáticamente). El índice omite el número OFFSET de claves cualificadas y devuelve el número de claves especificado por la cláusula LIMIT. El motor recupera los documentos para mantener el orden especificado por la cláusula ORDER BY.
Todas estas pequeñas optimizaciones juntas aseguran que el rendimiento de la consulta sea consistente tanto si OFFSET es 10, 100 o 1000. La única sobrecarga entre OFFSET más altos es la exploración del índice omitiendo los elementos adicionales. La evaluación de la clave del índice y la omisión es significativamente más rápida que obtener todos los documentos y ordenarlos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "#operator": "Secuencia", "~niños": [ { "#operator": "IndexScan2", "índice": "ixtypectcy", "index_id": "b2ab2c276bba7862", "proyección_índice": { "clave_primaria": verdadero }, "espacio clave": "viaje-muestra", "límite": "10", "espacio de nombres": "por defecto", "offset": "10", "vanos": [ { "exacto": verdadero, "rango": [ { "alto": "\"hotel\"", "inclusión": 3, "bajo": "\"hotel\"" } ] } |
Consideremos una consulta de larga duración con un potencial de devolución de hasta 24.000 documentos.
create index idxtypeaiaid ON `viajes-muestra`(tipo, aerolinea, airlineid)
Incluso cuando los predicados de consulta de paginación y el orden por están completamente cubiertos por el índice, hay un número limitado de casos en los que el LIMIT y OFFSET de paginación pueden ser empujados al escaneo del índice para hacerlo muy eficiente.
Estas son las reglas generales y los requisitos para enviar OFFSET y LIMIT al indexador. Tenga en cuenta que estas reglas no son exhaustivas ni completas, pero le dan una idea de cuándo se realiza esta optimización.
- El escaneo de la consulta debe realizarse en un único espacio clave (referencia única en la cláusula FROM sin JOINs.
- DESDE
viaje-muestrat - DESDE
viaje-muestrahotel INNER JOINviaje-muestrahitos ON KEYS hotel.lmid
- DESDE
El caso (a) cumple los requisitos, y el (b) no.
- Todos los predicados de la consulta son empujados hacia abajo en el escaneo del índice (spans).
- No podemos empujar los predicados (col LIKE "%xyz") al escaneo del índice. Por lo tanto, la paginación no se puede empujar hacia abajo también.
- Todos los predicados deben estar representados por un único span. Si tenemos que hacer varios escaneos de índice, después del procesamiento del escaneo de índice (por ejemplo, escaneo de unión, escaneo distinto en el explain), no podemos hacer que el indexador evalúe la paginación. La consulta se ejecutará sin enviar la cláusula de paginación al escaneo del índice. A continuación se muestran ejemplos de predicados que generan un único intervalo.
- Por ejemplo (a entre 4 y 8 y a 12)
- (a = 5 O a = 6)
- (a IN [4, 6, 9])
- Todos los predicados deben ser exactos.
- Predicados exactos: (a = 5), (a entre 9,8 y 9,99)
- Predicados inexactos: (a > 5 y a > $param)
- La consulta no puede contener cláusulas de agregación, agrupación, tener. No deben eliminar ningún documento después del escaneo del índice (no hay filtrado/reducción posterior al escaneo del índice).
- Las claves ORDER BY y el orden de las claves deben coincidir con la clave del índice y el orden de la clave del índice.
- CREAR ÍNDICE i1 EN t(a, b, c);
- SELECT * FROM t WHERE a = 1 ORDER BY a, b, c;
- SELECT * FROM t WHERE a = 1 ORDER BY b, c;
- SELECT * FROM t WHERE a > 3 ORDER BY b, c
- SELECT * FROM t WHERE a > 3 ORDER BY a, b, c
- SELECT * FROM t WHERE (a LIKE "%xyz") ORDER BY a, b, c OFFSET 10 LIMIT 5;
El caso (2) coincide perfectamente con el pedido.
El caso (3) no coincide perfectamente, pero la clave principal tiene un filtro de igualdad. Por lo tanto, sabemos que los resultados de la exploración estarán en el orden de (b, c). Por lo tanto, la paginación pushdown al índice es posible.
Para el caso (4), la clave principal tiene un predicado de rango (a > 3) y, por lo tanto, no es posible el pushdown de paginación.
En el caso (5), la cláusula ORDER BY coincide perfectamente con las claves del índice. Por lo tanto, podemos enviar la paginación al indexador, incluso si hay un predicado de rango en la clave principal.
Para el caso (f), podemos explotar el orden del índice, pero no podemos presionar OFFSET y LIMIT porque el predicado completo no puede ser evaluado por el escaneo del índice. Dado que obtenemos los resultados en el orden requerido, una vez proyectados el número de documentos OFFSET y LIMIT, finalizamos la exploración del índice.
Para simplificar, he utilizado una sola clave principal. Las afirmaciones son generalizadas y aplicables a múltiples claves principales.
Obviamente, la lógica de este optimizador es compleja. Véase información adicional en el apéndice sobre los requisitos.
OFFSET por encima:
La muestra de viajes inicial tiene unos 900 documentos con (tipo = "hotel"). Para experimentar, simplemente aumento la cantidad de datos volviendo a insertar los mismos datos varias veces utilizando la siguiente consulta:
|
1 2 3 4 5 6 7 8 9 10 11 |
insertar en Viajar-muestra`(clave UUID(), valor t) seleccione t de Viajar-muestra` t ; seleccione cuente(*) de Viajar-muestra` donde tipo = "hotel"; { "$1": 38318 } |
Ahora, probemos esta consulta:
|
1 2 3 4 5 6 7 8 |
SELECCIONE * DESDE Viajar-muestra` DONDE tipo = hotel PEDIR POR país, ciudad OFFSET 38000 LÍMITE 10; |
| OFFSET | LÍMITE | Tiempo de respuesta |
| 38000 | 10 | 28,97 ms |
A medida que aumenta el OFFSET, aumenta el tiempo que tarda el indizador en recorrer los elementos del índice. Esto afecta tanto a la latencia como al rendimiento.
¿Podemos mejorar esto? La paginación por teclas viene al rescate. Todas las reglas que hemos mencionado para la optimización de la paginación se aplican también en este caso. Además, uno de los predicados tiene que ser UNIQUE para que podamos navegar claramente de una página a otra sin que aparezcan documentos duplicados en varias páginas. Con Couchbase, estamos de suerte. Cada documento de un bucket tiene una clave de documento única. Es referenciada por META().id en la consulta N1QL.
La idea básica es que los clientes suelen querer la página SIGUIENTE en lugar de una página aleatoria del principio del conjunto de resultados. Por lo tanto, cuando obtenga cada página en orden, recuerde el último conjunto (MÁS ALTO/MÁS BAJO dependiendo de la cláusula ORDER BY). A continuación, utilice esa información para establecer los predicados y posicionar el índice para la siguiente búsqueda. Esto evitará el desperdicio de procesamiento de claves durante OFFSET.
Veamos un ejemplo:
CREAR ÍNDICE ixtypectcy EN viaje-muestra (tipo, país, ciudad, META().id);
- GET La PRIMERA PÁGINA. Fíjate que he añadido META().id a la cláusula index, projection y ORDER BY para que garantice el valor UNIQUE en cada una de ellas.
|
1 2 3 4 5 6 7 8 |
SELECCIONE país, ciudad, META().id DESDE Viajar-muestra` utilice índice (ixtypectcy) DONDE tipo = "hotel" PEDIR POR país, ciudad, META().id OFFSET 0 LÍMITE 5; |
Resultados:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "ciudad": "Avignon", "país": "Francia, "id": "000cb76b-ed85-4f56-9a6e-a6c300902944" }, { "ciudad": "Avignon", "país": "Francia, "id": "0070d2ac-e411-4aeb-a1e7-4a00635d2d5a" }, { "ciudad": "Avignon", "país": "Francia, "id": "01e4c1da-3749-43ce-88e3-37a00d0a376f" }, { "ciudad": "Avignon", "país": "Francia, "id": "0352b5c9-fcbf-48bc-9cf8-f5760cc910a2" }, { "ciudad": "Avignon", "país": "Francia, "id": "038c8a13-e1e7-4848-80ec-8819ff923602" } |
Esta consulta se ejecutó en 5,14 milisegundos.
- Ahora, construya la consulta para la página siguiente SIN utilizar OFFSET:
|
1 2 3 4 5 6 7 8 9 10 |
SELECCIONE país, ciudad, META().id DESDE Viajar-muestra` utilice índice (ixtypectcy) DONDE tipo = "hotel" Y país >= "Francia Y ciudad >= "Avignon" Y META().id > "038c8a13-e1e7-4848-80ec-8819ff923602" PEDIR POR país, ciudad, META().id LÍMITE 5; |
¿Cómo hemos construido esta consulta?
- Reutilice todos los predicados de la cláusula WHERE. (tipo = "hotel").
- Ahora, tome las claves del ORDER BY y construya los predicados adicionales. Así, simplemente tome el valor más alto devuelto por la última consulta y añada los nuevos predicados. No añada la clave del documento todavía. En este caso, estamos ordenando en orden ascendente. Por lo tanto, utilice el operador Mayor que O Igual a.
En este caso, es: (país >= "Francia" Y ciudad >= "Aviñón").
Ahora, para asegurar un valor único, añadimos el predicado META().id.
(META().id > "038c8a13-e1e7-4848-80ec-8819ff923602")
Esto se ejecuta en 5 milisegundos con el siguiente plan. A medida que avance por las páginas siguientes, simplemente repita los pasos para construir la siguiente consulta y evitar el OFFSET. ¡Puede continuar hasta el infinito con un tiempo de respuesta similar!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
{ "#operator": "IndexScan2", "tapas": [ "cover ((`viaje-muestra`.`tipo`))", "cover ((`viaje-muestra`.`país`))", "cubrir ((`viaje-muestra`.`ciudad`))", "cover ((meta(`viaje-muestra`).`id`))", "cover ((meta(`viaje-muestra`).`id`))" ], "índice": "ixtypectcy", "index_id": "5e43ce0471785942", "proyección_índice": { "entry_keys": [ 0, 1, 2 ], "clave_primaria": verdadero }, "espacio clave": "viaje-muestra", "límite": "5", "espacio de nombres": "por defecto", "vanos": [ { "exacto": verdadero, "rango": [ { "alto": "\"hotel\"", "inclusión": 3, "bajo": "\"hotel\"" }, { "inclusión": 1, "bajo": "\"France\"" }, { "inclusión": 1, "bajo": "\"Avignon\"" }, { "inclusión": 0, "bajo": "\"038c8a13-e1e7-4848-80ec-8819ff923602\"" } ] } ], |
RESUMEN:
Acabas de aprender cómo funciona la paginación. También aprendiste cómo el optimizador N1QL de Couchbase explota el índice para mejorar la eficiencia del rendimiento de la paginación de consultas. Puedes usar las técnicas de paginación keyset para mejorar aún más el rendimiento de OFFSET usando la técnica escrita.
Referencias:
- https://www.couchbase.com/blog/optimizing-database-pagination-using-couchbase-n1ql/
- https://www.slideshare.net/MarkusWinand/p2d2-pagination-done-the-postgresql-way
- http://use-the-index-luke.com/sql/partial-results/fetch-next-page
- https://blog.jooq.org/2013/10/26/faster-sql-paging-with-jooq-using-the-seek-method/
Apéndice: Optimizar la consulta con orden, desplazamiento y límite para aprovechar el orden de los índices
La evaluación de la consulta ORDER BY puede explotar el orden del índice con el indexador devolviendo los resultados en el orden requerido y la consulta no tiene que modificar el orden (por ejemplo, hace agrupaciones, uniones). Cuando cambia el orden de los registros, es necesario utilizar datos de ordenación para satisfacer la cláusula ORDER BY.
- No se utilizará el orden de índice cuando la cláusula from contenga agregados.
- El orden del índice no se utilizará cuando esté presente la cláusula GROUP BY.
- El orden del índice no se utilizará cuando se utilicen JOINs, NEST o UNNEST.
- El orden del índice no se utilizará cuando DISTINCT esté presente.
- No se utilizará el orden de índice cuando se utilicen operadores SET. Esto incluye UNION, UNION ALL, INTERSECT, EXCEPT, EXCEPTALL.
- El orden de los índices no se utilizará cuando se trate de una exploración primaria.
- No se utilizará el orden de índice cuando se trate de una exploración de intersección o unión.
- El orden de los índices no se utilizará cuando se trate de índices de matrices.
- El orden del índice no se utilizará cuando la intercalación del orden (ASC, DESC) no coincida con la intercalación del índice.
- El orden de índice no se utilizará cuando algún término de orden no coincida con claves de índice.
- Si la consulta explota el orden del índice, el operador Orden no estará presente en el EXPLAIN de la consulta.
OFFSET y LIMIT pueden ser empujados a IndexScan
- cuando el ORDER BY está presente y es capaz de explotar el orden del índice
- Cuando la consulta ORDER BY no está presente
- Todos los predicados se envían al indizador como parte de los intervalos.
- Los valores de los tramos empujados son exactos
- Basado en intervalos El Indexador no genera falsos positivos
- La consulta no reduce aún más los resultados de la exploración de índices.
- Si el OFFSET es empujado al indexador "offset" aparecerá en la sección IndexScan del EXPLAIN y el Operador Offset no estará presente al final del EXPLAIN.
- Si el límite es empujado al indexador "limit" aparecerá en la sección IndexScan del EXPLAIN.
Hola Keshav, ahora estoy implementando paginación cursor en couchbase, así que pensé que voy a tomar un registro en este post, sin embargo, he implementado de manera diferente que tú, y me preguntaba si me perdí algo.
En el ejemplo que utilizaste al final:
SELECT país, ciudad, META().id
DESDE
viaje-muestrautilizar índice (ixtypectcy)WHERE tipo = "hotel"
AND país >= "Francia"
AND ciudad >= "Avignon"
AND META().id > "038c8a13-e1e7-4848-80ec-8819ff923602"
ORDER BY país, ciudad, META().id
LÍMITE 5;
parece que te saltas muchos registros ya que filtras por META().id > "038c8a13-e1e7-4848-80ec-8819ff923602", sin embargo, puedes tener registros que se apliquen a país >= "Francia"
AND ciudad >= "Avignon" con id menor que "038c8a13-e1e7-4848-80ec-8819ff923602"