
WHITEPAPER
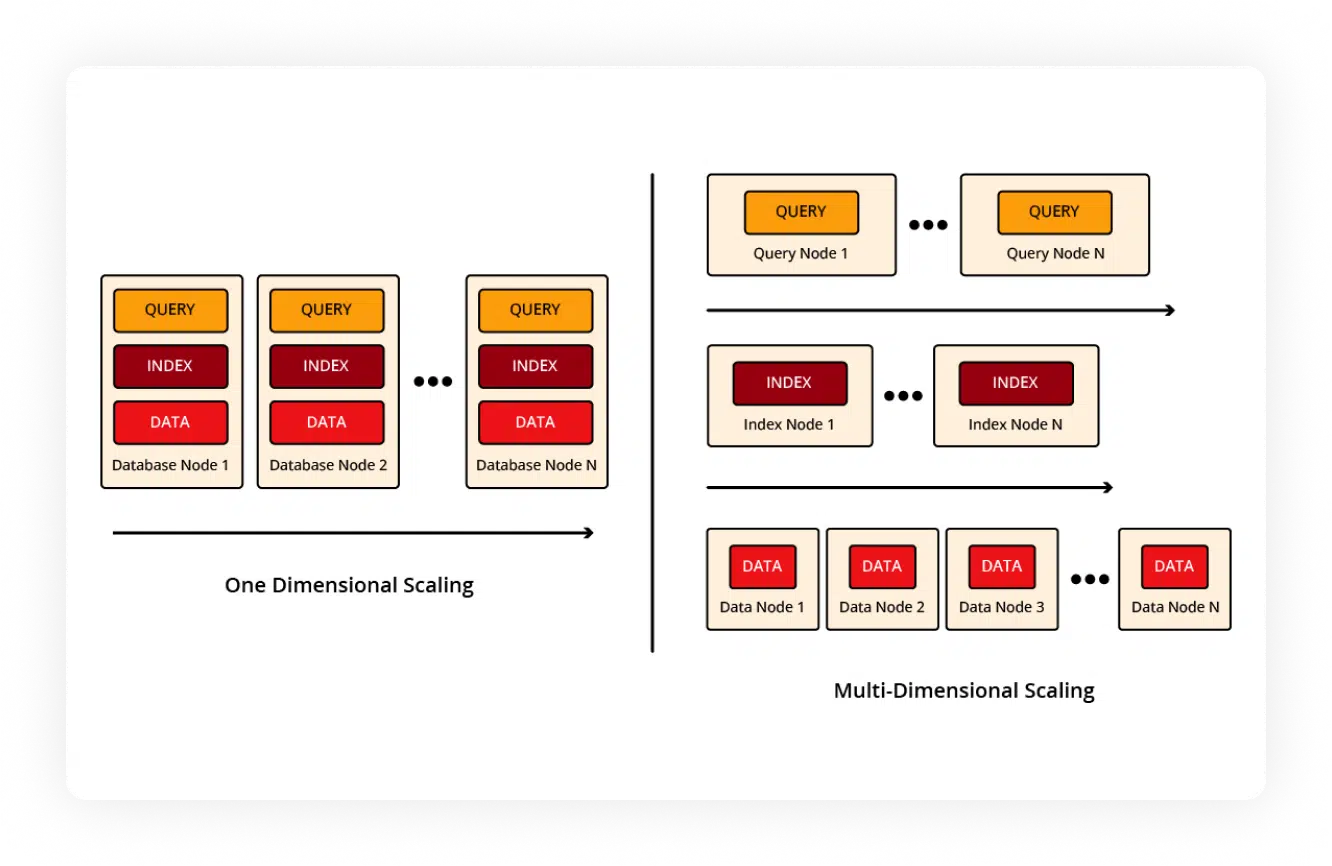
Couchbase MDS improves performance and reduces costs by letting you scale your query, index, and data services separately. This separation eliminates resource conflicts, wasted hardware, and unnecessary rebalancing. Plus, you can assign each service to the best hardware for its job – CPUs for queries, SSDs for indexes, and RAM for data. Your apps run faster, customers get a better experience, and your system is easier to manage.
Queries run faster on dedicated nodes and don’t slow down reads or writes by hogging CPU.
Indexes on dedicated nodes search faster and don’t slow down writes by overloading disk I/O.
More nodes mean more data capacity. With isolated data nodes memory use goes up, CPU/disk needs go down, and read/write speed stays consistent.
Couchbase lets you assign services to specific nodes, maximizing CPU and RAM usage through efficient resource distribution.
You can scale each of these Couchbase services independently and don’t need to run every service on every node.
Storage and key/value access for JSON documents.
SQL++ query engine can be used with Data and Index services.
Primary and secondary indexes on data.
Full-text, geospatial, and vector search for AI.
Real-time workload-isolated analytics and SQL++.
Real-time logic to respond to mutations/times.
Full and incremental backups and merges.
Dedicated query nodes ensure fast processing without slowing down reads or writes. By isolating query operations, you avoid CPU contention with other services, and you can scale query nodes without rebalancing data. This makes queries consistently fast, even under heavy loads.
Index services benefit from SSDs and operate best when isolated. This keeps writes fast since disk I/O isn’t shared with other services. You can scale indexing independently and create as many indexes as needed without affecting data distribution or write performance.

When data nodes are isolated from query and index workloads, reads and writes stay fast and predictable. You don’t have to rebalance queries or indexes to scale the data layer, and you can prioritize memory while using more modest CPU and disk resources.


“Switching to Couchbase increased performance while lowering database and operational costs.”

“What we value a lot is that Couchbase was able to embrace with us our vision to the cloud.”



Check out our developer portal to explore NoSQL, browse resources, and get started with tutorials.

Get hands-on with Couchbase in just a few clicks. Capella DBaaS is the easiest and fastest way to get started.

Want to learn more about Couchbase offerings? Let us help