Nos sistemas distribuídos modernos, a capacidade de replicar dados entre ambientes separados é crucial para garantir a alta disponibilidade, a recuperação de desastres e a otimização do desempenho. O recurso XDCR (Cross Data Center Replication) do Couchbase permite a replicação contínua de dados entre clusters, possibilitando o compartilhamento robusto de dados em ambientes geográfica ou logicamente isolados.
Este guia o orientará na configuração do XDCR entre dois clusters do Couchbase hospedados em clusters separados do Amazon EKS (Elastic Kubernetes Service) em diferentes VPCs. Vamos nos aprofundar em cada etapa, desde a configuração da infraestrutura até a configuração do DNS para comunicação entre clusters e a implantação do Couchbase para replicação em tempo real. Ao final deste passo a passo, você terá uma configuração pronta para produção com as habilidades para replicar isso em seu ambiente.
Pré-requisitos
Para seguir este guia, verifique se você tem:
-
- CLI DO AWS instalado e configurado
- Uma conta do AWS com permissões para criar VPCs, clusters EKS e grupos de segurança
- Familiaridade com o Kubernetes e ferramentas como kubectl e Helm
- Helm instalado para implementar o Couchbase
- Conhecimento básico de conceitos de rede, incluindo blocos CIDR, tabelas de roteamento e DNS
Etapa 1: implantar clusters EKS em VPCs separadas
O que estamos fazendo?
Criaremos dois clusters do Kubernetes, Cluster1 e Cluster2, em VPCs separados usando eksctl. Cada cluster operará de forma independente e terá seu próprio bloco CIDR para evitar conflitos de IP.
Por que isso é importante?
Essa separação garante:
-
- Isolamento para melhor segurança e gerenciamento
- Escalabilidade e flexibilidade para lidar com cargas de trabalho
- Regras claras de roteamento entre clusters
Comandos para criar clusters
Implantar o cluster1
|
1 2 3 4 5 6 7 8 9 10 |
eksctl create cluster \ --name cluster1 \ --region us-east-1 \ --zones us-east-1a,us-east-1b,us-east-1c \ --node-type t2.medium \ --nodes 2 \ --nodes-min 1 \ --nodes-max 3 \ --version 1.27 \ --vpc-cidr 10.0.0.0/16 |
Implantar o cluster2
|
1 2 3 4 5 6 7 8 9 10 |
eksctl create cluster \ --name cluster2 \ --region us-east-1 \ --zones us-east-1a,us-east-1b,us-east-1c \ --node-type t2.medium \ --nodes 2 \ --nodes-min 1 \ --nodes-max 3 \ --version 1.27 \ --vpc-cidr 10.1.0.0/16 |
Resultado esperado
-
- O cluster1 reside na VPC 10.0.0.0/16
- O cluster2 reside na VPC 10.1.0.0/16

Etapa 2: emparelhar as VPCs para comunicação entre clusters
O que estamos fazendo?
Estamos criando uma conexão de peering de VPC entre as duas VPCs e configurando regras de roteamento e segurança para permitir a comunicação entre clusters.
Etapas
2.1 Criar uma conexão de emparelhamento
-
- Vá para o Console da AWS > VPC > Conexões de peering
- Clique em Criar conexão de peering
- Selecione o VPC do solicitante (VPC do Cluster1) e VPC do aceitador (VPC do Cluster2)
- Nomear a conexão eks-peer
- Clique em Criar conexão de peering
2.2 Aceitar a solicitação de peering
-
- Selecione a conexão de emparelhamento
- Clique em Ações > Aceitar solicitação
2.3 Atualizar tabelas de rotas
-
- Para a VPC do Cluster1, adicione uma rota para 10.1.0.0/16, direcionando a conexão de emparelhamento
- Para a VPC do Cluster2, adicione uma rota para 10.0.0.0/16, direcionando a conexão de emparelhamento

2.4 Modificar grupos de segurança
Por que isso é necessário?
Os grupos de segurança funcionam como firewalls, e devemos permitir explicitamente o tráfego entre os clusters.
Como modificar
-
- Navegue até EC2 > Grupos de segurança no console do AWS
- Identificar os grupos de segurança associados ao Cluster1 e ao Cluster2
- Para o grupo de segurança do Cluster1:
- Clique em Editar regras de entrada
- Adicionar uma regra:
- Tipo: Todo o tráfego
- Fonte: ID do grupo de segurança do Cluster2
- Repita o procedimento para o Cluster2, permitindo o tráfego do grupo de segurança do Cluster1



Etapa 3: testar a conectividade implantando o NGINX no cluster2
O que estamos fazendo?
Estamos implantando um pod NGINX no Cluster2 para verificar se o Cluster1 pode se comunicar com ele.
Por que isso é importante?
Essa etapa garante que a rede entre os clusters esteja funcionando antes de implantar o Couchbase.
Etapas
3.1 Criar um espaço de nome no Cluster1 e no Cluster2
|
1 2 |
kubectl create ns dev #in cluster1 kubectl create ns prod #in cluster2 |
3.2 Implantar o NGINX no cluster1 e no cluster2
-
- Crie o nginx.yaml:
12345678910111213141516171819202122232425262728293031apiVersion: apps/v1kind: Deploymentmetadata:name: nginxspec:replicas: 1selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxports:- containerPort: 80---apiVersion: v1kind: Servicemetadata:name: nginxspec:clusterIP: Noneports:- port: 80targetPort: 80selector:app: nginx
- Crie o nginx.yaml:
3.3 Aplicar o YAML
|
1 |
kubectl apply -f nginx.yaml -n prod |
3.4 Verificar a conectividade do cluster1
-
- Execute no pod no Cluster1:
1kubectl exec -it -n dev <pod-name> -- /bin/bash
- Execute no pod no Cluster1:
3.5 Teste a conectividade com o Cluster2
|
1 |
curl nginx.prod |
Resultado esperado
O enrolar falhará sem o encaminhamento do DNS, destacando a necessidade de configuração adicional do DNS.

Etapa 4: Configuração do encaminhamento de DNS
O que estamos fazendo?
Configuraremos o encaminhamento de DNS para que os serviços no Cluster2 possam ser resolvidos pelo Cluster1. Isso é fundamental para permitir que os aplicativos no Cluster1 interajam com os serviços no Cluster2 usando seus nomes de DNS.
Por que isso é importante?
A descoberta de serviços do Kubernetes depende do DNS e, por padrão, as consultas de DNS para os serviços de um cluster não podem ser resolvidas em outro cluster. O CoreDNS no Cluster1 deve encaminhar as consultas para o resolvedor de DNS do Cluster2.
Etapas
4.1 Recuperar o ponto de extremidade do serviço DNS do Cluster2
-
- Execute o seguinte comando no Cluster2 para obter o ponto de extremidade do serviço DNS:
1kubectl get endpoints -n kube-system - Procure o kube-dns ou coredns e anote seu endereço IP. Por exemplo:
1234----------------------------------------NAME ENDPOINTS AGEkube-dns 10.1.20.116:53 3h----------------------------------------

- Execute o seguinte comando no Cluster2 para obter o ponto de extremidade do serviço DNS:
4.2 Editar o CoreDNS ConfigMap no Cluster1
-
- Abra o CoreDNS ConfigMap para edição:
1kubectl edit cm coredns -n kube-system
- Abra o CoreDNS ConfigMap para edição:
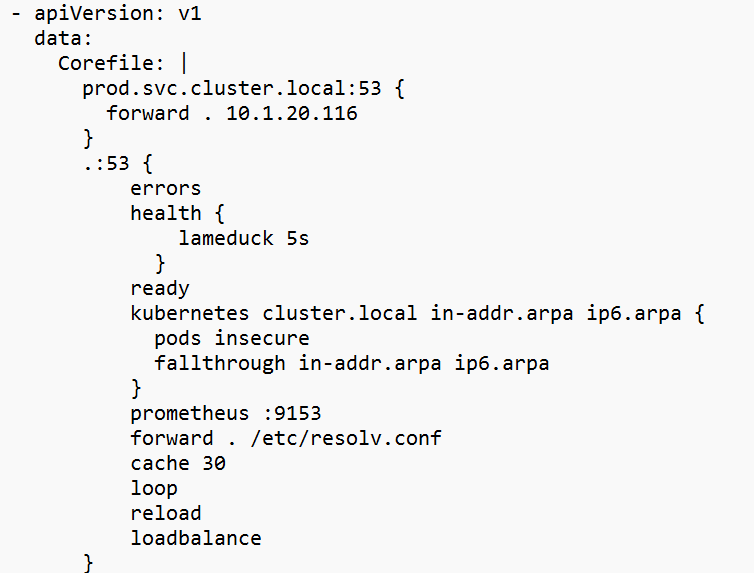
4.3 Aadicione o seguinte bloco à seção Corefile
|
1 2 3 |
prod.svc.cluster.local:53 { forward . 10.1.20.116 } |
Substitua 10.1.20.116 pelo IP real do ponto de extremidade do DNS do Cluster2.
Observação: só precisamos usar um dos endpoints do CoreDNS para esse ConfigMap. O IP dos pods do CoreDNS raramente muda, mas pode mudar se o nó ficar inativo. O serviço kube-dns ClusterIP pode ser usado, mas exigirá que o IP e a porta estejam abertos nos nós do EKS.
4.4 Reiniciar o CoreDNS no Cluster1
-
- Aplique as alterações reiniciando o CoreDNS:
1kubectl rollout restart deployment coredns -n kube-system

- Aplique as alterações reiniciando o CoreDNS:
4.5 Verificar o encaminhamento de DNS
-
- Executar em qualquer pod no Cluster1:
1kubectl exec -it -n default <pod-name> -- /bin/bash - Teste a resolução de DNS para um serviço NGINX no Cluster2:
1curl nginx.prod.svc.cluster.local - Você deverá ver uma resposta do serviço NGINX
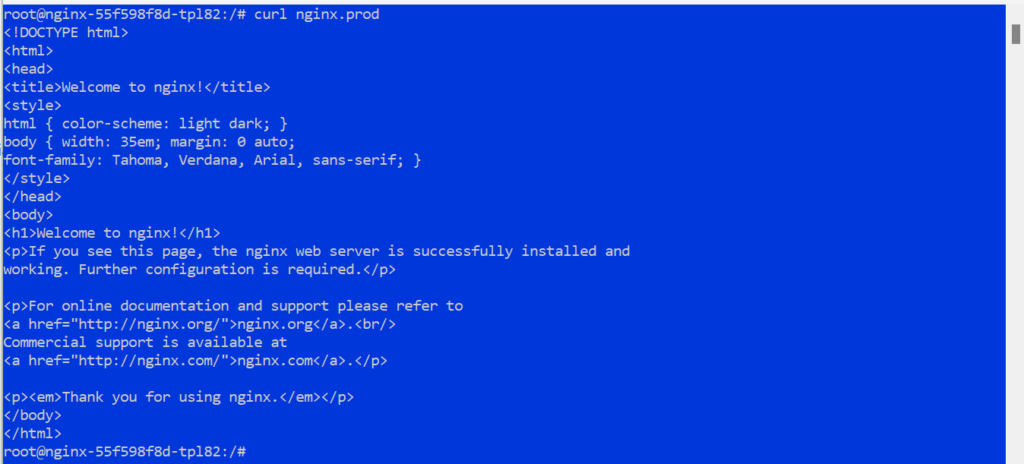
- Executar em qualquer pod no Cluster1:
Resultado esperado
As consultas de DNS do Cluster1 para o Cluster2 devem ser resolvidas com êxito.
Etapa 5: Implantação do Couchbase
O que estamos fazendo?
Implantaremos clusters do Couchbase em ambos os ambientes Kubernetes usando o Helm. Cada cluster gerenciará seus próprios dados de forma independente antes de ser conectado por meio do XDCR.
Por que isso é importante?
Os clusters do Couchbase formam a base da configuração do XDCR, fornecendo uma plataforma de banco de dados NoSQL robusta e dimensionável.
Etapas
5.1 Adicionar o repositório de gráficos do Couchbase Helm
|
1 2 |
helm repo add couchbase https://couchbase-partners.github.io/helm-charts/ helm repo update |
5.2 Implantar o Couchbase no Cluster1
-
- Mudar para o Cluster1:
1kubectl config use-context <cluster1-context> - Implantar o Couchbase:
1helm install couchbase couchbase/couchbase-operator --namespace dev
- Mudar para o Cluster1:

5.3 Implantar o Couchbase no Cluster2
-
- Mudar para o Cluster2:
1kubectl config use-context <cluster2-context> - Implantar o Couchbase:
1helm install couchbase couchbase-operator --namespace prod
- Mudar para o Cluster2:
5.4 Verificar a implantação
-
- Verifique os pods do Couchbase:
12kubectl get pods -n dev # For Cluster1kubectl get pods -n prod # For Cluster2

- Verifique se todos os pods estão em execução.
- Verifique os pods do Couchbase:

Observação: Se você encontrar um erro de implantação, edite o CRD do CouchbaseCluster para usar uma versão de imagem compatível:
|
1 |
kubectl edit couchbasecluster <cluster-name> -n <namespace> |
Mudança:
|
1 |
image: couchbase/server:7.2.0 |
Para:
|
1 |
image: couchbase/server:7.2.4 |
Resultado esperado
Os clusters do Couchbase devem estar em execução e acessíveis por meio de suas respectivas UIs.
Etapa 6: Configuração do XDCR
O que estamos fazendo?
Configuraremos o XDCR para ativar a replicação de dados entre os dois clusters do Couchbase.
Por que isso é importante?
O XDCR garante a consistência dos dados entre clusters, oferecendo suporte a cenários de alta disponibilidade e recuperação de desastres.
Etapas
6.1 Obter o nome do serviço do Cluster2
-
- No cluster2, execute o seguinte comando para recuperar o nome do serviço de um dos pods para que possamos fazer o encaminhamento de porta para ele.
1kubectl get services -n prod
- No cluster2, execute o seguinte comando para recuperar o nome do serviço de um dos pods para que possamos fazer o encaminhamento de porta para ele.
6.2 Acessar a interface do usuário do Couchbase para o Cluster2
-
-
- Encaminhar a interface do usuário do Couchbase:
1kubectl port-forward -n prod cluster2-0000 8091:8091
- Encaminhar a interface do usuário do Couchbase:
-
-
- Abra um navegador e navegue até:
https://localhost:8091
- Abra um navegador e navegue até:
-
- Faça login usando as credenciais configuradas durante a implementação.
6.3 Exibir documentos no Cluster2
-
- Na interface do usuário do Couchbase, vá para Baldes
- Observe que não existem documentos no padrão balde

6.4 Acessar a interface do usuário do Couchbase para o Cluster1
-
- Encaminhar a interface do usuário do Couchbase:
1kubectl port-forward -n dev cluster1-0000 8091:8091

- Abra um navegador e navegue até:
https://localhost:8091 - Faça login usando as credenciais configuradas durante a implementação
- Encaminhar a interface do usuário do Couchbase:
6.5 Adicionar um cluster remoto
-
- Na interface do usuário do Couchbase, vá para XDCR > Adicionar cluster remoto
- Configure o cluster remoto:
- Nome do cluster: Cluster2
- IP/nome do host:.prod.svc.cluster.local
- Nome de usuário: Nome de usuário do administrador do Cluster2
- Senha: Senha de administrador do Cluster2
- Clique em Salvar

6.6 Configurar a replicação
-
- Na interface do usuário do Couchbase para o Cluster1, vá para XDCR > Adicionar replicação
- Configure a replicação:
- Replicar a partir do Bucket: Bucket padrão no Cluster1
- Replicar para o Bucket: Bucket padrão no Cluster2
- Cluster remoto: Selecione Cluster2
- Clique em Salvar


6.7 Replicação de teste
-
- Adicione documentos de amostra ao bucket padrão no Cluster1:
- Na interface do usuário do Couchbase, navegue até Compartimentos > Documentos > Adicionar documento
- Dê a Documento um único ID e alguns dados em JSON formato
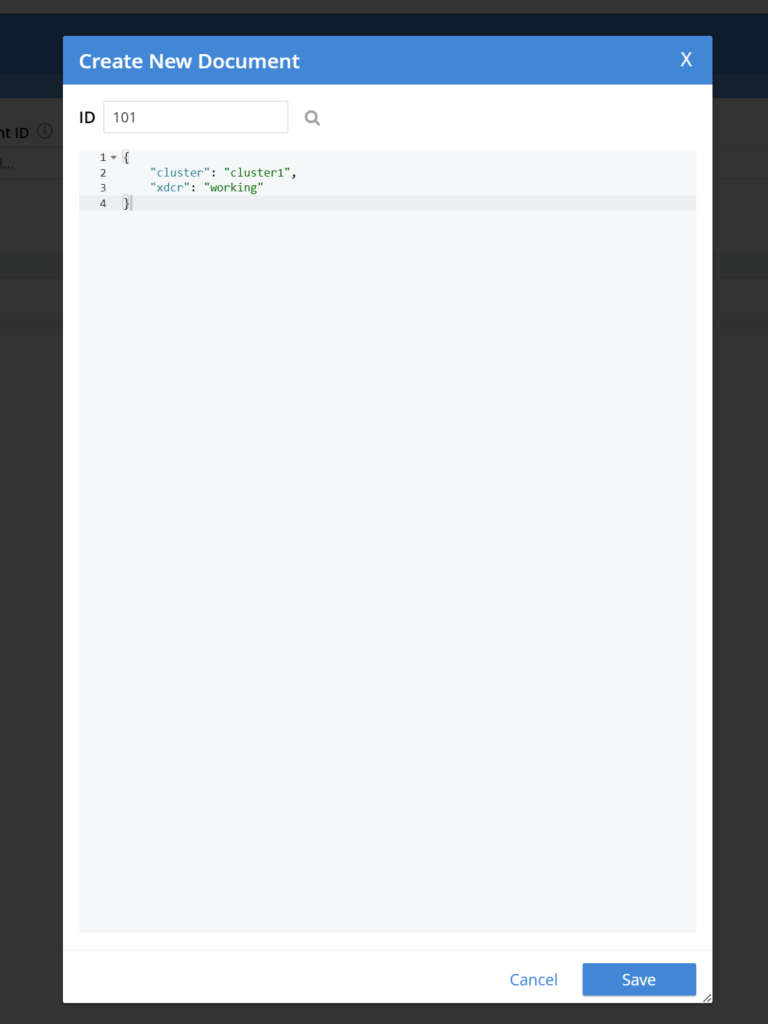
- Verifique se os documentos aparecem no bucket padrão do Cluster2:
- Encaminhe a porta para a interface do usuário do Cluster2 e faça login:
1kubectl port-forward -n prod cluster2-0000 8091:8091
- Encaminhe a porta para a interface do usuário do Cluster2 e faça login:
- Navegue até: https://localhost:8091
- Adicione documentos de amostra ao bucket padrão no Cluster1:

Resultado esperado
Os dados adicionados ao Cluster1 devem ser replicados para o Cluster2 em tempo real.
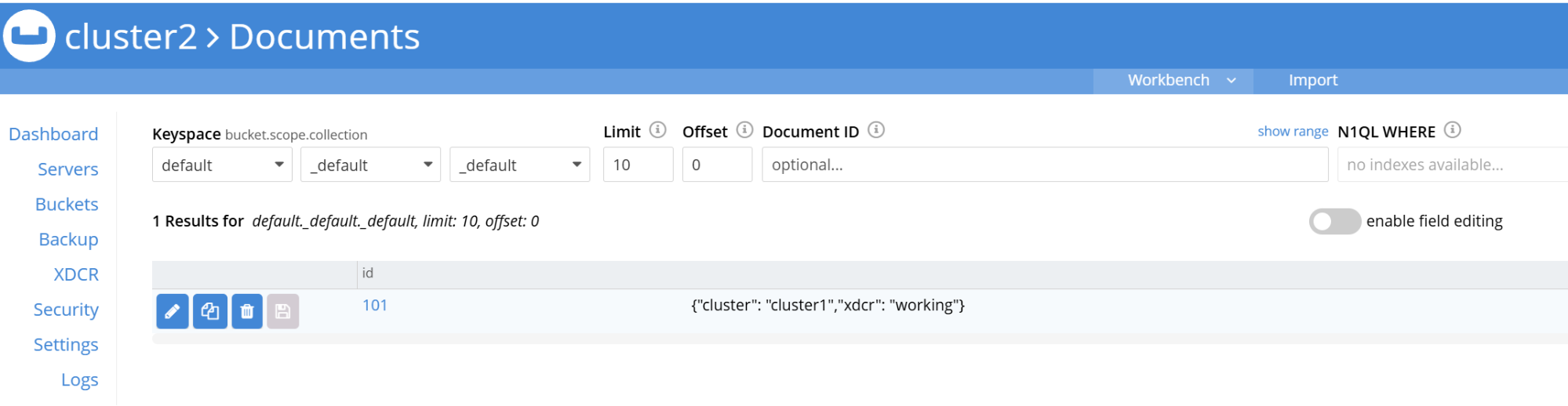
Etapa 7: Limpeza
O que estamos fazendo?
Limparemos nosso ambiente do AWS e excluiremos todos os recursos que implantamos.
Por que isso é importante?
Isso evitará que você incorra em cobranças desnecessárias.
Etapas
7.1 Acesse o console da AWS
-
- Vá para o Console da AWS > VPC > Conexões de peering
- Selecione e exclua a conexão de emparelhamento
- Vá para o Console da AWS > CloudFormation > Pilhas
- Selecione e exclua as duas pilhas de grupos de nós
- Quando as duas pilhas de grupos de nós tiverem terminado de excluir, selecione e exclua as pilhas de clusters
Resultado esperado
Todos os recursos criados para esse tutorial são excluídos da conta.
Conclusão
Por meio deste guia, estabelecemos com sucesso o XDCR entre clusters do Couchbase executados em clusters EKS separados em VPCs do AWS. Essa configuração destaca o poder de combinar a rede do AWS com o Kubernetes para obter soluções robustas e dimensionáveis. Com a replicação entre clusters implementada, seus aplicativos ganham maior resiliência, latência reduzida para usuários distribuídos e um sólido mecanismo de recuperação de desastres.
Ao compreender e implementar as etapas descritas aqui, você estará preparado para enfrentar os desafios do mundo real que envolvem configurações de vários clusters, expandindo sua experiência em redes de nuvem e gerenciamento de bancos de dados distribuídos.
-
- Saiba mais sobre Replicação entre centros de dados do Couchbase (XDCR)
- Leia o Documentação do XDCR
- Leia como O XDCR é essencial para dados distribuídos globalmenterecuperação de desastres e alta disponibilidade

